

MoE model besar MoE sumber terbuka domestik terkini telah menjadi popular sejurus selepas debutnya.
Prestasi DeepSeek-V2 mencapai tahap GPT-4, tetapi ia adalah sumber terbuka, percuma untuk kegunaan komersial dan harga API hanya satu peratus daripada GPT-4-Turbo.
Jadi sebaik sahaja dikeluarkan, ia segera mencetuskan banyak perbincangan.
 Pictures
Pictures
Berdasarkan petunjuk prestasi yang diterbitkan, keupayaan Cina komprehensif DeepSeek V2 mengatasi kebanyakan model sumber terbuka Pada masa yang sama, model sumber tertutup seperti GPT-4 Turbo dan Wenkuai 4.0 juga berada dalam versi pertama. eselon.
Keupayaan Bahasa Inggeris yang komprehensif juga berada dalam eselon pertama yang sama seperti LLaMA3-70B, dan melebihi Mixtral 8x22B, yang juga merupakan KPM.
Ia juga menunjukkan prestasi yang baik dalam pengetahuan, matematik, penaakulan, pengaturcaraan, dll. Dan menyokong konteks 128K.
 Gambar
Gambar
Keupayaan ini boleh terus digunakan oleh pengguna biasa secara percuma. Beta tertutup kini dibuka, anda boleh mengalaminya serta-merta selepas mendaftar.
 Gambar
Gambar
API adalah lebih mahal: input ialah 1 yuan dan output ialah 2 yuan bagi setiap juta token (konteks 32K). Harganya hanya hampir satu peratus daripada GPT-4-Turbo.
Pada masa yang sama, seni bina model juga diinovasikan, menggunakan struktur MLA (Multi-head Latent Attention) dan Jarang yang dibangunkan sendiri, yang boleh mengurangkan jumlah pengiraan model dan ingatan inferens dengan ketara.
Netizen mengeluh: DeepSeek sentiasa membawa kejutan kepada orang ramai!
 Gambar
Gambar
Kami adalah orang pertama yang mengalami kesan khusus!
Pada masa ini, versi beta dalaman V2 boleh mengalami dialog universal dan pembantu kod.
 Gambar
Gambar
Anda boleh menguji logik, pengetahuan, penjanaan, matematik dan kebolehan lain model besar dalam perbualan umum.
Sebagai contoh, anda boleh memintanya untuk meniru gaya "The Legend of Zhen Huan" untuk menulis copywriting tanam gincu.
 Gambar
Gambar
juga boleh menerangkan dengan cara yang popular apa itu kuantum kuantum.
 Gambar
Gambar
Dari segi matematik, ia boleh menjawab soalan kalkulus lanjutan, seperti:
Gunakan kalkulus untuk membuktikan perwakilan siri tak terhingga bagi asas e logaritma asli.
 Gambar
Gambar
juga boleh mengelakkan beberapa perangkap logik bahasa.
 Pictures
Pictures
Ujian menunjukkan bahawa kandungan pengetahuan DeepSeek-V2 telah dikemas kini kepada 2023.
 Pictures
Pictures
Dari segi kod, halaman ujian dalaman menunjukkan bahawa DeepSeek-Coder-33B digunakan untuk menjawab soalan.
Dalam menjana kod yang lebih mudah, tiada ralat dalam beberapa ujian sebenar.
 Gambar
Gambar
juga boleh menerangkan dan menganalisis kod yang diberikan.
 Gambar
Gambar
 Gambar
Gambar
Walau bagaimanapun, terdapat juga kes jawapan yang salah dalam ujian.
Dalam soalan logik berikut, semasa proses pengiraan, DeepSeek-V2 tersilap mengira masa yang diperlukan untuk lilin dinyalakan dari kedua-dua hujung pada masa yang sama dan terbakar sebagai satu perempat daripada masa yang diperlukan untuk menyala keluar dari satu hujung. Apakah peningkatan yang dibawa oleh
 gambar
gambar
Menurut pengenalan rasmi, DeepSeek-V2 mempunyai jumlah parameter 236B dan pengaktifan 21B, yang secara kasarnya mencapai keupayaan model 70B~110B Padat.
 Pictures
Pictures
Berbanding dengan DeepSeek 67B sebelumnya, ia mempunyai prestasi yang lebih kukuh dan kos latihan yang lebih rendah. Ia boleh menjimatkan 42.5% kos latihan, mengurangkan cache KV sebanyak 93.3%, dan meningkatkan daya pengeluaran maksimum kepada 5.76 kali.
Dinyatakan secara rasmi bahawa ini bermakna memori video (KV Cache) yang digunakan oleh DeepSeek-V2 hanyalah 1/5~1/100 daripada model Dense pada tahap yang sama, dan kos setiap token dikurangkan dengan ketara.
Banyak pengoptimuman komunikasi telah dilakukan khusus untuk spesifikasi H800 Ia sebenarnya digunakan pada mesin H800 8 kad Daya input melebihi 100,000 token sesaat dan output melebihi 50,000 token sesaat.
 Gambar
Gambar
Pada beberapa Penanda Aras asas, model asas DeepSeek-V2 berprestasi seperti berikut:
 Gambar
Gambar
mengguna pakai seni bina yang inovatif DeepSeek-V2
Cadangan seni bina MLA (Multi-head Latent Attention) untuk mengurangkan jumlah pengiraan dan ingatan inferens dengan ketara.
Pada masa yang sama, kami membangunkan struktur Jarang sendiri untuk mengurangkan lagi jumlah pengiraan.
 Gambar
Gambar
Sesetengah orang berkata bahawa peningkatan ini mungkin sangat membantu untuk pengkomputeran berskala besar di pusat data.
 Pictures
Pictures
Dan dari segi harga API, DeepSeek-V2 hampir lebih rendah daripada semua model bintang di pasaran.
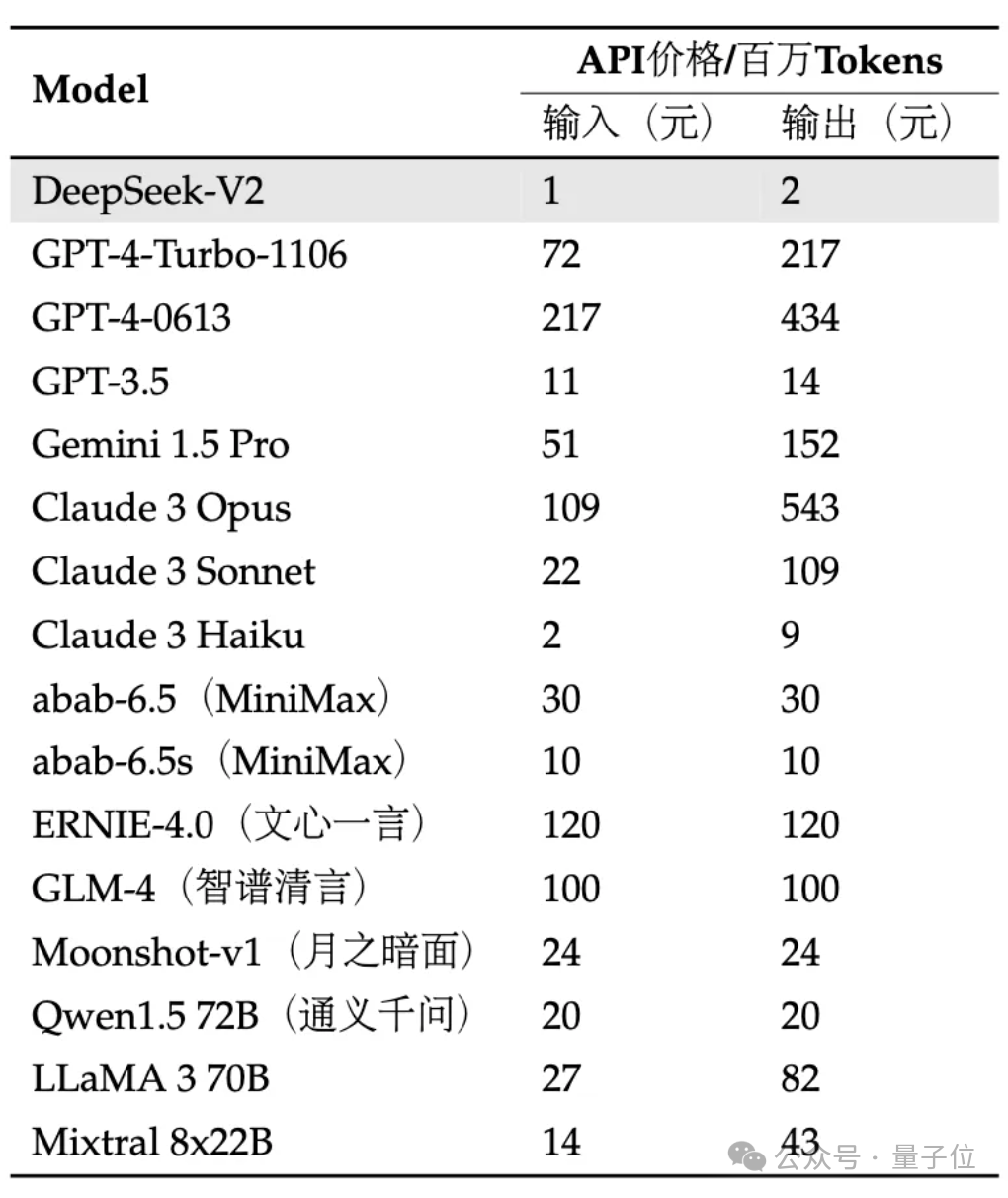 Pictures
Pictures
Pasukan menyatakan bahawa model dan kertas DeepSeek-V2 juga akan menjadi sumber terbuka sepenuhnya. Berat model dan laporan teknikal diberikan.
Log masuk ke platform terbuka DeepSeek API sekarang dan daftar untuk menerima 10 juta input/5 juta Token output sebagai hadiah. Percubaan biasa adalah percuma sepenuhnya.
Atas ialah kandungan terperinci Penunjuk MoE sumber terbuka domestik meletup: keupayaan tahap GPT-4, harga API hanya satu peratus. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!
 Bagaimana untuk mengambil tangkapan skrin pada telefon mudah alih Huawei
Bagaimana untuk mengambil tangkapan skrin pada telefon mudah alih Huawei
 Apakah yang perlu saya lakukan jika eDonkey Search tidak dapat menyambung ke pelayan?
Apakah yang perlu saya lakukan jika eDonkey Search tidak dapat menyambung ke pelayan?
 Bagaimana untuk memperlahankan video di Douyin
Bagaimana untuk memperlahankan video di Douyin
 Apakah fungsi Huawei nfc?
Apakah fungsi Huawei nfc?
 Penggunaan fungsi terima
Penggunaan fungsi terima
 kad bebas mysql
kad bebas mysql
 Apakah topologi rangkaian bintang?
Apakah topologi rangkaian bintang?
 Alat pertanyaan nama domain pendaftaran
Alat pertanyaan nama domain pendaftaran








![[Web front-end] Permulaan pantas Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



