
 Peranti teknologi
AI
Dalam 12 tugas pemahaman video, Mamba pertama kali mengalahkan Transformer
Peranti teknologi
AI
Dalam 12 tugas pemahaman video, Mamba pertama kali mengalahkan Transformer
Dalam 12 tugas pemahaman video, Mamba pertama kali mengalahkan Transformer


Tapak ini menerbitkan lajur dengan kandungan akademik dan teknikal. Dalam tahun-tahun kebelakangan ini, lajur AIxiv laman web ini telah menerima lebih daripada 2,000 laporan, meliputi makmal terkemuka dari universiti dan syarikat utama di seluruh dunia, mempromosikan pertukaran dan penyebaran akademik secara berkesan. Jika anda mempunyai kerja yang sangat baik yang ingin anda kongsikan, sila berasa bebas untuk menyumbang atau hubungi kami untuk melaporkan. E-mel penyerahan: liyazhou@jiqizhixin.com; zhaoyunfeng@jiqizhixin.com.

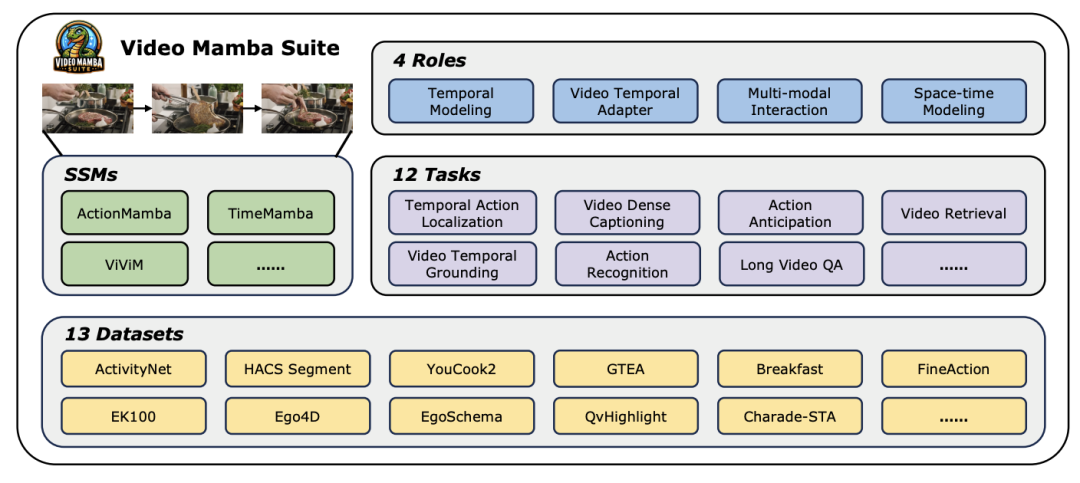
Tajuk kertas: Video Mamba Suite: State Space Model sebagai Alternatif Serbaguna untuk Pemahaman Video Pautan kertas: https://arxiv.org/abs/2403.09626 ://github.com/OpenGVLab/video-mamba-suite
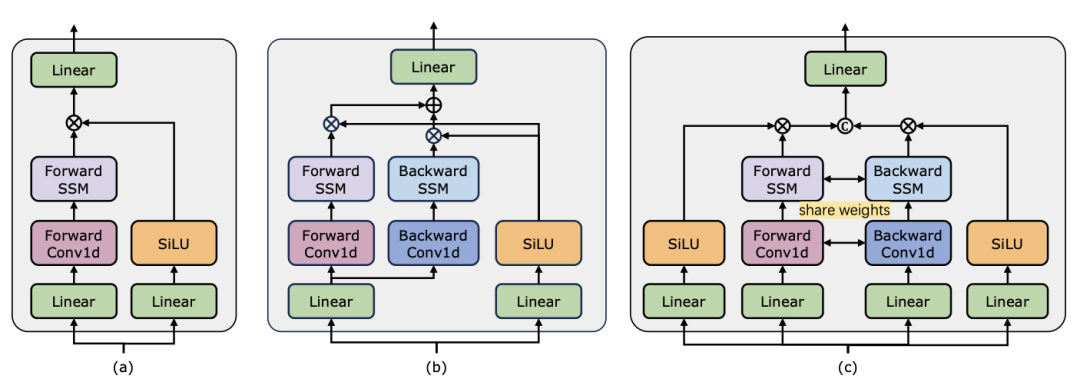
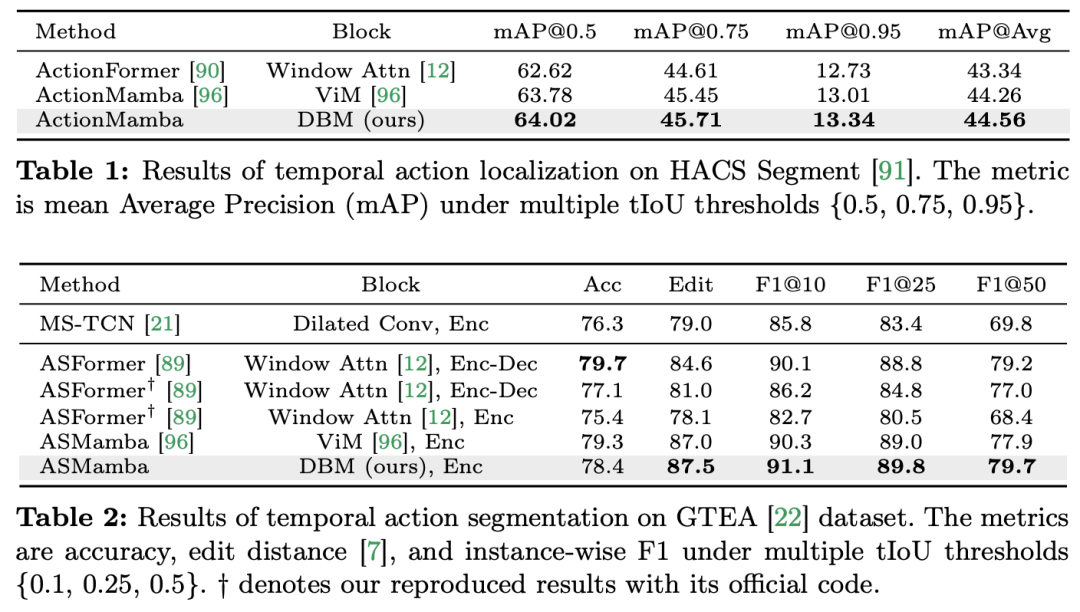
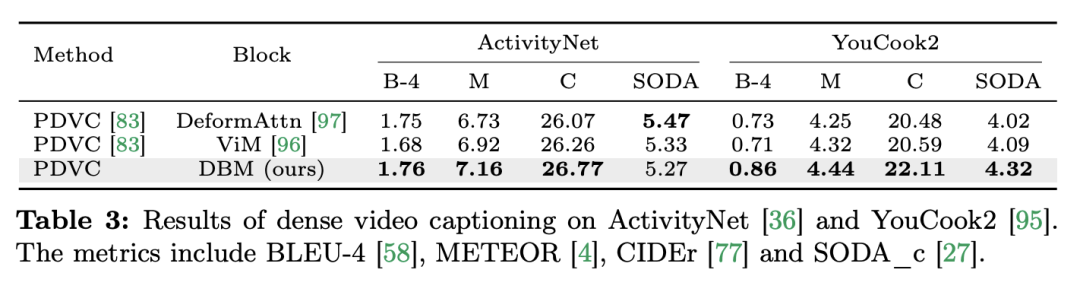
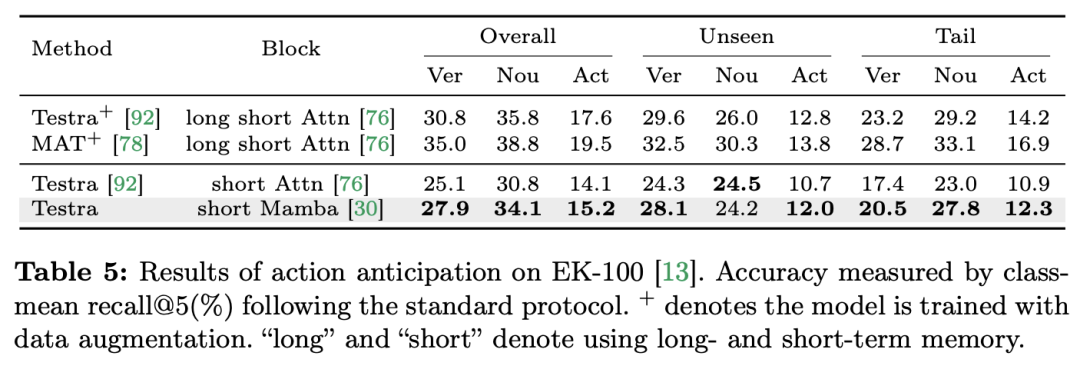
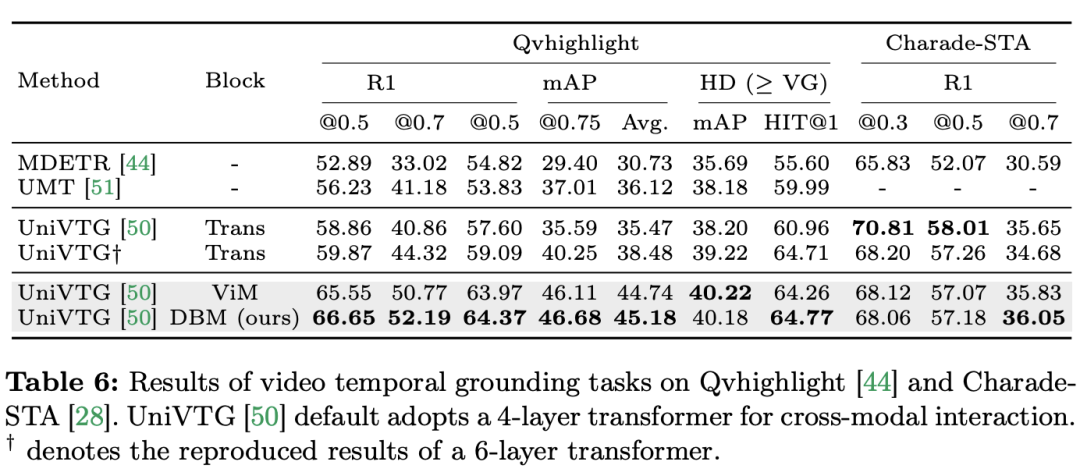

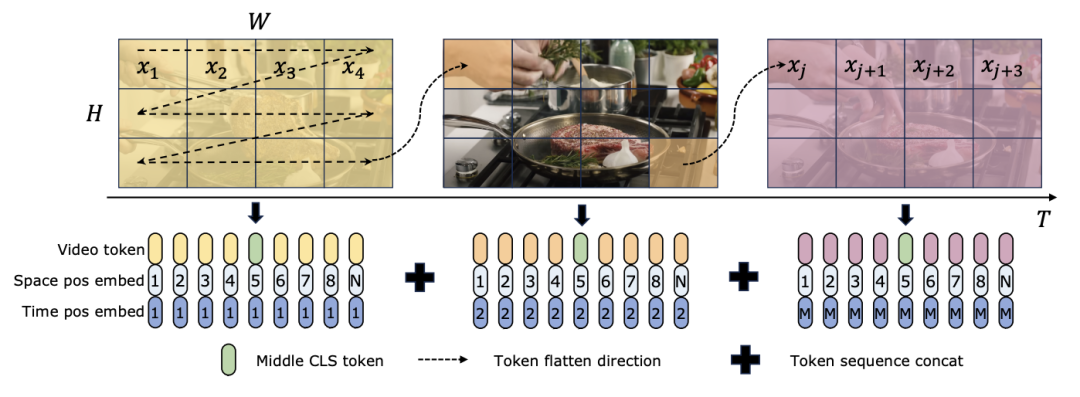
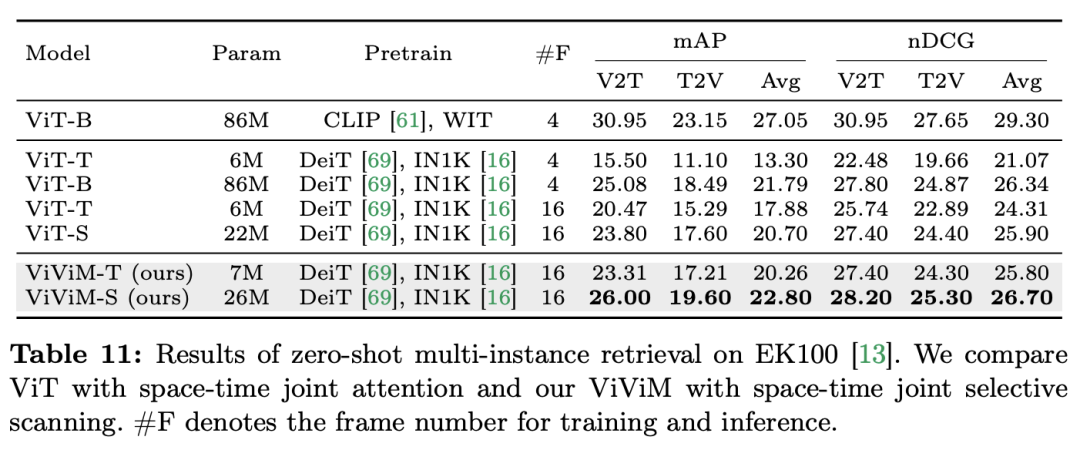
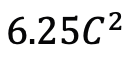 ) daripada blok perhatian diri, dengan C ialah dimensi ciri. Oleh itu, nisbah pengembangan E blok ViM ditetapkan kepada 1 dalam kertas, mengurangkan saiz parameternya kepada
) daripada blok perhatian diri, dengan C ialah dimensi ciri. Oleh itu, nisbah pengembangan E blok ViM ditetapkan kepada 1 dalam kertas, mengurangkan saiz parameternya kepada 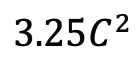 untuk perbandingan yang saksama. Sebagai tambahan kepada bentuk sambungan baki biasa yang digunakan oleh TimeSformer, pasukan penyelidik juga meneroka penyesuaian gaya Frozen. Berikut ialah 5 struktur penyesuai:
untuk perbandingan yang saksama. Sebagai tambahan kepada bentuk sambungan baki biasa yang digunakan oleh TimeSformer, pasukan penyelidik juga meneroka penyesuaian gaya Frozen. Berikut ialah 5 struktur penyesuai: 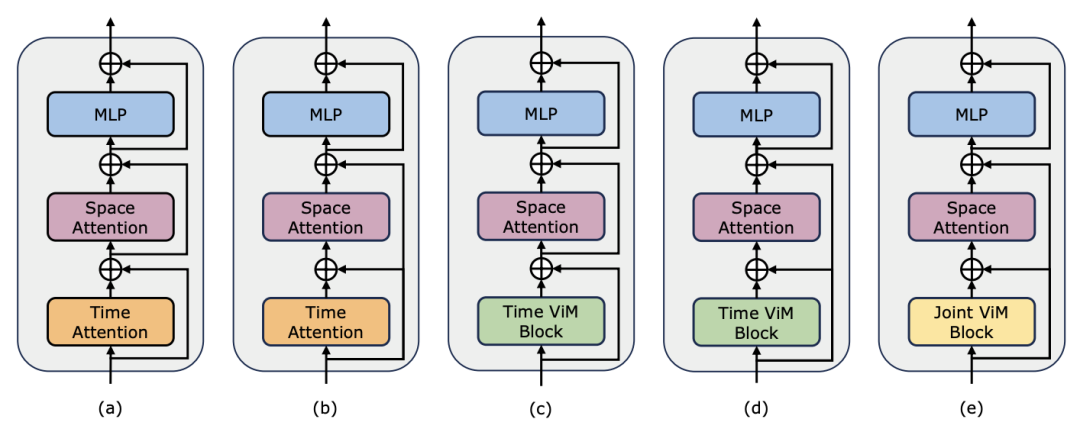
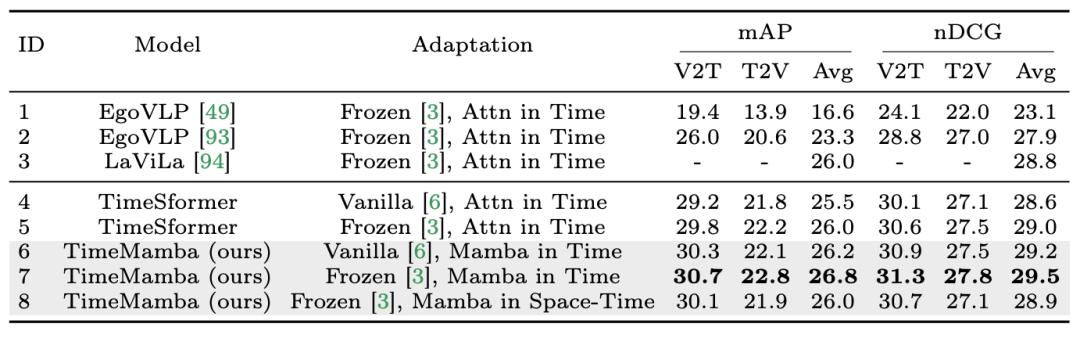
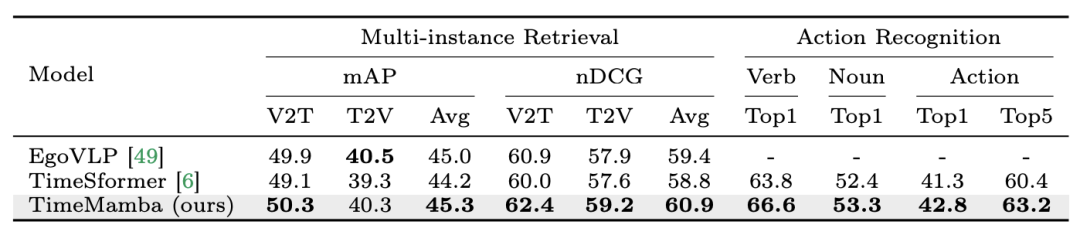
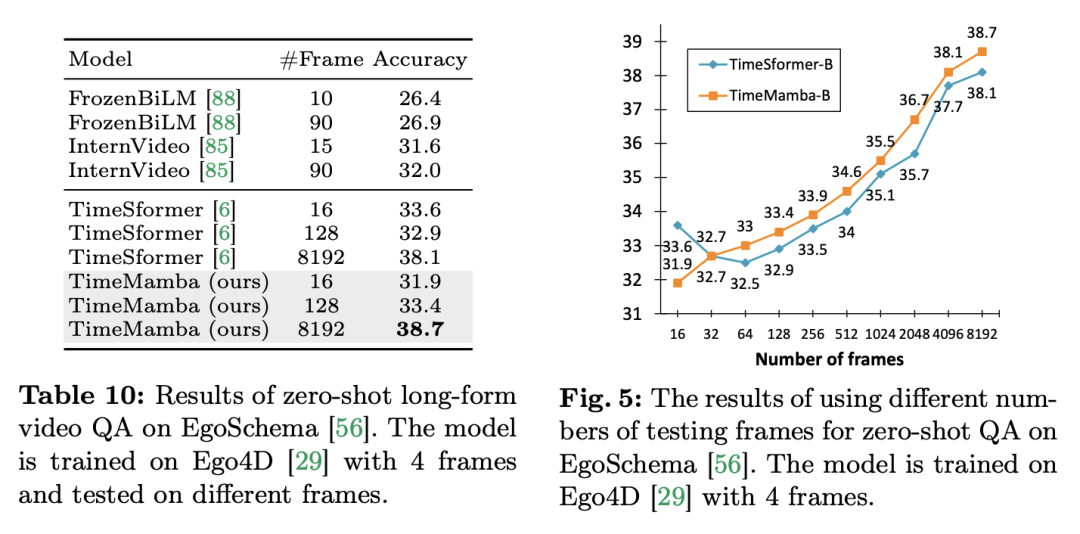
Atas ialah kandungan terperinci Dalam 12 tugas pemahaman video, Mamba pertama kali mengalahkan Transformer. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!

Alat AI Hot

Undresser.AI Undress
Apl berkuasa AI untuk mencipta foto bogel yang realistik

AI Clothes Remover
Alat AI dalam talian untuk mengeluarkan pakaian daripada foto.

Undress AI Tool
Gambar buka pakaian secara percuma

Clothoff.io
Penyingkiran pakaian AI

AI Hentai Generator
Menjana ai hentai secara percuma.

Artikel Panas
Alat panas

Notepad++7.3.1
Editor kod yang mudah digunakan dan percuma

SublimeText3 versi Cina
Versi Cina, sangat mudah digunakan

Hantar Studio 13.0.1
Persekitaran pembangunan bersepadu PHP yang berkuasa

Dreamweaver CS6
Alat pembangunan web visual

SublimeText3 versi Mac
Perisian penyuntingan kod peringkat Tuhan (SublimeText3)
Topik panas
 1374
1374
 52
52

 GITEE PAGES PENYEDIAAN LAMAN WEB STATIC Gagal: Bagaimana menyelesaikan masalah dan menyelesaikan kesilapan fail tunggal 404?
Apr 04, 2025 pm 11:54 PM
GITEE PAGES PENYEDIAAN LAMAN WEB STATIC Gagal: Bagaimana menyelesaikan masalah dan menyelesaikan kesilapan fail tunggal 404?
Apr 04, 2025 pm 11:54 PM
Giteepages Statik Laman Web Penggunaan Gagal: 404 Penyelesaian Masalah dan Resolusi Ralat Semasa Menggunakan Gitee ...
 Cara Menjalankan Projek H5
Apr 06, 2025 pm 12:21 PM
Cara Menjalankan Projek H5
Apr 06, 2025 pm 12:21 PM
Menjalankan projek H5 memerlukan langkah -langkah berikut: memasang alat yang diperlukan seperti pelayan web, node.js, alat pembangunan, dan lain -lain. Membina persekitaran pembangunan, membuat folder projek, memulakan projek, dan menulis kod. Mulakan pelayan pembangunan dan jalankan arahan menggunakan baris arahan. Pratonton projek dalam penyemak imbas anda dan masukkan URL Server Pembangunan. Menerbitkan projek, mengoptimumkan kod, menggunakan projek, dan menyediakan konfigurasi pelayan web.
 Adakah pengeluaran halaman H5 memerlukan penyelenggaraan berterusan?
Apr 05, 2025 pm 11:27 PM
Adakah pengeluaran halaman H5 memerlukan penyelenggaraan berterusan?
Apr 05, 2025 pm 11:27 PM
Halaman H5 perlu dikekalkan secara berterusan, kerana faktor -faktor seperti kelemahan kod, keserasian pelayar, pengoptimuman prestasi, kemas kini keselamatan dan peningkatan pengalaman pengguna. Kaedah penyelenggaraan yang berkesan termasuk mewujudkan sistem ujian lengkap, menggunakan alat kawalan versi, kerap memantau prestasi halaman, mengumpul maklum balas pengguna dan merumuskan pelan penyelenggaraan.
 Bagaimana untuk melaksanakan susun atur penyesuaian kedudukan paksi y dalam anotasi web?
Apr 04, 2025 pm 11:30 PM
Bagaimana untuk melaksanakan susun atur penyesuaian kedudukan paksi y dalam anotasi web?
Apr 04, 2025 pm 11:30 PM
Algoritma Adaptif Kedudukan Y-Axis untuk Fungsi Anotasi Web Artikel ini akan meneroka cara melaksanakan fungsi anotasi yang serupa dengan dokumen perkataan, terutama bagaimana menangani selang antara anotasi ...
 Cara Mengira C-SubScript 3 Subscript 5 C-SubScript 3 Subscript 5 Algoritma Tutorial
Apr 03, 2025 pm 10:33 PM
Cara Mengira C-SubScript 3 Subscript 5 C-SubScript 3 Subscript 5 Algoritma Tutorial
Apr 03, 2025 pm 10:33 PM
Pengiraan C35 pada dasarnya adalah matematik gabungan, yang mewakili bilangan kombinasi yang dipilih dari 3 dari 5 elemen. Formula pengiraan ialah C53 = 5! / (3! * 2!), Yang boleh dikira secara langsung oleh gelung untuk meningkatkan kecekapan dan mengelakkan limpahan. Di samping itu, memahami sifat kombinasi dan menguasai kaedah pengiraan yang cekap adalah penting untuk menyelesaikan banyak masalah dalam bidang statistik kebarangkalian, kriptografi, reka bentuk algoritma, dll.
 Bagaimana untuk menjadikan ketinggian lajur bersebelahan dalam UI elemen secara automatik menyesuaikan diri dengan kandungan?
Apr 05, 2025 am 06:12 AM
Bagaimana untuk menjadikan ketinggian lajur bersebelahan dalam UI elemen secara automatik menyesuaikan diri dengan kandungan?
Apr 05, 2025 am 06:12 AM
Bagaimana untuk menjadikan ketinggian lajur bersebelahan baris yang sama secara automatik menyesuaikan diri dengan kandungan? Dalam reka bentuk web, kita sering menghadapi masalah ini: apabila terdapat banyak di meja atau baris ...
 Fungsi Penggunaan Fungsi Jarak Jarak Jarak Penggunaan C Tutorial Penggunaan
Apr 03, 2025 pm 10:27 PM
Fungsi Penggunaan Fungsi Jarak Jarak Jarak Penggunaan C Tutorial Penggunaan
Apr 03, 2025 pm 10:27 PM
STD :: Unik menghilangkan elemen pendua bersebelahan di dalam bekas dan menggerakkannya ke akhir, mengembalikan iterator yang menunjuk ke elemen pendua pertama. STD :: Jarak mengira jarak antara dua iterators, iaitu bilangan elemen yang mereka maksudkan. Kedua -dua fungsi ini berguna untuk mengoptimumkan kod dan meningkatkan kecekapan, tetapi terdapat juga beberapa perangkap yang perlu diberi perhatian, seperti: STD :: Unik hanya berkaitan dengan unsur -unsur pendua yang bersebelahan. STD :: Jarak kurang cekap apabila berurusan dengan Iterator Akses Bukan Rawak. Dengan menguasai ciri -ciri dan amalan terbaik ini, anda boleh menggunakan sepenuhnya kuasa kedua -dua fungsi ini.
 Bagaimana dengan cepat membina halaman latar depan dalam projek Vite React menggunakan alat AI?
Apr 04, 2025 pm 01:45 PM
Bagaimana dengan cepat membina halaman latar depan dalam projek Vite React menggunakan alat AI?
Apr 04, 2025 pm 01:45 PM
Bagaimana dengan cepat membina halaman front-end dalam pembangunan back-end? Sebagai pemaju backend dengan tiga atau empat tahun pengalaman, dia telah menguasai asas JavaScript, CSS dan HTML ...
