
 Peranti teknologi
AI
Kuantiti, pemangkasan, penyulingan, apa sebenarnya yang dikatakan slanga model besar ini?
Peranti teknologi
AI
Kuantiti, pemangkasan, penyulingan, apa sebenarnya yang dikatakan slanga model besar ini?
Kuantiti, pemangkasan, penyulingan, apa sebenarnya yang dikatakan slanga model besar ini?

Kuantiti, pemangkasan, penyulingan, jika anda sering memberi perhatian kepada model bahasa yang besar, anda pasti akan melihat kata-kata ini, sukar untuk kita memahami apa yang mereka lakukan, tetapi perkataan ini sangat penting untuk pembangunan model bahasa besar pada peringkat ini. Artikel ini akan membantu anda mengenali mereka dan memahami prinsip mereka.
Mampatan model
Kuantisasi, pemangkasan dan penyulingan sebenarnya adalah teknologi pemampatan model rangkaian saraf umum, bukan eksklusif kepada model bahasa besar.
Kepentingan pemampatan model
Selepas pemampatan, fail model akan menjadi lebih kecil, ruang cakera keras yang digunakan juga akan menjadi lebih kecil, ruang cache yang digunakan semasa memuatkan ke dalam memori atau dipaparkan juga akan menjadi lebih kecil, dan berjalan model juga akan menjadi lebih kecil. Mungkin juga terdapat beberapa peningkatan kelajuan.
Melalui pemampatan, menggunakan model akan menggunakan kurang sumber pengkomputeran, yang boleh meluaskan senario aplikasi model, terutamanya tempat di mana saiz model dan kecekapan pengkomputeran lebih dititikberatkan, seperti telefon mudah alih, peranti terbenam, dsb.
Apakah yang dimampatkan?
Apa yang dimampatkan ialah parameter model.
Anda mungkin pernah mendengar bahawa pembelajaran mesin semasa menggunakan model rangkaian saraf Model rangkaian saraf meniru rangkaian saraf dalam otak manusia.
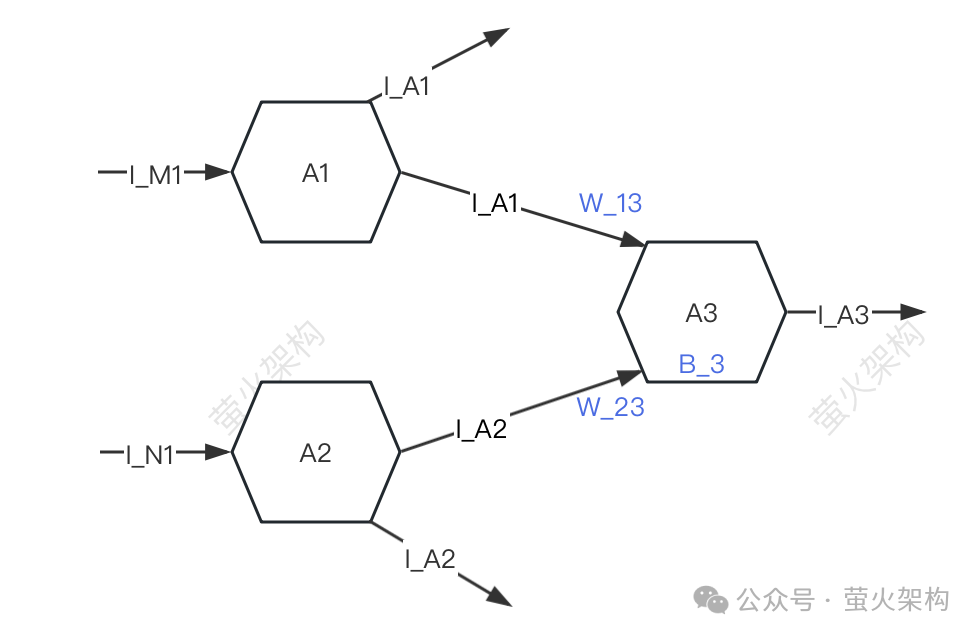
Di sini saya lukis gambar rajah mudah, anda boleh lihat.
 Gambar
Gambar
Untuk kesederhanaan, hanya tiga neuron diterangkan: A1, A2, A3. Setiap neuron menerima isyarat daripada neuron lain dan menghantar isyarat kepada neuron lain.
A3 akan menerima isyarat I_A1 dan I_A2 daripada A1 dan A2, tetapi kekuatan isyarat yang diterima oleh A3 daripada A1 dan A2 adalah berbeza (kekuatan ini dipanggil "berat"). W_23 masing-masing , A3 akan memproses data isyarat yang diterima.
- Mula-mula lakukan penjumlahan wajaran isyarat, iaitu, I_A1*W_13+I_A2*W_23,
- Kemudian tambahkan parameter A3 sendiri B_3, (dipanggil "bias") ini, ditukar kepada bentuk tertentu, dan isyarat yang ditukar dihantar ke neuron seterusnya.
Apabila menggunakan model bahasa yang besar untuk menghasilkan teks, parameter ini sudah dilatih dan kami tidak boleh mengubah suainya seperti pekali polinomial dalam matematik Kami hanya boleh lulus dalam xyz yang tidak diketahui dan mendapatkan hasil Output .
Mampatan model adalah untuk memampatkan parameter model ini Pertimbangan utama adalah berat dan berat sebelah Kaedah khusus yang digunakan ialah kuantisasi, pemangkasan dan penyulingan, yang menjadi tumpuan artikel ini.
Quantization
Quantization adalah untuk mengurangkan ketepatan berangka parameter model Sebagai contoh, pemberat yang dilatih pada mulanya ialah nombor titik terapung 32-bit, tetapi dalam penggunaan sebenar, didapati hampir tiada kerugian jika. dinyatakan dalam 16 bit, tetapi fail model Saiznya dikurangkan separuh, penggunaan memori video dikurangkan separuh, dan keperluan jalur lebar komunikasi antara pemproses dan memori juga dikurangkan, yang bermaksud kos yang lebih rendah dan faedah yang lebih tinggi.
Ia seperti mengikut resipi, anda perlu menentukan berat setiap bahan. Anda boleh menggunakan penimbang elektronik yang sangat tepat iaitu tepat hingga 0.01 gram, yang sangat bagus kerana anda boleh mengetahui berat setiap bahan dengan sangat tepat. Walau bagaimanapun, jika anda hanya membuat hidangan potluck dan sebenarnya tidak memerlukan ketepatan yang tinggi, anda boleh menggunakan skala yang mudah dan murah dengan skala minimum 1 gram, yang tidak seberapa tepat tetapi cukup untuk membuat hidangan yang lazat. makan malam.
Gambar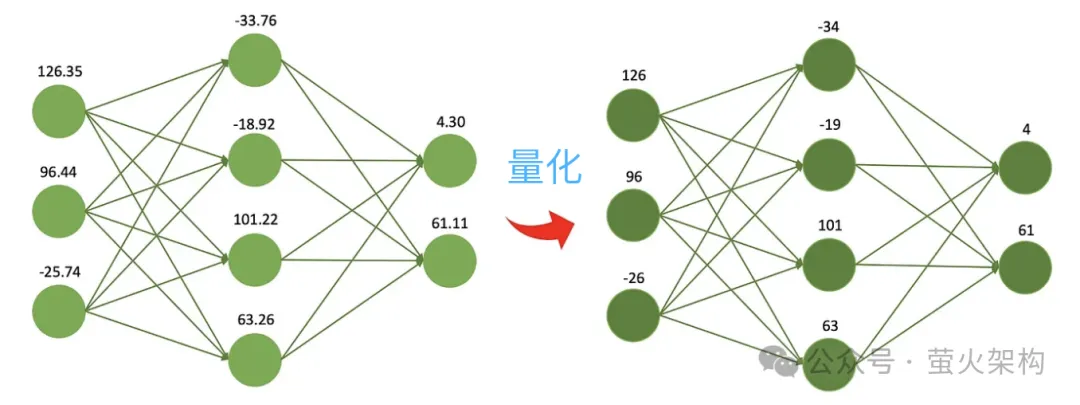
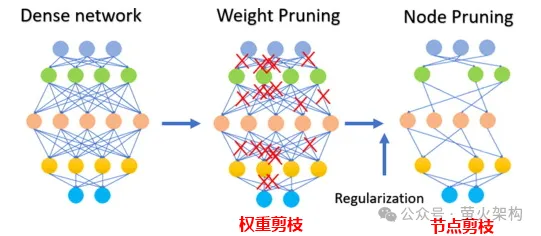
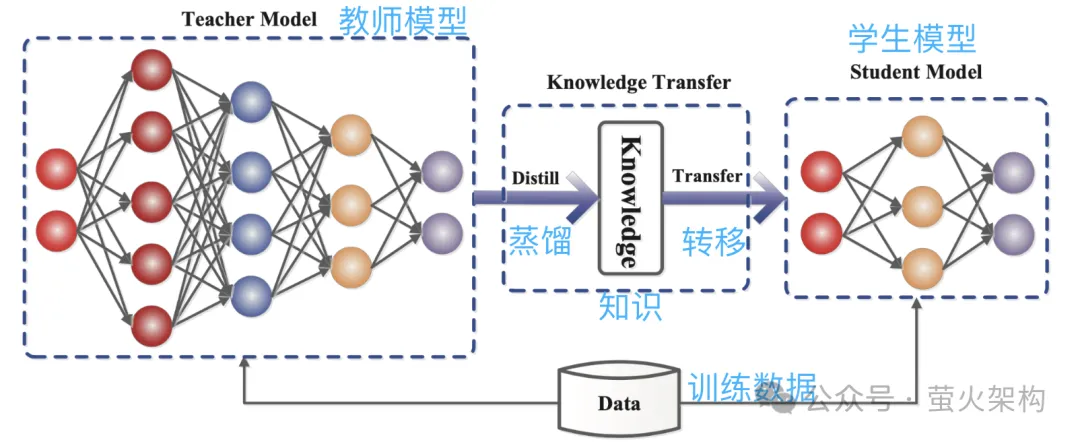
Berikutan idea ini, orang ramai terus memampatkan model 8-bit, 4-bit dan 2-bit, yang bersaiz lebih kecil dan menggunakan kurang sumber pengkomputeran. Walau bagaimanapun, apabila ketepatan pemberat berkurangan, nilai pemberat yang berbeza akan menjadi lebih hampir atau sama, yang akan mengurangkan ketepatan dan ketepatan keluaran model, dan prestasi model akan menurun kepada tahap yang berbeza-beza. Teknologi kuantisasi mempunyai banyak strategi dan butiran teknikal yang berbeza, seperti kuantisasi dinamik, kuantisasi statik, kuantisasi simetri, kuantisasi asimetri, dll. Untuk model bahasa besar, strategi kuantisasi statik biasanya digunakan Selepas latihan model selesai, kami Parameter dikira sekali, dan pengiraan kuantitatif tidak lagi diperlukan apabila model dijalankan, menjadikannya mudah untuk diedarkan dan digunakan. Pemangkasan adalah untuk membuang pemberat yang tidak penting atau jarang digunakan dalam model Nilai pemberat ini secara amnya hampir kepada 0. Bagi sesetengah model, pemangkasan boleh menghasilkan nisbah mampatan yang lebih tinggi, menjadikan model lebih padat dan cekap. Ini amat berguna untuk menggunakan model pada peranti yang dikekang sumber atau apabila memori dan storan terhad. Pemangkasan juga meningkatkan kebolehtafsiran model. Dengan mengalih keluar komponen yang tidak diperlukan, pemangkasan menjadikan struktur asas model lebih telus dan lebih mudah untuk dianalisis. Ini penting untuk memahami proses membuat keputusan model kompleks seperti rangkaian saraf. Pemangkasan bukan sahaja melibatkan parameter berat pemangkasan, tetapi juga pemangkasan nod neuron tertentu, seperti yang ditunjukkan dalam rajah berikut: Perhatikan bahawa pemangkasan tidak sesuai untuk semua model. model (kebanyakan parameter adalah 0 atau hampir dengan 0), pemangkasan mungkin tidak mempunyai kesan; Ia tidak sesuai untuk pemangkasan model, seperti diagnosis perubatan, yang merupakan soal hidup dan mati. Apabila benar-benar menggunakan teknologi pemangkasan, biasanya perlu mempertimbangkan secara menyeluruh peningkatan kelajuan larian model dan kesan negatif pemangkasan ke atas prestasi model, dan menggunakan beberapa strategi, seperti menjaringkan setiap parameter dalam model, iaitu, menilai parameter. Berapa banyak ia menyumbang kepada prestasi model. Mereka yang mempunyai markah tinggi ialah parameter penting yang tidak boleh dipotong; mereka yang mempunyai markah rendah ialah parameter yang mungkin tidak begitu penting dan boleh dipertimbangkan untuk dipotong. Skor ini boleh dikira melalui pelbagai kaedah, seperti melihat saiz parameter (nilai mutlak yang lebih besar biasanya lebih penting), atau ditentukan melalui beberapa kaedah analisis statistik yang lebih kompleks. Penyulingan adalah untuk menyalin terus taburan kebarangkalian yang dipelajari oleh model besar ke dalam model kecil. Model yang disalin dipanggil model guru, yang secara amnya merupakan model yang sangat baik dengan sejumlah besar parameter dan prestasi yang kukuh Model baru dipanggil model pelajar, yang secara amnya merupakan model kecil dengan parameter yang agak sedikit. Semasa penyulingan, model guru akan menjana pengagihan kebarangkalian berbilang output yang mungkin berdasarkan input, dan kemudian model pelajar akan mempelajari pengagihan kebarangkalian input dan output ini. Selepas latihan yang meluas, model pelajar boleh meniru tingkah laku model guru, atau mempelajari pengetahuan model guru. Sebagai contoh, dalam tugas pengelasan imej, diberikan gambar, model guru mungkin mengeluarkan taburan kebarangkalian yang serupa dengan yang berikut: Kemudian serahkan gambar ini dan maklumat taburan kebarangkalian output kepada model pelajar untuk pembelajaran tiruan. Oleh kerana penyulingan memampatkan pengetahuan model guru menjadi model pelajar yang lebih kecil dan mudah, model baharu mungkin kehilangan beberapa maklumat di samping itu, model pelajar mungkin terlalu bergantung pada model guru, menyebabkan model kebolehan generalisasi yang lemah. Untuk menjadikan kesan pembelajaran model pelajar lebih baik, kita boleh mengamalkan beberapa kaedah dan strategi. Memperkenalkan parameter suhu: Andaikata ada guru yang mengajar sangat cepat dan kepadatan maklumat sangat tinggi, mungkin agak sukar untuk diikuti oleh pelajar. Pada masa ini, jika guru memperlahankan dan mempermudahkan maklumat, lebih mudah untuk pelajar memahami. Dalam penyulingan model, parameter suhu memainkan peranan yang serupa dengan "melaraskan kelajuan kuliah" untuk membantu model pelajar (model kecil) lebih memahami dan mempelajari pengetahuan model guru (model besar). Secara profesional, ia adalah untuk menjadikan output model sebagai taburan kebarangkalian yang lebih lancar, menjadikannya lebih mudah bagi model pelajar untuk menangkap dan mempelajari butiran output model guru. Laraskan struktur model guru dan model pelajar: Mungkin sukar untuk pelajar mempelajari sesuatu daripada pakar, kerana jurang pengetahuan antara mereka terlalu besar, dan pembelajaran langsung mungkin tidak faham pada masa ini tambah seorang guru di tengah, yang boleh sama-sama memahami kata-kata pakar dan menterjemahkannya ke dalam bahasa yang boleh difahami oleh pelajar. Guru menambah di tengah mungkin beberapa lapisan perantaraan atau rangkaian saraf tambahan, atau guru boleh membuat beberapa pelarasan pada model pelajar supaya ia dapat memadankan dengan lebih baik output model guru. Kami telah memperkenalkan tiga teknologi pemampatan model utama di atas Sebenarnya, masih terdapat banyak butiran di sini, tetapi ia hampir cukup untuk memahami prinsip Terdapat juga teknologi pemampatan model lain, seperti penguraian peringkat rendah dan perkongsian parameter , sambungan jarang, dsb. Pelajar yang berminat boleh menyemak lebih banyak kandungan yang berkaitan. Selain itu, selepas model dimampatkan, prestasinya mungkin menurun dengan ketara Pada masa ini, kita boleh membuat beberapa penalaan halus model, terutamanya untuk tugas yang memerlukan ketepatan model yang tinggi, seperti diagnosis perubatan, risiko kewangan. kawalan, dan automatik Untuk pemanduan, dsb., penalaan halus boleh memulihkan prestasi model pada tahap tertentu dan menstabilkan ketepatan dan ketepatannya dalam aspek tertentu. Bercakap tentang penalaan halus model, saya baru-baru ini telah berkongsi imej WebUI Penjanaan Teks pada AutoDL Penjanaan Teks WebUI ialah program web yang ditulis menggunakan Gradio, yang boleh melakukan inferens dan penalaan halus model bahasa besar dan sokongan. pelbagai Jenis model bahasa besar, termasuk Transformers, llama.cpp (GGUF), GPTQ, AWQ, EXL2 dan model lain dalam pelbagai format Dalam imej terkini, saya telah terbina dalam model besar Llama3 yang bersumberkan Meta . Pelajar yang berminat Anda boleh mencubanya, dan lihat cara menggunakannya: Belajar memperhalusi model bahasa yang besar dalam masa sepuluh minit Artikel rujukan: //www.php.cn/link/d7852cd2408d9d3205dc75b59 a6ce22e https://www.php.cn/link/f204aab71691a8e18c3d https://www.php.cn/link/b31f0c758bb498b5d56b5fea80 f313a7Pemangkasan
 Gambar
GambarPenyulingan
 Gambar
Gambar Gambar
Gambar
Atas ialah kandungan terperinci Kuantiti, pemangkasan, penyulingan, apa sebenarnya yang dikatakan slanga model besar ini?. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!

Alat AI Hot

Undresser.AI Undress
Apl berkuasa AI untuk mencipta foto bogel yang realistik

AI Clothes Remover
Alat AI dalam talian untuk mengeluarkan pakaian daripada foto.

Undress AI Tool
Gambar buka pakaian secara percuma

Clothoff.io
Penyingkiran pakaian AI

AI Hentai Generator
Menjana ai hentai secara percuma.

Artikel Panas
Alat panas

Notepad++7.3.1
Editor kod yang mudah digunakan dan percuma

SublimeText3 versi Cina
Versi Cina, sangat mudah digunakan

Hantar Studio 13.0.1
Persekitaran pembangunan bersepadu PHP yang berkuasa

Dreamweaver CS6
Alat pembangunan web visual

SublimeText3 versi Mac
Perisian penyuntingan kod peringkat Tuhan (SublimeText3)
Topik panas
 1376
1376
 52
52

 Apr 09, 2024 am 08:34 AM
Apr 09, 2024 am 08:34 AM
Ramai rakan menggunakan perisian Meituan Xiuxiu untuk P-picture, tetapi bagaimana untuk mengekalkan kualiti asal gambar apabila menyimpannya selepas P-picture? Kaedah operasi dibawakan kepada anda di bawah Kawan-kawan yang berminat boleh lihat dengan saya. Selepas membuka APP Meitu Xiu Xiu pada telefon mudah alih anda, klik "Saya" di penjuru kanan sebelah bawah halaman untuk masuk, dan kemudian klik ikon heksagon di penjuru kanan sebelah atas halaman Saya untuk membukanya. 2. Selepas datang ke halaman tetapan, cari "Umum" dan klik pada item ini untuk masuk. 3. Seterusnya, terdapat "Kualiti Gambar" pada halaman umum Klik anak panah di belakangnya untuk memasuki tetapan. 4. Akhir sekali, selepas memasuki antara muka tetapan kualiti imej, anda akan melihat garis mendatar di bahagian bawah Klik peluncur bulat pada garisan mendatar dan seret ke kanan ke 100. Apabila anda menyimpan gambar selepas mengedit, ia akan menjadi. kualiti gambar asal.
 Model MoE sumber terbuka paling berkuasa di dunia ada di sini, dengan keupayaan bahasa Cina setanding dengan GPT-4, dan harganya hanya hampir satu peratus daripada GPT-4-Turbo
May 07, 2024 pm 04:13 PM
Model MoE sumber terbuka paling berkuasa di dunia ada di sini, dengan keupayaan bahasa Cina setanding dengan GPT-4, dan harganya hanya hampir satu peratus daripada GPT-4-Turbo
May 07, 2024 pm 04:13 PM
Bayangkan model kecerdasan buatan yang bukan sahaja mempunyai keupayaan untuk mengatasi pengkomputeran tradisional, tetapi juga mencapai prestasi yang lebih cekap pada kos yang lebih rendah. Ini bukan fiksyen sains, DeepSeek-V2[1], model MoE sumber terbuka paling berkuasa di dunia ada di sini. DeepSeek-V2 ialah gabungan model bahasa pakar (MoE) yang berkuasa dengan ciri-ciri latihan ekonomi dan inferens yang cekap. Ia terdiri daripada 236B parameter, 21B daripadanya digunakan untuk mengaktifkan setiap penanda. Berbanding dengan DeepSeek67B, DeepSeek-V2 mempunyai prestasi yang lebih kukuh, sambil menjimatkan 42.5% kos latihan, mengurangkan cache KV sebanyak 93.3% dan meningkatkan daya pemprosesan penjanaan maksimum kepada 5.76 kali. DeepSeek ialah sebuah syarikat yang meneroka kecerdasan buatan am
 Hello, Atlas elektrik! Robot Boston Dynamics hidup semula, gerakan pelik 180 darjah menakutkan Musk
Apr 18, 2024 pm 07:58 PM
Hello, Atlas elektrik! Robot Boston Dynamics hidup semula, gerakan pelik 180 darjah menakutkan Musk
Apr 18, 2024 pm 07:58 PM
Boston Dynamics Atlas secara rasmi memasuki era robot elektrik! Semalam, Atlas hidraulik hanya "menangis" menarik diri daripada peringkat sejarah Hari ini, Boston Dynamics mengumumkan bahawa Atlas elektrik sedang berfungsi. Nampaknya dalam bidang robot humanoid komersial, Boston Dynamics berazam untuk bersaing dengan Tesla. Selepas video baharu itu dikeluarkan, ia telah pun ditonton oleh lebih sejuta orang dalam masa sepuluh jam sahaja. Orang lama pergi dan peranan baru muncul. Ini adalah keperluan sejarah. Tidak dinafikan bahawa tahun ini adalah tahun letupan robot humanoid. Netizen mengulas: Kemajuan robot telah menjadikan majlis pembukaan tahun ini kelihatan seperti manusia, dan tahap kebebasan adalah jauh lebih besar daripada manusia Tetapi adakah ini benar-benar bukan filem seram? Pada permulaan video, Atlas berbaring dengan tenang di atas tanah, seolah-olah terlentang. Apa yang berikut adalah rahang-jatuh
 KAN, yang menggantikan MLP, telah diperluaskan kepada konvolusi oleh projek sumber terbuka
Jun 01, 2024 pm 10:03 PM
KAN, yang menggantikan MLP, telah diperluaskan kepada konvolusi oleh projek sumber terbuka
Jun 01, 2024 pm 10:03 PM
Awal bulan ini, penyelidik dari MIT dan institusi lain mencadangkan alternatif yang sangat menjanjikan kepada MLP - KAN. KAN mengatasi MLP dari segi ketepatan dan kebolehtafsiran. Dan ia boleh mengatasi prestasi MLP berjalan dengan bilangan parameter yang lebih besar dengan bilangan parameter yang sangat kecil. Sebagai contoh, penulis menyatakan bahawa mereka menggunakan KAN untuk menghasilkan semula keputusan DeepMind dengan rangkaian yang lebih kecil dan tahap automasi yang lebih tinggi. Khususnya, MLP DeepMind mempunyai kira-kira 300,000 parameter, manakala KAN hanya mempunyai kira-kira 200 parameter. KAN mempunyai asas matematik yang kukuh seperti MLP berdasarkan teorem penghampiran universal, manakala KAN berdasarkan teorem perwakilan Kolmogorov-Arnold. Seperti yang ditunjukkan dalam rajah di bawah, KAN telah
 Apr 09, 2024 am 11:52 AM
Apr 09, 2024 am 11:52 AM
AI memang mengubah matematik. Baru-baru ini, Tao Zhexuan, yang telah mengambil perhatian terhadap isu ini, telah memajukan keluaran terbaru "Buletin Persatuan Matematik Amerika" (Buletin Persatuan Matematik Amerika). Memfokuskan pada topik "Adakah mesin akan mengubah matematik?", ramai ahli matematik menyatakan pendapat mereka Seluruh proses itu penuh dengan percikan api, tegar dan menarik. Penulis mempunyai barisan yang kuat, termasuk pemenang Fields Medal Akshay Venkatesh, ahli matematik China Zheng Lejun, saintis komputer NYU Ernest Davis dan ramai lagi sarjana terkenal dalam industri. Dunia AI telah berubah secara mendadak Anda tahu, banyak artikel ini telah dihantar setahun yang lalu.
 Google gembira: prestasi JAX mengatasi Pytorch dan TensorFlow! Ia mungkin menjadi pilihan terpantas untuk latihan inferens GPU
Apr 01, 2024 pm 07:46 PM
Google gembira: prestasi JAX mengatasi Pytorch dan TensorFlow! Ia mungkin menjadi pilihan terpantas untuk latihan inferens GPU
Apr 01, 2024 pm 07:46 PM
Prestasi JAX, yang dipromosikan oleh Google, telah mengatasi Pytorch dan TensorFlow dalam ujian penanda aras baru-baru ini, menduduki tempat pertama dalam 7 penunjuk. Dan ujian tidak dilakukan pada TPU dengan prestasi JAX terbaik. Walaupun dalam kalangan pembangun, Pytorch masih lebih popular daripada Tensorflow. Tetapi pada masa hadapan, mungkin lebih banyak model besar akan dilatih dan dijalankan berdasarkan platform JAX. Model Baru-baru ini, pasukan Keras menanda aras tiga hujung belakang (TensorFlow, JAX, PyTorch) dengan pelaksanaan PyTorch asli dan Keras2 dengan TensorFlow. Pertama, mereka memilih satu set arus perdana
 cURL vs. wget: Mana satu lebih baik untuk anda?
May 07, 2024 am 09:04 AM
cURL vs. wget: Mana satu lebih baik untuk anda?
May 07, 2024 am 09:04 AM
Apabila anda ingin memuat turun fail terus melalui baris arahan Linux, dua alat segera terlintas di fikiran: wget dan cURL. Mereka mempunyai banyak ciri yang sama dan boleh menyelesaikan beberapa tugas yang sama dengan mudah Walaupun mereka mempunyai beberapa ciri yang serupa, mereka tidak betul-betul sama. Kedua-dua program ini sesuai untuk situasi yang berbeza dan mempunyai ciri tersendiri dalam situasi tertentu. cURL vs wget: Persamaan Kedua-dua wget dan cURL boleh memuat turun kandungan. Ini adalah bagaimana mereka direka pada teras mereka. Kedua-duanya boleh menghantar permintaan ke Internet dan memulangkan item yang diminta. Ini boleh menjadi fail, imej atau sesuatu yang lain seperti HTML mentah tapak web. Kedua-dua program boleh membuat permintaan HTTPPOST. Ini bermakna mereka semua boleh menghantar
 Robot Tesla bekerja di kilang, Musk: Tahap kebebasan tangan akan mencapai 22 tahun ini!
May 06, 2024 pm 04:13 PM
Robot Tesla bekerja di kilang, Musk: Tahap kebebasan tangan akan mencapai 22 tahun ini!
May 06, 2024 pm 04:13 PM
Video terbaru robot Tesla Optimus dikeluarkan, dan ia sudah boleh berfungsi di kilang. Pada kelajuan biasa, ia mengisih bateri (bateri 4680 Tesla) seperti ini: Pegawai itu juga mengeluarkan rupanya pada kelajuan 20x - pada "stesen kerja" kecil, memilih dan memilih dan memilih: Kali ini ia dikeluarkan Salah satu sorotan video itu ialah Optimus menyelesaikan kerja ini di kilang, sepenuhnya secara autonomi, tanpa campur tangan manusia sepanjang proses. Dan dari perspektif Optimus, ia juga boleh mengambil dan meletakkan bateri yang bengkok, memfokuskan pada pembetulan ralat automatik: Berkenaan tangan Optimus, saintis NVIDIA Jim Fan memberikan penilaian yang tinggi: Tangan Optimus adalah robot lima jari di dunia paling cerdik. Tangannya bukan sahaja boleh disentuh
