
 Peranti teknologi
AI
CVPR 2024 |. Model gabungan imej umum berdasarkan KPM, menambah 2.8% parameter untuk menyelesaikan berbilang tugas
Peranti teknologi
AI
CVPR 2024 |. Model gabungan imej umum berdasarkan KPM, menambah 2.8% parameter untuk menyelesaikan berbilang tugas
CVPR 2024 |. Model gabungan imej umum berdasarkan KPM, menambah 2.8% parameter untuk menyelesaikan berbilang tugas


Lajur AIxiv ialah lajur di mana tapak ini menerbitkan kandungan akademik dan teknikal. Dalam beberapa tahun kebelakangan ini, lajur AIxiv laman web ini telah menerima lebih daripada 2,000 laporan, meliputi makmal terkemuka dari universiti dan syarikat utama di seluruh dunia, mempromosikan pertukaran dan penyebaran akademik secara berkesan. Jika anda mempunyai kerja yang sangat baik yang ingin anda kongsikan, sila berasa bebas untuk menyumbang atau hubungi kami untuk melaporkan. E-mel penyerahan: liyazhou@jiqizhixin.com; zhaoyunfeng@jiqizhixin.com.

paper Link: https://arxiv.org/abs/2403.12494 Code Link: https://github.com/yangsun22/tc-moa paper Tajuk: Campuran Penyesuai Tersuai Tugas untuk Gabungan Imej Umum

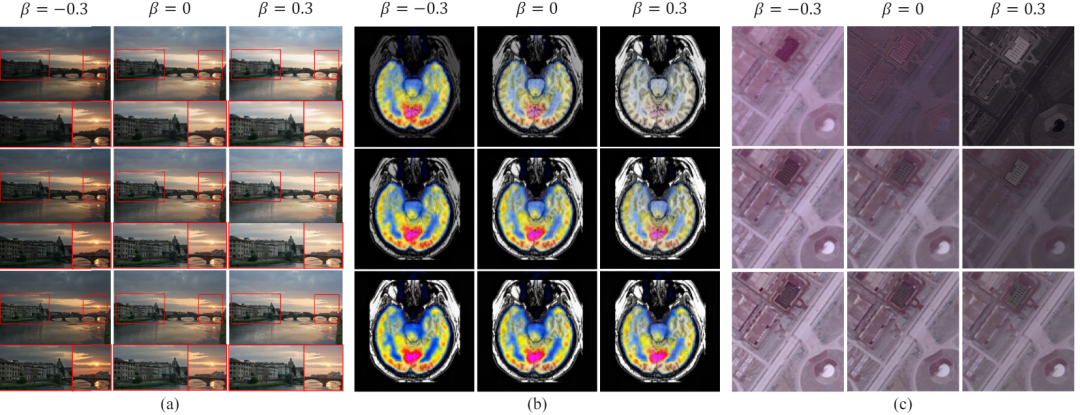
- Kami mencadangkan kaedah penyelarasan maklumat bersama untuk penyesuai, yang membolehkan model kami mengenal pasti dengan lebih tepat keamatan dominan imej sumber yang berbeza.
- Sepanjang pengetahuan kami, kami mencadangkan penyesuai fleksibel berasaskan KPM buat kali pertama. Dengan menambah hanya 2.8% daripada parameter yang boleh dipelajari, model kami boleh mengendalikan banyak tugas gabungan. Eksperimen yang meluas menunjukkan kelebihan kaedah bersaing kami sambil menunjukkan kebolehkawalan dan generalisasi yang ketara.. Kami memasukkan imej sumber ke dalam rangkaian ViT dan mendapatkan Token imej sumber melalui lapisan pengekodan patch. ViT terdiri daripada pengekod untuk pengekstrakan ciri dan penyahkod untuk pembinaan semula imej, yang kedua-duanya terdiri daripada blok Transformer.
Masukkan satu TC-MoA setiap

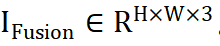
Peringatan untuk menjana
 . Kami menggabungkan
. Kami menggabungkan  sebagai representasi ciri pasangan Token berbilang sumber. Ini membolehkan token daripada sumber berbeza bertukar maklumat dalam rangkaian seterusnya. Walau bagaimanapun, pengiraan terus ciri gabungan dimensi tinggi akan membawa sejumlah besar parameter yang tidak diperlukan. Oleh itu, kami menggunakan
sebagai representasi ciri pasangan Token berbilang sumber. Ini membolehkan token daripada sumber berbeza bertukar maklumat dalam rangkaian seterusnya. Walau bagaimanapun, pengiraan terus ciri gabungan dimensi tinggi akan membawa sejumlah besar parameter yang tidak diperlukan. Oleh itu, kami menggunakan  untuk melakukan pengurangan dimensi ciri dan mendapatkan ciri berbilang sumber yang diproses
untuk melakukan pengurangan dimensi ciri dan mendapatkan ciri berbilang sumber yang diproses  , seperti berikut:
, seperti berikut: 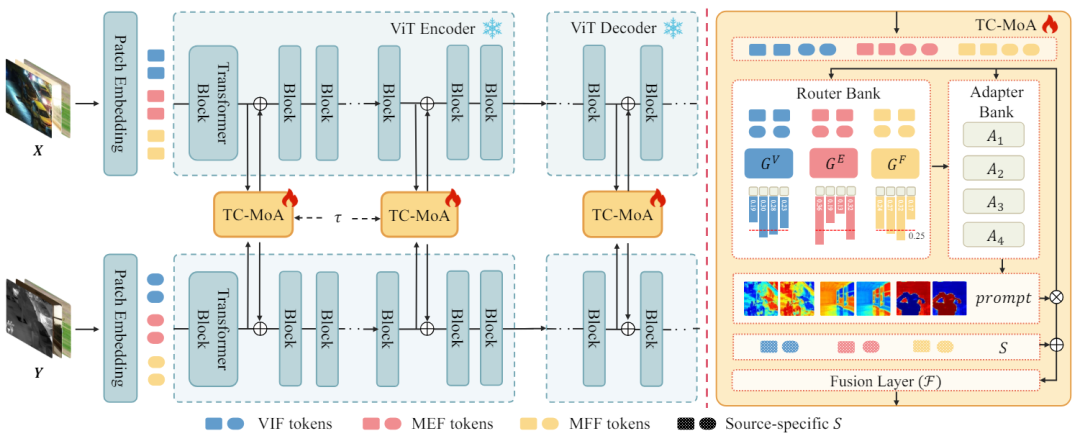
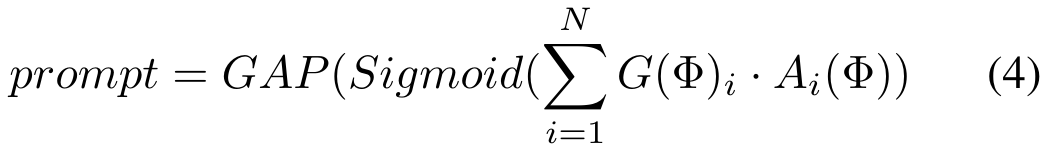
 , dan kemudian memperoleh ciri gabungan melalui lapisan gabungan F. Prosesnya adalah seperti berikut:
, dan kemudian memperoleh ciri gabungan melalui lapisan gabungan F. Prosesnya adalah seperti berikut: 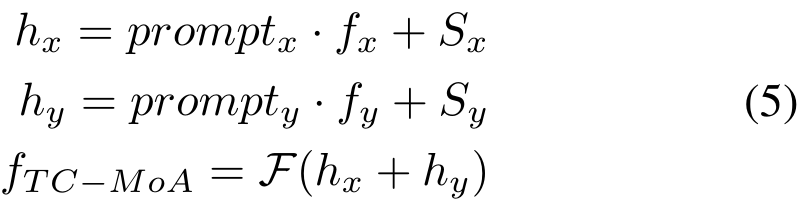
 ialah hiperparameter):
ialah hiperparameter): 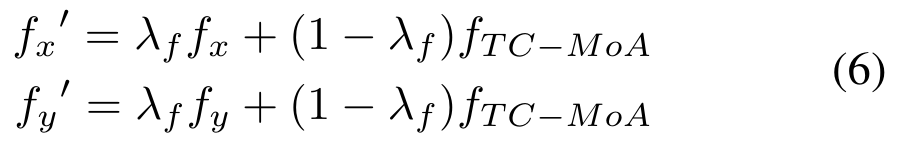



 eksperimen perbandingan litatif pada data tugasan MFF set
eksperimen perbandingan litatif pada data tugasan MFF set
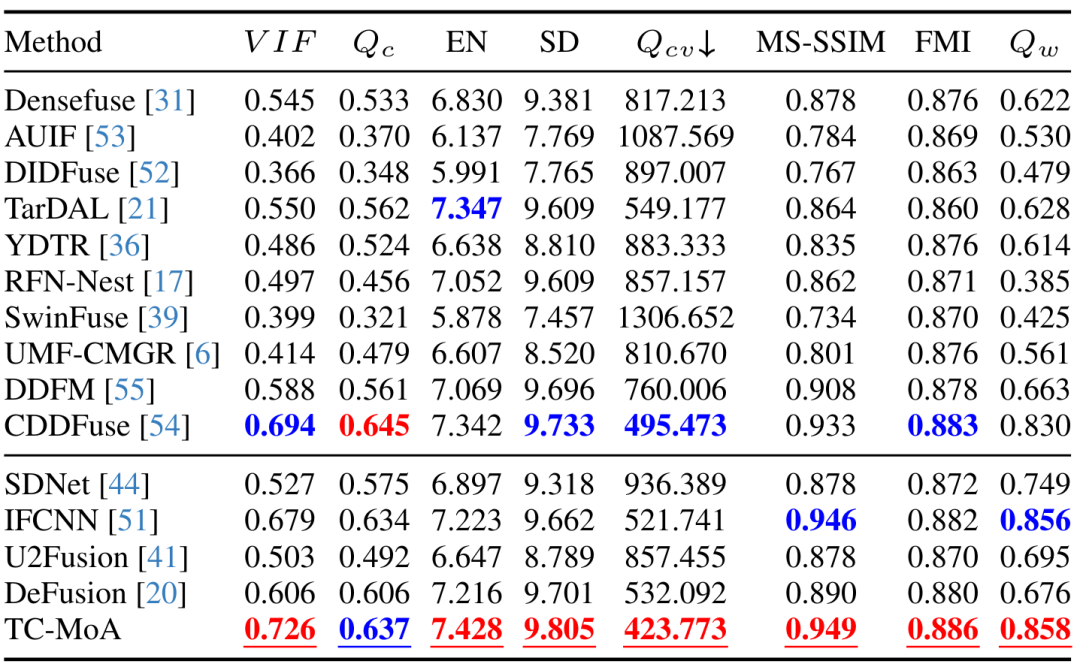 Jadual 1 VIF set data LLVIP set data eksperimen perbandingan kuantitatif
Jadual 1 VIF set data LLVIP set data eksperimen perbandingan kuantitatif
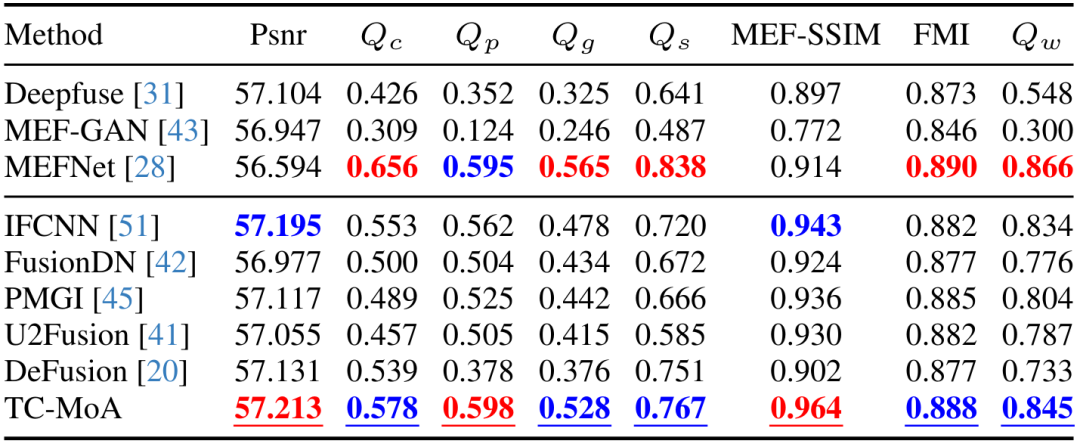
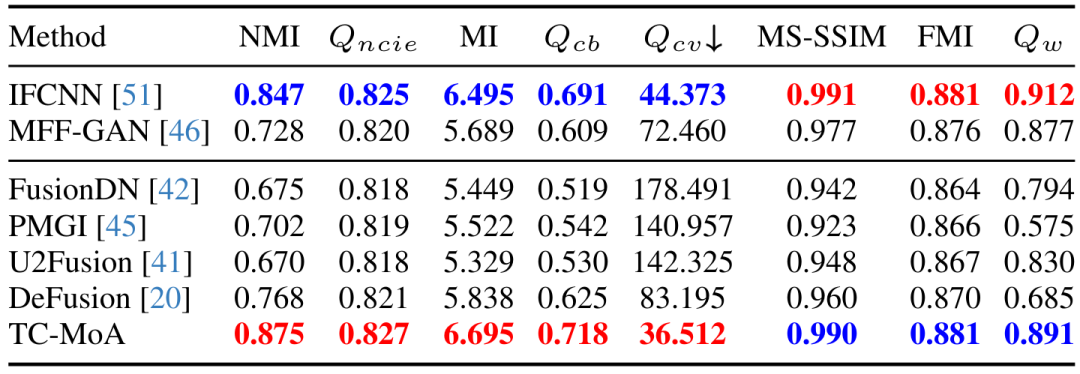
Atas ialah kandungan terperinci CVPR 2024 |. Model gabungan imej umum berdasarkan KPM, menambah 2.8% parameter untuk menyelesaikan berbilang tugas. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!

Alat AI Hot

Undresser.AI Undress
Apl berkuasa AI untuk mencipta foto bogel yang realistik

AI Clothes Remover
Alat AI dalam talian untuk mengeluarkan pakaian daripada foto.

Undress AI Tool
Gambar buka pakaian secara percuma

Clothoff.io
Penyingkiran pakaian AI

AI Hentai Generator
Menjana ai hentai secara percuma.

Artikel Panas
Alat panas

Notepad++7.3.1
Editor kod yang mudah digunakan dan percuma

SublimeText3 versi Cina
Versi Cina, sangat mudah digunakan

Hantar Studio 13.0.1
Persekitaran pembangunan bersepadu PHP yang berkuasa

Dreamweaver CS6
Alat pembangunan web visual

SublimeText3 versi Mac
Perisian penyuntingan kod peringkat Tuhan (SublimeText3)
Topik panas
 1371
1371
 52
52

 Perpustakaan apa yang digunakan untuk operasi nombor terapung di GO?
Apr 02, 2025 pm 02:06 PM
Perpustakaan apa yang digunakan untuk operasi nombor terapung di GO?
Apr 02, 2025 pm 02:06 PM
Perpustakaan yang digunakan untuk operasi nombor terapung dalam bahasa Go memperkenalkan cara memastikan ketepatannya ...
 Bitwise: perniagaan membeli bitcoin trend besar yang diabaikan
Mar 05, 2025 pm 02:42 PM
Bitwise: perniagaan membeli bitcoin trend besar yang diabaikan
Mar 05, 2025 pm 02:42 PM
Pemerhatian Mingguan: Perniagaan Menimbulkan Bitcoin - Perubahan Brewing Saya sering menunjukkan beberapa trend pasaran yang diabaikan dalam memo mingguan. Langkah MicroStrategy adalah contoh yang jelas. Ramai orang mungkin berkata, "MicroStrategy dan Michaelsaylor sudah terkenal, apa yang akan anda perhatikan?" Pandangan ini adalah satu sisi. Penyelidikan mendalam mengenai penggunaan Bitcoin sebagai aset rizab dalam beberapa bulan kebelakangan ini menunjukkan bahawa ini bukan kes terpencil, tetapi trend utama yang muncul. Saya meramalkan bahawa dalam 12-18 bulan akan datang, beratus-ratus syarikat akan mengikutinya dan membeli jumlah besar bitcoin
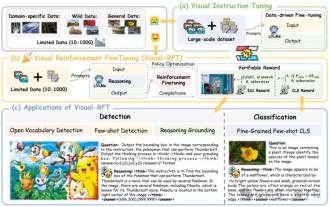 Melampaui SFT, rahsia di belakang O1/DeepSeek-R1 juga boleh digunakan dalam model besar multimodal
Mar 12, 2025 pm 01:03 PM
Melampaui SFT, rahsia di belakang O1/DeepSeek-R1 juga boleh digunakan dalam model besar multimodal
Mar 12, 2025 pm 01:03 PM
Penyelidik dari Universiti Shanghai Jiaoto, Shanghai Ailab dan Universiti Cina Hong Kong telah melancarkan projek sumber terbuka Visual-RFT (Visual Fine Fine Tuning), yang hanya memerlukan sedikit data untuk meningkatkan prestasi model bahasa besar visual (LVLM). Visual-RFT bijak menggabungkan pendekatan pembelajaran tetulang berasaskan peraturan DeepSeek-R1 dengan paradigma penalaan Fine-Penalaan Terbuka (RFT) OpenAI, berjaya memperluaskan pendekatan ini dari medan teks ke medan visual. Dengan merancang ganjaran peraturan yang sepadan untuk tugas-tugas seperti subkategori visual dan pengesanan objek, Visual-RFT mengatasi batasan kaedah DeepSeek-R1 yang terhad kepada teks, penalaran matematik dan bidang lain, menyediakan cara baru untuk latihan LVLM. Vis
 Perpustakaan mana yang dibangunkan oleh syarikat besar atau disediakan oleh projek sumber terbuka yang terkenal?
Apr 02, 2025 pm 04:12 PM
Perpustakaan mana yang dibangunkan oleh syarikat besar atau disediakan oleh projek sumber terbuka yang terkenal?
Apr 02, 2025 pm 04:12 PM
Perpustakaan mana yang dibangunkan oleh syarikat besar atau projek sumber terbuka yang terkenal? Semasa pengaturcaraan di GO, pemaju sering menghadapi beberapa keperluan biasa, ...
 GITEE PAGES PENYEDIAAN LAMAN WEB STATIC Gagal: Bagaimana menyelesaikan masalah dan menyelesaikan kesilapan fail tunggal 404?
Apr 04, 2025 pm 11:54 PM
GITEE PAGES PENYEDIAAN LAMAN WEB STATIC Gagal: Bagaimana menyelesaikan masalah dan menyelesaikan kesilapan fail tunggal 404?
Apr 04, 2025 pm 11:54 PM
Giteepages Statik Laman Web Penggunaan Gagal: 404 Penyelesaian Masalah dan Resolusi Ralat Semasa Menggunakan Gitee ...
 Bagaimana untuk mendapatkan data kawasan perkapalan versi luar negara? Apakah beberapa sumber siap sedia ada?
Apr 01, 2025 am 08:15 AM
Bagaimana untuk mendapatkan data kawasan perkapalan versi luar negara? Apakah beberapa sumber siap sedia ada?
Apr 01, 2025 am 08:15 AM
Penerangan Soalan: Bagaimana untuk mendapatkan data kawasan perkapalan versi luar negara? Adakah sumber sedia ada yang ada? Dapatkan tepat dalam e-dagang rentas sempadan atau perniagaan global ...
 Typecho Route Conflict Conflict: Kenapa saya/TEST/TAG/HIS/10086 Pencocokan TestTagIndex dan bukannya TestTagPage?
Apr 01, 2025 am 09:03 AM
Typecho Route Conflict Conflict: Kenapa saya/TEST/TAG/HIS/10086 Pencocokan TestTagIndex dan bukannya TestTagPage?
Apr 01, 2025 am 09:03 AM
TypeCho Routing Pencocokan Peraturan Analisis dan Penyiasatan Masalah Artikel ini akan menganalisis dan menjawab soalan mengenai hasil yang tidak konsisten dari pendaftaran routing plug-in typecho dan hasil padanan sebenar ...
 Python Hourglass Graph Lukisan: Bagaimana untuk mengelakkan kesilapan yang tidak ditentukan?
Apr 01, 2025 pm 06:27 PM
Python Hourglass Graph Lukisan: Bagaimana untuk mengelakkan kesilapan yang tidak ditentukan?
Apr 01, 2025 pm 06:27 PM
Bermula dengan Python: Lukisan Grafik Hourglass dan Pengesahan Input Artikel ini akan menyelesaikan masalah definisi berubah -ubah yang dihadapi oleh pemula python dalam program lukisan grafik Hourglass. Kod ...
