
 Peranti teknologi
AI
Percepatkan model resapan, jana imej tahap SOTA dalam 1 langkah terpantas, Byte Hyper-SD ialah sumber terbuka
Peranti teknologi
AI
Percepatkan model resapan, jana imej tahap SOTA dalam 1 langkah terpantas, Byte Hyper-SD ialah sumber terbuka
Percepatkan model resapan, jana imej tahap SOTA dalam 1 langkah terpantas, Byte Hyper-SD ialah sumber terbuka

Baru-baru ini, Model Penyebaran telah mencapai kemajuan yang ketara dalam bidang penjanaan imej, membawa peluang pembangunan yang belum pernah berlaku sebelum ini kepada tugas penjanaan imej dan penjanaan video. Walaupun hasil yang mengagumkan, sifat denoising berulang pelbagai langkah yang wujud dalam proses inferens model resapan menghasilkan kos pengiraan yang tinggi. Baru-baru ini, satu siri algoritma penyulingan model resapan telah muncul untuk mempercepatkan proses inferens model resapan. Kaedah-kaedah ini secara kasar boleh dibahagikan kepada dua kategori: i) penyulingan pemuliharaan trajektori; ii) penyulingan pembinaan semula trajektori. Walau bagaimanapun, kedua-dua jenis kaedah ini akan dihadkan oleh siling kesan terhad atau perubahan dalam domain output.
Untuk menyelesaikan masalah ini, pasukan teknikal ByteDance mencadangkan model konsistensi segmentasi trajektori yang dipanggil Hyper-SD. Sumber terbuka Hyper-SD juga telah diiktiraf oleh Ketua Pegawai Eksekutif Huggingface Clem Delangue.
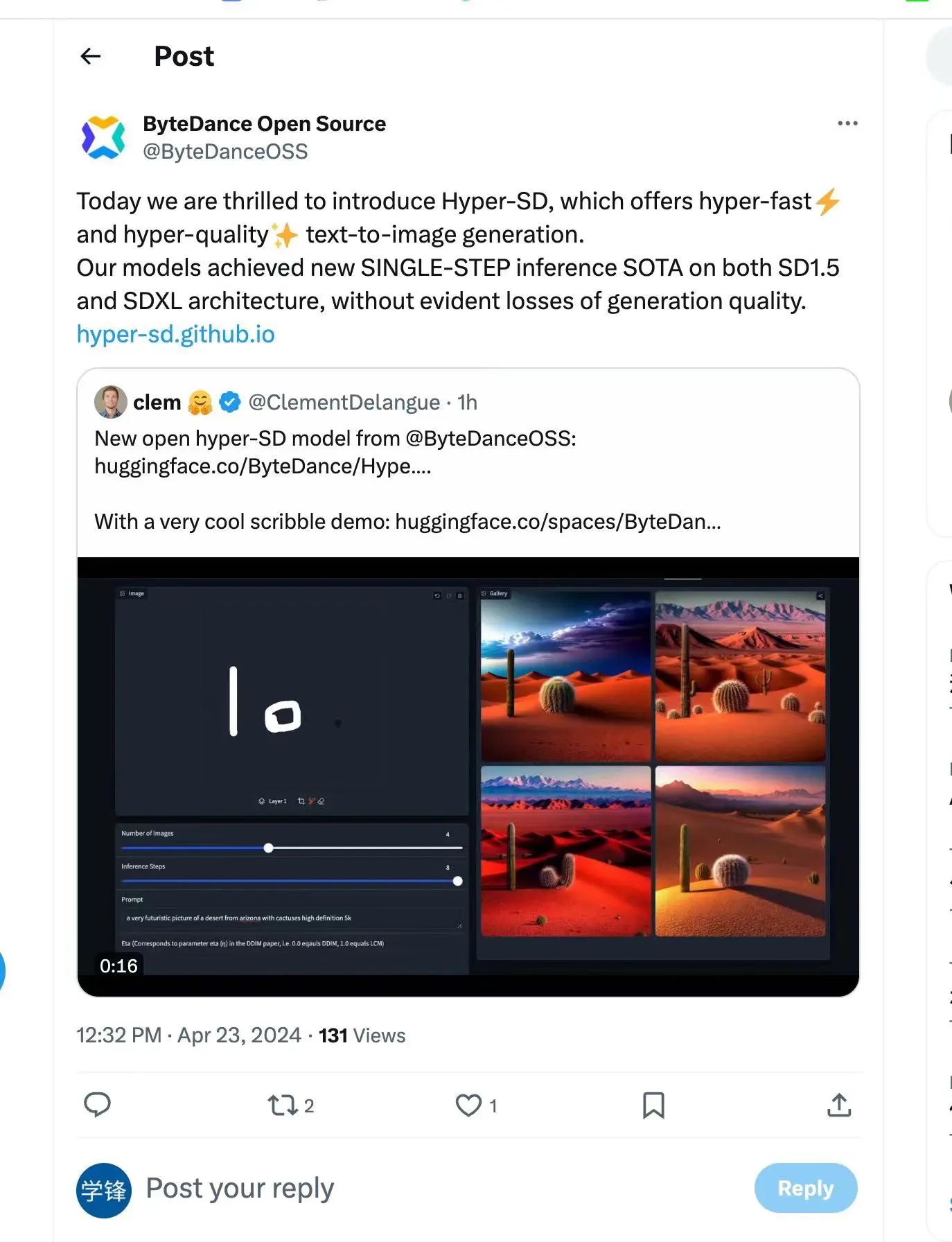
Model ini ialah rangka kerja penyulingan model resapan baru yang menggabungkan kelebihan penyulingan memelihara trajektori dan penyulingan pembinaan semula trajektori untuk memampatkan bilangan langkah denoising sambil mengekalkan prestasi hampir tanpa kerugian. Berbanding dengan algoritma pecutan model resapan sedia ada, kaedah ini mencapai hasil pecutan yang sangat baik. Selepas percubaan yang meluas dan ulasan pengguna, Hyper-SD+ boleh mencapai prestasi penjanaan imej peringkat SOTA dalam 1 hingga 8 langkah pada kedua-dua seni bina SDXL dan SD1.5.

Laman utama projek: https://hyper-sd.github.io/
-
Pautan kertas: https://arxiv.org/abs/2404.13686
/Hugging // /huggingface.co/ByteDance/Hyper-SD - Pautan Demo generasi satu langkah: https://huggingface.co/spaces/ByteDance/Hyper-SDXL-1Step-T2I
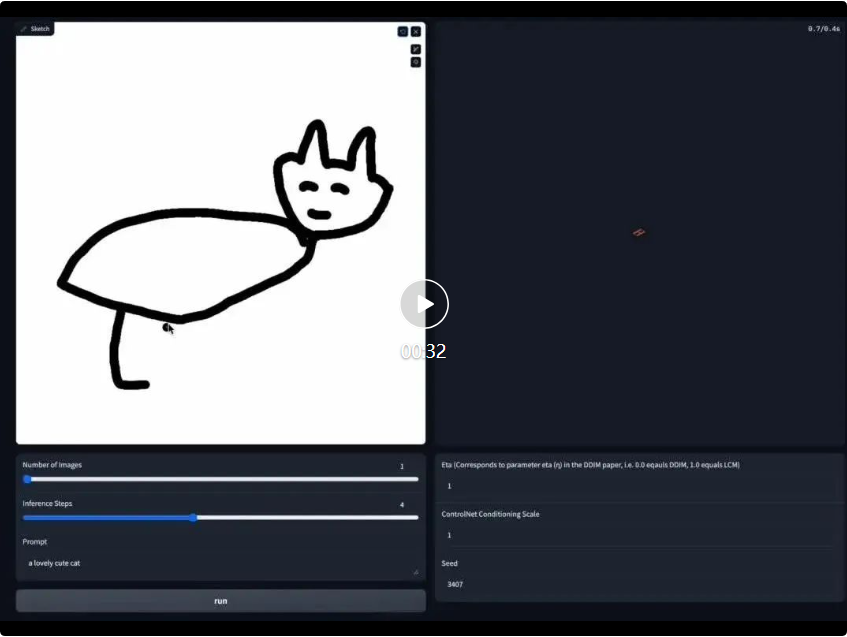
- lukisan masa nyata papan pautan Demo: https: //huggingface.co/spaces/ByteDance/Hyper-SD15-Scribble

Kertas kerja ini mencadangkan model ketekalan segmentasi trajektori (pendek kata Hyper-SD) yang menggabungkan kelebihan strategi pemeliharaan trajektori dan pembinaan semula. Khususnya, algoritma mula-mula memperkenalkan penyulingan konsistensi segmentasi trajektori untuk menguatkuasakan konsistensi dalam setiap segmen dan secara beransur-ansur mengurangkan bilangan segmen untuk mencapai konsistensi sepenuh masa. Strategi ini menyelesaikan masalah prestasi suboptimum model konsisten disebabkan oleh keupayaan pemasangan model yang tidak mencukupi dan pengumpulan ralat inferens. Selepas itu, algoritma menggunakan pembelajaran maklum balas manusia (RLHF) untuk menambah baik kesan penjanaan model bagi mengimbangi kehilangan kesan penjanaan model semasa proses pecutan dan menjadikannya lebih baik disesuaikan dengan penaakulan langkah rendah. Akhir sekali, algoritma menggunakan penyulingan pecahan untuk meningkatkan prestasi penjanaan satu langkah dan mencapai model resapan konsisten langkah sepenuh masa yang ideal melalui LORA bersatu, mencapai keputusan cemerlang dalam kesan penjanaan.
Kaedah1
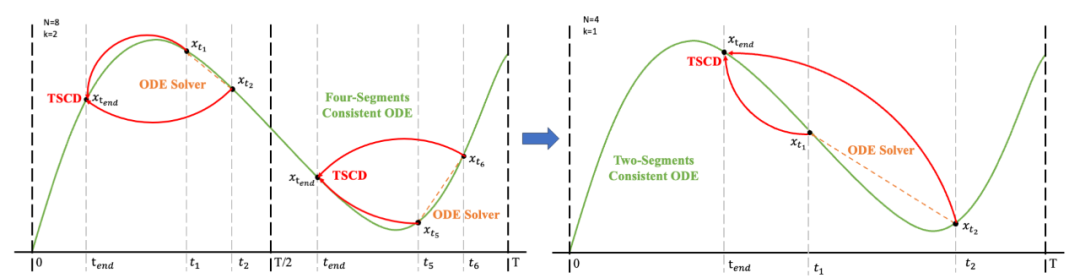
Penyulingan Konsisten (CD) [24] dan Model Trajektori Konsisten (CTM) [4] kedua-duanya bertujuan untuk menukar model resapan kepada model yang konsisten untuk keseluruhan julat langkah masa [0, T] melalui penyulingan satu pukulan. Walau bagaimanapun, model penyulingan ini selalunya gagal mencapai keoptimuman disebabkan oleh batasan dalam keupayaan pemasangan model. Diilhamkan oleh objektif konsistensi lembut yang diperkenalkan dalam CTM, kami memperhalusi proses latihan dengan membahagikan keseluruhan julat langkah masa [0, T] kepada segmen k dan melakukan penyulingan model yang konsisten sekeping demi selangkah.
Pada peringkat pertama, kami menetapkan k=8 dan menggunakan model penyebaran asal untuk memulakan 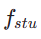 dan
dan 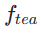 . Langkah masa mula
. Langkah masa mula 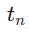 diambil secara seragam secara rawak daripada
diambil secara seragam secara rawak daripada  . Kemudian, kami mengambil contoh langkah masa akhir
. Kemudian, kami mengambil contoh langkah masa akhir 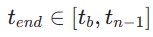 , di mana
, di mana 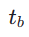 dikira seperti berikut:
dikira seperti berikut:
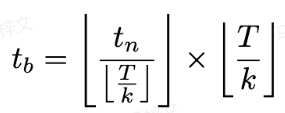
Kehilangan latihan dikira seperti berikut:
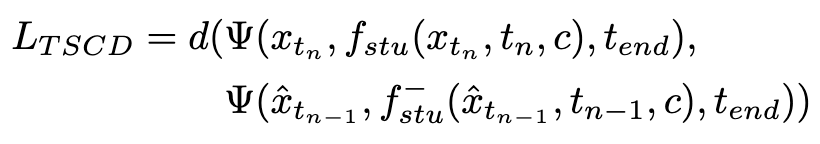
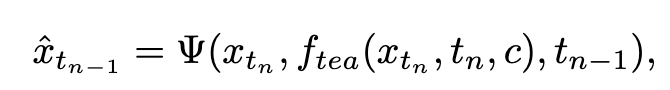
di mana 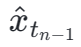
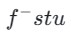 diwakili oleh persamaan 3 dan diwakili oleh persamaan
diwakili oleh persamaan 3 dan diwakili oleh persamaan
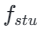 Seterusnya, kami memulihkan berat model dari peringkat sebelumnya dan meneruskan latihan
Seterusnya, kami memulihkan berat model dari peringkat sebelumnya dan meneruskan latihan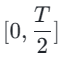 , secara beransur-ansur mengurangkan k kepada [4,2,1]. Perlu diingat bahawa k=1 sepadan dengan skema latihan CTM standard. Untuk metrik jarak d, kami menggunakan campuran kerugian adversarial dan kerugian ralat kuasa dua min (MSE). Dalam eksperimen, kami mendapati bahawa kerugian MSE lebih berkesan apabila nilai ramalan dan sasaran hampir (cth., untuk k=8, 4), manakala kerugian lawan meningkat apabila perbezaan antara nilai ramalan dan sasaran meningkat . menjadi lebih tepat (contohnya, untuk k=2, 1). Oleh itu, kami secara dinamik meningkatkan berat kehilangan lawan dan mengurangkan berat kehilangan MSE sepanjang fasa latihan. Selain itu, kami juga menyepadukan mekanisme gangguan bunyi untuk meningkatkan kestabilan latihan. Ambil proses Penyulingan Konsensus Segmen Trajektori (TSCD) dua peringkat sebagai contoh. Seperti yang ditunjukkan dalam rajah di bawah, kami melakukan penyulingan konsistensi bebas pada peringkat pertama dalam tempoh masa
, secara beransur-ansur mengurangkan k kepada [4,2,1]. Perlu diingat bahawa k=1 sepadan dengan skema latihan CTM standard. Untuk metrik jarak d, kami menggunakan campuran kerugian adversarial dan kerugian ralat kuasa dua min (MSE). Dalam eksperimen, kami mendapati bahawa kerugian MSE lebih berkesan apabila nilai ramalan dan sasaran hampir (cth., untuk k=8, 4), manakala kerugian lawan meningkat apabila perbezaan antara nilai ramalan dan sasaran meningkat . menjadi lebih tepat (contohnya, untuk k=2, 1). Oleh itu, kami secara dinamik meningkatkan berat kehilangan lawan dan mengurangkan berat kehilangan MSE sepanjang fasa latihan. Selain itu, kami juga menyepadukan mekanisme gangguan bunyi untuk meningkatkan kestabilan latihan. Ambil proses Penyulingan Konsensus Segmen Trajektori (TSCD) dua peringkat sebagai contoh. Seperti yang ditunjukkan dalam rajah di bawah, kami melakukan penyulingan konsistensi bebas pada peringkat pertama dalam tempoh masa 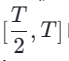 dan
dan

2 Pembelajaran maklum balas manusia
Selain penyulingan, kami menggabungkan pembelajaran maklum balas untuk meningkatkan prestasi model resapan dipercepat. Khususnya, kami meningkatkan kualiti penjanaan model dipercepatkan dengan memanfaatkan maklum balas daripada keutamaan estetik manusia dan model persepsi visual sedia ada. Untuk maklum balas estetik, kami menggunakan peramal estetik LAION dan model ganjaran keutamaan estetik yang disediakan dalam ImageReward untuk membimbing model menjana lebih banyak imej estetik, seperti ditunjukkan di bawah: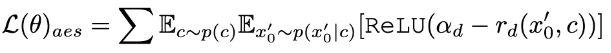
di mana 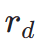 ialah model ganjaran estetik, termasuk peramal estetik set data LAION dan model ImageReward, c ialah gesaan teks,
ialah model ganjaran estetik, termasuk peramal estetik set data LAION dan model ImageReward, c ialah gesaan teks, 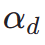 digunakan bersama-sama dengan fungsi ReLU sebagai kehilangan engsel. Selain maklum balas daripada keutamaan estetik, kami ambil perhatian bahawa model persepsi visual sedia ada yang membenamkan pengetahuan terdahulu yang kaya tentang imej juga boleh berfungsi sebagai penyedia maklum balas yang baik. Secara empirik, kami mendapati bahawa model pembahagian contoh boleh membimbing model untuk menjana objek yang berstruktur dengan baik. Khususnya, kami mula-mula meresap hingar pada imej
digunakan bersama-sama dengan fungsi ReLU sebagai kehilangan engsel. Selain maklum balas daripada keutamaan estetik, kami ambil perhatian bahawa model persepsi visual sedia ada yang membenamkan pengetahuan terdahulu yang kaya tentang imej juga boleh berfungsi sebagai penyedia maklum balas yang baik. Secara empirik, kami mendapati bahawa model pembahagian contoh boleh membimbing model untuk menjana objek yang berstruktur dengan baik. Khususnya, kami mula-mula meresap hingar pada imej 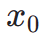 kepada
kepada 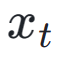 dalam ruang terpendam, selepas itu, serupa dengan ImageReward, kami melakukan denoising berulang sehingga langkah masa tertentu
dalam ruang terpendam, selepas itu, serupa dengan ImageReward, kami melakukan denoising berulang sehingga langkah masa tertentu 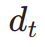 dan meramalkan terus
dan meramalkan terus 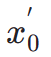 . Selepas itu, kami memanfaatkan model segmentasi contoh persepsi untuk menilai prestasi penjanaan struktur dengan mengkaji perbezaan antara anotasi segmentasi tika untuk imej sebenar dan ramalan segmentasi tika untuk imej terdenois, seperti berikut:
. Selepas itu, kami memanfaatkan model segmentasi contoh persepsi untuk menilai prestasi penjanaan struktur dengan mengkaji perbezaan antara anotasi segmentasi tika untuk imej sebenar dan ramalan segmentasi tika untuk imej terdenois, seperti berikut:
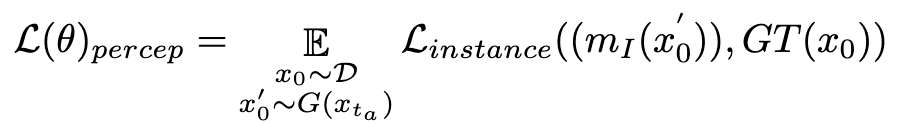
di mana 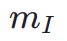 ialah model segmentasi tika (cth. SOLO). Model pembahagian contoh boleh menangkap dengan lebih tepat kecacatan struktur imej yang dijana dan memberikan isyarat maklum balas yang lebih disasarkan. Perlu diingat bahawa sebagai tambahan kepada model segmentasi contoh, model persepsi lain juga boleh digunakan. Model persepsi ini boleh berfungsi sebagai maklum balas pelengkap kepada estetika subjektif, lebih memfokuskan pada kualiti generatif objektif. Oleh itu, model resapan kami yang dioptimumkan dengan isyarat maklum balas boleh ditakrifkan sebagai:
ialah model segmentasi tika (cth. SOLO). Model pembahagian contoh boleh menangkap dengan lebih tepat kecacatan struktur imej yang dijana dan memberikan isyarat maklum balas yang lebih disasarkan. Perlu diingat bahawa sebagai tambahan kepada model segmentasi contoh, model persepsi lain juga boleh digunakan. Model persepsi ini boleh berfungsi sebagai maklum balas pelengkap kepada estetika subjektif, lebih memfokuskan pada kualiti generatif objektif. Oleh itu, model resapan kami yang dioptimumkan dengan isyarat maklum balas boleh ditakrifkan sebagai:
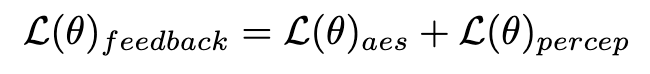
3 Peningkatan penjanaan satu langkah
Disebabkan oleh had yang wujud dalam kehilangan konsistensi, penjanaan satu langkah dalam rangka kerja model ketekalan. ideal. Seperti yang dianalisis dalam CM, model penyulingan konsensus menunjukkan ketepatan yang sangat baik dalam membimbing titik akhir trajektori  pada kedudukan
pada kedudukan  . Oleh itu, penyulingan pecahan adalah kaedah yang sesuai dan berkesan untuk meningkatkan lagi kesan penjanaan satu langkah model TSCD kami. Khususnya, kami memajukan penjanaan lanjut melalui teknik penyulingan padanan agihan (DMD) yang dioptimumkan. DMD meningkatkan output model dengan menggunakan dua fungsi pemarkahan berbeza: pengedaran
. Oleh itu, penyulingan pecahan adalah kaedah yang sesuai dan berkesan untuk meningkatkan lagi kesan penjanaan satu langkah model TSCD kami. Khususnya, kami memajukan penjanaan lanjut melalui teknik penyulingan padanan agihan (DMD) yang dioptimumkan. DMD meningkatkan output model dengan menggunakan dua fungsi pemarkahan berbeza: pengedaran 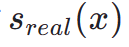 daripada model guru dan
daripada model guru dan 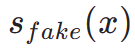 daripada model palsu. Kami menggabungkan kerugian ralat kuasa dua (MSE) dengan penyulingan berasaskan skor untuk meningkatkan kestabilan latihan. Dalam proses ini, teknik pembelajaran maklum balas manusia yang disebutkan di atas juga disepadukan untuk memperhalusi model kami untuk menghasilkan imej dengan kesetiaan tinggi dengan berkesan.
daripada model palsu. Kami menggabungkan kerugian ralat kuasa dua (MSE) dengan penyulingan berasaskan skor untuk meningkatkan kestabilan latihan. Dalam proses ini, teknik pembelajaran maklum balas manusia yang disebutkan di atas juga disepadukan untuk memperhalusi model kami untuk menghasilkan imej dengan kesetiaan tinggi dengan berkesan.
Dengan menyepadukan strategi ini, kaedah kami bukan sahaja mencapai keputusan inferens langkah rendah yang sangat baik pada kedua-dua SD1.5 dan SDXL (dan tidak memerlukan Bimbingan Pengelas), tetapi juga mencapai model ketekalan global yang ideal tanpa memerlukan setiap nombor tertentu. daripada langkah digunakan untuk melatih UNet atau LoRA untuk mencapai model penaakulan langkah rendah bersatu.
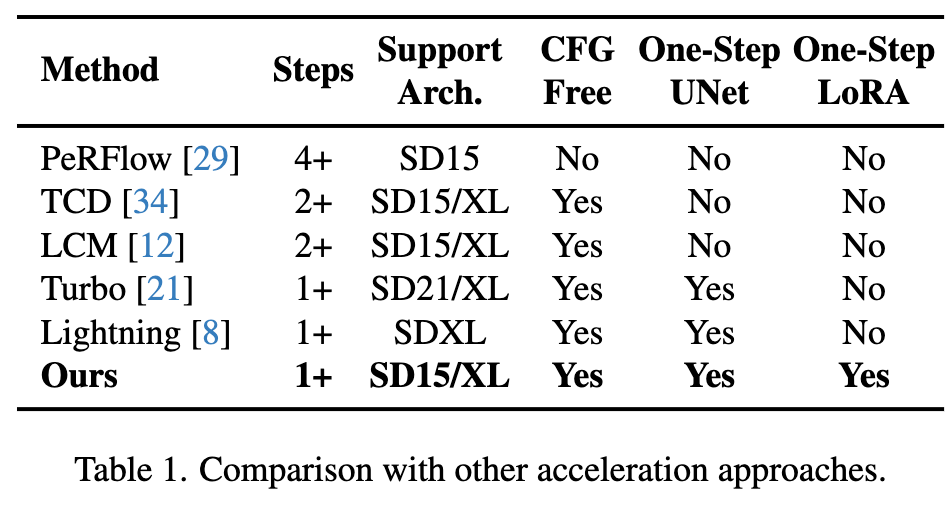
Eksperimen
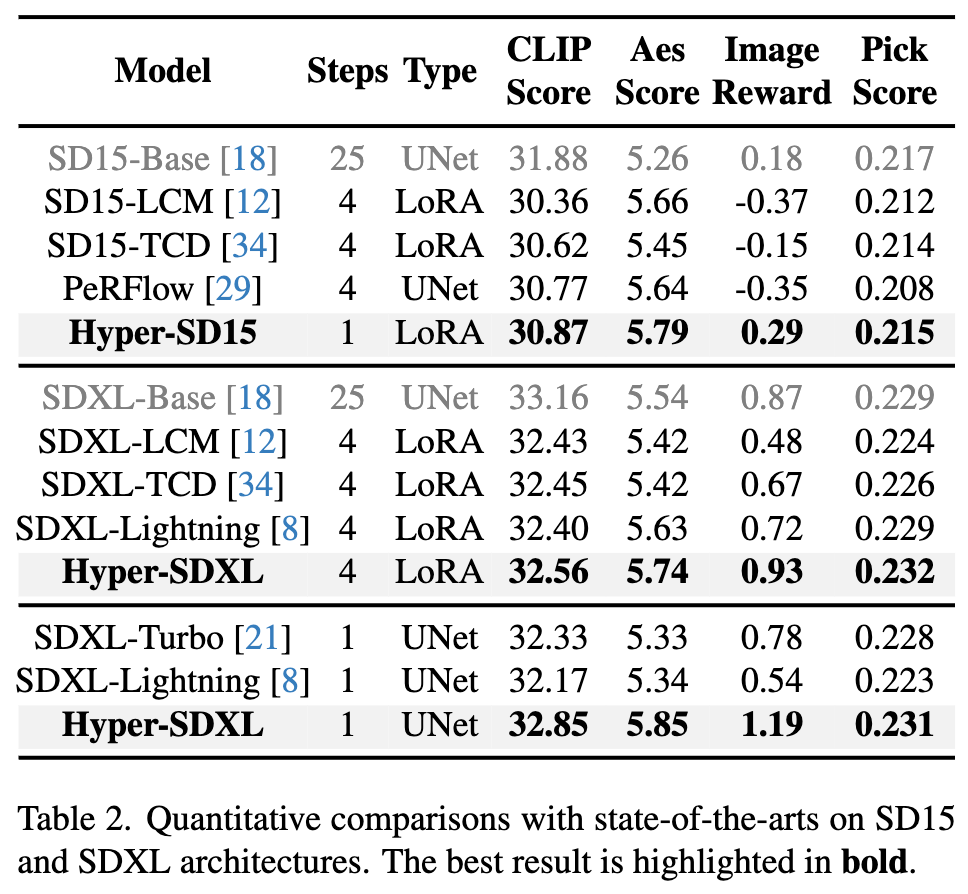
Perbandingan kuantitatif pelbagai algoritma pecutan sedia ada pada SD1.5 dan SDXL, dapat dilihat bahawa Hyper-SD jauh lebih baik daripada kaedah terkini
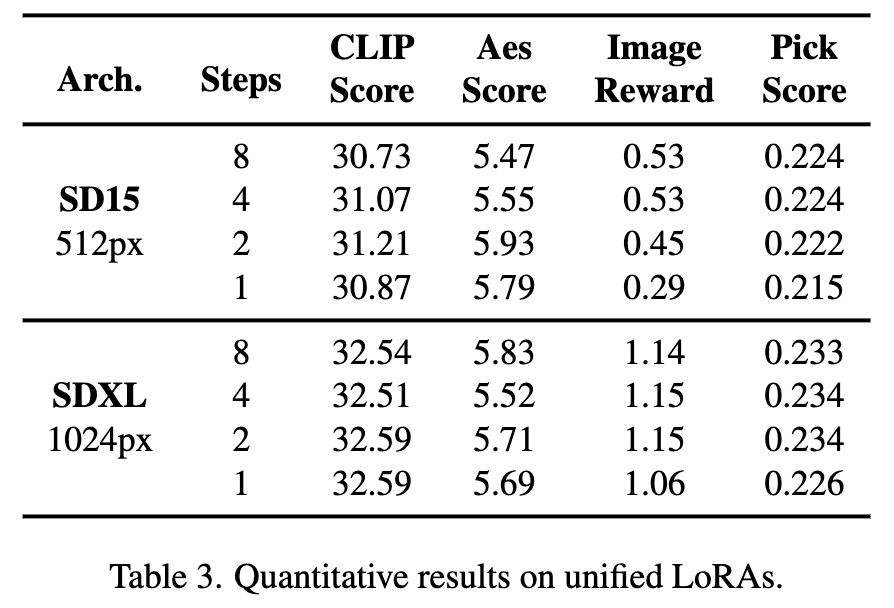
Selain itu, Hyper-SD boleh menggunakan satu model untuk mencapai pelbagai inferens langkah rendah Penunjuk kuantitatif di atas juga menunjukkan kesan kaedah kami apabila menggunakan model bersatu untuk inferens.


Visualisasi kesan pecutan pada SD1.5 dan SDXL secara intuitif menunjukkan keunggulan Hyper-SD dalam mempercepatkan inferens model resapan.
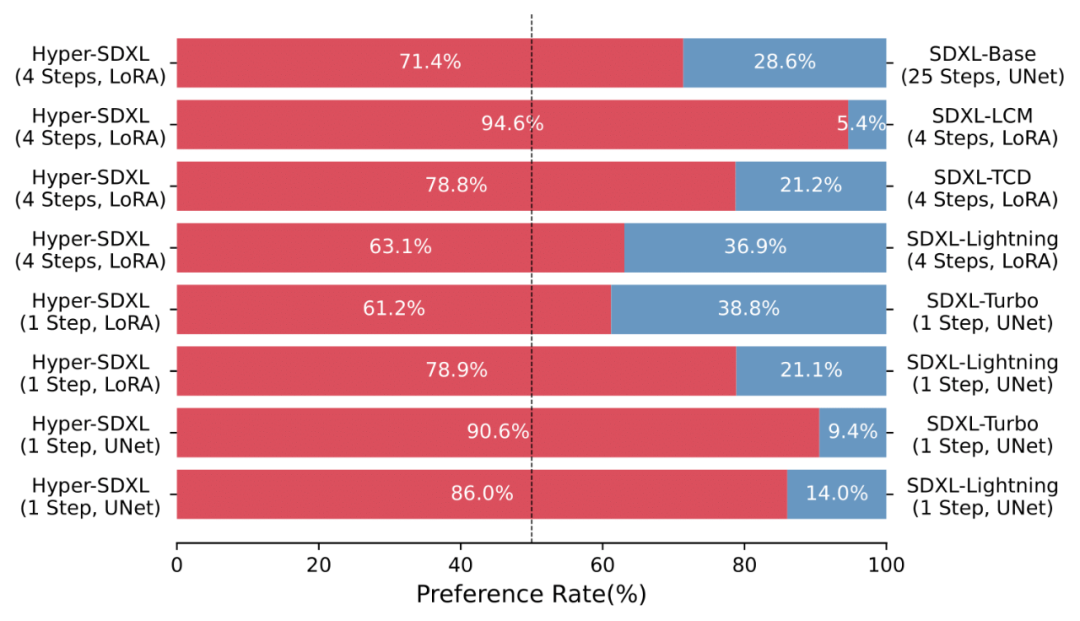
Sebilangan besar Kajian Pengguna juga menunjukkan keunggulan Hyper-SD berbanding pelbagai algoritma pecutan sedia ada.

LoRA dipercepatkan yang dilatih oleh Hyper-SD sangat serasi dengan pelbagai gaya model asas angka Vincent.
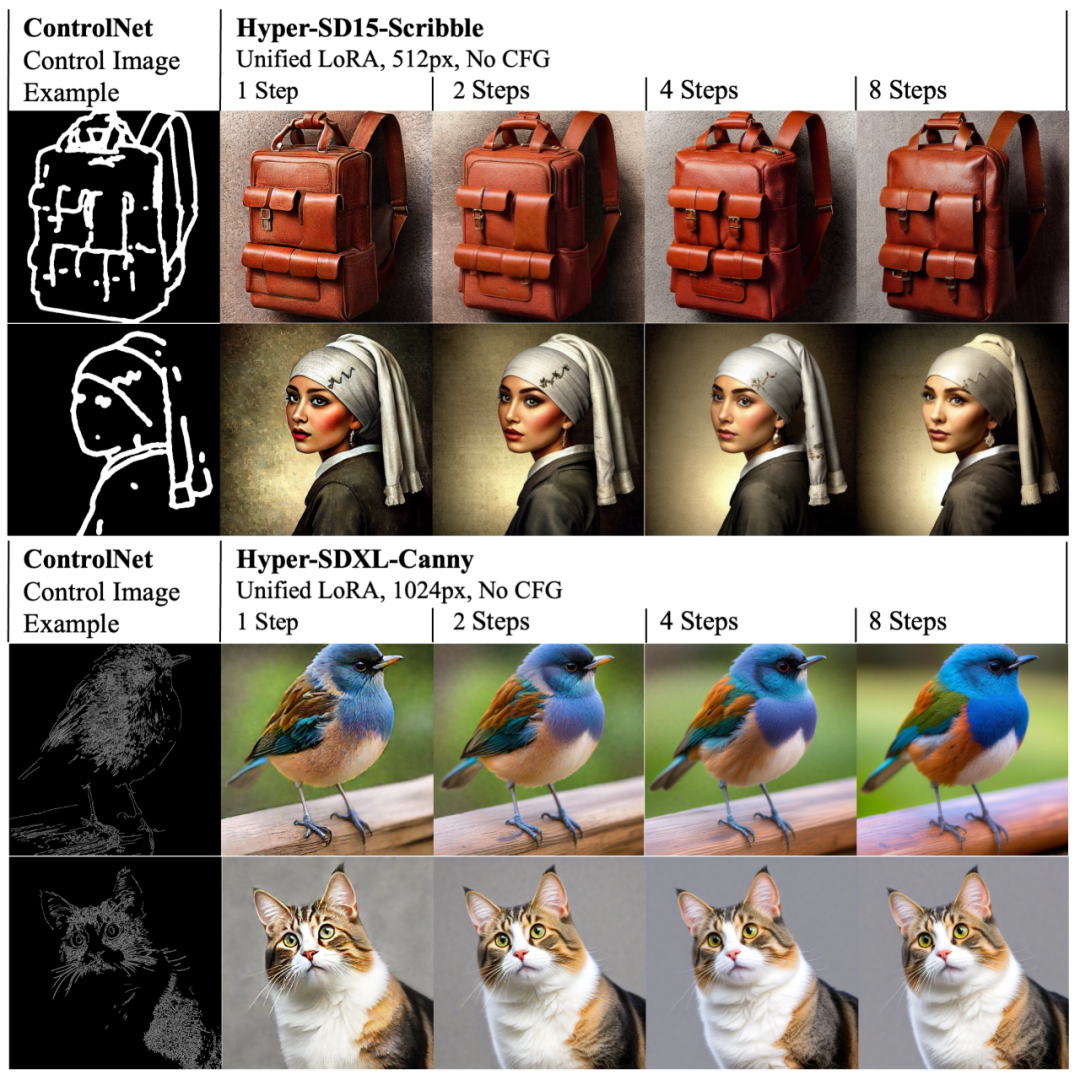
Pada masa yang sama, LoRA Hyper-SD juga boleh menyesuaikan diri dengan ControlNet sedia ada untuk mencapai penjanaan imej terkawal berkualiti tinggi pada bilangan langkah yang rendah.
Ringkasan
Makalah ini mencadangkan Hyper-SD, rangka kerja pecutan model resapan bersatu yang boleh meningkatkan dengan ketara keupayaan penjanaan model resapan dalam situasi langkah rendah dan mencapai prestasi SOTA baharu berdasarkan SDXL dan SD15. Kaedah ini menggunakan penyulingan konsistensi segmentasi trajektori untuk meningkatkan keupayaan pemeliharaan trajektori semasa proses penyulingan dan mencapai kesan penjanaan yang hampir dengan model asal. Kemudian, potensi model pada kiraan langkah yang sangat rendah dipertingkatkan dengan memanfaatkan lagi pembelajaran maklum balas manusia dan penyulingan pecahan variasi, menghasilkan penjanaan model yang lebih optimum dan cekap. Kertas kerja itu juga menggunakan sumber terbuka pemalam Lora untuk SDXL dan SD15 daripada inferens 1 hingga 8 langkah, serta model SDXL satu langkah yang berdedikasi, bertujuan untuk menggalakkan lagi pembangunan komuniti AI generatif.
Atas ialah kandungan terperinci Percepatkan model resapan, jana imej tahap SOTA dalam 1 langkah terpantas, Byte Hyper-SD ialah sumber terbuka. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!

Alat AI Hot

Undresser.AI Undress
Apl berkuasa AI untuk mencipta foto bogel yang realistik

AI Clothes Remover
Alat AI dalam talian untuk mengeluarkan pakaian daripada foto.

Undress AI Tool
Gambar buka pakaian secara percuma

Clothoff.io
Penyingkiran pakaian AI

Video Face Swap
Tukar muka dalam mana-mana video dengan mudah menggunakan alat tukar muka AI percuma kami!

Artikel Panas
Alat panas

Notepad++7.3.1
Editor kod yang mudah digunakan dan percuma

SublimeText3 versi Cina
Versi Cina, sangat mudah digunakan

Hantar Studio 13.0.1
Persekitaran pembangunan bersepadu PHP yang berkuasa

Dreamweaver CS6
Alat pembangunan web visual

SublimeText3 versi Mac
Perisian penyuntingan kod peringkat Tuhan (SublimeText3)
Topik panas
 1676
1676
 14
1429
52
1333
25
1278
29
1257
24
14
1429
52
1333
25
1278
29
1257
24

 Cara memuat turun projek git ke tempatan
Apr 17, 2025 pm 04:36 PM
Cara memuat turun projek git ke tempatan
Apr 17, 2025 pm 04:36 PM
Untuk memuat turun projek secara tempatan melalui Git, ikuti langkah -langkah ini: pasang git. Navigasi ke direktori projek. Pengklonan Repositori Jauh menggunakan arahan berikut: Git Clone https://github.com/username/repository-name.git
 Cara mengemas kini kod dalam git
Apr 17, 2025 pm 04:45 PM
Cara mengemas kini kod dalam git
Apr 17, 2025 pm 04:45 PM
Langkah -langkah untuk mengemas kini kod git: lihat kod: klon git https://github.com/username/repo.git Dapatkan perubahan terkini: Git mengambil Perubahan Gabungan: Git Gabungan Asal/Master Push Change (Pilihan): Git Push Origin Master
 Cara memadam repositori dengan git
Apr 17, 2025 pm 04:03 PM
Cara memadam repositori dengan git
Apr 17, 2025 pm 04:03 PM
Untuk memadam repositori Git, ikuti langkah -langkah ini: Sahkan repositori yang anda mahu padamkan. Penghapusan repositori tempatan: Gunakan perintah RM -RF untuk memadam foldernya. Jauh memadam gudang: Navigasi ke tetapan gudang, cari pilihan "Padam Gudang", dan sahkan operasi.
 Cara mengemas kini kod tempatan di Git
Apr 17, 2025 pm 04:48 PM
Cara mengemas kini kod tempatan di Git
Apr 17, 2025 pm 04:48 PM
Bagaimana cara mengemas kini kod git tempatan? Gunakan Git Fetch untuk menarik perubahan terkini dari repositori jauh. Gabungkan perubahan jauh ke cawangan tempatan menggunakan git gabungan asal/& lt; nama cawangan jauh & gt;. Menyelesaikan konflik yang timbul daripada penggabungan. Gunakan git commit -m "gabungan cawangan & lt; nama cawangan jauh & gt;" untuk menghantar penggabungan dan memohon kemas kini.
 Cara menggabungkan kod dalam git
Apr 17, 2025 pm 04:39 PM
Cara menggabungkan kod dalam git
Apr 17, 2025 pm 04:39 PM
Proses penggabungan kod Git: Tarik perubahan terkini untuk mengelakkan konflik. Beralih ke cawangan yang anda mahu bergabung. Memulakan gabungan, menyatakan cawangan untuk bergabung. Selesaikan gabungan konflik (jika ada). Pementasan dan komit gabungan, memberikan mesej komit.
 Cara menggunakan komitmen git
Apr 17, 2025 pm 03:57 PM
Cara menggunakan komitmen git
Apr 17, 2025 pm 03:57 PM
Git Commit adalah arahan yang merekodkan fail perubahan kepada repositori git untuk menyelamatkan gambar keadaan semasa projek. Cara menggunakannya adalah seperti berikut: Tambahkan perubahan ke kawasan penyimpanan sementara Tulis mesej penyerahan ringkas dan bermaklumat untuk menyimpan dan keluar dari mesej penyerahan untuk melengkapkan penyerahan secara opsyen: Tambahkan tandatangan untuk log penyerahan Git Log untuk melihat kandungan penyerahan
 Apa yang Harus Dilakukan Sekiranya Muat turun Git Tidak Aktif
Apr 17, 2025 pm 04:54 PM
Apa yang Harus Dilakukan Sekiranya Muat turun Git Tidak Aktif
Apr 17, 2025 pm 04:54 PM
Selesaikan: Apabila kelajuan muat turun git perlahan, anda boleh mengambil langkah -langkah berikut: periksa sambungan rangkaian dan cuba menukar kaedah sambungan. Mengoptimumkan Konfigurasi Git: Meningkatkan Saiz Penampan Pos (Git Config-Global Http.PostBuffer 524288000), dan mengurangkan had berkelajuan rendah (git config --global http.lowspeedlimit 1000). Gunakan proksi Git (seperti Git-Proxy atau Git-LFS-Proxy). Cuba gunakan klien Git yang berbeza (seperti sourcetree atau github desktop). Periksa perlindungan kebakaran
 Bagaimana menyelesaikan masalah carian yang cekap dalam projek PHP? Jenis membantu anda mencapainya!
Apr 17, 2025 pm 08:15 PM
Bagaimana menyelesaikan masalah carian yang cekap dalam projek PHP? Jenis membantu anda mencapainya!
Apr 17, 2025 pm 08:15 PM
Apabila membangunkan laman web e-dagang, saya menghadapi masalah yang sukar: bagaimana untuk mencapai fungsi carian yang cekap dalam sejumlah besar data produk? Carian pangkalan data tradisional tidak cekap dan mempunyai pengalaman pengguna yang lemah. Selepas beberapa penyelidikan, saya dapati jenis enjin carian dan menyelesaikan masalah ini melalui PHP pelanggan PHP TypeSense/TypeSense-PHP, yang meningkatkan prestasi carian.
