

Kemunculan model bahasa kecil adalah untuk mengimbangi kelemahan latihan mahal dan inferens model bahasa besar, tetapi ia juga mempunyai hakikat bahawa prestasinya menurun selepas latihan ke peringkat tertentu (fenomena tepu), jadi sebabnya untuk fenomena ini adalah Apa? Bolehkah ia diatasi dan dieksploitasi untuk meningkatkan prestasi model bahasa kecil?
Kemajuan terkini dalam bidang pemodelan bahasa terletak pada pra-latihan rangkaian saraf berparameter tinggi pada korpora teks web berskala sangat besar. Dalam amalan, menggunakan model sedemikian untuk latihan dan inferens boleh memakan kos yang tinggi, mendorong penggunaan model alternatif yang lebih kecil. Walau bagaimanapun, telah diperhatikan bahawa model yang lebih kecil mungkin mengalami ketepuan dan fenomena yang dicirikan oleh penurunan keupayaan dan dataran tinggi pada beberapa peringkat latihan lanjutan.
Satu kertas kerja baru-baru ini mendapati bahawa fenomena jumlah tepu ini boleh dijelaskan oleh ketidakpadanan antara dimensi pendam model yang lebih kecil dan kedudukan tinggi taburan kebarangkalian konteks sasaran. Ketidakpadanan ini menjejaskan prestasi kepala ramalan linear yang digunakan dalam model ini dengan mengeksploitasi prestasi model yang dipanggil softmax bottlenecks.

Pautan kertas: https://arxiv.org/pdf/2404.07647.pdf
Kertas ini mengukur kesan kesesakan softmax di bawah tetapan yang berbeza dan mendapati bahawa model berdasarkan kurang daripada 1000 dimensi tersembunyi cenderung menjadi pra -representasi terpendam merosot yang terlatih diterima pakai pada peringkat seterusnya, menyebabkan prestasi penilaian berkurangan.
Pengenalan
Masalah kemerosotan perwakilan adalah fenomena biasa yang mempengaruhi banyak mod seperti kaedah pembelajaran diselia sendiri bagi data teks. Pemerhatian perwakilan pertengahan model bahasa mendedahkan kebolehubahan sudut rendahnya (atau anisotropi), atau dimensi luar biasa yang timbul semasa latihan. Walau bagaimanapun, pemerhatian ini kebanyakannya dibuat pada model berskala yang agak kecil dengan dimensi yang setanding dengan model keluarga seperti BERT atau GPT-2.
Model ini biasanya terdiri daripada rangkaian saraf f_θ yang menerima jujukan token:
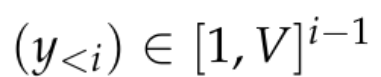
dan menjana perwakilan konteks dimensi yang agak rendah dalam R^d, dengan d ialah dimensi tersembunyi model. Mereka kemudiannya bergantung pada kepala pemodelan bahasa yang menghasilkan logaritma kebarangkalian token konteks. Pilihan biasa untuk kepala pemodelan bahasa ialah lapisan linear dengan parameter W ∈ R^(V×d), dengan V ialah bilangan token yang mungkin. Jadi taburan kebarangkalian yang terhasil untuk token seterusnya ialah 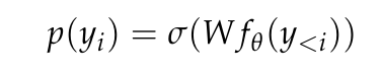 di mana σ ialah fungsi softmax.
di mana σ ialah fungsi softmax.
Dalam bidang pemodelan bahasa, trend semasa adalah untuk melanjutkan kaedah pra-latihan generatif yang diperkenalkan oleh GPT-2, yang bermaksud model saraf latihan yang terdiri daripada berbilion parameter pada korpus besar teks web. Walau bagaimanapun, latihan dan penggunaan model berparameter tinggi ini menimbulkan isu berkaitan tenaga dan perkakasan, yang memerlukan mencari cara untuk mencapai tahap prestasi yang serupa dengan model yang lebih kecil.
Walau bagaimanapun, penilaian suite model Pythia menunjukkan bahawa melatih model kecil pada korpora yang sangat besar boleh membawa kepada ketepuan, yang ditunjukkan oleh kemerosotan prestasi lewat dalam pra-latihan. Kertas kerja ini meneroka fenomena tepu ini melalui lensa kemerosotan perwakilan dan mendapati bahawa terdapat korelasi yang kuat antara kedua-dua fenomena, sambil menunjukkan lagi bahawa kemerosotan perwakilan berlaku dalam kepala pemodelan bahasa bagi model kecil dan telah ditunjukkan secara teori dan empirik di atas bagaimana pengepala pemodelan bahasa linear boleh menjadi hambatan prestasi untuk seni bina berdasarkan dimensi tersembunyi yang kecil.
Fenomena Ketepuan Model Bahasa
Kertas kerja ini mula-mula mengesahkan bahawa ketepuan prestasi pusat pemeriksaan Pythia sememangnya boleh diperhatikan dan dikira, kerana ia adalah satu-satunya pusat pemeriksaan perantaraan yang diterbitkan untuk pelbagai saiz model. Makalah ini mengukur entropi silang pusat pemeriksaan Pythia pada 50,000 token yang diambil secara rawak daripada set data pra-latihan mereka (iaitu, The Pile).
Ia boleh dilihat dengan jelas dalam Rajah 1a bahawa walaupun model 410 juta parameter menghadapi tepu, ditunjukkan oleh peningkatan kehilangan domain pada peringkat latihan lanjutan.
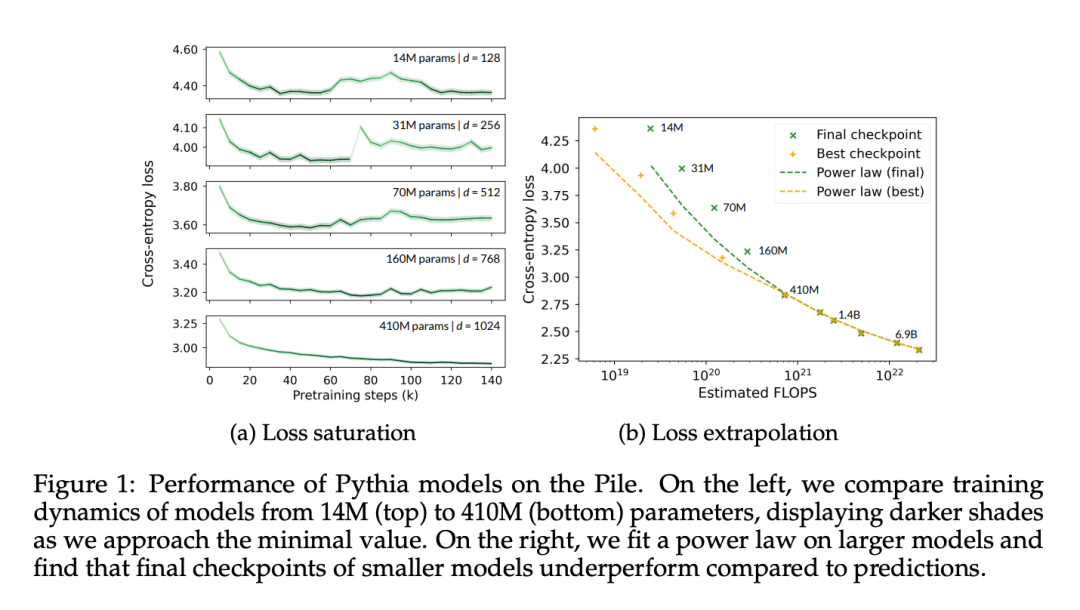
Dalam Rajah 1b, artikel ini sesuai dengan titik data model bermula daripada 410 juta parameter mengikut kaedah Hoffmann et al (2022), dan hanya mengoptimumkan pemalar yang berkaitan dengan model (A dan α). , Semasa menggunakan semula semua nilai lain (B = 410.7, β = 0.28, E = 1.69). Di sini kita menyemak hubungan antara kiraan parameter N dan kiraan token T yang diberikan oleh Hoffmann et al (2022):

Kertas ini mendapati parameter optimum ialah A = 119.09 dan α = 0.246. Pengarang menunjukkan keluk terpasang kiraan token sepadan dengan pusat pemeriksaan optimum dan akhir. Dapat diperhatikan bahawa prestasi pusat pemeriksaan akhir adalah secara purata kira-kira 8% lebih rendah daripada nilai ekstrapolasi. Pusat pemeriksaan pengurangan kerugian (optimum) dijangka lebih rendah daripada kaedah ekstrapolasi disebabkan penyejukan kadar pembelajaran yang tidak lengkap, tetapi prestasinya hanya kira-kira 4% lebih rendah daripada kaedah ekstrapolasi.
Fenomena ketepuan prestasi yang serupa juga diperhatikan dalam set data yang digunakan untuk penilaian alat penilaian model bahasa (LM Evaluation Harness), seperti ditunjukkan dalam Jadual 1.

Ketepuan prestasi ialah Ketepuan Kedudukan
Skala Anisotropi
Anisotropi ialah satu bentuk kemerosotan perwakilan yang diperhatikan dalam pelbagai model kebolehubahan bersudut tertentu lapisan. Penyelidikan terdahulu (Ethayarajh, 2019; Godey et al., 2024) menyatakan bahawa hampir semua lapisan model bahasa cacat kecil adalah anisotropik. Cara biasa untuk mengukur anisotropi dalam set perwakilan vektor H ialah persamaan kosinus purata:
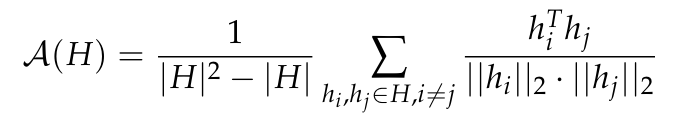
Walau bagaimanapun, tidak jelas sama ada anisotropi mempengaruhi model yang mempunyai lebih satu bilion parameter. Untuk menyelesaikan masalah ini, kertas kerja ini mengira purata persamaan kosinus antara lapisan untuk satu siri perwakilan perantaraan model iaitu GPT-2, OPT, Pythia dan Gemma. Artikel ini menggunakan subsampel The Pile kerana diandaikan bahawa domain set data ini termasuk atau sepadan dengan domain set data pra-latihan yang digunakan dalam suite ini.
Dalam Rajah 2, boleh diperhatikan bahawa kebanyakan lapisan kebanyakan model Transformer adalah anisotropik sedikit sebanyak, tanpa mengira skalanya. Walau bagaimanapun, nampaknya terdapat dikotomi dalam lapisan terakhir, di mana modelnya sama ada hampir isotropik atau sangat anisotropik. Makalah ini menyatakan bahawa dikotomi ini konsisten dengan salah satu fenomena tepu suite Pythia, di mana hanya model dengan 160 juta parameter atau kurang dipengaruhi oleh anisotropi lapisan terakhir.
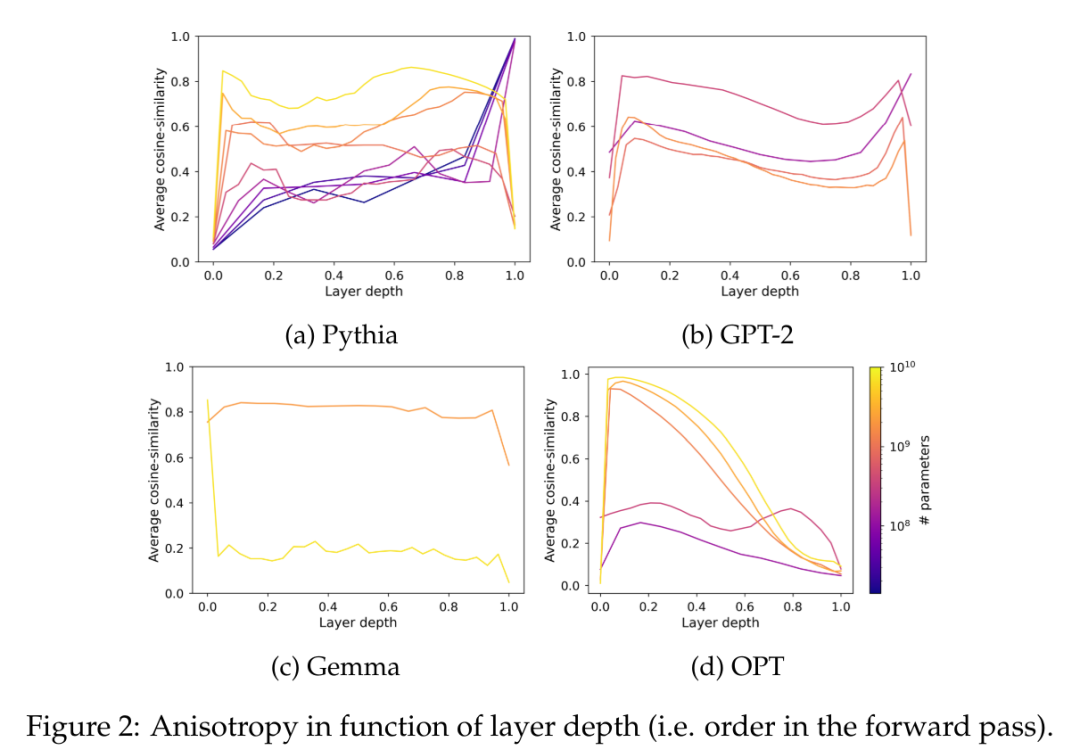
Artikel ini mengkaji dinamik latihan anisotropi dalam suite Pythia dan membandingkannya dengan fenomena tepu dalam Rajah 3.
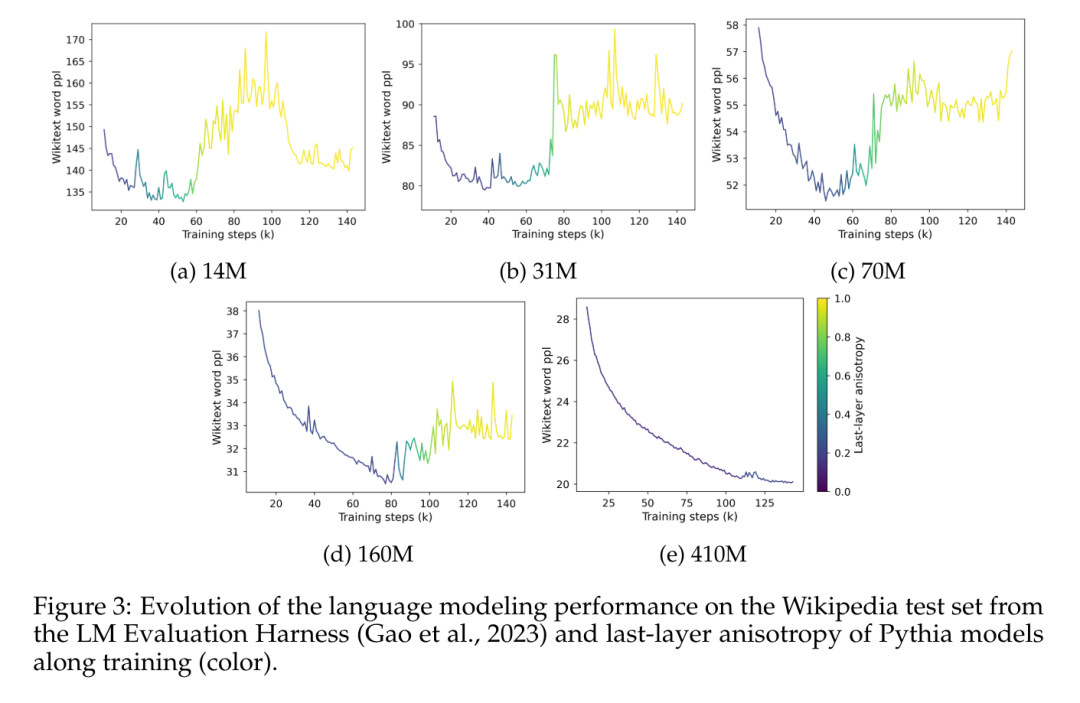
Rajah 3 jelas menunjukkan korelasi yang jelas antara kemunculan ketepuan prestasi dan kemunculan anisotropi dalam perwakilan lapisan terakhir model. Ia juga menunjukkan peningkatan mendadak dalam anisotropi berhampiran titik tepu semasa latihan. Apa yang diperhatikan di sini ialah dalam korpus dalam domain tertentu, model itu kehilangan prestasi dengan cepat apabila tepu dan nampaknya tidak pernah pulih sepenuhnya daripada letupan ini.
Tepu nilai tunggal
Min persamaan kosinus ialah ukuran keseragaman taburan yang berharga, tetapi termasuk metrik lain boleh membantu menangkap kerumitan manifold tertentu dengan lebih baik. Tambahan pula, ia hanya memfokuskan pada pembenaman output model bahasa dan bukan pada pemberatnya. Bahagian ini memanjangkan analisis kertas ini dengan mengkaji taburan nilai tunggal bagi kepala pemodelan bahasa untuk menghubungkan pemerhatian empirikal kepada penemuan teori kertas ini.
Rajah 4 menunjukkan taburan nilai tunggal di sepanjang berat lapisan ramalan akhir W semasa latihan:
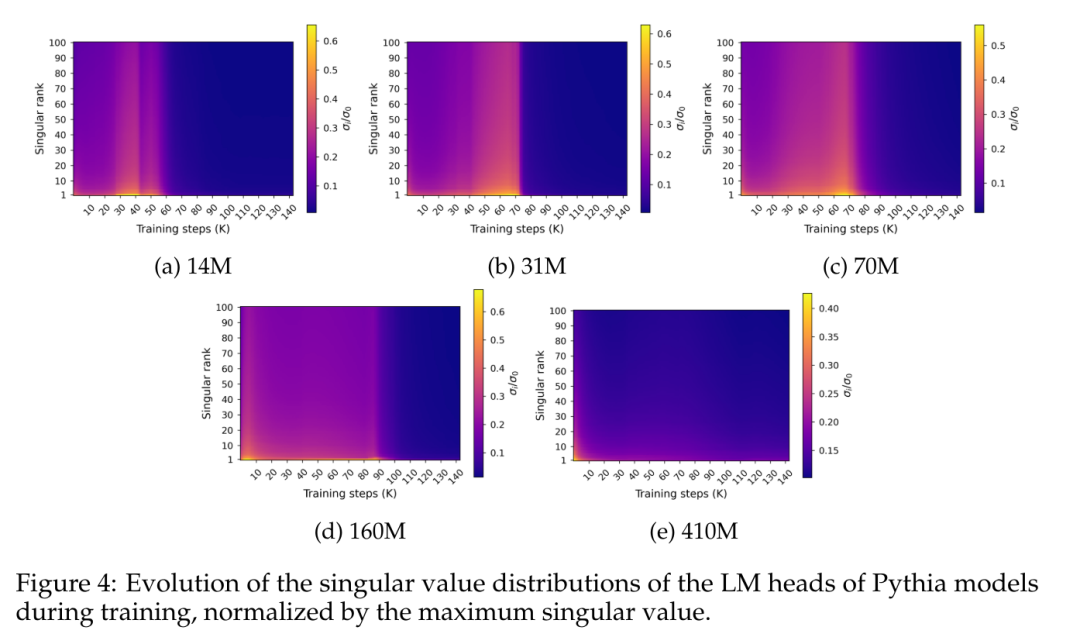
Rajah 4 mendedahkan corak ketepuan spektrum tertentu yang berlaku lebih kurang serentak dengan ketepuan prestasi. Angka tersebut menunjukkan bahawa taburan nilai tunggal secara beransur-ansur mendatar semasa proses latihan, hampir mencapai keseragaman, dan kemudian tiba-tiba berkembang menjadi taburan berduri dengan nilai tunggal terbesar yang relatif tinggi berbanding taburan lain.
Untuk mengukur gelagat ini dengan lebih tepat, makalah ini menggunakan metrik entropi tunggal, dikira sebagai perbezaan Kullback-Leibler antara taburan nilai tunggal ternormal dan taburan seragam.
Rajah 5 menunjukkan cara pengedaran tunggal berubah secara berbeza untuk model yang menggunakan kurang daripada 410 juta parameter berbanding model yang menggunakan parameter yang lebih besar. Ketua model kecil melihat pengagihan nilai tunggal mereka secara beransur-ansur menjadi lebih seragam, sehingga mereka tiba-tiba merosot, yang sekali lagi berkorelasi dengan prestasi model bahasa yang merosot. Pengagihan nilai tunggal model yang lebih besar cenderung untuk menjadi lebih stabil dan tidak menunjukkan corak monotonik yang jelas sepanjang latihan. Dimensi bahasa dan kesesakan Softmax terlibat dalam pengoptimuman telah dipersoalkan. Bahagian ini mencadangkan untuk mengukur secara empirikal nilai kritikal pangkat kepala LM dan menganggarkan dimensi taburan kebarangkalian kontekstual bahawa output kepala ini harus dipadankan.
Untuk mengukur secara empirikal impak kedudukan kepala linear, kertas kerja ini mencadangkan untuk melatih ketua terhad pangkat pada perwakilan kontekstual terlatih yang diperoleh daripada model bahasa yang sangat parameter. Untuk mengawal kedudukan maksimum r, pertimbangkan kepala bentuk W = AB ∈ R^(V×d), di mana pekali A ∈ R^(V×r) dan B ∈ R^(r×d) bermula dari N(0 ,1) diekstrak (d ialah dimensi tersembunyi model). Kedudukan matriks W ini diimbas pada julat nilai yang dikekang oleh parameter r ∈ [1, d].
Dengan membekukan model bahasa dan melatih ketua terhad pangkat pada kira-kira 150 juta token sambil melaraskan kadar pembelajaran agar sesuai dengan bilangan parameter yang boleh dilatih.
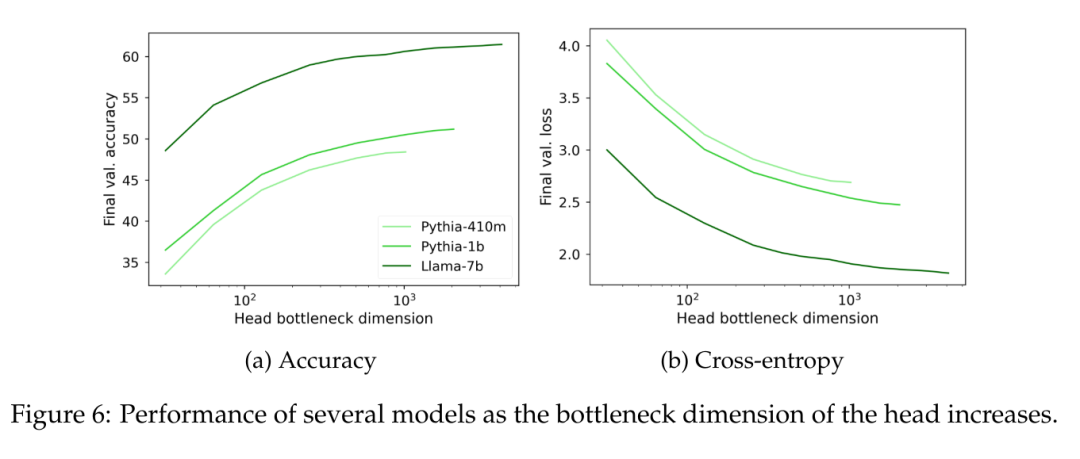
Boleh diperhatikan dalam Rajah 6 bahawa tanpa mengira saiz model, apabila pangkat kepala pemodelan bahasa W jatuh di bawah 1000, kebingungan mula berkurangan dengan ketara. Ini menunjukkan bahawa untuk model dengan dimensi tersembunyi yang lebih besar, kepala bukanlah halangan prestasi utama, tetapi untuk model dengan dimensi tersembunyi yang lebih kecil ia mungkin menjejaskan prestasi tanpa mengira kualiti perwakilan output.
Satu lagi faktor menarik ialah dimensi yang wujud bagi data anggaran itu sendiri. Untuk mengelakkan kemungkinan kesan yang berkaitan dengan bias induktif tertentu, makalah ini melatih model bahasa 5 gram yang naif pada beberapa set data dengan liputan berbeza (IMDb, Wikitext dan The Pile), menggunakan dua saiz perbendaharaan kata yang berbeza (30k token untuk Llama-2, 50k token untuk Pythia). Memandangkan C diperhatikan 5-gram, kertas ini mempertimbangkan matriks W ∈ R^(C×V), di mana setiap baris ialah taburan kebarangkalian token yang mungkin diberi 4 token, dan mengira taburan nilai tunggalnya, seperti Terashima (2003).
Rajah 7 melaporkan ralat W, ralat anggaran minimum untuk matriks W pangkat d yang diramalkan oleh teorem Eckart-Young-Mirsky (lihat Lemma 5.2) dan dinormalkan kepada norma Frobenius bagi W. . Di sini kita akan menganalisis hubungan antara dimensi dan prestasi kepala pemodelan bahasa linear yang ideal dari perspektif teori.
Bahagian ini bertujuan untuk mengenal pasti pautan formal antara dimensi sedia ada taburan konteks dan kesesakan prestasi yang boleh dikaitkan dengan dimensi perwakilan output model bahasa yang lebih rendah. Untuk tujuan ini, kepala pemodelan bahasa yang dioptimumkan pada perwakilan konteks yang ideal difikirkan, dan hubungan antara sifat spektrumnya dan jurang prestasi yang timbul apabila melatih ketua peringkat rendah pada perwakilan yang sama diterokai. 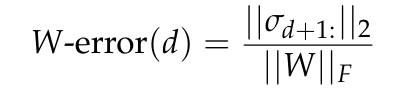
Atas ialah kandungan terperinci Prestasi model kecil adalah tepu dan prestasinya buruk Adakah puncanya disebabkan oleh Softmax?. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!
















![[Web front-end] Permulaan pantas Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



