

FP8 dan ketepatan pengiraan titik terapung yang lebih rendah bukan lagi "paten" H100!
Lao Huang mahu semua orang menggunakan INT8/INT4 Pasukan Microsoft DeepSpeed secara paksa mula menjalankan FP6 pada A100 tanpa sokongan rasmi daripada NVIDIA.
Keputusan ujian menunjukkan bahawa kaedah baharu TC-FPx's FP6 kuantisasi kelajuan pada A100 adalah hampir atau sekali-sekala melebihi INT4, dan ia mempunyai ketepatan yang lebih tinggi daripada yang terakhir. Atas dasar ini, terdapat juga
sokongan model besar dari hujung ke hujung, yang telah sumber terbuka dan disepadukan ke dalam rangka kerja inferens pembelajaran mendalam seperti DeepSpeed. Hasil ini juga memberi kesan serta-merta pada pecutan model besar - di bawah rangka kerja ini, menggunakan satu kad untuk menjalankan Llama, daya pemprosesan adalah 2.65 kali lebih tinggi daripada dua kad.
Selepas membacanya, seorang penyelidik pembelajaran mesin berkata bahawa penyelidikan Microsoft boleh digambarkan sebagai gila.
 pek emotikon juga dalam talian serta-merta, jadi seperti:
pek emotikon juga dalam talian serta-merta, jadi seperti:
Microsoft: Baik, saya akan buat sendiri.
 Jadi, apakah jenis kesan yang boleh dicapai oleh rangka kerja ini, dan apakah jenis teknologi yang digunakan di belakangnya?
Jadi, apakah jenis kesan yang boleh dicapai oleh rangka kerja ini, dan apakah jenis teknologi yang digunakan di belakangnya?
Menggunakan FP6 untuk menjalankan Llama, satu kad lebih pantas daripada dua kad
peningkatan prestasi peringkat kernel. Para penyelidik memilih lapisan linear dalam model Llama dan model OPT dengan saiz yang berbeza, dan mengujinya menggunakan CUDA 11.8 pada platform GPU NVIDIA A100-40GB.
Hasilnya dibandingkan dengan cuBLAS rasmi NVIDIA
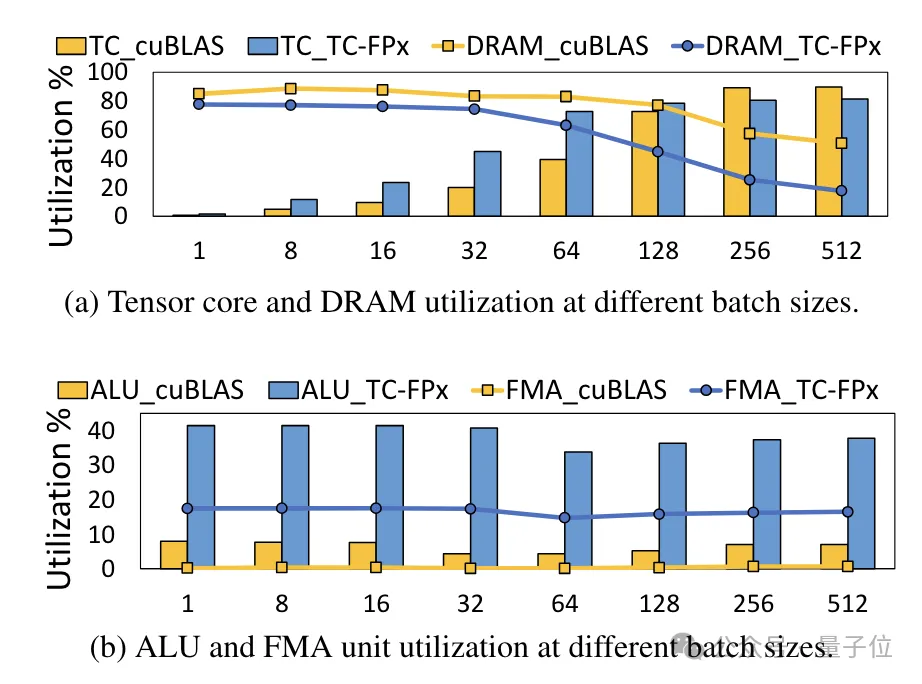
(W16A16)dan TensorRT-LLM(W8A16), peningkatan kelajuan maksimum TC-FPx(W6A16) masing-masing ialah 2.6 kali dan 1.9 kali Berbanding dengan kaedah 4bit BitsandBytes(W4A16), peningkatan kelajuan maksimum TC-FPx ialah 8.9 kali. . keperluan untuk akses memori DRAM, dan menambah baik penggunaan lebar jalur DRAM dan penggunaan Tensor Cores, serta penggunaan unit ALU dan FMA.
Rangka kerja inferens hujung ke hujung FP6-LLM
direka berdasarkan TC-FPx juga membawa peningkatan prestasi yang ketara kepada model besar.
Mengambil Llama-70B sebagai contoh, daya pemprosesan menjalankan FP6-LLM pada satu kad adalah 2.65 kali lebih tinggi daripada FP16 pada dwi kad, dan kependaman dalam saiz kelompok di bawah 16 juga lebih rendah daripada FP16.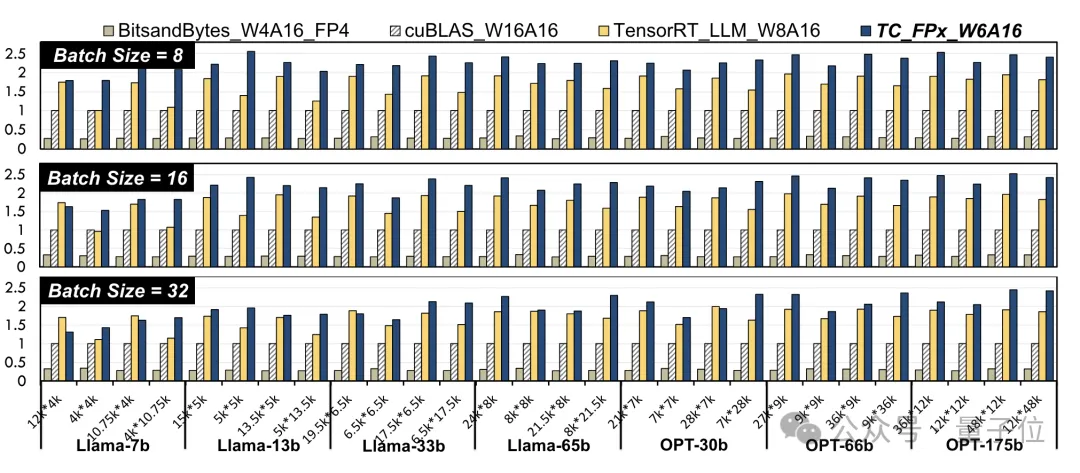
Jadi, bagaimanakah pasukan Microsoft mencapai kuantisasi FP16 yang dijalankan pada A100? Penyelesaian kernel yang direka bentuk semula
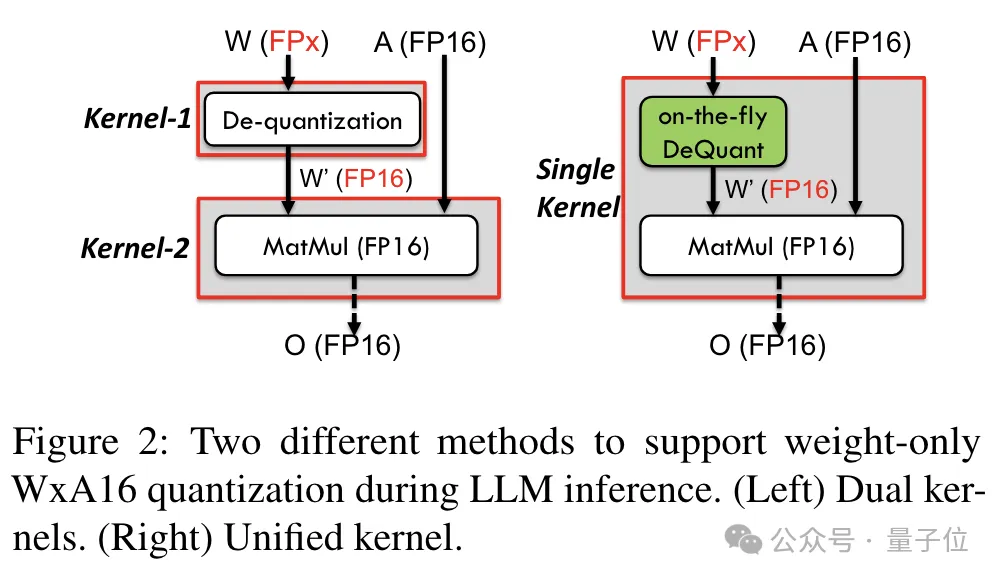
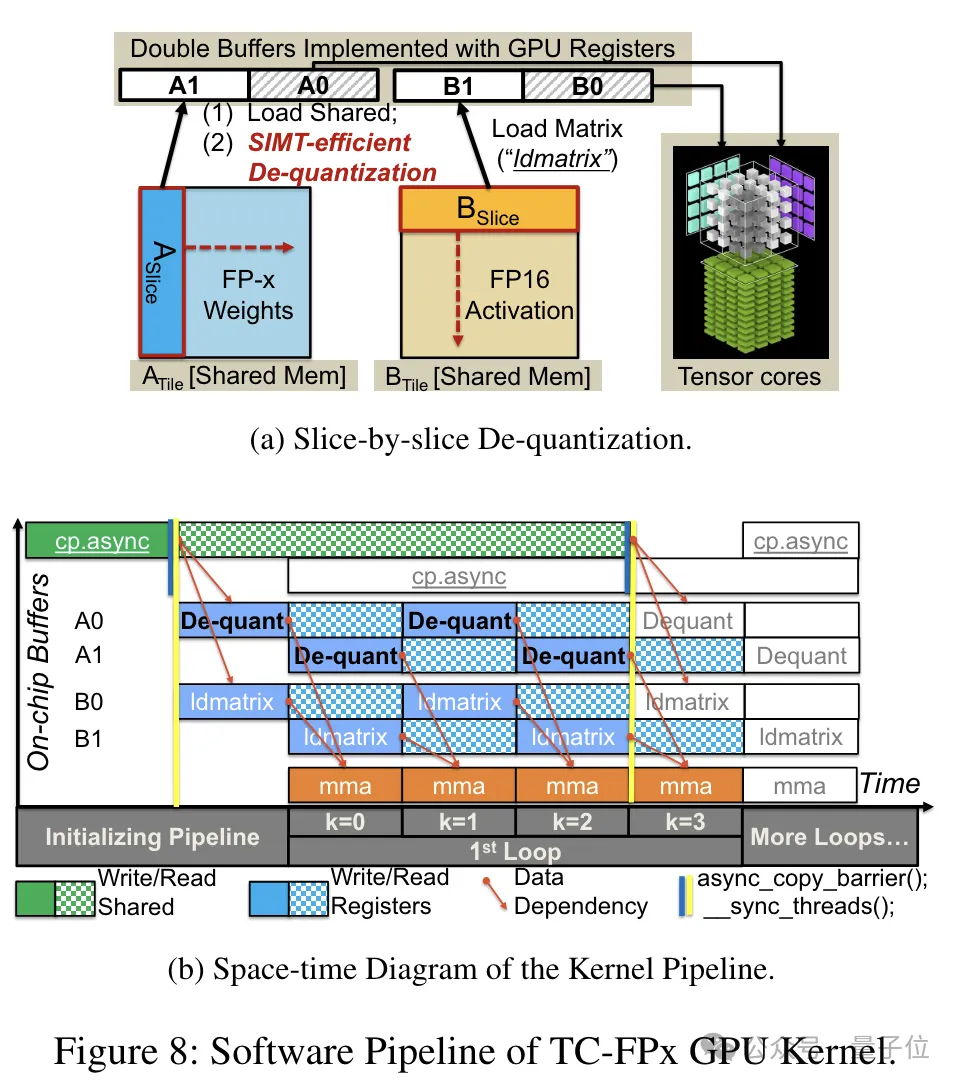
Untuk menyokong ketepatan termasuk 6bit, pasukan TC-FPx mereka bentuk penyelesaian kernel bersatu yang boleh menyokong berat pengkuantitian lebar bit yang berbeza. Berbanding dengan kaedah dwi-teras tradisional, TC-FPx mengurangkan bilangan akses memori dan meningkatkan prestasi dengan menyepadukan penyahkuansian dan pendaraban matriks dalam satu teras.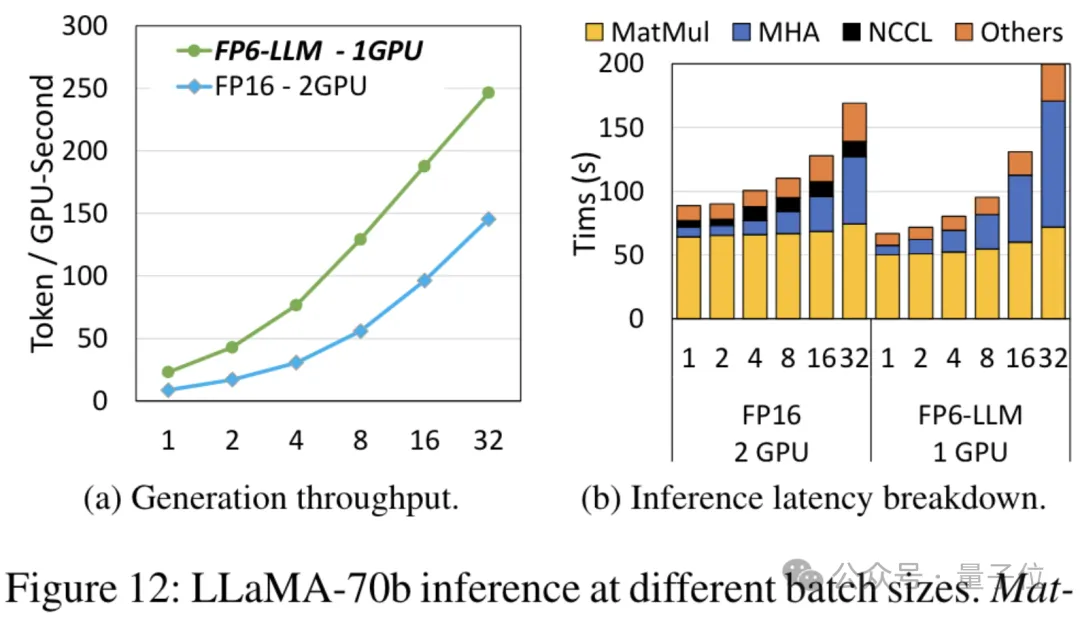 Rahsia teras untuk mencapai pengkuantitian ketepatan rendah adalah untuk "menyamarkan" data ketepatan FP6 sebagai FP16 melalui penyahkuantitian, dan kemudian menyerahkannya kepada GPU untuk pengiraan dalam format FP16.
Rahsia teras untuk mencapai pengkuantitian ketepatan rendah adalah untuk "menyamarkan" data ketepatan FP6 sebagai FP16 melalui penyahkuantitian, dan kemudian menyerahkannya kepada GPU untuk pengiraan dalam format FP16.
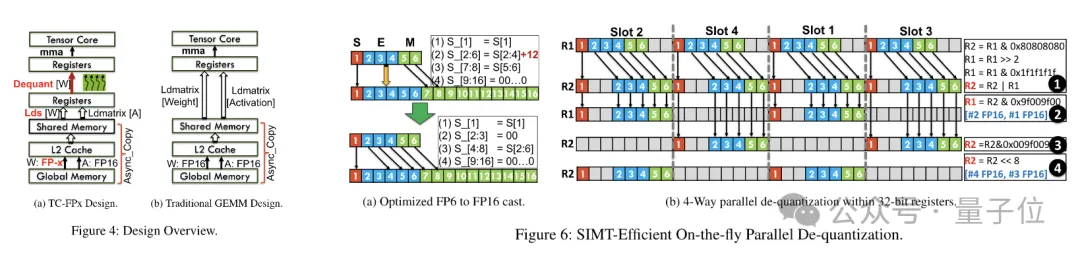
Pada masa yang sama, pasukan juga menggunakan teknologi prapembungkusan peringkat bit untuk menyelesaikan masalah sistem memori GPU tidak mesra kepada lebar bukan kuasa-2 bit (seperti 6 -sedikit).
Secara khusus, prapembungkusan tahap bit ialah penyusunan semula data berat sebelum inferens model, termasuk menyusun semula pemberat terkuantiti 6-bit supaya ia boleh diakses dalam cara yang mesra sistem memori GPU.
Selain itu, memandangkan sistem memori GPU biasanya mengakses data dalam blok 32-bit atau 64-bit, teknologi pra-pembungkusan peringkat bit juga akan membungkus pemberat 6-bit supaya ia boleh disimpan dan diakses dalam bentuk sejajar ini blok.

Selepas prapembungkusan selesai, pasukan penyelidik menggunakan keupayaan pemprosesan selari teras SIMT untuk melakukan dekuantisasi selari pada pemberat FP6 dalam daftar untuk menjana pemberat dalam format FP16.
Berat FP16 yang dinyahkuantisasi dibina semula dalam daftar dan kemudian dihantar ke Teras Tensor Pemberat FP16 yang dibina semula digunakan untuk melaksanakan operasi pendaraban matriks untuk melengkapkan pengiraan lapisan linear.
Dalam proses ini, pasukan mengambil kesempatan daripada paralelisme tahap bit teras SMIT untuk meningkatkan kecekapan keseluruhan proses dekuantisasi.
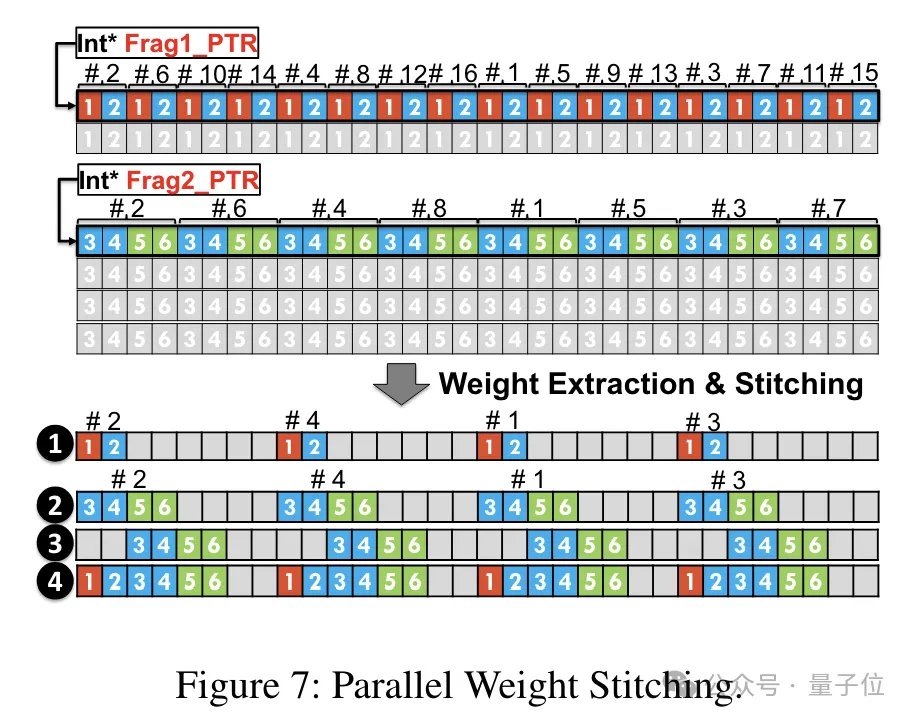
Untuk membolehkan tugas pembinaan semula berat berjalan selari, pasukan juga menggunakan teknologi penyambungan berat selari.
Secara khusus, setiap berat dibahagikan kepada beberapa bahagian, dan lebar bit setiap bahagian adalah kuasa 2 (seperti membahagikan 6 kepada 2+4 atau 4+2).
Sebelum penyahkuansian, pemberat dimuatkan terlebih dahulu ke dalam daftar daripada memori bersama. Memandangkan setiap pemberat dibahagikan kepada beberapa bahagian, berat lengkap perlu dibina semula pada peringkat daftar semasa masa jalan.
Untuk mengurangkan overhed masa jalan, TC-FPx mencadangkan kaedah pengekstrakan selari dan penyambungan pemberat. Pendekatan ini menggunakan dua set daftar untuk menyimpan segmen 32 pemberat FP6, membina semula pemberat ini secara selari.
Pada masa yang sama, untuk mengekstrak dan menyambung pemberat secara selari, adalah perlu untuk memastikan bahawa susun atur data awal memenuhi keperluan pesanan tertentu, jadi TC-FPx menyusun semula serpihan berat sebelum dijalankan.
Selain itu, TC-FPx turut mereka bentuk saluran paip perisian, yang menyepadukan langkah penyahkuansian dengan operasi pendaraban matriks Teras Tensor, meningkatkan kecekapan pelaksanaan keseluruhan melalui keselarian peringkat arahan.
Alamat kertas: https://arxiv.org/abs/2401.14112
Atas ialah kandungan terperinci Satu kad menjalankan Llama 70B lebih pantas daripada dua kad, Microsoft hanya meletakkan FP6 ke dalam A100 |. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!
















![[Web front-end] Permulaan pantas Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



