
 Peranti teknologi
AI
Pembalikan selepas letupan? KAN yang 'membunuh MLP dalam satu malam': Sebenarnya, saya juga seorang MLP
Peranti teknologi
AI
Pembalikan selepas letupan? KAN yang 'membunuh MLP dalam satu malam': Sebenarnya, saya juga seorang MLP
Pembalikan selepas letupan? KAN yang 'membunuh MLP dalam satu malam': Sebenarnya, saya juga seorang MLP

Multilayer Perceptron (MLP), juga dikenali sebagai rangkaian neural suapan ke hadapan yang bersambung sepenuhnya, ialah blok binaan asas model pembelajaran mendalam hari ini. Kepentingan MLP tidak boleh dilebih-lebihkan, kerana ia adalah kaedah lalai untuk menganggarkan fungsi tak linear dalam pembelajaran mesin.
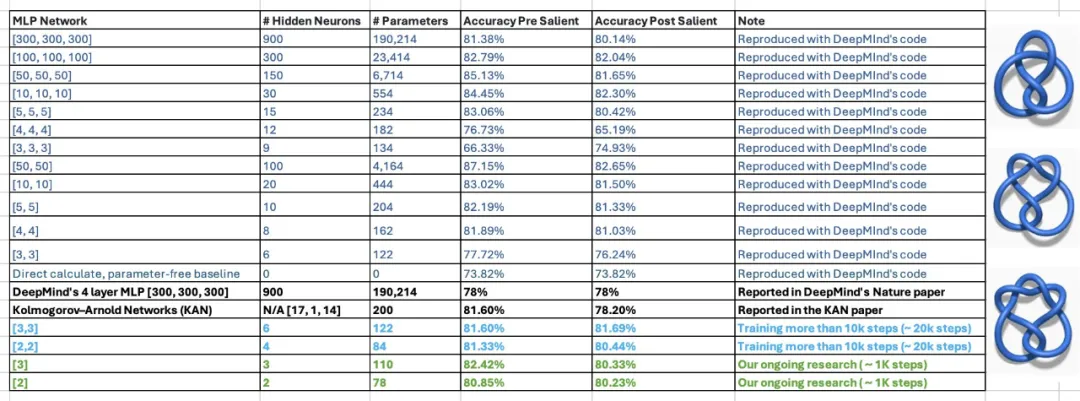
Tetapi baru-baru ini, penyelidik dari MIT dan institusi lain telah mencadangkan kaedah alternatif yang sangat menjanjikan - KAN. Kaedah ini mengatasi MLP dari segi ketepatan dan kebolehtafsiran. Tambahan pula, ia boleh mengatasi prestasi MLP yang dijalankan dengan saiz parameter yang lebih besar dengan parameter yang sangat sedikit. Sebagai contoh, penulis menyatakan bahawa mereka menggunakan KAN untuk menemui semula undang-undang matematik dalam teori simpulan dan menghasilkan semula keputusan DeepMind dengan rangkaian yang lebih kecil dan tahap automasi yang lebih tinggi. Khususnya, MLP DeepMind mempunyai kira-kira 300,000 parameter, manakala KAN hanya mempunyai kira-kira 200 parameter.
Kandungan penalaan halus adalah seperti berikut: Hasil penyelidikan yang menakjubkan ini menjadikan KAN cepat popular dan menarik ramai orang untuk mengkajinya. Tidak lama kemudian, beberapa orang menimbulkan keraguan. Antaranya, dokumen Colab bertajuk "KAN is just MLP" menjadi tumpuan perbincangan.
KAN Hanya MLP biasa?
Pengarang dokumen di atas menyatakan bahawa anda boleh menulis KAN sebagai MLP dengan menambah beberapa ulangan dan anjakan sebelum ReLU.
Dalam contoh ringkas, penulis menunjukkan cara menulis semula rangkaian KAN ke dalam MLP biasa dengan bilangan parameter yang sama dan struktur tidak linear sedikit.
Apa yang perlu diingat ialah KAN mempunyai fungsi pengaktifan di bahagian tepi. Mereka menggunakan B-splines. Dalam contoh yang ditunjukkan, pengarang hanya akan menggunakan fungsi linear sekeping untuk kesederhanaan. Ini tidak mengubah keupayaan pemodelan rangkaian.
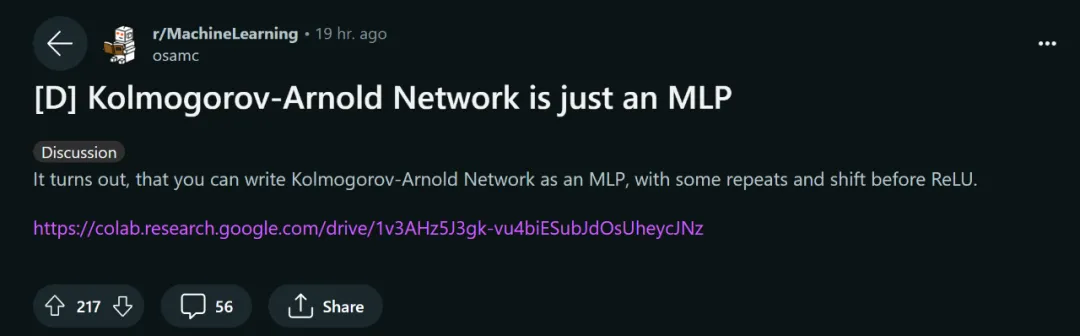
Berikut ialah contoh fungsi linear sekeping:
def f(x):if x
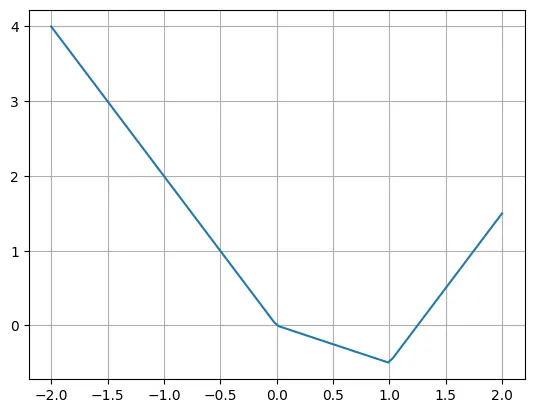
Pengarang menyatakan bahawa kita boleh menulis semula fungsi ini dengan mudah menggunakan pelbagai fungsi ReLU dan linear. Ambil perhatian bahawa kadangkala adalah perlu untuk memindahkan input ReLU.
plt.plot(X, -2*X + torch.relu(X)*1.5 + torch.relu(X-1)*2.5)plt.grid()
Persoalan sebenar ialah bagaimana untuk menulis semula lapisan KAN ke dalam lapisan MLP biasa. Katakan terdapat n neuron input, m neuron keluaran, dan fungsi sekeping mempunyai k keping. Ini memerlukan n*m*k parameter (k parameter setiap tepi, dan anda mempunyai n*m tepi).
Sekarang pertimbangkan kelebihan KAN. Untuk melakukan ini, input perlu disalin k kali, setiap salinan dialihkan oleh pemalar, dan kemudian dijalankan melalui ReLU dan lapisan linear (kecuali lapisan pertama). Secara grafik ia kelihatan seperti ini (C ialah pemalar dan W ialah berat):
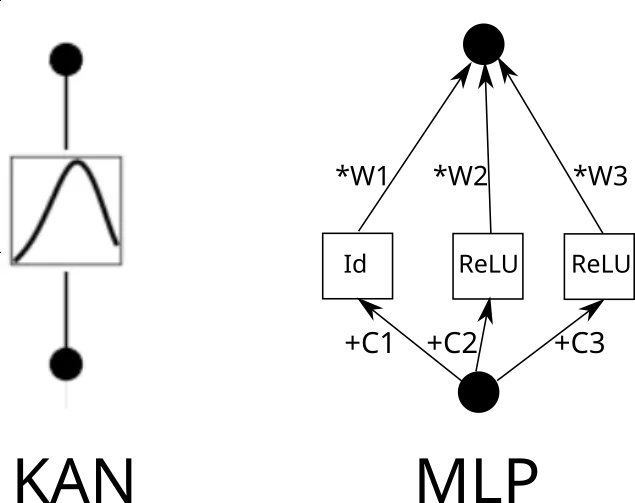
Kini, anda boleh mengulangi proses ini untuk setiap tepi. Tetapi satu perkara yang perlu diberi perhatian ialah jika grid fungsi linear sekeping adalah sama di mana-mana, kita boleh berkongsi output ReLU perantaraan dan hanya menggabungkan pemberat padanya. Seperti ini:
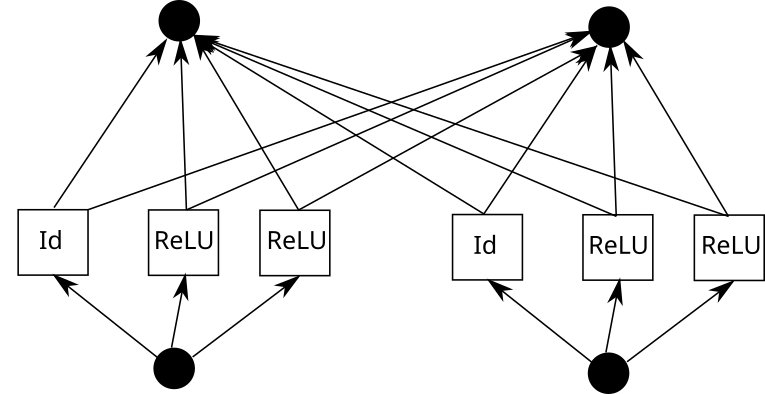
Dalam Pytorch, ini diterjemahkan kepada:
k = 3 # Grid sizeinp_size = 5out_size = 7batch_size = 10X = torch.randn(batch_size, inp_size) # Our inputlinear = nn.Linear(inp_size*k, out_size)# Weightsrepeated = X.unsqueeze(1).repeat(1,k,1)shifts = torch.linspace(-1, 1, k).reshape(1,k,1)shifted = repeated + shiftsintermediate = torch.cat([shifted[:,:1,:], torch.relu(shifted[:,1:,:])], dim=1).flatten(1)outputs = linear(intermediate)
Kini lapisan kami kelihatan seperti ini:
- Kembangkan + anjakan + ReLU
- Linear
Pertimbangkan tiga lapisan
- : + satu demi satu shift + ReLU (Lapisan 1 bermula di sini)
- Linear
- Kembangkan + anjakan + ReLU (Lapisan 2 bermula di sini)
- Linear
- Kembang di sini
- Kembangkan di sini + Mulakan semula Linear
Mengabaikan pengembangan input, kita boleh menyusun semula:
- Linear (Lapisan 1 bermula di sini)
- Kembangkan + anjakan + ReLU
- Kembangkan + shift + ReLU
Lapisan berikut pada asasnya boleh dipanggil MLP. Anda juga boleh menjadikan lapisan linear lebih besar, mengalih keluar mengembangkan dan beralih serta mendapatkan keupayaan pemodelan yang lebih baik (walaupun pada kos parameter yang lebih tinggi).
- Linear (Lapisan 2 bermula di sini)
- Expand + shift + ReLU
Melalui contoh ini, penulis menunjukkan bahawa KAN adalah sejenis MLP. Kenyataan ini mencetuskan semua orang untuk memikirkan semula dua jenis kaedah.

Pemeriksaan semula idea, kaedah dan keputusan KAN
Malah, selain hubungan yang tidak jelas dengan MLP, KAN juga telah dipersoalkan oleh banyak aspek lain.
Ringkasnya, perbincangan penyelidik tertumpu pada perkara berikut.
Pertama, sumbangan utama KAN terletak pada kebolehtafsiran, bukan pada kelajuan pengembangan, ketepatan, dll.
Penulis kertas itu pernah berkata:
- KAN skala lebih cepat daripada MLP. KAN mempunyai ketepatan yang lebih baik daripada MLP dengan parameter yang lebih sedikit.
- KAN boleh divisualisasikan secara intuitif. KAN menyediakan kebolehtafsiran dan interaktiviti yang tidak dapat dilakukan oleh MLP. Kami berpotensi menemui undang-undang saintifik baharu menggunakan KAN.
Antaranya, kepentingan kebolehtafsiran rangkaian untuk model untuk menyelesaikan masalah kehidupan sebenar adalah jelas:

Tetapi masalahnya ialah: "Saya fikir dakwaan mereka hanya kerana ia belajar lebih cepat dan mempunyai Kebolehtafsiran, bukannya sesuatu yang lain yang masuk akal jika KAN mempunyai parameter yang lebih sedikit daripada NN yang setara Saya masih merasakan bahawa latihan KAN adalah sangat tidak stabil daripada NN yang setara?
 Sebagai tindak balas, pengarang kertas kerja itu juga memberi respons positif:
Sebagai tindak balas, pengarang kertas kerja itu juga memberi respons positif:
Kedua, kaedah KAN dan MLP pada asasnya tidak berbeza.

"Ya, itu jelas perkara yang sama. Dalam KAN mereka melakukan pengaktifan dahulu dan kemudian kombinasi linear, manakala dalam MLP mereka melakukan kombinasi linear dahulu dan kemudian pengaktifan. Perkuatkannya, pada asasnya Itu perkara yang sama. Setahu saya, sebab utama penggunaan KAN adalah kebolehtafsiran dan regresi simbolik "Selain mempersoalkan kaedah tersebut, penyelidik juga menyeru agar penilaian kertas ini dikembalikan. Sebab:
 "Saya rasa orang ramai. perlu berhenti memikirkan kertas KAN sebagai perubahan besar dalam unit asas pembelajaran mendalam, dan anggap sahaja ia sebagai kertas kerja yang baik tentang kebolehtafsiran pembelajaran mendalam Belajar pada setiap kelebihan Kebolehtafsiran fungsi bukan linear adalah sumbangan utama kertas ini . "
"Saya rasa orang ramai. perlu berhenti memikirkan kertas KAN sebagai perubahan besar dalam unit asas pembelajaran mendalam, dan anggap sahaja ia sebagai kertas kerja yang baik tentang kebolehtafsiran pembelajaran mendalam Belajar pada setiap kelebihan Kebolehtafsiran fungsi bukan linear adalah sumbangan utama kertas ini . "
Ketiga, beberapa penyelidik mengatakan bahawa idea KAN bukan baru.
"Orang ramai mengkaji perkara ini pada tahun 1980-an. Perbincangan Berita Hacker menyebut kertas Itali membincangkan masalah ini. Jadi ini bukan perkara baru sama sekali. 40 tahun kemudian, ini Hanya sesuatu yang sama ada kembali atau ditolak dan telah dilawati semula."
 Tetapi dapat dilihat bahawa pengarang kertas KAN juga tidak menghiraukan isu tersebut.
Tetapi dapat dilihat bahawa pengarang kertas KAN juga tidak menghiraukan isu tersebut.
“Idea ini bukan perkara baharu, tetapi saya rasa pengarangnya tidak mengelak daripada perkara itu dan melakukan beberapa eksperimen yang bagus tentang data mainan tetapi ia juga merupakan Sumbangan
Pada masa yang sama, kertas kerja Ian Goodfellow dan Yoshua Bengio MaxOut (https://arxiv.org/pdf/1302.4389) lebih sepuluh tahun yang lalu juga disebut Beberapa penyelidik percaya bahawa kedua-dua "walaupun sedikit Terdapat perbezaan, tetapi idea agak serupa.”Pengarang: Matlamat penyelidikan asal sememangnya kebolehtafsiran
Hasil perbincangan hangat, salah seorang pengarang, Sachin Vaidya, tampil ke hadapan.
Sebagai salah seorang penulis makalah ini, saya ingin mengucapkan beberapa perkataan. Perhatian yang diterima KAN sangat mengagumkan, dan perbincangan ini adalah perkara yang diperlukan untuk mendorong teknologi baharu ke had mereka dan mengetahui apa yang berkesan dan apa yang tidak.
Saya fikir saya akan berkongsi sedikit latar belakang tentang motivasi. Idea utama kami untuk melaksanakan KAN berpunca daripada pencarian kami untuk model AI yang boleh ditafsir yang boleh "mempelajari" cerapan yang ditemui oleh ahli fizik tentang undang-undang semula jadi. Oleh itu, seperti yang disedari oleh orang lain, kami memberi tumpuan sepenuhnya kepada matlamat ini kerana model kotak hitam tradisional tidak dapat memberikan cerapan yang penting kepada penemuan asas dalam sains. Kami kemudian menunjukkan melalui contoh yang berkaitan dengan fizik dan matematik bahawa KAN dengan ketara mengatasi kaedah tradisional dari segi kebolehtafsiran. Kami pastinya berharap bahawa kegunaan KAN akan melampaui motivasi awal kami.
Soalan yang paling biasa saya ditanya baru-baru ini ialah sama ada KAN akan menjadi generasi akan datang daripada LLM. Saya tidak mempunyai pertimbangan yang jelas mengenai perkara ini.
KAN direka untuk aplikasi yang mementingkan ketepatan dan kebolehtafsiran yang tinggi. Kami mengambil berat tentang kebolehtafsiran LLM, tetapi kebolehtafsiran boleh bermakna perkara yang sangat berbeza untuk LLM dan sains. Adakah kita mengambil berat tentang ketepatan tinggi LLM? Undang-undang penskalaan nampaknya membayangkan demikian, tetapi mungkin tidak begitu tepat. Selain itu, ketepatan juga boleh bermakna perkara yang berbeza untuk LLM dan sains.
Saya mengalu-alukan orang ramai untuk mengkritik KAN, amalan adalah satu-satunya kriteria untuk menguji kebenaran. Terdapat banyak perkara yang kita tidak tahu terlebih dahulu sehingga ia benar-benar dicuba dan terbukti berjaya atau gagal. Walaupun saya ingin melihat KAN berjaya, saya juga ingin tahu tentang kegagalan KAN.
KAN dan MLP bukanlah pengganti antara satu sama lain. Mereka masing-masing mempunyai kelebihan dalam beberapa kes dan batasan dalam beberapa kes. Saya akan berminat dengan rangka kerja teori yang merangkumi kedua-duanya, dan mungkin juga menghasilkan alternatif baharu (ahli fizik suka teori bersatu, maaf).
KAN Pengarang pertama kertas kerja ialah Liu Ziming. Beliau ialah seorang ahli fizik dan penyelidik pembelajaran mesin dan kini merupakan pelajar PhD tahun ketiga di MIT dan IAIFI di bawah Max Tegmark. Minat penyelidikannya tertumpu pada persimpangan kecerdasan buatan dan fizik.
Atas ialah kandungan terperinci Pembalikan selepas letupan? KAN yang 'membunuh MLP dalam satu malam': Sebenarnya, saya juga seorang MLP. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!

Alat AI Hot

Undresser.AI Undress
Apl berkuasa AI untuk mencipta foto bogel yang realistik

AI Clothes Remover
Alat AI dalam talian untuk mengeluarkan pakaian daripada foto.

Undress AI Tool
Gambar buka pakaian secara percuma

Clothoff.io
Penyingkiran pakaian AI

Video Face Swap
Tukar muka dalam mana-mana video dengan mudah menggunakan alat tukar muka AI percuma kami!

Artikel Panas
Alat panas

Notepad++7.3.1
Editor kod yang mudah digunakan dan percuma

SublimeText3 versi Cina
Versi Cina, sangat mudah digunakan

Hantar Studio 13.0.1
Persekitaran pembangunan bersepadu PHP yang berkuasa

Dreamweaver CS6
Alat pembangunan web visual

SublimeText3 versi Mac
Perisian penyuntingan kod peringkat Tuhan (SublimeText3)
Topik panas
 1393
1393
 52
1207
24
52
1207
24

 Cara mengemas kini kod dalam git
Apr 17, 2025 pm 04:45 PM
Cara mengemas kini kod dalam git
Apr 17, 2025 pm 04:45 PM
Langkah -langkah untuk mengemas kini kod git: lihat kod: klon git https://github.com/username/repo.git Dapatkan perubahan terkini: Git mengambil Perubahan Gabungan: Git Gabungan Asal/Master Push Change (Pilihan): Git Push Origin Master
 Cara memuat turun projek git ke tempatan
Apr 17, 2025 pm 04:36 PM
Cara memuat turun projek git ke tempatan
Apr 17, 2025 pm 04:36 PM
Untuk memuat turun projek secara tempatan melalui Git, ikuti langkah -langkah ini: pasang git. Navigasi ke direktori projek. Pengklonan Repositori Jauh menggunakan arahan berikut: Git Clone https://github.com/username/repository-name.git
 Apa yang Harus Dilakukan Sekiranya Muat turun Git Tidak Aktif
Apr 17, 2025 pm 04:54 PM
Apa yang Harus Dilakukan Sekiranya Muat turun Git Tidak Aktif
Apr 17, 2025 pm 04:54 PM
Selesaikan: Apabila kelajuan muat turun git perlahan, anda boleh mengambil langkah -langkah berikut: periksa sambungan rangkaian dan cuba menukar kaedah sambungan. Mengoptimumkan Konfigurasi Git: Meningkatkan Saiz Penampan Pos (Git Config-Global Http.PostBuffer 524288000), dan mengurangkan had berkelajuan rendah (git config --global http.lowspeedlimit 1000). Gunakan proksi Git (seperti Git-Proxy atau Git-LFS-Proxy). Cuba gunakan klien Git yang berbeza (seperti sourcetree atau github desktop). Periksa perlindungan kebakaran
 Cara menggunakan komitmen git
Apr 17, 2025 pm 03:57 PM
Cara menggunakan komitmen git
Apr 17, 2025 pm 03:57 PM
Git Commit adalah arahan yang merekodkan fail perubahan kepada repositori git untuk menyelamatkan gambar keadaan semasa projek. Cara menggunakannya adalah seperti berikut: Tambahkan perubahan ke kawasan penyimpanan sementara Tulis mesej penyerahan ringkas dan bermaklumat untuk menyimpan dan keluar dari mesej penyerahan untuk melengkapkan penyerahan secara opsyen: Tambahkan tandatangan untuk log penyerahan Git Log untuk melihat kandungan penyerahan
 Cara memadam repositori dengan git
Apr 17, 2025 pm 04:03 PM
Cara memadam repositori dengan git
Apr 17, 2025 pm 04:03 PM
Untuk memadam repositori Git, ikuti langkah -langkah ini: Sahkan repositori yang anda mahu padamkan. Penghapusan repositori tempatan: Gunakan perintah RM -RF untuk memadam foldernya. Jauh memadam gudang: Navigasi ke tetapan gudang, cari pilihan "Padam Gudang", dan sahkan operasi.
 Cara menggabungkan kod dalam git
Apr 17, 2025 pm 04:39 PM
Cara menggabungkan kod dalam git
Apr 17, 2025 pm 04:39 PM
Proses penggabungan kod Git: Tarik perubahan terkini untuk mengelakkan konflik. Beralih ke cawangan yang anda mahu bergabung. Memulakan gabungan, menyatakan cawangan untuk bergabung. Selesaikan gabungan konflik (jika ada). Pementasan dan komit gabungan, memberikan mesej komit.
 Bagaimana menyelesaikan masalah carian yang cekap dalam projek PHP? Jenis membantu anda mencapainya!
Apr 17, 2025 pm 08:15 PM
Bagaimana menyelesaikan masalah carian yang cekap dalam projek PHP? Jenis membantu anda mencapainya!
Apr 17, 2025 pm 08:15 PM
Apabila membangunkan laman web e-dagang, saya menghadapi masalah yang sukar: bagaimana untuk mencapai fungsi carian yang cekap dalam sejumlah besar data produk? Carian pangkalan data tradisional tidak cekap dan mempunyai pengalaman pengguna yang lemah. Selepas beberapa penyelidikan, saya dapati jenis enjin carian dan menyelesaikan masalah ini melalui PHP pelanggan PHP TypeSense/TypeSense-PHP, yang meningkatkan prestasi carian.
 Cara menghantar folder kosong dalam git
Apr 17, 2025 pm 04:09 PM
Cara menghantar folder kosong dalam git
Apr 17, 2025 pm 04:09 PM
Untuk menghantar folder kosong di Git, ikuti langkah -langkah berikut: 1. Buat folder kosong; 2. Tambah folder ke kawasan pementasan; 3. Hantar perubahan dan masukkan mesej komit; 4. (Pilihan) Tolak perubahan ke repositori jauh. Nota: Nama folder kosong tidak boleh bermula dengan. Jika folder sudah wujud, anda perlu menggunakan Git Add --force untuk menambah.
