
 Peranti teknologi
AI
Prestasi pengkuantitian bit rendah Llama 3 menurun dengan ketara! Keputusan penilaian komprehensif ada di sini |
Peranti teknologi
AI
Prestasi pengkuantitian bit rendah Llama 3 menurun dengan ketara! Keputusan penilaian komprehensif ada di sini |
Prestasi pengkuantitian bit rendah Llama 3 menurun dengan ketara! Keputusan penilaian komprehensif ada di sini |

Kuasa model besar menjadikan LLaMA3 mencapai tahap yang lebih tinggi:
Pada data Token 15T+ yang telah dilatih secara besar-besaran, peningkatan prestasi yang mengagumkan telah dicapai, dan ia sekali lagi meledak kerana ia jauh melebihi yang disyorkan jumlah perbincangan komuniti sumber terbuka Chinchilla.
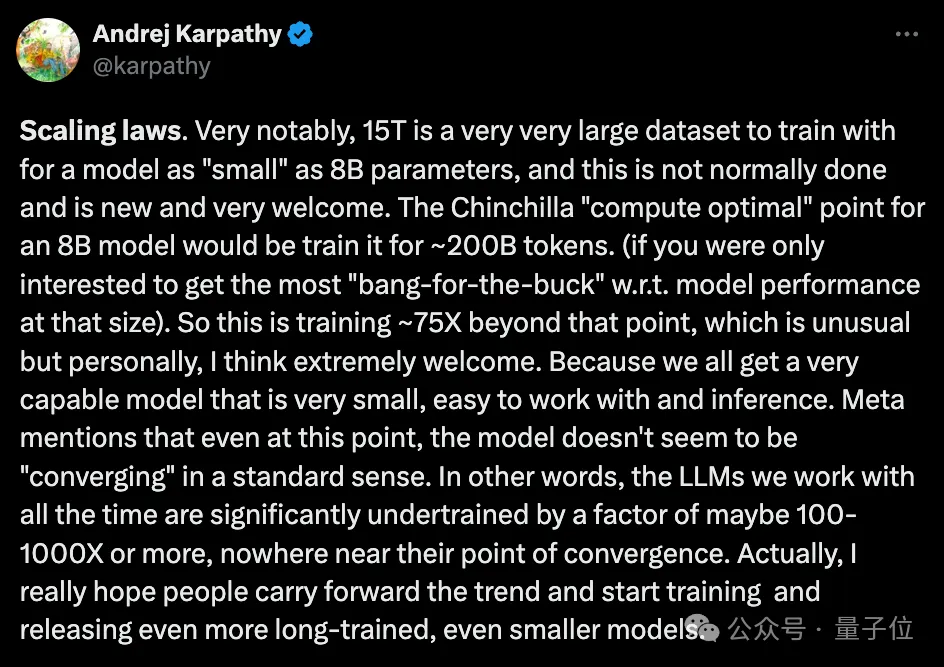
Pada masa yang sama, di peringkat aplikasi praktikal, satu lagi topik hangat turut muncul:
Apakah prestasi kuantitatif LLaMA3 dalam senario dengan sumber terhad?
Universiti Hong Kong, Universiti Beihang dan Institut Teknologi Persekutuan Zurich bersama-sama melancarkan kajian empirikal yang mendedahkan sepenuhnya keupayaan pengkuantitian bit rendah LLaMA3.

Para penyelidik menilai keputusan LLaMA3 dengan 1-8 bit dan pelbagai set data penilaian menggunakan 10 kaedah penalaan halus LoRA terkuantiti pasca latihan sedia ada. Mereka mendapati:
Walaupun prestasinya yang mengagumkan, LLaMA3 masih mengalami degradasi yang tidak boleh diabaikan pada pengkuantitian bit rendah, terutamanya pada lebar bit ultra rendah.

Projek ini telah menjadi sumber terbuka pada GitHub, dan model kuantitatif juga telah dilancarkan pada HuggingFace.
Mari kita lihat keputusan empirikal secara khusus.
Track 1: Kuantisasi selepas latihan
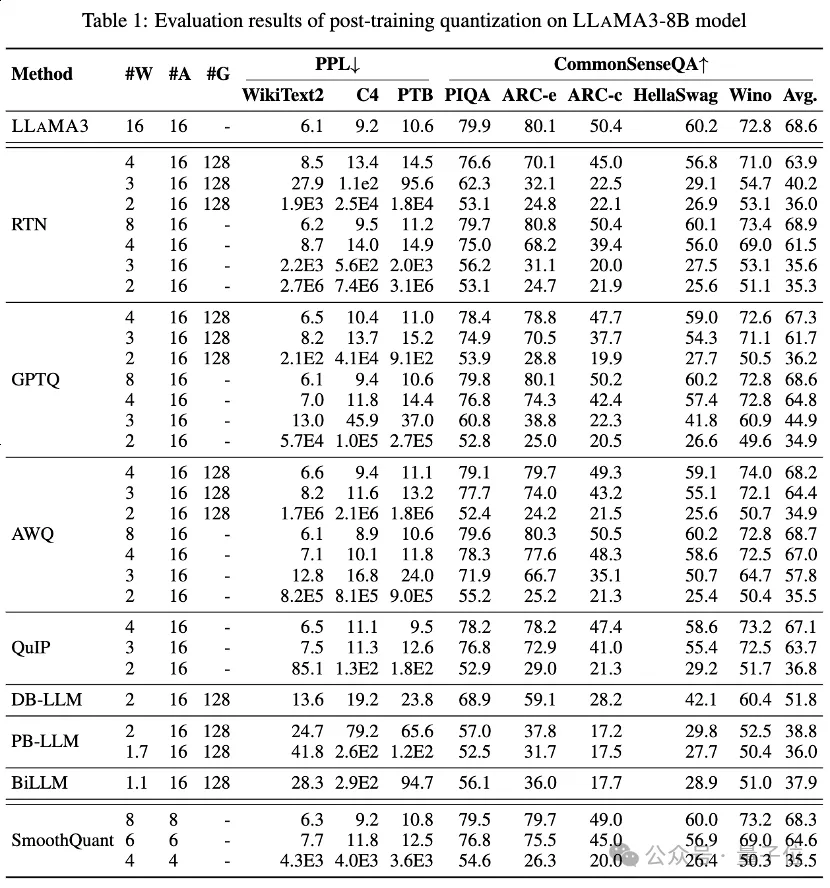
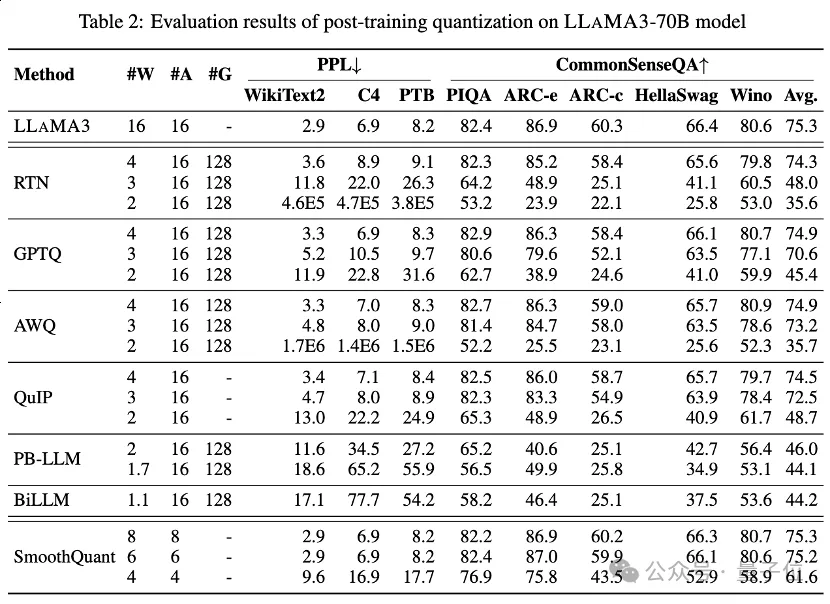
Jadual 1 dan Jadual 2 memberikan prestasi bit rendah LLaMA3-8B dan LLaMA3-70B di bawah 8 kaedah PTQ yang berbeza, meliputi julat luas daripada 1 bit hingga 8 bit Lebar bit.
1. Low-bit privilege weight
Antaranya, Round-To-Nearest (RTN) ialah kaedah pengkuantitian asas.
GPTQ ialah salah satu kaedah pengkuantitian berat sahaja yang paling cekap dan berkesan pada masa ini, yang mengeksploitasikan pampasan ralat dalam pengkuantitian. Tetapi pada 2-3 bit, GPTQ menyebabkan ketepatan yang teruk runtuh apabila mengkuantifikasi LLaMA3.
AWQ menggunakan kaedah penindasan saluran yang tidak normal untuk mengurangkan kesukaran pengkuantitian berat, manakala QuIP memastikan ketidakkonsistenan antara pemberat dan Hessian dengan mengoptimumkan pengiraan matriks. Kesemuanya mengekalkan keupayaan LLaMA3 pada 3 bit dan juga menolak pengkuantitian 2-bit ke tahap yang menjanjikan.
2. Mampatan berat LLM lebar bit ultra-rendah
Kaedah pengkuantitian LLM binari yang baru muncul mencapai pemampatan berat LLM lebar bit ultra rendah.
PB-LLM mengguna pakai strategi pengkuantitian ketepatan campuran untuk mengekalkan ketepatan penuh sebahagian kecil pemberat penting sambil mengkuantisasi kebanyakan pemberat menjadi 1 bit.
DB-LLM mencapai pemampatan LLM yang cekap melalui pembahagian berat perduaan dua, dan mencadangkan strategi penyulingan sedar berat sebelah untuk meningkatkan lagi prestasi LLM 2-bit.
BiLLM terus menolak sempadan pengkuantitian LLM ke bawah kepada 1.1 bit melalui anggaran baki pemberat ketara dan pengkuantitian berkumpulan bagi pemberat tidak ketara. Kaedah pengkuantitian LLM ini yang direka khusus untuk lebar bit ultra rendah boleh mencapai pengkuantitian ketepatan yang lebih tinggi LLaMA3-8B, pada ⩽2 bit jauh melebihi kaedah seperti GPTQ, AWQ dan QuIP pada 2 bit (dan juga dalam beberapa kes 3 bit).
3. Pengaktifan terkuantisasi bit rendah
juga melakukan penilaian LLaMA3 ke atas pengaktifan terkuantisasi melalui SmoothQuant, yang memindahkan kesukaran pengkuantitian daripada pengaktifan kepada pemberat untuk melancarkan outlier pengaktifan. Penilaian menunjukkan bahawa SmoothQuant boleh mengekalkan ketepatan LLaMA3 pada pemberat dan pengaktifan 8-bit dan 6-bit, tetapi muka runtuh pada 4-bit.
Lagu 2: Kuantiti diperhalusi LoRA
Pada set data MMLU, untuk LLaMA3-8B di bawah kuantisasi LoRA-FT, pemerhatian yang paling menarik ialah penalaan halus peringkat rendah pada set data Alpaca bukan sahaja gagal mengimbangi pengkuantitian Pepijat yang diperkenalkan menjadikan kemerosotan prestasi lebih teruk.
Secara khusus, prestasi LLaMA3 terkuantasi yang diperolehi oleh pelbagai kaedah pengkuantitian LoRA-FT pada 4 bit adalah lebih teruk daripada versi sepadan 4-bit tanpa LoRA-FT. Ini berbeza dengan fenomena serupa pada LLaMA1 dan LLaMA2, di mana versi pengkuantitian diperhalusi peringkat rendah 4-bit malah dengan mudah mengatasi prestasi rakan sejawatan FP16 pada MMLU.
Menurut analisis intuitif, sebab utama fenomena ini ialah prestasi hebat LLaMA3 mendapat manfaat daripada pra-latihan berskala besar, yang bermaksud kehilangan prestasi selepas pengkuantitian model asal tidak boleh dilakukan pada set kecil data parameter peringkat rendah Penalaan halus untuk mengimbangi (ini boleh dianggap sebagai subset model asal).
Walaupun kemerosotan ketara yang disebabkan oleh pengkuantitian tidak dapat dikompensasikan dengan penalaan halus, LLaMA3-8B terkuantasi LoRA-FT 4-bit dengan ketara mengatasi prestasi LLaMA1-7B dan LLaMA2-7B di bawah pelbagai kaedah pengkuantitian. Contohnya, menggunakan kaedah QLoRA, ketepatan purata 4-bit LLaMA3-8B ialah 57.0 (FP16: 64.8), yang melebihi 38.4 daripada 4-bit LLaMA1-7B (FP16: 34.6) sebanyak 18.6 dan melebihi 43.9 daripada 4-bit LLaMA2-7B (FP16: 45.5 ) 13.1. Ini menunjukkan keperluan untuk paradigma pengkuantitian LoRA-FT baharu dalam era LLaMA3.
Fenomena serupa berlaku dalam penanda aras CommonSenseQA. Prestasi model yang diperhalusi dengan QLoRA dan IR-QLoRA juga menurun berbanding rakan sejawat 4-bit tanpa LoRA-FT (cth., penurunan purata 2.8% untuk QLoRA berbanding penurunan purata 2.4% untuk IR-QLoRA). Ini seterusnya menunjukkan kelebihan menggunakan set data berkualiti tinggi dalam LLaMA3 dan set data tujuan umum Alpaca tidak menyumbang kepada prestasi model dalam tugas lain.
Kesimpulan
Kertas kerja ini menilai secara komprehensif prestasi LLaMA3 dalam pelbagai teknik pengkuantitian bit rendah, termasuk pengkuantitian pasca latihan dan pengkuantitian disesuaikan LoRA.
Penemuan penyelidikan ini menunjukkan bahawa walaupun LLaMA3 masih mempamerkan prestasi unggul selepas pengkuantitian, penurunan prestasi yang dikaitkan dengan pengkuantitian adalah ketara dan malah boleh menyebabkan penurunan yang lebih besar dalam banyak kes.
Penemuan ini menyerlahkan potensi cabaran yang mungkin dihadapi apabila menggunakan LLaMA3 dalam persekitaran terhad sumber dan menyerlahkan ruang yang cukup untuk pertumbuhan dan penambahbaikan dalam konteks pengkuantitian bit rendah. Dengan menyelesaikan kemerosotan prestasi yang disebabkan oleh pengkuantitian bit rendah, paradigma pengkuantitian seterusnya dijangka akan membolehkan LLM mencapai keupayaan yang lebih kukuh pada kos pengiraan yang lebih rendah, akhirnya memacu kecerdasan buatan generatif perwakilan ke tahap yang lebih tinggi.
Pautan kertas: https://arxiv.org/abs/2404.14047.
Pautan projek: https://github.com/Macaronlin/LLaMA3-Quantizationhttps://huggingface.co/LLMQ.
Atas ialah kandungan terperinci Prestasi pengkuantitian bit rendah Llama 3 menurun dengan ketara! Keputusan penilaian komprehensif ada di sini |. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!

Alat AI Hot

Undresser.AI Undress
Apl berkuasa AI untuk mencipta foto bogel yang realistik

AI Clothes Remover
Alat AI dalam talian untuk mengeluarkan pakaian daripada foto.

Undress AI Tool
Gambar buka pakaian secara percuma

Clothoff.io
Penyingkiran pakaian AI

AI Hentai Generator
Menjana ai hentai secara percuma.

Artikel Panas
Alat panas

Notepad++7.3.1
Editor kod yang mudah digunakan dan percuma

SublimeText3 versi Cina
Versi Cina, sangat mudah digunakan

Hantar Studio 13.0.1
Persekitaran pembangunan bersepadu PHP yang berkuasa

Dreamweaver CS6
Alat pembangunan web visual

SublimeText3 versi Mac
Perisian penyuntingan kod peringkat Tuhan (SublimeText3)
Topik panas
 1381
1381
 52
52

 Cara menyambung ke rangkaian awam pelayan git
Apr 17, 2025 pm 02:27 PM
Cara menyambung ke rangkaian awam pelayan git
Apr 17, 2025 pm 02:27 PM
Menyambungkan pelayan Git ke rangkaian awam termasuk lima langkah: 1. Sediakan alamat IP awam; 2. Buka port firewall (22, 9418, 80/443); 3. Konfigurasi akses SSH (menghasilkan pasangan utama, buat pengguna); 4. Konfigurasi akses HTTP/HTTPS (pasang pelayan, konfigurasikan keizinan); 5. Uji sambungan (menggunakan klien SSH atau arahan git).
 Cara Menambah Kekunci Awam ke Akaun Git
Apr 17, 2025 pm 02:42 PM
Cara Menambah Kekunci Awam ke Akaun Git
Apr 17, 2025 pm 02:42 PM
Bagaimana untuk menambah kunci awam ke akaun Git? Langkah: Menjana pasangan kunci SSH. Salin kunci awam. Tambah kunci awam di Gitlab atau GitHub. Uji sambungan SSH.
 Cara Menangani Konflik Kod Git
Apr 17, 2025 pm 02:51 PM
Cara Menangani Konflik Kod Git
Apr 17, 2025 pm 02:51 PM
Konflik kod merujuk kepada konflik yang berlaku apabila pelbagai pemaju mengubah suai kod yang sama dan menyebabkan Git bergabung tanpa memilih perubahan secara automatik. Langkah -langkah resolusi termasuk: Buka fail yang bercanggah dan cari kod yang bercanggah. Gabungkan kod secara manual dan salin perubahan yang anda mahu masuk ke dalam penanda konflik. Padam tanda konflik. Simpan dan serahkan perubahan.
 Cara mengesan ssh dengan git
Apr 17, 2025 pm 02:33 PM
Cara mengesan ssh dengan git
Apr 17, 2025 pm 02:33 PM
Untuk mengesan SSH melalui Git, anda perlu melakukan langkah -langkah berikut: menghasilkan pasangan kunci SSH. Tambah kunci awam ke pelayan Git. Konfigurasikan Git untuk menggunakan SSH. Uji sambungan SSH. Menyelesaikan masalah yang mungkin mengikut keadaan sebenar.
 Cara memisahkan komitmen git
Apr 17, 2025 pm 02:36 PM
Cara memisahkan komitmen git
Apr 17, 2025 pm 02:36 PM
Gunakan Git untuk menyerahkan kod secara berasingan, menyediakan pengesanan perubahan berbutir dan keupayaan kerja bebas. Langkah -langkah adalah seperti berikut: 1. Tambah fail yang diubah; 2. Kirim perubahan tertentu; 3. Ulangi langkah -langkah di atas; 4. Tolak penyerahan ke repositori jauh.
 Cara membina pelayan git
Apr 17, 2025 pm 12:57 PM
Cara membina pelayan git
Apr 17, 2025 pm 12:57 PM
Membina pelayan Git termasuk: memasang git pada pelayan. Buat pengguna dan kumpulan yang menjalankan pelayan. Buat direktori repositori git. Memulakan repositori kosong. Konfigurasikan Tetapan Kawalan Akses. Mulakan perkhidmatan SSH. Memberi akses kepada pengguna. Uji sambungan.
 Apa yang Harus Dilakukan Sekiranya Git Mengemukakan Cawangan Berkejak
Apr 17, 2025 pm 02:24 PM
Apa yang Harus Dilakukan Sekiranya Git Mengemukakan Cawangan Berkejak
Apr 17, 2025 pm 02:24 PM
Selepas melakukan cawangan yang salah, anda boleh menyelesaikannya dengan: Tentukan bahawa cawangan yang salah membuat cawangan baru, menunjuk cawangan yang betul memohon komitmen untuk cawangan baru menolak cawangan baru ke repositori jauh untuk memadamkan cawangan yang salah. Kemas kini Kemas kini Cawangan Jauh
 Cara menambah pembolehubah persekitaran ke git
Apr 17, 2025 pm 02:39 PM
Cara menambah pembolehubah persekitaran ke git
Apr 17, 2025 pm 02:39 PM
Cara Menambah Pembolehubah Alam Sekitar ke Git: Ubah suai fail .GitConfig. Tambah env = kekunci = nilai dalam blok [teras]. Simpan dan keluar dari fail. Muat semula konfigurasi Git (Git Config - -Reload). Sahkan Pembolehubah Alam Sekitar (Git Config -Dapatkan Core.env.my_env_var).
