
Lajur AIxiv ialah lajur di mana tapak ini menerbitkan kandungan akademik dan teknikal. Dalam beberapa tahun kebelakangan ini, lajur AIxiv laman web ini telah menerima lebih daripada 2,000 laporan, meliputi makmal terkemuka dari universiti dan syarikat utama di seluruh dunia, mempromosikan pertukaran dan penyebaran akademik secara berkesan. Jika anda mempunyai kerja cemerlang yang ingin anda kongsikan, sila berasa bebas untuk menyumbang atau hubungi kami untuk melaporkan. E-mel penyerahan: liyazhou@jiqizhixin.com; zhaoyunfeng@jiqizhixin.com.
Baru-baru ini, model AI berskala besar seperti model bahasa besar dan model graf Vincentian telah berkembang pesat. Di bawah situasi ini, cara menyesuaikan diri dengan keperluan yang berubah dengan pantas dan cepat menyesuaikan model besar kepada pelbagai tugas hiliran telah menjadi satu cabaran penting. Terhad oleh sumber pengkomputeran, kaedah penalaan halus parameter penuh tradisional mungkin tidak mencukupi, jadi strategi penalaan halus yang lebih cekap perlu diterokai. Cabaran di atas telah menimbulkan perkembangan pesat teknologi penalaan halus parameter cekap (PEFT) baru-baru ini. Untuk meringkaskan secara menyeluruh sejarah pembangunan teknologi PEFT dan mengikuti kemajuan penyelidikan terkini, penyelidik dari Northeastern University, University of California Riverside, Arizona State University dan New York University baru-baru ini menyiasat, menyusun dan meringkaskan parameter Aplikasi teknologi penalaan halus yang cekap (PEFT) pada model besar dan prospek pembangunannya diringkaskan dalam semakan yang komprehensif dan canggih. Pautan kertas: https://arxiv.org/pdf/2403.14608.pdf memperhalusi bilangan parameter yang sangat kecil, membolehkan model besar bergerak dengan mudah dan cepat menyesuaikan diri dengan pelbagai tugas hiliran, menjadikan model besar tidak lagi "Mac besar".
Teks penuh sepanjang 24 muka surat, merangkumi hampir 250 dokumen terkini telah dipetik oleh Universiti Stanford, Universiti Peking dan institusi lain sebaik sahaja ia dikeluarkan, dan telah mendapat populariti yang besar di pelbagai platform.
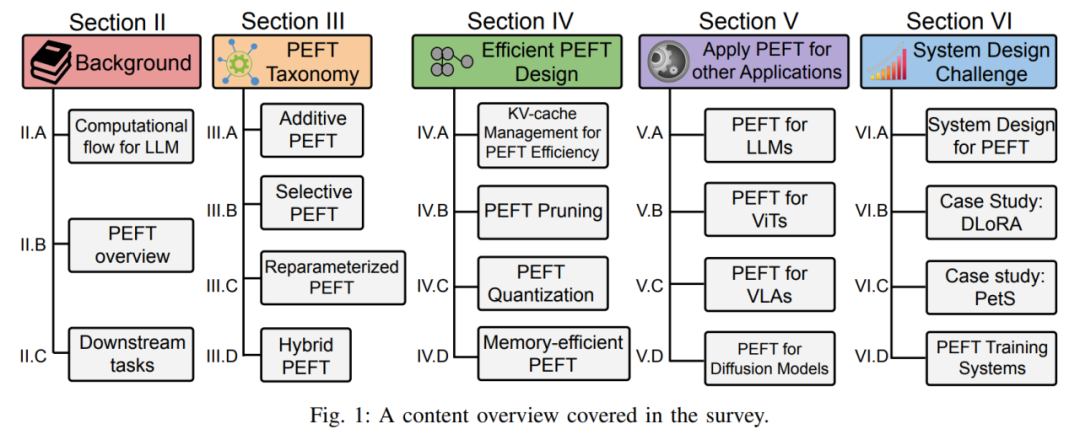
Secara khusus, ulasan ini menganalisis secara komprehensif sejarah pembangunan dan kemajuan terkini PEFT daripada empat aspek: klasifikasi algoritma PEFT, reka bentuk PEFT yang cekap, aplikasi merentas medan PEFT dan reka bentuk dan penggunaan sistem PEFT serta penjelasan terperinci . Sama ada anda seorang pengamal dalam industri berkaitan atau pemula dalam bidang penalaan halus model besar, ulasan ini boleh berfungsi sebagai panduan pembelajaran yang komprehensif.
1. Pengenalan latar belakang PEFT
Kertas pertama kali menggunakan model LLaMA yang popular baru-baru ini sebagai wakil untuk menganalisis dan menghuraikan proses pengiraan dan model bahasa besar (LLM-) dan lain-lain model berasaskan , dan mentakrifkan perwakilan simbolik yang diperlukan untuk memudahkan analisis pelbagai teknologi PEFT kemudiannya.
Selain itu, penulis juga menggariskan kaedah pengelasan algoritma PEFT. Penulis membahagikan algoritma PEFT kepada penalaan halus tambahan, penalaan halus terpilih, penalaan halus berparameter berat dan penalaan halus hibrid mengikut operasi yang berbeza. Rajah 3 menunjukkan klasifikasi algoritma PEFT dan nama algoritma khusus yang disertakan dalam setiap kategori. Takrifan khusus bagi setiap kategori akan diterangkan secara terperinci kemudian. Di bahagian latar belakang, pengarang juga memperkenalkan tanda aras hiliran biasa dan set data yang digunakan untuk mengesahkan prestasi kaedah PEFT, menjadikannya lebih mudah untuk pembaca membiasakan diri dengan tetapan tugas biasa. 2. Klasifikasi kaedah PEFT
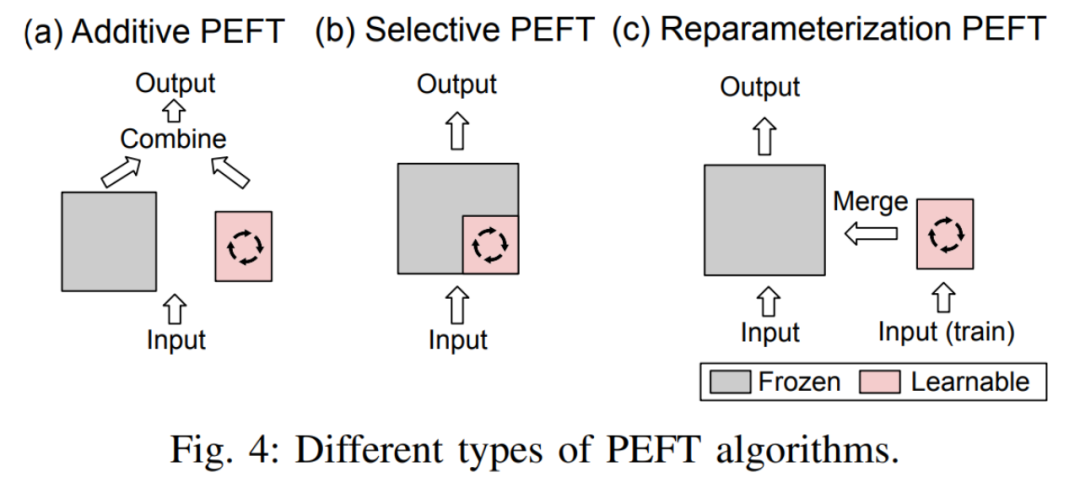
Pengarang terlebih dahulu memberikan definisi penalaan halus tambahan, penalaan halus terpilih, penalaan halus berparameter berat dan penalaan halus hibrid:
- Penalaan halus tambahan Dengan menambahkan modul atau parameter yang boleh dipelajari di lokasi tertentu dalam model pra-latihan untuk meminimumkan bilangan parameter model yang boleh dilatih apabila menyesuaikan diri dengan tugasan hiliran.
- Penalaan halus terpilihDalam proses penalaan halus, hanya sebahagian daripada parameter dalam model dikemas kini, manakala parameter yang selebihnya dikekalkan tetap. Berbanding dengan penalaan halus tambahan, penalaan halus terpilih tidak memerlukan perubahan seni bina model pra-latihan.
- Penalaan halus terparameter semula berfungsi dengan membina perwakilan (pangkat rendah) parameter model pra-latihan untuk latihan. Semasa inferens, parameter akan ditukar secara setara ke dalam struktur parameter model pra-latihan untuk mengelak daripada memperkenalkan kelewatan inferens tambahan.
Perbezaan antara ketiga-tiganya ditunjukkan dalam Rajah 4:
Penalaan halus hibrid
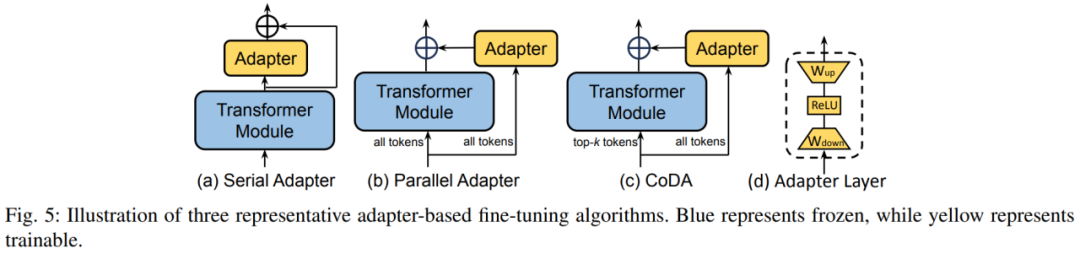
menggabungkan kelebihan pelbagai kaedah PEFT yang berbeza dan membina seni bina yang serupa yang tidak disatukan atau mencari hiperparameter PEFT yang optimum. . er di dalam blok Transformer Lapisan Penyesuai melaksanakan penalaan halus parameter yang cekap. Setiap lapisan Penyesuai mengandungi matriks unjuran bawah, fungsi pengaktifan dan matriks unjuran atas. Matriks unjuran ke bawah memetakan ciri input kepada dimensi kesesakan r, dan matriks unjuran atas memetakan ciri kesesakan kembali ke dimensi asal d.
Rajah 5 menunjukkan tiga strategi sisipan tipikal lapisan Penyesuai dalam model. Penyesuai Bersiri dimasukkan secara berurutan selepas modul Transformer, dan Penyesuai Selari dimasukkan secara selari di sebelah modul Transformer. CoDA ialah kaedah Penyesuai jarang Untuk token penting, CoDA menggunakan kedua-dua modul Transformer yang telah dilatih dan cawangan Penyesuai untuk penaakulan untuk token yang tidak penting, CoDA hanya menggunakan cawangan Penyesuai untuk menaakul untuk menjimatkan overhed pengkomputeran.
Soft Prompt mencapai penalaan halus yang cekap bagi parameter dengan menambahkan vektor yang boleh dipelajari di kepala jujukan input. Kaedah perwakilan termasuk Penalaan Awalan dan Penalaan Segera. Penalaan awalan membolehkan penalaan halus perwakilan model dengan menambahkan vektor yang boleh dipelajari di hadapan kunci, nilai dan matriks pertanyaan setiap lapisan Transformer. Penalaan Prompt hanya memasukkan vektor yang boleh dipelajari dalam lapisan vektor perkataan pertama untuk mengurangkan lagi parameter latihan. Selain dua klasifikasi di atas, terdapat juga beberapa kaedah PEFT yang turut memperkenalkan parameter baharu dalam proses latihan.
Dua kaedah tipikal ditunjukkan dalam Rajah 6. (IA) 3 memperkenalkan tiga vektor penskalaan untuk melaraskan kunci, nilai dan pengaktifan rangkaian suapan hadapan. SSF melaraskan nilai pengaktifan model melalui transformasi linear. Selepas setiap langkah, SSF menambah lapisan SSF-ADA untuk mendayakan penskalaan dan terjemahan nilai pengaktifan.
B. Penalaan halus terpilih:
1) Topeng tidak berstruktur
Kaedah jenis ini menentukan parameter yang boleh ditala dengan teliti dengan parameter binari. . Banyak kerja, seperti pemangkasan Diff, FishMask, dan LT-SFT, dsb., memfokuskan pada pengiraan kedudukan topeng. 2) Topeng berstruktur
Topeng tidak berstruktur tidak mempunyai sekatan pada bentuk topeng, tetapi ini membawa kepada ketidakcekapan dalam impaknya. Oleh itu, beberapa karya, seperti FAR, S-Bitfit, Xattn Tuning, dll., mengenakan sekatan berstruktur pada bentuk topeng. Perbezaan antara keduanya ditunjukkan dalam gambar di bawah: C. Penalaan halus berparameter semula:
1) Penguraian peringkat rendah Kaedah jenis ini melakukan penalaan halus bagi pihak keseluruhan ruang parameter dengan mencari pelbagai parameter semula berparameter rendah bentuk matriks berat pra-latihan. Kaedah yang paling tipikal ialah LoRA, yang membina perwakilan peringkat rendah bagi parameter model asal untuk latihan dengan menambah dua matriks unjuran atas dan bawah tambahan. Selepas latihan, parameter tambahan boleh digabungkan dengan lancar ke dalam pemberat yang telah dilatih untuk mengelak daripada memperkenalkan overhed inferens tambahan. DoRA memisahkan matriks berat kepada panjang dan arah modular, dan memanfaatkan LoRA untuk memperhalusi matriks arah. Penulis membahagikan kaedah terbitan LoRA kepada pemilihan dinamik pangkat LoRA dan peningkatan LoRA dalam pelbagai aspek. Dalam kedudukan dinamik LoRA, kaedah biasa ialah DyLoRA, yang membina satu siri pangkat untuk latihan serentak semasa proses latihan, dengan itu mengurangkan sumber yang dibelanjakan untuk mencari pangkat optimum. Dalam penambahbaikan LoRA, penulis menyenaraikan kelemahan LoRA tradisional dalam pelbagai aspek dan penyelesaian yang sepadan. D. Penalaan halus hibrid: Bahagian ini mengkaji cara mengintegrasikan teknologi PEFT yang berbeza ke dalam model bersatu dan mencari corak reka bentuk yang optimum. Selain itu, beberapa penyelesaian menggunakan carian seni bina saraf (NAS) untuk mendapatkan hiperparameter latihan PEFT yang optimum turut diperkenalkan. 3. Reka bentuk PEFT yang cekap
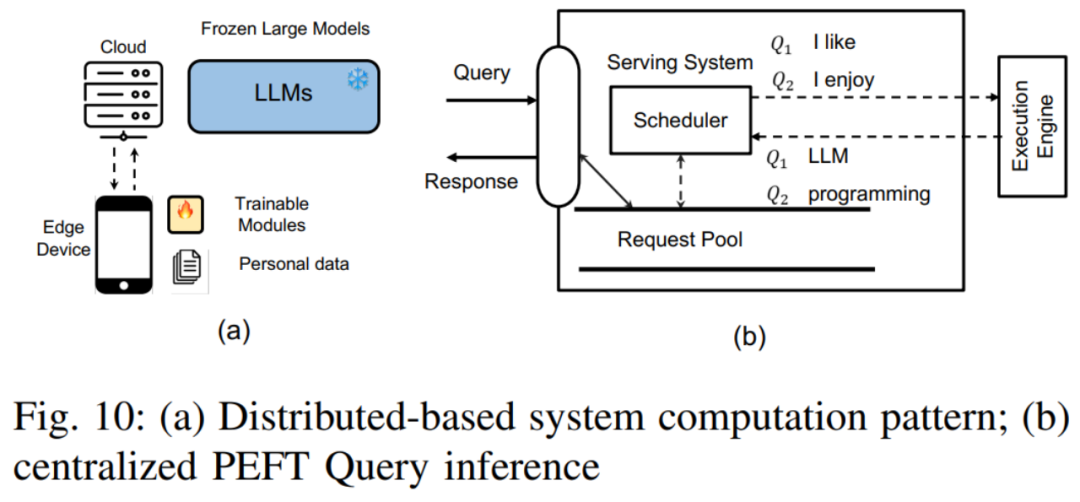
Dalam bahagian ini, penulis membincangkan penyelidikan tentang meningkatkan kecekapan PEFT, memfokuskan pada kependaman dan overhed memori puncak latihan dan inferensnya. Penulis terutamanya menerangkan cara meningkatkan kecekapan PEFT dari tiga perspektif. Ia adalah: Strategi pemangkasan PEFT: Menggabungkan teknologi pemangkasan rangkaian saraf dan teknologi PEFT untuk meningkatkan lagi kecekapan. Tugas wakil termasuk AdapterDrop, SparseAdapter, dsb. Strategi pengiraan PEFT: Iaitu, mengurangkan saiz model dengan mengurangkan ketepatan model, dengan itu meningkatkan kecekapan pengiraan. Apabila digabungkan dengan PEFT, kesukaran utama ialah bagaimana untuk mengambil kira berat pra-latihan dengan lebih baik dan pemprosesan pengkuantitian modul PEFT baharu. Kerja perwakilan termasuk QLoRA, LoftQ, dsb. Reka bentuk PEFT yang cekap memori: Walaupun PEFT boleh mengemas kini hanya sebilangan kecil parameter semasa latihan, jejak ingatannya masih besar kerana keperluan untuk pengiraan kecerunan dan perambatan belakang. Untuk menangani cabaran ini, beberapa kaedah cuba mengurangkan overhed memori dengan memintas pengiraan kecerunan dalam pemberat pra-latihan, seperti Penalaan Sisi dan LST. Pada masa yang sama, kaedah lain cuba mengelakkan penyebaran balik dalam LLM untuk menyelesaikan masalah ini, seperti HyperTuning, MeZO, dll. 4. Aplikasi merentas medan PEFTDalam bab ini, penulis meneroka aplikasi PEFT dalam bidang yang berbeza dan membincangkan cara mereka bentuk kaedah PEFT yang lebih baik untuk meningkatkan prestasi model atau tugas tertentu dibincangkan. Bahagian ini tertumpu terutamanya pada pelbagai model pra-latihan berskala besar, termasuk LLM, Transformer visual (ViT), model teks visual dan model resapan, dan menerangkan secara terperinci peranan PEFT dalam penyesuaian tugas hiliran model pra-terlatih ini. Dari segi LLM, penulis memperkenalkan cara menggunakan PEFT untuk memperhalusi LLM untuk menerima input arahan visual, kerja perwakilan seperti LLaMA-Adapter. Selain itu, penulis juga meneroka aplikasi PEFT dalam pembelajaran berterusan LLM dan menyebut cara memperhalusi LLM dengan PEFT untuk mengembangkan tetingkap konteksnya. Untuk ViT, penulis menerangkan cara menggunakan teknologi PEFT untuk menyesuaikannya dengan tugas pengecaman imej hiliran, dan cara menggunakan PEFT untuk memberikan keupayaan pengecaman video ViT. Dari segi model teks visual, penulis memperkenalkan banyak karya yang menggunakan PEFT untuk memperhalusi model teks visual untuk tugas pengelasan imej set terbuka. Untuk model resapan, pengarang mengenal pasti dua senario biasa: cara menambah input tambahan selain teks, dan cara mencapai penjanaan diperibadikan, dan menerangkan penggunaan PEFT dalam kedua-dua jenis tugasan ini. 5. Cabaran reka bentuk sistem PEFT Dalam bab ini, penulis terlebih dahulu menerangkan cabaran yang dihadapi oleh sistem PEFT berdasarkan perkhidmatan awan. Ia terutamanya termasuk perkara berikut: Perkhidmatan pertanyaan PEFT terpusat: Dalam mod ini, pelayan awan menyimpan satu salinan model LLM dan berbilang modul PEFT. Mengikut keperluan tugas pertanyaan PEFT yang berbeza, pelayan awan akan memilih modul PEFT yang sepadan dan menyepadukannya dengan model LLM. Perkhidmatan Pertanyaan PEFT Teragih: Dalam mod ini, model LLM disimpan pada pelayan awan, manakala pemberat dan set data PEFT disimpan pada peranti pengguna. Peranti pengguna menggunakan kaedah PEFT untuk memperhalusi model LLM, dan kemudian memuat naik pemberat PEFT yang diperhalusi dan set data ke pelayan awan. Latihan PEFT berbilang: Cabaran termasuk cara mengurus kecerunan memori dan penyimpanan berat model, dan cara mereka bentuk kernel yang cekap untuk melatih PEFT secara kelompok, dsb.
Sebagai tindak balas kepada cabaran reka bentuk sistem di atas, penulis menyenaraikan tiga kes reka bentuk sistem terperinci untuk memberikan analisis yang lebih mendalam tentang cabaran ini dan strategi penyelesaian yang boleh dilaksanakan. Penalaan Luar Tapak: Terutamanya menyelesaikan dilema privasi data dan isu penggunaan sumber besar-besaran yang timbul apabila menyesuaikan LLM. PetS: Menyediakan rangka kerja perkhidmatan bersatu dan menyediakan mekanisme pengurusan dan penjadualan bersatu untuk modul PEFT.
Rangka Kerja Latihan Selari PEFT: Memperkenalkan dua rangka kerja latihan PEFT selari, termasuk S-LoRA dan Punica, dan cara mereka meningkatkan kecekapan latihan PEFT. 6. Hala tuju penyelidikan masa depan Penulis percaya walaupun teknologi PEFT telah berjaya dalam banyak tugas hiliran, masih terdapat beberapa kelemahan yang perlu diselesaikan dalam kerja akan datang. Wujudkan penanda aras penilaian bersatu: Walaupun sesetengah perpustakaan PEFT wujud, terdapat kekurangan penanda aras yang komprehensif untuk membandingkan secara adil keberkesanan dan kecekapan kaedah PEFT yang berbeza. Mewujudkan penanda aras yang diiktiraf akan memupuk inovasi dan kerjasama dalam komuniti. Kecekapan latihan yang dipertingkatkan: Jumlah parameter boleh dilatih PEFT tidak selalu konsisten dengan penjimatan pengiraan dan memori semasa latihan. Seperti yang dibincangkan dalam bahagian Reka Bentuk PEFT Cekap, penyelidikan masa depan boleh meneroka lebih lanjut cara untuk mengoptimumkan memori dan kecekapan pengiraan. Meneroka Hukum Penskalaan: Banyak teknik PEFT dilaksanakan pada model Transformer yang lebih kecil, dan keberkesanannya tidak semestinya terpakai pada pelbagai model parameter besar hari ini. Penyelidikan masa depan boleh meneroka cara menyesuaikan kaedah PEFT kepada model besar. Menyajikan lebih banyak model dan tugas: Dengan kemunculan lebih banyak model berskala besar, seperti Sora, Mamba, dll., teknologi PEFT boleh membuka kunci senario aplikasi baharu. Penyelidikan masa depan boleh memberi tumpuan kepada mereka bentuk kaedah PEFT untuk model dan tugas tertentu. Privasi Data Dipertingkat: Sistem berpusat mungkin menghadapi isu privasi data semasa menyiarkan atau memperhalusi modul PEFT diperibadikan. Penyelidikan masa depan boleh meneroka protokol penyulitan untuk melindungi data peribadi dan hasil latihan/inferens perantaraan. PEFT dan pemampatan model: Impak teknik pemampatan model seperti pemangkasan dan kuantisasi pada kaedah PEFT belum dikaji sepenuhnya. Penyelidikan masa depan boleh memberi tumpuan kepada cara model termampat menyesuaikan diri dengan prestasi kaedah PEFT. Atas ialah kandungan terperinci Biarkan model besar tidak lagi menjadi 'Mac besar'.. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!





 Selain dua klasifikasi di atas, terdapat juga beberapa kaedah PEFT yang turut memperkenalkan parameter baharu dalam proses latihan.
Selain dua klasifikasi di atas, terdapat juga beberapa kaedah PEFT yang turut memperkenalkan parameter baharu dalam proses latihan. 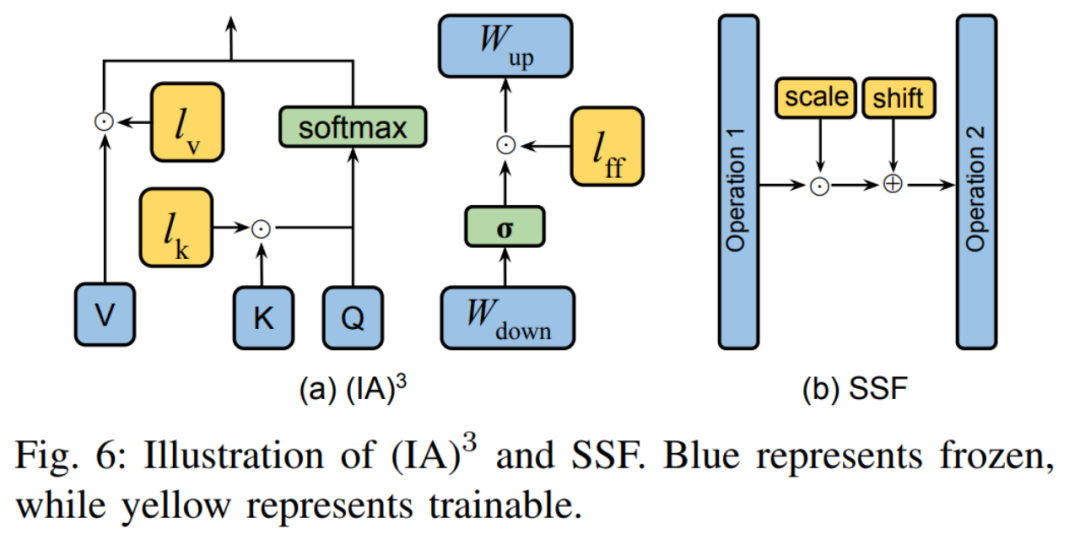 2) Topeng berstruktur
2) Topeng berstruktur 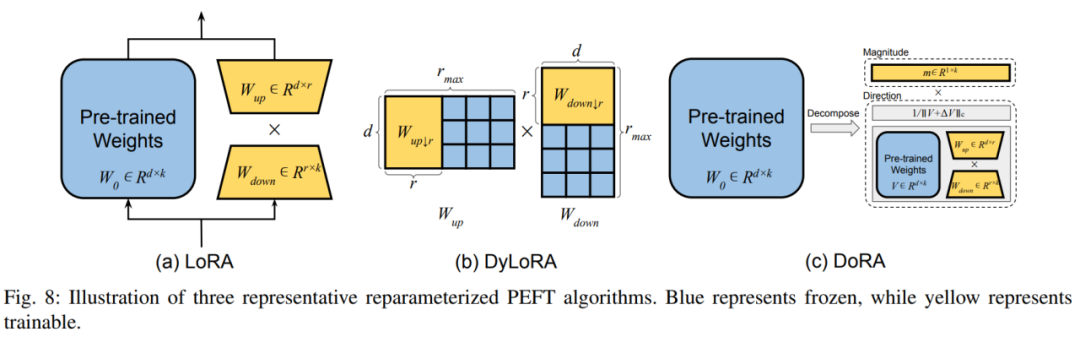

 Latihan PEFT berbilang: Cabaran termasuk cara mengurus kecerunan memori dan penyimpanan berat model, dan cara mereka bentuk kernel yang cekap untuk melatih PEFT secara kelompok, dsb.
Latihan PEFT berbilang: Cabaran termasuk cara mengurus kecerunan memori dan penyimpanan berat model, dan cara mereka bentuk kernel yang cekap untuk melatih PEFT secara kelompok, dsb. 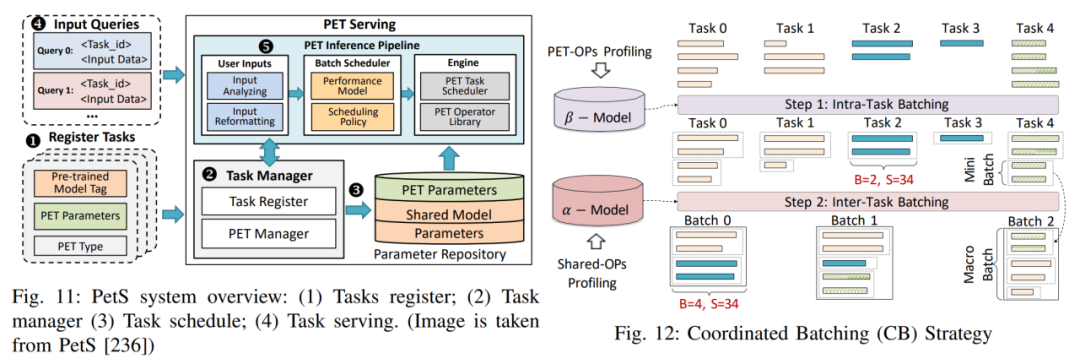
 Perbezaan antara benang dan proses
Perbezaan antara benang dan proses
 langbar.chm
langbar.chm
 Bagaimana cara menaip tulisan pada bulatan syiling?
Bagaimana cara menaip tulisan pada bulatan syiling?
 Bagaimana untuk menyelesaikan pelanggaran akses
Bagaimana untuk menyelesaikan pelanggaran akses
 Perbezaan antara fungsi anak panah dan fungsi biasa
Perbezaan antara fungsi anak panah dan fungsi biasa
 Bagaimana untuk menaik taraf sistem Hongmeng pada telefon bimbit Honor
Bagaimana untuk menaik taraf sistem Hongmeng pada telefon bimbit Honor
 Mengapakah vue.js melaporkan ralat?
Mengapakah vue.js melaporkan ralat?
 ERR_CONNECTION_REFUSED
ERR_CONNECTION_REFUSED








![[Web front-end] Permulaan pantas Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



