

Meningkatkan keupayaan penaakulan model bahasa besar ialah salah satu hala tuju penyelidikan semasa yang paling penting Dalam jenis tugasan ini, banyak model kecil yang dikeluarkan baru-baru ini nampaknya berprestasi baik dan boleh menangani tugasan sedemikian dengan baik. Contohnya, Microsoft Phi-3, Mistral 8x22B dan model lain.
Penyelidik menegaskan bahawa terdapat masalah utama dalam bidang semasa penyelidikan model besar: banyak kajian gagal menanda aras dengan tepat keupayaan LLM sedia ada. Ini menunjukkan bahawa kita perlu meluangkan lebih banyak masa untuk menilai dan menguji tahap keupayaan LLM semasa.

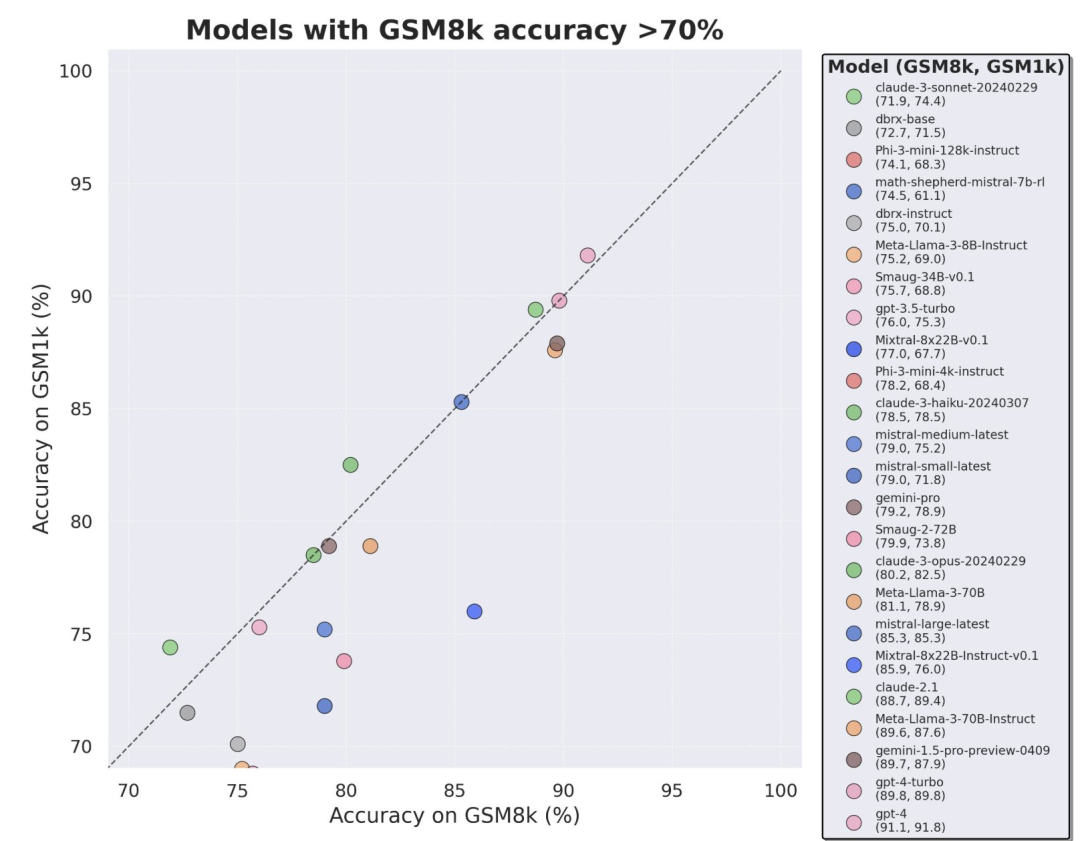
Ini kerana kebanyakan penyelidikan semasa menggunakan set ujian seperti GSM8k, MATH, MBPP, HumanEval, SWEBench, dll sebagai penanda aras. Memandangkan model dilatih pada set data besar yang dikikis daripada Internet, set data latihan mungkin mengandungi sampel yang sangat serupa dengan soalan dalam penanda aras.
Pencemaran ini boleh menyebabkan keupayaan penaakulan model disalah nilai - Mereka mungkin keliru dengan soalan semasa proses latihan dan kebetulan menyebut jawapan yang betul.
Sebentar tadi, kertas kerja oleh Scale AI menjalankan tinjauan mendalam tentang model besar yang paling popular, termasuk OpenAI's GPT-4, Gemini, Claude, Mistral, Llama, Phi, Abdin dan siri lain dengan jumlah parameter yang berbeza .
Hasil ujian mengesahkan syak wasangka yang meluas: banyak model dicemari oleh data penanda aras.
Tajuk kertas: Peperiksaan Teliti Prestasi Model Bahasa Besar pada Aritmetik Sekolah Gred
Pautan kertas: https://arxiv.org/pdf/2405.003
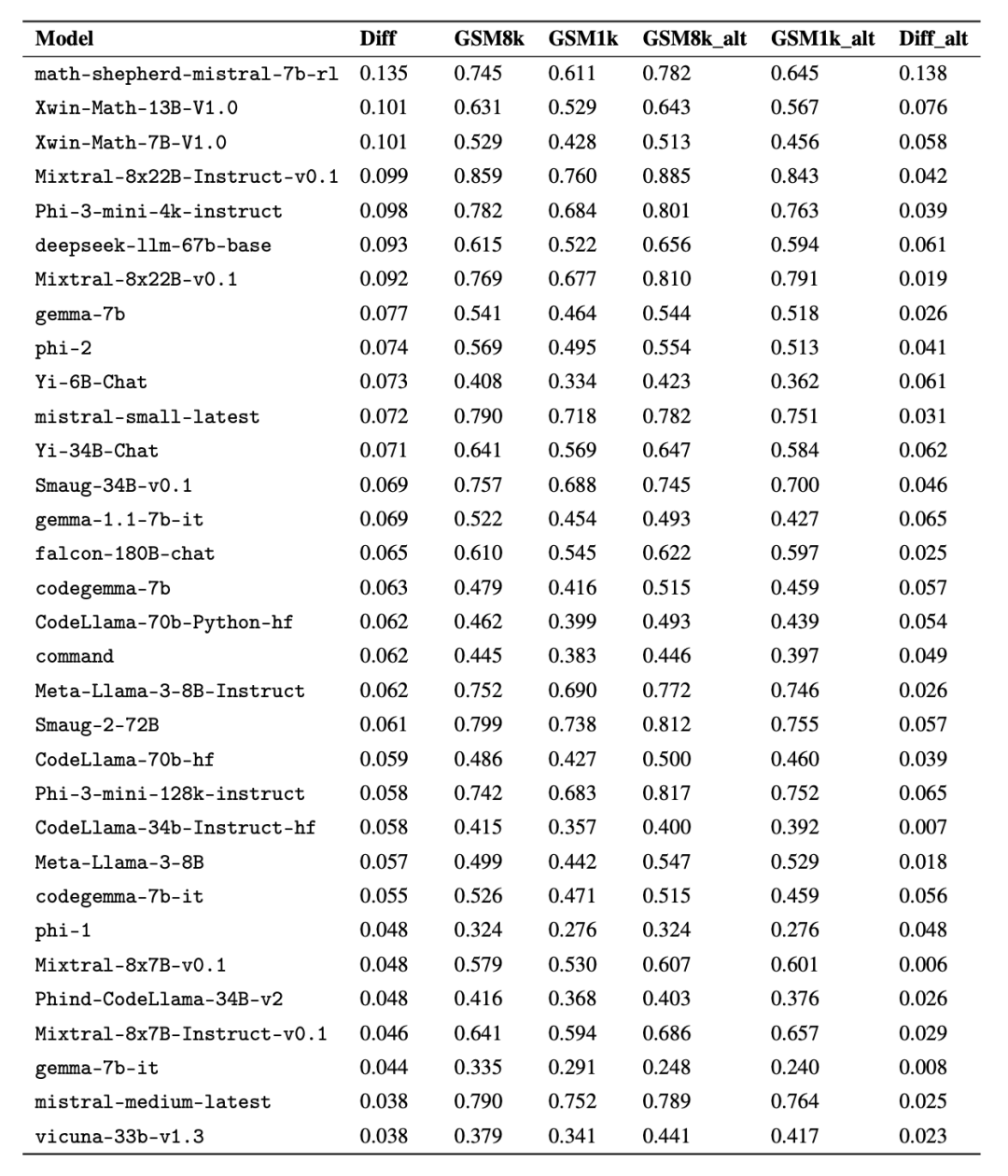
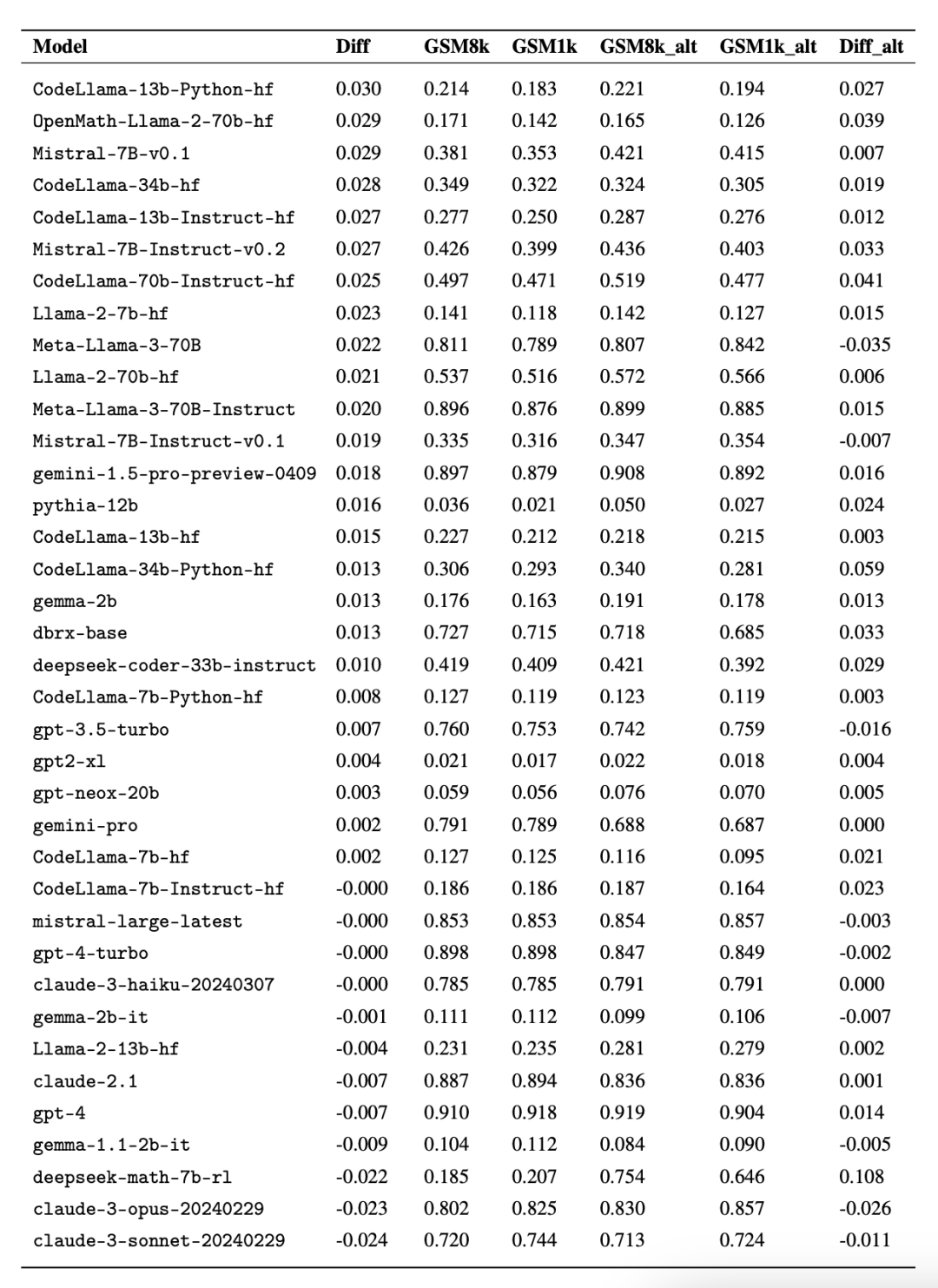
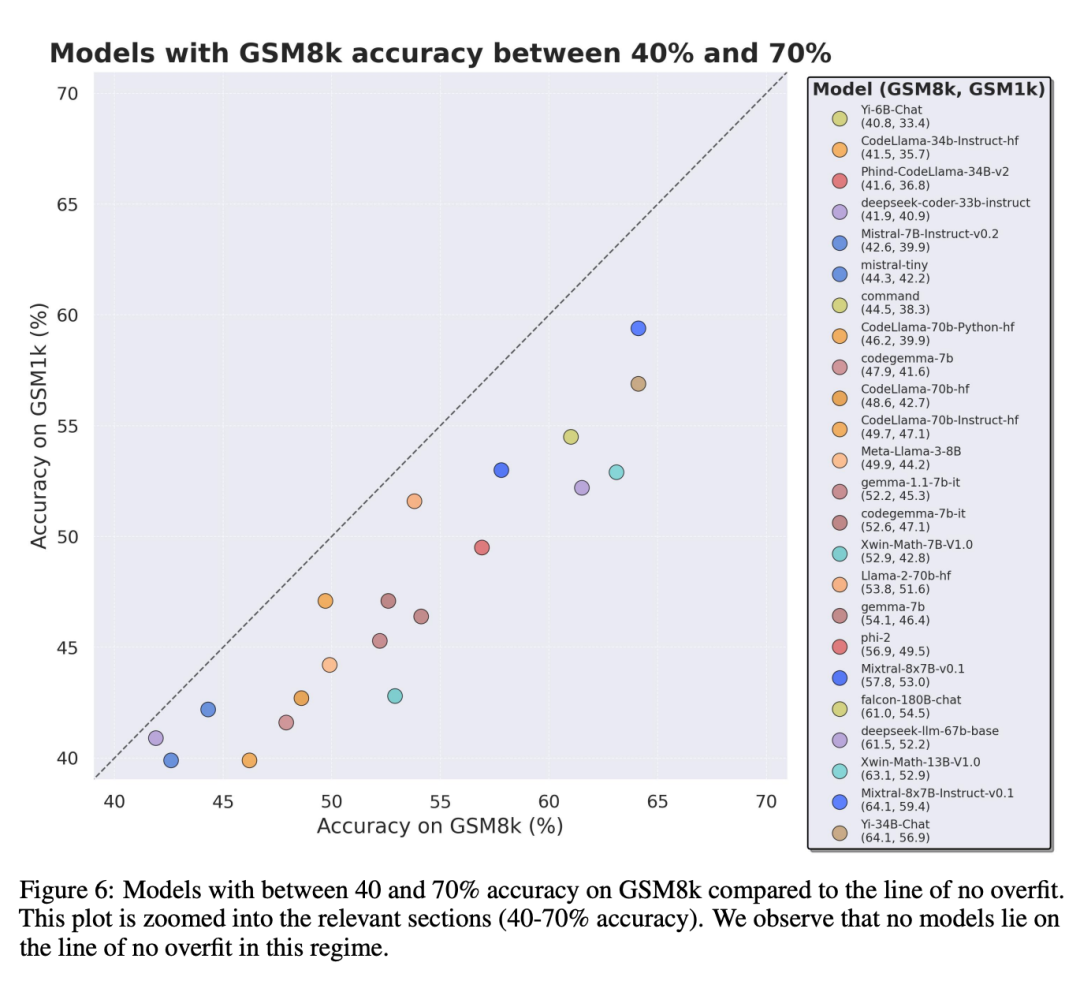
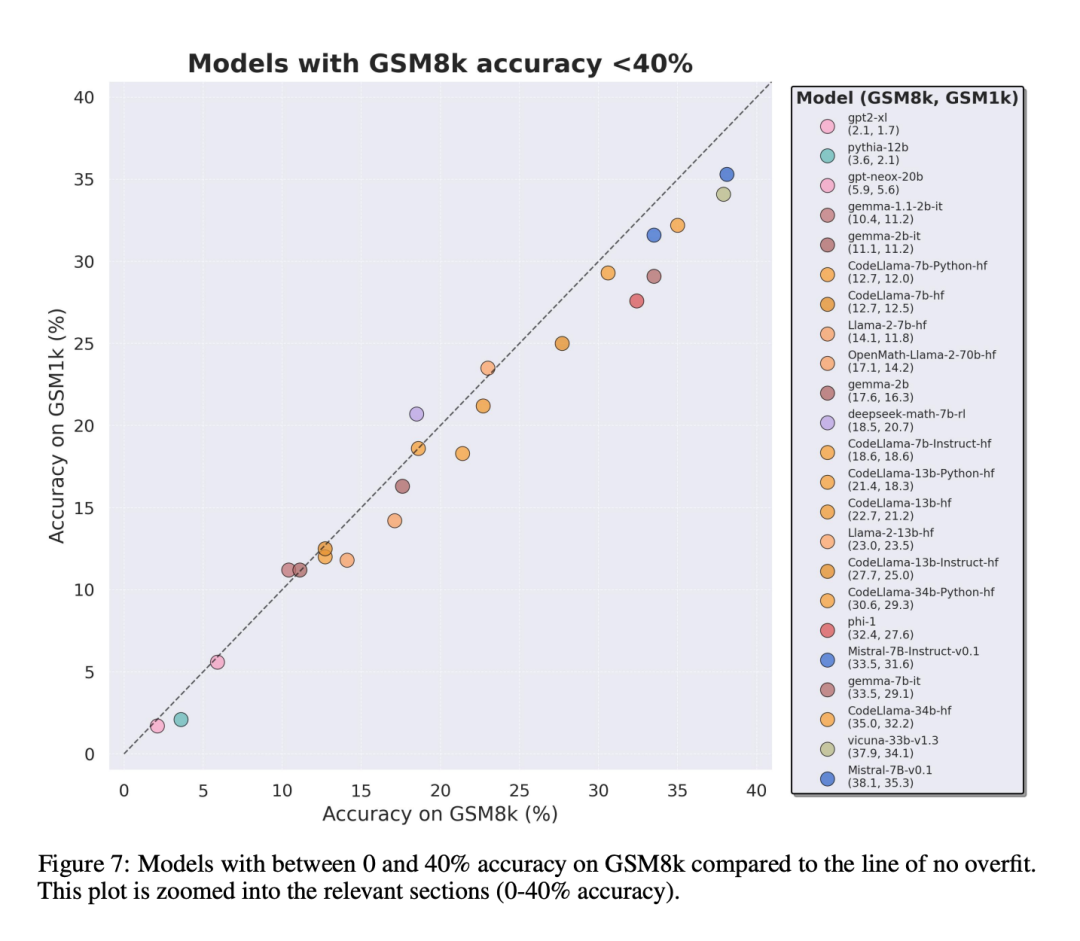
Terutamanya siri model Mistral dan Phi, yang terkenal dengan kuantiti yang kecil dan kualiti yang tinggi Menurut keputusan ujian GSM1k, hampir semua versi mereka menunjukkan bukti overfitting yang konsisten.
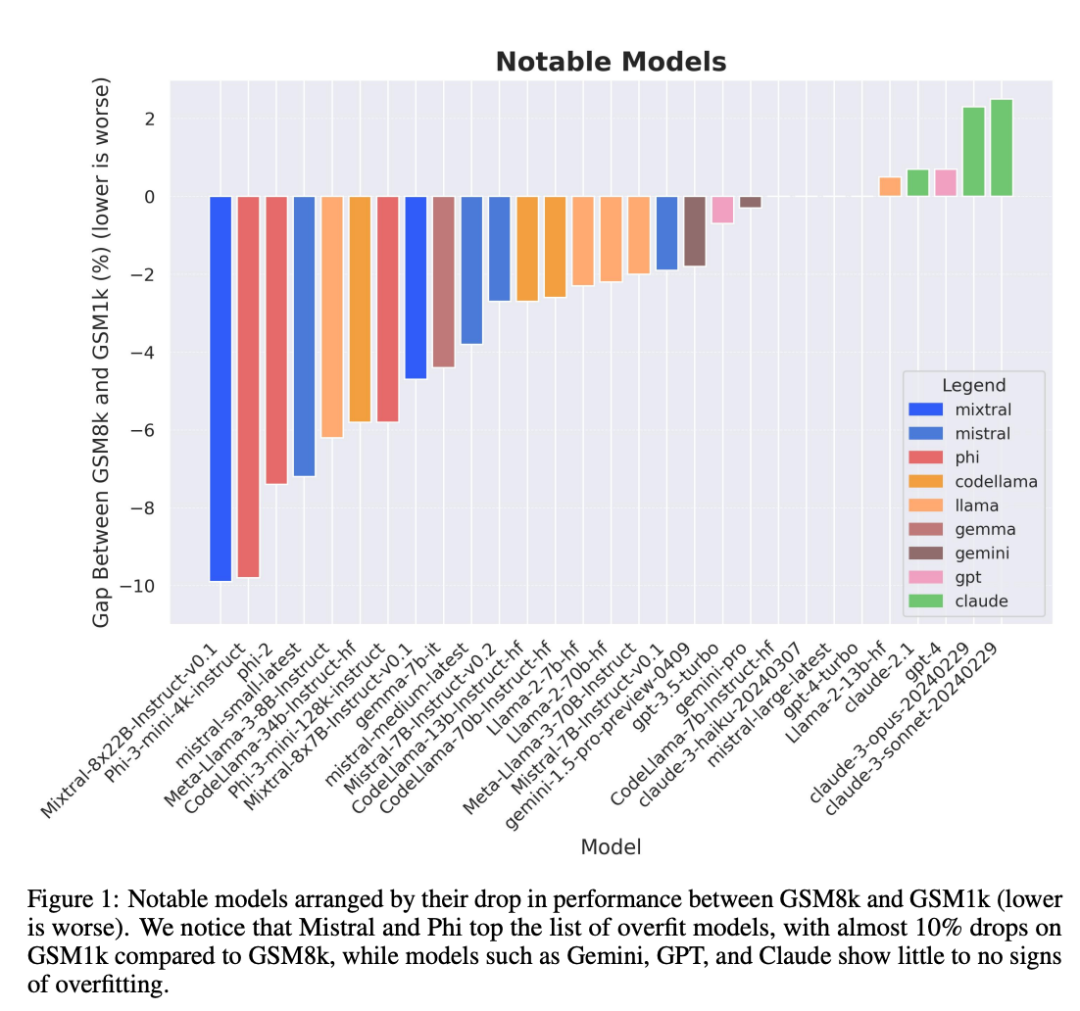 Analisis lanjut mendapati terdapat korelasi positif antara kebarangkalian model menjana sampel GSM8k dan jurang prestasinya antara GSM8k dan GSM1k (pekali korelasi r^2 = 0.32). Ini menunjukkan dengan kuat bahawa punca utama pemasangan lampau ialah model tersebut salah menilai sebahagian sampel dalam GSM8k.
Analisis lanjut mendapati terdapat korelasi positif antara kebarangkalian model menjana sampel GSM8k dan jurang prestasinya antara GSM8k dan GSM1k (pekali korelasi r^2 = 0.32). Ini menunjukkan dengan kuat bahawa punca utama pemasangan lampau ialah model tersebut salah menilai sebahagian sampel dalam GSM8k.
Selain itu, semua model, termasuk model yang paling banyak dipasang, masih berjaya membuat generalisasi kepada masalah matematik sekolah rendah yang baharu, walaupun kadangkala pada kadar kejayaan yang lebih rendah daripada data asas yang ditunjukkan.
 Skala AI pada masa ini tidak merancang untuk mengeluarkan GSM1k secara terbuka untuk mengelakkan isu pencemaran data yang serupa daripada berlaku pada masa hadapan. Mereka merancang untuk menjalankan penilaian berterusan secara tetap bagi semua LLM sumber terbuka dan tertutup utama, dan juga akan membuka sumber kod penilaian supaya kajian seterusnya boleh meniru keputusan dalam kertas.
Skala AI pada masa ini tidak merancang untuk mengeluarkan GSM1k secara terbuka untuk mengelakkan isu pencemaran data yang serupa daripada berlaku pada masa hadapan. Mereka merancang untuk menjalankan penilaian berterusan secara tetap bagi semua LLM sumber terbuka dan tertutup utama, dan juga akan membuka sumber kod penilaian supaya kajian seterusnya boleh meniru keputusan dalam kertas.
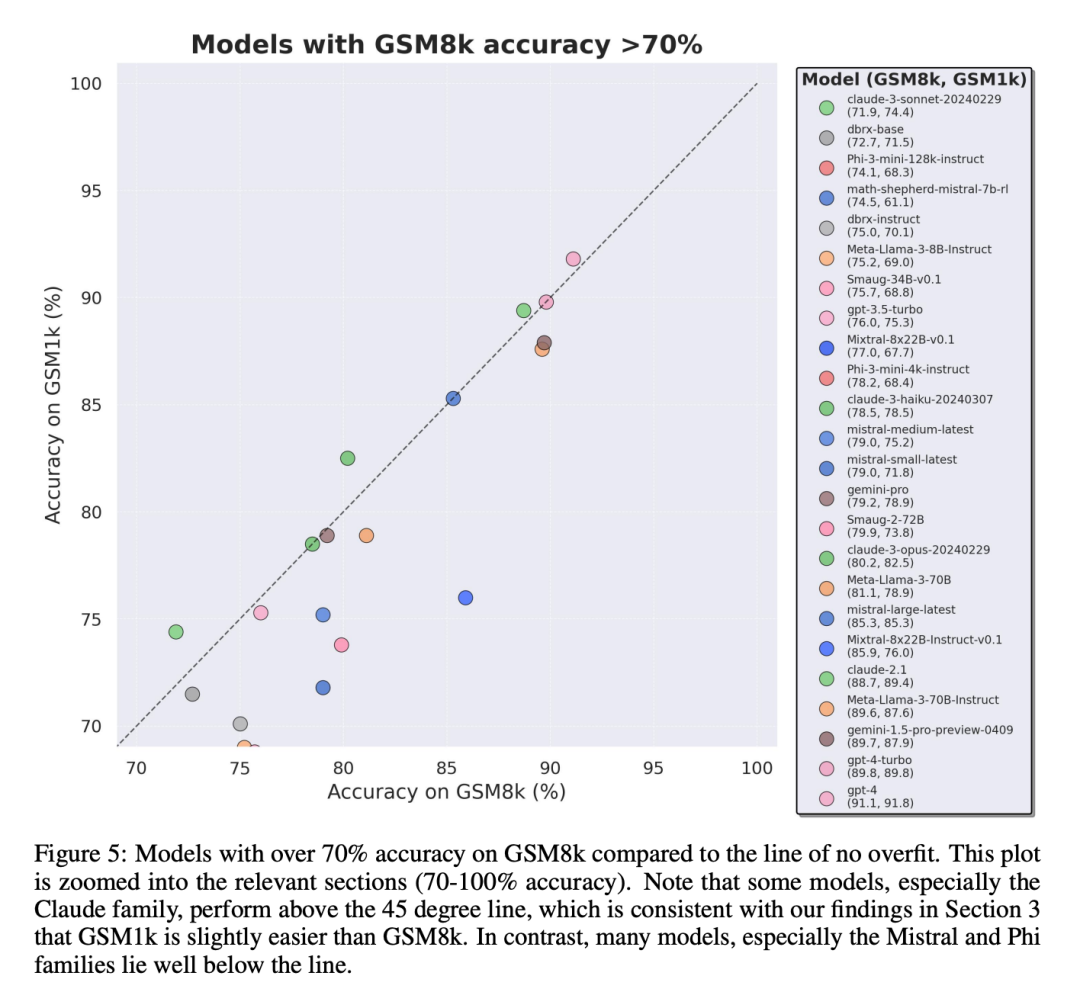
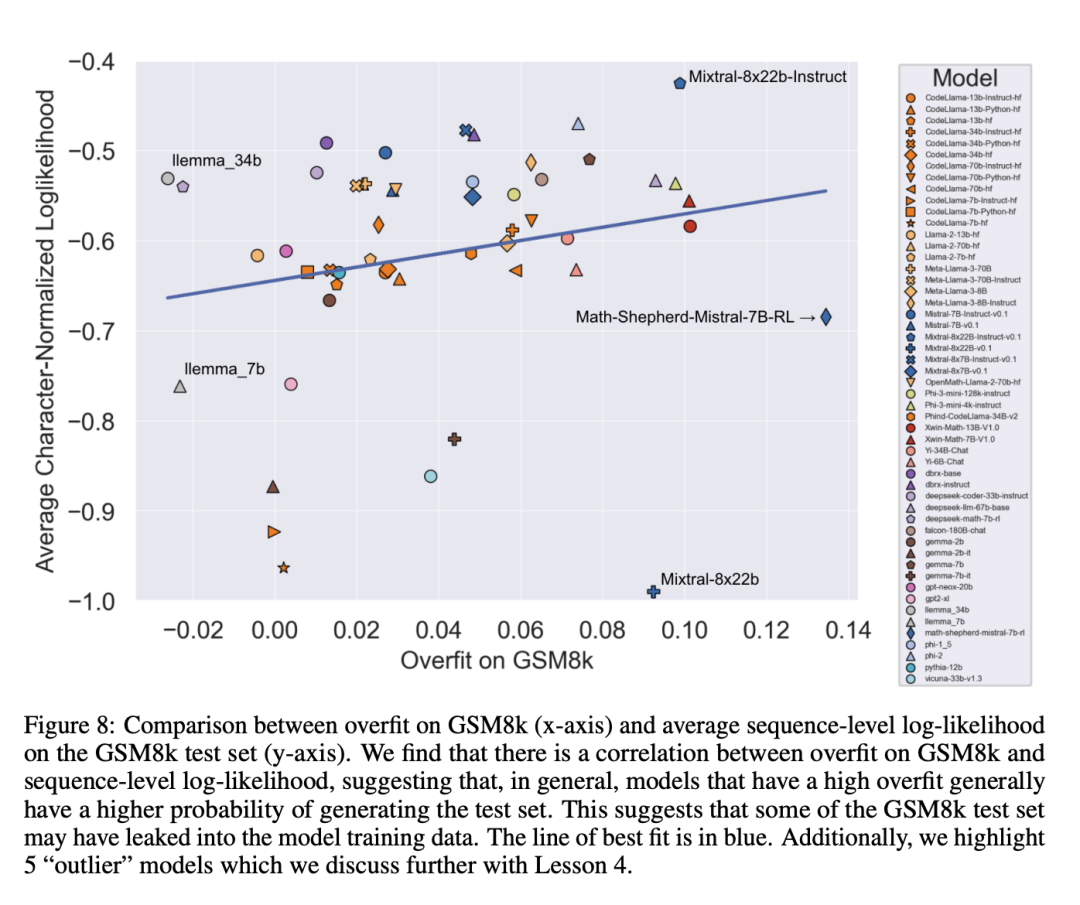
GSM1k mengandungi 1250 soalan matematik sekolah rendah. Masalah ini boleh diselesaikan dengan hanya penaakulan matematik asas. Skala AI menunjukkan setiap anotasi manusia 3 contoh soalan daripada GSM8k dan meminta mereka bertanya soalan baharu dengan kesukaran yang sama, menghasilkan set data GSM1k. Penyelidik meminta juru anotasi manusia supaya tidak menggunakan sebarang konsep matematik lanjutan dan hanya menggunakan aritmetik asas (tambah, tolak, darab dan bahagi) untuk merumus soalan. Seperti GSM8k, penyelesaian kepada semua masalah adalah integer positif. Tiada model bahasa digunakan dalam pembinaan set data GSM1k. Untuk mengelakkan isu pencemaran data dengan set data GSM1k, Scale AI tidak akan mengeluarkan set data secara terbuka pada masa ini, tetapi akan membuka sumber rangka kerja penilaian GSM1k, yang berdasarkan EleutherAI's LM Evaluation Harness. Tetapi Scale AI berjanji, Set data GSM1k yang lengkap akan dikeluarkan di bawah lesen MIT selepas satu daripada dua syarat berikut dipenuhi terlebih dahulu: (1) Terdapat tiga model sumber terbuka berdasarkan garis keturunan model asas pra-latihan yang berbeza. Mencapai ketepatan 95% pada GSM1k; (2) Menjelang akhir tahun 2025. Pada ketika itu, kemungkinan besar bahawa matematik sekolah rendah tidak lagi menjadi penanda aras yang sah untuk menilai prestasi LLM. Untuk menilai model proprietari, penyelidik akan menerbitkan set data melalui API. Sebab bagi pendekatan keluaran ini ialah pengarang percaya bahawa vendor LLM secara amnya tidak menggunakan titik data API untuk melatih model model. Namun begitu, jika data GSM1k dibocorkan melalui API, pengarang telah mengekalkan titik data yang tidak muncul dalam set data GSM1k akhir, dan titik data sandaran ini akan dikeluarkan dengan GSM1k apabila syarat di atas dipenuhi. Mereka berharap keluaran penanda aras masa hadapan akan mengikut corak yang sama - tidak mengeluarkannya secara terbuka pada mulanya, tetapi berjanji untuk mengeluarkannya pada tarikh akan datang atau apabila syarat tertentu dipenuhi untuk mengelakkan manipulasi. Selain itu, walaupun Skala AI melakukan usaha terbaik untuk memastikan konsistensi maksimum antara GSM8k dan GSM1k. Tetapi set ujian GSM8k telah dikeluarkan secara terbuka dan digunakan secara meluas untuk ujian model, jadi GSM1k dan GSM8k hanyalah anggaran dalam keadaan ideal. Keputusan penilaian berikut diperoleh apabila pengedaran GSM8k dan GSM1k tidak betul-betul sama. Hasil penilaian Untuk menilai model, penyelidik menggunakan cawangan LM Evaluation Harness EleutherAI dan menggunakan tetapan lalai. Gesaan berjalan untuk masalah GSM8k dan GSM1k adalah sama Mereka memilih 5 sampel secara rawak daripada set latihan GSM8k, yang juga merupakan konfigurasi standard dalam medan ini (lihat Lampiran B untuk maklumat segera yang lengkap). Semua model sumber terbuka dinilai pada suhu 0 untuk memastikan kebolehulangan. Kit Penilaian LM mengekstrak jawapan berangka terakhir dalam respons dan membandingkannya dengan jawapan yang betul. Oleh itu, respons model yang menghasilkan jawapan "betul" dalam format yang tidak sepadan dengan sampel akan ditandakan sebagai tidak betul. Untuk model sumber terbuka, jika model itu serasi dengan pustaka, vLLM akan digunakan untuk mempercepatkan inferens model, jika tidak, pustaka HuggingFace standard akan digunakan untuk inferens secara lalai. Model sumber tertutup disoal melalui perpustakaan LiteLLM, yang menyatukan format panggilan API untuk semua model proprietari yang dinilai. Semua hasil model API adalah daripada pertanyaan antara 16 April dan 28 April 2024, dan gunakan tetapan lalai. Dari segi model yang dinilai, penyelidik memilihnya berdasarkan popularitinya, dan juga menilai beberapa model yang kurang dikenali yang mendapat kedudukan tinggi di OpenLLMLeaderboard. Menariknya, penyelidik menemui bukti undang-undang Goodhart dalam proses: banyak model berprestasi lebih teruk pada GSM1k berbanding GSM8k, menunjukkan bahawa mereka kebanyakannya memenuhi penanda aras GSM8k berbanding Benar-benar meningkatkan keupayaan penaakulan model. Prestasi semua model ditunjukkan dalam Lampiran D di bawah. Untuk membuat perbandingan yang adil, penyelidik membahagikan model mengikut prestasi mereka pada GSM8k dan membandingkannya dengan model lain yang mempunyai prestasi yang sama (Rajah 5, Rajah 6, Rajah 7). Apakah kesimpulan yang dibuat? Walaupun penyelidik memberikan hasil penilaian objektif bagi pelbagai model, mereka juga menyatakan bahawa mentafsir keputusan penilaian, seperti mentafsir mimpi, selalunya merupakan tugas yang sangat subjektif. Di bahagian terakhir kertas kerja, mereka menghuraikan empat implikasi penilaian di atas dengan cara yang lebih subjektif: Kesimpulan 1: Sesetengah keluarga model secara sistematik terlalu sesuai Walaupun selalunya sukar untuk ditentukan dari satu titik data. atau kesimpulan versi model, tetapi meneliti keluarga model dan memerhati corak overfitting membolehkan pernyataan yang lebih muktamad dibuat. Sesetengah keluarga model, termasuk Phi dan Mistral, menunjukkan arah aliran ke arah prestasi sistem yang lebih kukuh pada GSM8k berbanding GSM1k dalam hampir setiap versi dan saiz model. Terdapat keluarga model lain seperti Yi, Xwin, Gemma dan CodeLlama yang turut memaparkan corak ini pada tahap yang lebih rendah. Kesimpulan 2: Model lain, terutamanya model canggih, tidak menunjukkan tanda-tanda overfitting Banyak model menunjukkan tanda-tanda kecil overfitting di semua kawasan prestasi, terutamanya termasuk Mistral Large All yang proprietari terdepan atau hampir terkemuka- model tepi dalam , kelihatan berprestasi serupa pada GSM8k dan GSM1k. Dalam hal ini, para penyelidik mengemukakan dua kemungkinan hipotesis: 1) Model Frontier mempunyai keupayaan penaakulan yang cukup maju, jadi walaupun masalah GSM8k telah muncul dalam set latihan mereka, mereka boleh membuat generalisasi kepada masalah baharu 2) Model Frontier Pembina model mungkin lebih berhati-hati tentang pencemaran data. Walaupun mustahil untuk melihat set latihan setiap model dan menentukan andaian ini, satu bukti yang menyokong yang pertama ialah Mistral Large ialah satu-satunya model dalam siri Mistral yang tidak menunjukkan tanda-tanda overfitting. Andaian bahawa Mistral hanya memastikan model terbesarnya bebas daripada pencemaran data nampaknya tidak mungkin, jadi para penyelidik memilih bahawa LLM yang cukup berkuasa juga akan mempelajari keupayaan inferens asas semasa latihan. Jika model belajar menaakul dengan cukup baik untuk menyelesaikan masalah kesukaran yang diberikan, ia akan dapat membuat generalisasi kepada masalah baharu walaupun GSM8k terdapat dalam set latihannya. Kesimpulan 3: Model overfitting masih mempunyai kebolehan untuk menaakul Salah satu kebimbangan ramai penyelidik tentang model overfitting ialah model tidak boleh melakukan penaakulan dan hanya menghafal jawapan dalam data latihan, tetapi kertas ini Keputusan tidak menyokong hipotesis ini. Hakikat bahawa model berlebihan tidak bermakna keupayaan inferensnya lemah, ia bermakna ia tidak sebaik yang ditunjukkan oleh penanda aras. Malah, penyelidik telah mendapati bahawa banyak model yang terlalu dipasang masih mampu menaakul dan menyelesaikan masalah baru. Sebagai contoh, ketepatan Phi-3 menurun hampir 10% antara GSM8k dan GSM1k, tetapi ia masih menyelesaikan lebih daripada 68% masalah GSM1k dengan betul — masalah yang pastinya tidak muncul dalam pengedaran latihannya. Prestasi ini serupa dengan model yang lebih besar seperti dbrx-instruct, yang mengandungi hampir 35 kali ganda bilangan parameter. Begitu juga, walaupun mengambil kira overfitting, model Mistral masih merupakan salah satu model sumber terbuka terkuat. Ini memberikan lebih banyak bukti untuk kesimpulan kertas ini bahawa model yang cukup berkuasa boleh mempelajari inferens asas walaupun data penanda aras secara tidak sengaja bocor ke dalam pengedaran latihan, yang mungkin berlaku dengan kebanyakan model overfit. Kesimpulan 4: Pencemaran data mungkin bukan penjelasan lengkap tentang overfitting Hipotesis semula jadi yang apriori ialah punca utama overfitting ialah pencemaran data, contohnya, dalam pra-latihan atau arahan untuk mencipta model Untuk bahagian penalaan halus, set ujian telah bocor. Penyelidikan terdahulu telah menunjukkan bahawa model memberikan kemungkinan log yang lebih tinggi kepada data yang telah mereka lihat semasa latihan (Carlini et al. [2023]). Penyelidik menguji hipotesis bahawa pencemaran data adalah punca lampiran dengan mengukur kebarangkalian model menjana sampel daripada set ujian GSM8k dan membandingkan tahap overfittingnya berbanding GSM8k dan GSM1k. Penyelidik mengatakan bahawa pencemaran data mungkin bukan punca keseluruhannya. Mereka memerhatikan ini dengan beberapa penyimpangan. Melihat lebih dekat pada outlier ini mendedahkan bahawa model dengan kemungkinan log terendah bagi setiap aksara (Mixtral-8x22b) dan model dengan kemungkinan log tertinggi bagi setiap aksara (Mixtral-8x22b-Instruct) bukan hanya varian model yang sama , dan mempunyai tahap overfitting yang serupa. Lebih menarik, model yang paling banyak dipasang (Math-Shepherd-Mistral-7B-RL (Yu et al. [2023])) mempunyai kemungkinan log yang agak rendah bagi setiap aksara (Math Shepherd menggunakan data sintetik Melatih model ganjaran pada data peringkat proses ). Oleh itu, penyelidik membuat hipotesis bahawa proses pemodelan ganjaran mungkin telah membocorkan maklumat tentang rantai inferens yang betul untuk GSM8k, walaupun isu itu sendiri tidak pernah muncul dalam set data. Akhirnya, mereka mendapati bahawa model Llema mempunyai kemungkinan log yang tinggi dan overfitting minimum. Memandangkan model ini adalah sumber terbuka dan data latihannya diketahui, beberapa kejadian masalah GSM8k muncul dalam korpus latihan, seperti yang diterangkan dalam kertas Llema. Walau bagaimanapun, penulis mendapati bahawa beberapa kejadian ini tidak membawa kepada overfitting yang teruk. Kewujudan outlier ini menunjukkan bahawa overfitting pada GSM8k bukan semata-mata disebabkan oleh pencemaran data, tetapi mungkin disebabkan oleh cara tidak langsung lain, seperti pembina model mengumpul data dengan sifat yang serupa dengan garis dasar sebagai data latihan, atau berdasarkan Prestasi pada penanda aras memilih pusat pemeriksaan model akhir, walaupun model itu sendiri mungkin tidak melihat dataset GSM8k pada bila-bila masa semasa latihan. Perkara sebaliknya juga berlaku: sejumlah kecil pencemaran data tidak semestinya membawa kepada pemasangan berlebihan. Untuk butiran penyelidikan lanjut, sila rujuk kertas asal. 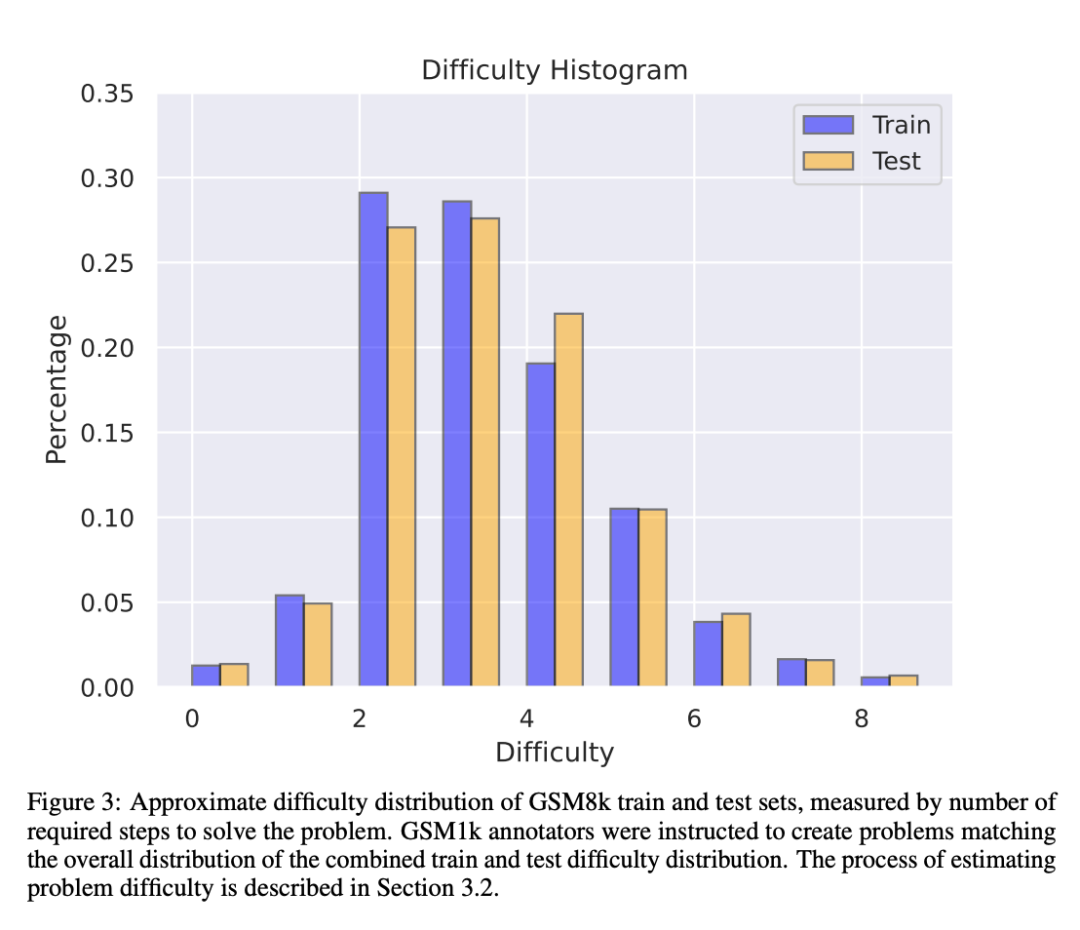
Atas ialah kandungan terperinci Akhirnya, seseorang menyiasat pemasangan model kecil yang berlebihan: dua pertiga daripada mereka mempunyai pencemaran data, dan Microsoft Phi-3 dan Mixtral 8x22B dinamakan. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!

















![[Web front-end] Permulaan pantas Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



