
 Peranti teknologi
AI
7262 kertas telah diserahkan, ICLR 2024 menjadi popular, dan dua kertas domestik telah dicalonkan untuk kertas tertunggak.
Peranti teknologi
AI
7262 kertas telah diserahkan, ICLR 2024 menjadi popular, dan dua kertas domestik telah dicalonkan untuk kertas tertunggak.
7262 kertas telah diserahkan, ICLR 2024 menjadi popular, dan dua kertas domestik telah dicalonkan untuk kertas tertunggak.

Sebanyak 5 anugerah kertas cemerlang dan 11 sebutan kehormat telah dipilih pada tahun ini.
ICLR bermaksud Persidangan Antarabangsa mengenai Perwakilan Pembelajaran Tahun ini adalah persidangan ke-12, yang diadakan di Vienna, Austria dari 7 hingga 11 Mei.
Dalam komuniti pembelajaran mesin, ICLR ialah persidangan akademik teratas yang agak "muda" Ia dihoskan oleh gergasi pembelajaran mendalam dan pemenang Anugerah Turing Yoshua Bengio dan Yann LeCun Ia baru sahaja mengadakan sesi pertamanya pada tahun 2013. Walau bagaimanapun, ICLR dengan cepat mendapat pengiktirafan luas daripada penyelidik akademik dan dianggap sebagai persidangan akademik teratas mengenai pembelajaran mendalam.
Persidangan ini menerima sejumlah 7262 kertas kerja yang diserahkan, dan menerima 2260 kertas kerja Kadar penerimaan keseluruhan adalah kira-kira 31%, sama seperti tahun lepas (31.8%). Selain itu, bahagian kertas Spotlights ialah 5% dan bahagian kertas Lisan ialah 1.2%. . R Untuk kertas ICLR terdahulu, dalam kertas pemenang anugerah yang diumumkan baru-baru ini, persidangan itu memilih 5 anugerah tesis cemerlang dan 11 anugerah pencalonan kehormat. Anugerah Kertas Cemerlang 5 bersih / pdf?id=ANvmVS2Yr0


Pengarang: Zahra Kadkhodaie, Florentin Guth, Eero P. Simoncelli, Stéphane Mallat
Artikel umum yang diimport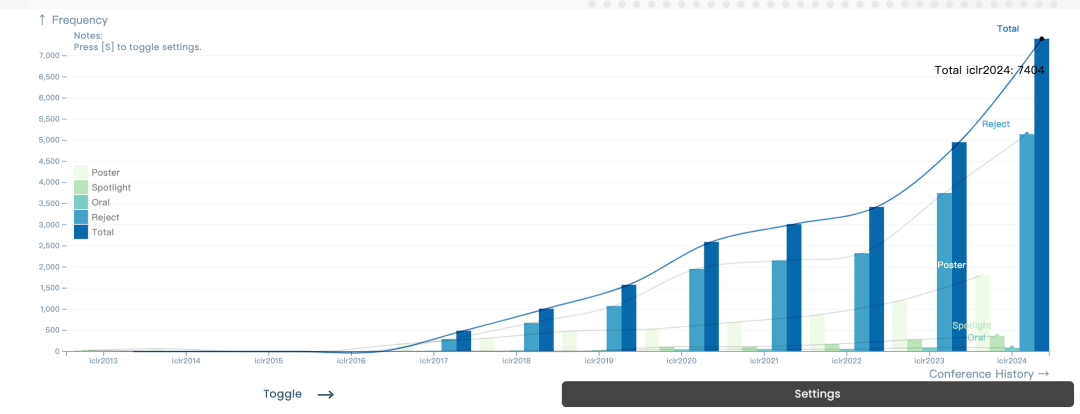
Kertas: Belajar Simulator Dunia Sebenar Interaktif
Alamat kertas: https://openreview.net/forum?id=sFyTZEqmUY
Alamat kertas: https://openreview.net/forum?id=sFyTZEqmUY
, Institusi Google: Deep, Google MIT Universiti Berta 
- Pengarang: Sherry Yang, Yilun Du, Kamyar Ghasemipour, Jonathan Tompson, Leslie Kaelbling, Dale Schuurmans, Pieter Abbeel
- Mengagregatkan data merentas pelbagai sumber matlamat untuk melatih model asas jangka panjang . Memandangkan robot yang berbeza mempunyai antara muka sensorimotor yang berbeza, ini menimbulkan cabaran yang ketara kepada latihan merentas set data berskala besar. UniSim
- , merupakan langkah penting ke arah ini dan pencapaian kejuruteraan, memanfaatkan antara muka bersatu berdasarkan penerangan teks persepsi visual dan kawalan untuk mengagregat data dan dengan memanfaatkan kemajuan terkini dalam penglihatan dan bahasa yang Dibangunkan untuk melatih simulator robot . Ringkasnya, artikel ini meneroka UniSim, simulator tujuan umum untuk mempelajari interaksi dunia sebenar melalui model generatif, dan mengambil langkah pertama ke arah membina simulator tujuan umum. Sebagai contoh, UniSim boleh mensimulasikan cara manusia dan ejen berinteraksi dengan dunia dengan mensimulasikan arahan peringkat tinggi seperti "buka laci" dan hasil visual arahan peringkat rendah.
Seperti yang ditunjukkan dalam Rajah 3 di bawah, UniSim boleh mensimulasikan satu siri tindakan yang kaya, seperti mencuci tangan, mengambil mangkuk, memotong lobak merah, dan mengeringkan tangan di bahagian atas sebelah kanan Rajah 3 menunjukkan menekan suis yang berbeza; Rajah 3 menunjukkan dua adegan navigasi.

Adegan navigasi di sebelah kanan bawah Rajah 3
 Thesis: Tidak pernah berlatih dari awal: Perbandingan adil model urutan panjang memerlukan data yang didorong oleh Jonathan Berant, Ankit Gupta
Thesis: Tidak pernah berlatih dari awal: Perbandingan adil model urutan panjang memerlukan data yang didorong oleh Jonathan Berant, Ankit Gupta
Makalah ini menyelidiki keupayaan model ruang negeri yang dicadangkan baru-baru ini dan seni bina pengubah untuk memodelkan kebergantungan jujukan jangka panjang. Anehnya, pengarang mendapati bahawa melatih model pengubah dari awal menyebabkan prestasinya dipandang rendah, dan peningkatan prestasi yang ketara boleh dicapai dengan tetapan pra-latihan dan penalaan halus. Makalah ini cemerlang dalam fokusnya pada kesederhanaan dan pandangan sistematik.
Kertas: Penemuan Protein dengan Persampelan Walk-Jump Diskret

Alamat kertas: https://openreview.net/forum?id=zMPHKOmQNb
- Alamat kertas: https://openreview.net/forum?id=zMPHKOmQNb
Pengarang: Nathan C. Frey, Dan Berenberg, Karina Zadorozhny, Joseph Kleinhenz, Julien Lafrance-Vanasse, Isidro Hotzel, Yan Wu, Stephen Ra, Richard Bonneau, Kyunghyun Cho, Andreas Loukas, Vladimir Gligorijevic, Saeed Saremi

- Kertas kerja ini menangani masalah reka bentuk antibodi berasaskan jujukan, aplikasi model penjanaan jujukan protein yang tepat pada masanya dan penting.
Untuk tujuan ini, penulis memperkenalkan kaedah pemodelan baharu yang inovatif dan berkesan yang disasarkan khusus kepada masalah pemprosesan data jujukan protein diskret. Di samping mengesahkan kaedah dalam silico, penulis melakukan eksperimen makmal basah yang meluas untuk mengukur pertalian mengikat antibodi in vitro, menunjukkan keberkesanan kaedah yang dihasilkan mereka.
- Kertas: Vision Transformers Perlu Daftar
Pengarang: Timothée Darce t. Maxime Oquab, Julien Mairal, Piotr Bojanowski

- Kertas ini mengenal pasti artifak dalam peta ciri rangkaian pengubah penglihatan, yang dicirikan oleh token norma tinggi di kawasan latar belakang maklumat rendah.
Pengarang mencadangkan andaian utama tentang bagaimana fenomena ini berlaku dan menyediakan penyelesaian yang ringkas tetapi elegan menggunakan token daftar tambahan untuk menangani kesan ini, dengan itu meningkatkan prestasi model dalam pelbagai tugas. Cerapan yang diperoleh daripada kerja ini juga boleh memberi kesan kepada bidang aplikasi lain.
Kertas kerja ini ditulis dengan cemerlang dan memberikan contoh yang baik dalam menjalankan penyelidikan: "Kenal pasti masalah, fahami mengapa ia berlaku, dan kemudian cadangkan penyelesaian - 11 sebutan yang mulia
Selain 5 kertas kerja yang belum selesai." ICLR 2024 juga memilih 11 sebutan kehormat.
Institusi: University of Montreal, University of Oxford
Pengarang: Edward J Hu, Moksh Jain, Ericness Elmoznind Lajodar, Youness Elmoznino Bendarie , Nikolay Malkin
Alamat kertas: https://openreview.net/forum?id=Ouj6p4ca60
- Makalah ini mencadangkan alternatif kepada penyahkodan autoregresif dalam model bahasa besar dari perspektif pendekatan inferens Bayesian. yang boleh memberi inspirasi kepada penyelidikan susulan.
- Kertas: Mengira Nash Equilibria dalam Permainan Bentuk Normal melalui Pengoptimuman Stokastik
- Institusi: DeepMind
- Pengarang: Ian Gemp, Luke Marris, alamat
Ini adalah kertas bertulis yang sangat jelas yang menyumbang secara signifikan untuk menyelesaikan masalah penting untuk membangunkan penyelesai Nash yang cekap dan berskala.
Institusi: Universiti Peking, Institut Penyelidikan Kecerdasan Buatan Zhiyuan Beijing
-
Pengarang: Ying Wei Gai Wei Heng Heng Qi Wei Heng Qi Weiheng
- Alamat kertas: https://openreview.net/forum?id=HSKaGOi7Ar
- Institusi: Meta
- Pengarang: Ricky T. Q. Chen, Yaron Lipman
- alamat: Tinjauan: Meta
- Kertas: Adakah ImageNet bernilai 1 video? Mempelajari pengekod imej yang kukuh daripada 1 video panjang tanpa label
- Institusi: University of Central Florida, Google DeepMind, University of Amsterdam, dsb. Mamshad Nayeem Rizve, Joao Carreira, Yuki M Asano, Yannis Avrithis
- Alamat kertas: https://openreview.net/forum?id=Yen1lGns2o
- Institusi: City University of Hong Kong, Tencent AI Lab, Xi'an Jiaotong University, dsb.
- Wu, Long-Kai Huang, Renzhen Wang, Deyu Meng, dan Ying Wei
- Institusi: University of Illinois di Urbana-Champaign, Microsoft
- Pengarang: Liyuan Zhang, Liyuan, Liyuan, Liyuan Zhang, Jiawei Han, Jianfeng Gao
- Institusi: Universiti Stanford, Universiti Columbia
- Pengarang: Yonatan Oren, Nicole Meister, Niladri S. Faisunori Ladhakaji, Tadhakhimori S. Alamat kertas: https://openreview.net/forum?id=KS8mIvetg2
- Institusi: Google DeepMind
- Pengarang: Jonathan Richens, Tom Everitt
Kertas: Asas mekanistik pergantungan data dan pembelajaran mendadak dalam tugas pengelasan dalam konteks
- Institusi: Universiti Princeton, Universiti Harvard, dll.
- Pengarang: Gautam Reddy Alamat: Gautam Reddy
- Institusi: Granica Computing
- Pengarang: Germain Kolossov, Andrea Montanari, alamat Pulkit Tandon
Kertas: Beyond Weisfeiler-Lehman: Rangka Kerja Kuantitatif untuk Ekspresi GNN
Kertas: Flow Matching on General Geometries
?alamat TL: https://o.
- Kertas kerja ini meneroka masalah pemodelan generatif yang mencabar tetapi penting pada pancarongga geometri am dan mencadangkan algoritma yang praktikal dan cekap. Kertas ini dibentangkan dengan cemerlang dan disahkan sepenuhnya secara eksperimen pada pelbagai tugas.
Makalah ini mencadangkan kaedah penyeliaan kendiri novel , iaitu dengan latihan daripada Belajar daripada video berterusan. Kertas kerja ini menyumbang kedua-dua jenis data baharu dan kaedah untuk belajar daripada data baharu.
Kertas: Pembelajaran Berterusan Meta Disemak Semula: Secara Tersirat Meningkatkan Penghampiran Hessian Dalam Talian melalui Pengurangan VariansPengarang mencadangkan varians pembelajaran meta-berterusan baharu kaedah pengurangan. Kaedah ini berfungsi dengan baik dan bukan sahaja mempunyai kesan praktikal tetapi juga disokong oleh analisis penyesalan.
- Kertas: Model Memberitahu Anda Perkara yang Perlu Dibuang: Mampatan Cache KV Adaptif untuk LLM
Artikel ini memfokuskan pada masalah mampatan cache KV (masalah ini memberi kesan yang besar kepada Transformer- berasaskan LLM), dengan idea mudah yang mengurangkan memori dan boleh digunakan tanpa penalaan halus atau latihan semula yang mahal. Kaedah ini sangat mudah dan telah terbukti sangat berkesan.
- Kertas: Membuktikan Pencemaran Set Ujian dalam Model Bahasa Black-Box
Kertas ini menggunakan kaedah yang mudah dan elegan untuk menguji sama ada set data pembelajaran yang diselia telah dimasukkan dalam model bahasa besar dalam latihan.
Kertas: Ejen teguh belajar model dunia kausalalamatforum: https://Paperid
pOoKI3ouv1Kertas kerja ini membuat kemajuan besar dalam meletakkan asas teori untuk memahami peranan penaakulan kausal dalam keupayaan ejen untuk membuat generalisasi kepada domain baharu, dengan implikasi untuk pelbagai bidang berkaitan.
Ini adalah kajian yang tepat pada masanya dan sangat sistematik yang meneroka hubungan antara pembelajaran dalam konteks dan pembelajaran dalam berat apabila kita mula memahami fenomena ini.
- Kertas: Ke arah teori statistik pemilihan data di bawah pengawasan yang lemah
Kertas kerja ini mewujudkan asas statistik untuk pemilihan subset data dan mengenal pasti kelemahan kaedah pemilihan data yang popular.
Pautan rujukan: https://blog.iclr.cc/2024/05/06/iclr-2024-outstanding-paper-awards/🎜🎜🎜Atas ialah kandungan terperinci 7262 kertas telah diserahkan, ICLR 2024 menjadi popular, dan dua kertas domestik telah dicalonkan untuk kertas tertunggak.. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!

Alat AI Hot

Undresser.AI Undress
Apl berkuasa AI untuk mencipta foto bogel yang realistik

AI Clothes Remover
Alat AI dalam talian untuk mengeluarkan pakaian daripada foto.

Undress AI Tool
Gambar buka pakaian secara percuma

Clothoff.io
Penyingkiran pakaian AI

AI Hentai Generator
Menjana ai hentai secara percuma.

Artikel Panas
Alat panas

Notepad++7.3.1
Editor kod yang mudah digunakan dan percuma

SublimeText3 versi Cina
Versi Cina, sangat mudah digunakan

Hantar Studio 13.0.1
Persekitaran pembangunan bersepadu PHP yang berkuasa

Dreamweaver CS6
Alat pembangunan web visual

SublimeText3 versi Mac
Perisian penyuntingan kod peringkat Tuhan (SublimeText3)
Topik panas
 1359
1359
 52
52

 Robot DeepMind bermain pingpong, dan pukulan depan dan pukulan kilasnya tergelincir ke udara, mengalahkan manusia pemula sepenuhnya
Aug 09, 2024 pm 04:01 PM
Robot DeepMind bermain pingpong, dan pukulan depan dan pukulan kilasnya tergelincir ke udara, mengalahkan manusia pemula sepenuhnya
Aug 09, 2024 pm 04:01 PM
Tetapi mungkin dia tidak dapat mengalahkan lelaki tua di taman itu? Sukan Olimpik Paris sedang rancak berlangsung, dan pingpong telah menarik perhatian ramai. Pada masa yang sama, robot juga telah membuat penemuan baru dalam bermain pingpong. Sebentar tadi, DeepMind mencadangkan ejen robot pembelajaran pertama yang boleh mencapai tahap pemain amatur manusia dalam pingpong yang kompetitif. Alamat kertas: https://arxiv.org/pdf/2408.03906 Sejauh manakah robot DeepMind bermain pingpong? Mungkin setanding dengan pemain amatur manusia: kedua-dua pukulan depan dan pukulan kilas: pihak lawan menggunakan pelbagai gaya permainan, dan robot juga boleh bertahan: servis menerima dengan putaran yang berbeza: Walau bagaimanapun, keamatan permainan nampaknya tidak begitu sengit seperti lelaki tua di taman itu. Untuk robot, pingpong
 Cakar mekanikal pertama! Yuanluobao muncul di Persidangan Robot Dunia 2024 dan mengeluarkan robot catur pertama yang boleh memasuki rumah
Aug 21, 2024 pm 07:33 PM
Cakar mekanikal pertama! Yuanluobao muncul di Persidangan Robot Dunia 2024 dan mengeluarkan robot catur pertama yang boleh memasuki rumah
Aug 21, 2024 pm 07:33 PM
Pada 21 Ogos, Persidangan Robot Dunia 2024 telah diadakan dengan megah di Beijing. Jenama robot rumah SenseTime "Yuanluobot SenseRobot" telah memperkenalkan seluruh keluarga produknya, dan baru-baru ini mengeluarkan robot permainan catur AI Yuanluobot - Edisi Profesional Catur (selepas ini dirujuk sebagai "Yuanluobot SenseRobot"), menjadi robot catur A pertama di dunia untuk rumah. Sebagai produk robot permainan catur ketiga Yuanluobo, robot Guoxiang baharu telah melalui sejumlah besar peningkatan teknikal khas dan inovasi dalam AI dan jentera kejuruteraan Buat pertama kalinya, ia telah menyedari keupayaan untuk mengambil buah catur tiga dimensi melalui cakar mekanikal pada robot rumah, dan melaksanakan Fungsi mesin manusia seperti bermain catur, semua orang bermain catur, semakan notasi, dsb.
 Claude pun dah jadi malas! Netizen: Belajar untuk memberi percutian kepada diri sendiri
Sep 02, 2024 pm 01:56 PM
Claude pun dah jadi malas! Netizen: Belajar untuk memberi percutian kepada diri sendiri
Sep 02, 2024 pm 01:56 PM
Permulaan sekolah akan bermula, dan bukan hanya pelajar yang akan memulakan semester baharu yang harus menjaga diri mereka sendiri, tetapi juga model AI yang besar. Beberapa ketika dahulu, Reddit dipenuhi oleh netizen yang mengadu Claude semakin malas. "Tahapnya telah banyak menurun, ia sering berhenti seketika, malah output menjadi sangat singkat. Pada minggu pertama keluaran, ia boleh menterjemah dokumen penuh 4 halaman sekaligus, tetapi kini ia tidak dapat mengeluarkan separuh halaman pun. !" https:// www.reddit.com/r/ClaudeAI/comments/1by8rw8/something_just_feels_wrong_with_claude_in_the/ dalam siaran bertajuk "Totally disappointed with Claude", penuh dengan
 Pada Persidangan Robot Sedunia, robot domestik yang membawa 'harapan penjagaan warga tua masa depan' ini telah dikepung
Aug 22, 2024 pm 10:35 PM
Pada Persidangan Robot Sedunia, robot domestik yang membawa 'harapan penjagaan warga tua masa depan' ini telah dikepung
Aug 22, 2024 pm 10:35 PM
Pada Persidangan Robot Dunia yang diadakan di Beijing, paparan robot humanoid telah menjadi tumpuan mutlak di gerai Stardust Intelligent, pembantu robot AI S1 mempersembahkan tiga persembahan utama dulcimer, seni mempertahankan diri dan kaligrafi dalam. satu kawasan pameran, berkebolehan kedua-dua sastera dan seni mempertahankan diri, menarik sejumlah besar khalayak profesional dan media. Permainan elegan pada rentetan elastik membolehkan S1 menunjukkan operasi halus dan kawalan mutlak dengan kelajuan, kekuatan dan ketepatan. CCTV News menjalankan laporan khas mengenai pembelajaran tiruan dan kawalan pintar di sebalik "Kaligrafi Pengasas Syarikat Lai Jie menjelaskan bahawa di sebalik pergerakan sutera, bahagian perkakasan mengejar kawalan daya terbaik dan penunjuk badan yang paling menyerupai manusia (kelajuan, beban). dll.), tetapi di sisi AI, data pergerakan sebenar orang dikumpulkan, membolehkan robot menjadi lebih kuat apabila ia menghadapi situasi yang kuat dan belajar untuk berkembang dengan cepat. Dan tangkas
 Pasukan Li Feifei mencadangkan ReKep untuk memberi robot kecerdasan spatial dan mengintegrasikan GPT-4o
Sep 03, 2024 pm 05:18 PM
Pasukan Li Feifei mencadangkan ReKep untuk memberi robot kecerdasan spatial dan mengintegrasikan GPT-4o
Sep 03, 2024 pm 05:18 PM
Penyepaduan mendalam penglihatan dan pembelajaran robot. Apabila dua tangan robot bekerja bersama-sama dengan lancar untuk melipat pakaian, menuang teh dan mengemas kasut, ditambah pula dengan 1X robot humanoid NEO yang telah menjadi tajuk berita baru-baru ini, anda mungkin mempunyai perasaan: kita seolah-olah memasuki zaman robot. Malah, pergerakan sutera ini adalah hasil teknologi robotik canggih + reka bentuk bingkai yang indah + model besar berbilang modal. Kami tahu bahawa robot yang berguna sering memerlukan interaksi yang kompleks dan indah dengan alam sekitar, dan persekitaran boleh diwakili sebagai kekangan dalam domain spatial dan temporal. Sebagai contoh, jika anda ingin robot menuang teh, robot terlebih dahulu perlu menggenggam pemegang teko dan memastikannya tegak tanpa menumpahkan teh, kemudian gerakkannya dengan lancar sehingga mulut periuk sejajar dengan mulut cawan. , dan kemudian condongkan teko pada sudut tertentu. ini
 Anugerah ACL 2024 Diumumkan: Salah satu Kertas Terbaik mengenai Pentafsiran Oracle oleh HuaTech, Anugerah Ujian Masa GloVe
Aug 15, 2024 pm 04:37 PM
Anugerah ACL 2024 Diumumkan: Salah satu Kertas Terbaik mengenai Pentafsiran Oracle oleh HuaTech, Anugerah Ujian Masa GloVe
Aug 15, 2024 pm 04:37 PM
Pada persidangan ACL ini, para penyumbang telah mendapat banyak keuntungan. ACL2024 selama enam hari diadakan di Bangkok, Thailand. ACL ialah persidangan antarabangsa teratas dalam bidang linguistik pengiraan dan pemprosesan bahasa semula jadi Ia dianjurkan oleh Persatuan Antarabangsa untuk Linguistik Pengiraan dan diadakan setiap tahun. ACL sentiasa menduduki tempat pertama dalam pengaruh akademik dalam bidang NLP, dan ia juga merupakan persidangan yang disyorkan CCF-A. Persidangan ACL tahun ini adalah yang ke-62 dan telah menerima lebih daripada 400 karya termaju dalam bidang NLP. Petang semalam, persidangan itu mengumumkan kertas kerja terbaik dan anugerah lain. Kali ini, terdapat 7 Anugerah Kertas Terbaik (dua tidak diterbitkan), 1 Anugerah Kertas Tema Terbaik, dan 35 Anugerah Kertas Cemerlang. Persidangan itu turut menganugerahkan 3 Anugerah Kertas Sumber (ResourceAward) dan Anugerah Impak Sosial (
 Hongmeng Smart Travel S9 dan persidangan pelancaran produk baharu senario penuh, beberapa produk baharu blockbuster dikeluarkan bersama-sama
Aug 08, 2024 am 07:02 AM
Hongmeng Smart Travel S9 dan persidangan pelancaran produk baharu senario penuh, beberapa produk baharu blockbuster dikeluarkan bersama-sama
Aug 08, 2024 am 07:02 AM
Petang ini, Hongmeng Zhixing secara rasmi mengalu-alukan jenama baharu dan kereta baharu. Pada 6 Ogos, Huawei mengadakan persidangan pelancaran produk baharu Hongmeng Smart Xingxing S9 dan senario penuh Huawei, membawakan sedan perdana pintar panoramik Xiangjie S9, M7Pro dan Huawei novaFlip baharu, MatePad Pro 12.2 inci, MatePad Air baharu, Huawei Bisheng With banyak produk pintar semua senario baharu termasuk pencetak laser siri X1, FreeBuds6i, WATCHFIT3 dan skrin pintar S5Pro, daripada perjalanan pintar, pejabat pintar kepada pakaian pintar, Huawei terus membina ekosistem pintar senario penuh untuk membawa pengguna pengalaman pintar Internet Segala-galanya. Hongmeng Zhixing: Pemerkasaan mendalam untuk menggalakkan peningkatan industri kereta pintar Huawei berganding bahu dengan rakan industri automotif China untuk menyediakan
 AI sedang digunakan |. Permainan Amway AI yang gila oleh CEO Microsoft telah menyeksa saya beribu kali
Aug 14, 2024 am 12:00 AM
AI sedang digunakan |. Permainan Amway AI yang gila oleh CEO Microsoft telah menyeksa saya beribu kali
Aug 14, 2024 am 12:00 AM
Editor Laporan Kuasa Mesin: Yang Wen Gelombang kecerdasan buatan yang diwakili oleh model besar dan AIGC telah mengubah cara kita hidup dan bekerja secara senyap-senyap, tetapi kebanyakan orang masih tidak tahu cara menggunakannya. Oleh itu, kami telah melancarkan lajur "AI dalam Penggunaan" untuk memperkenalkan secara terperinci cara menggunakan AI melalui kes penggunaan kecerdasan buatan yang intuitif, menarik dan padat serta merangsang pemikiran semua orang. Kami juga mengalu-alukan pembaca untuk menyerahkan kes penggunaan yang inovatif dan praktikal. Ya Tuhan, AI benar-benar menjadi seorang yang genius. Baru-baru ini, ia menjadi topik hangat bahawa sukar untuk membezakan ketulenan gambar yang dihasilkan oleh AI. (Untuk butiran, sila pergi ke: AI sedang digunakan | Menjadi kecantikan AI dalam tiga langkah, dan dipukul kembali kepada bentuk asal anda oleh AI dalam sesaat) Selain wanita AI Google yang popular di Internet, pelbagai penjana FLUX telah muncul di platform sosial
