
 Peranti teknologi
AI
Model asas graf sumber terbuka besar HKU OpenGraph: keupayaan generalisasi yang kuat, penyebaran ke hadapan untuk meramalkan data baharu
Peranti teknologi
AI
Model asas graf sumber terbuka besar HKU OpenGraph: keupayaan generalisasi yang kuat, penyebaran ke hadapan untuk meramalkan data baharu
Model asas graf sumber terbuka besar HKU OpenGraph: keupayaan generalisasi yang kuat, penyebaran ke hadapan untuk meramalkan data baharu

Masalah kebuluran data dalam bidang pembelajaran graf telah diselesaikan dengan helah baharu!
OpenGraph, model berasaskan graf asas yang direka khusus untuk ramalan tangkapan sifar pada pelbagai set data graf.
Pasukan Chao Huang, ketua Makmal Perisikan Data Besar Hong Kong, turut mencadangkan teknik penambahbaikan dan pelarasan untuk model untuk meningkatkan kebolehsuaian model kepada tugasan baharu.
Pada masa ini, kerja ini telah dimuat naik ke GitHub.
Memperkenalkan teknik penambahan data ini terutamanya meneroka strategi yang mendalam untuk meningkatkan keupayaan generalisasi model grafik (terutamanya apabila terdapat perbezaan yang ketara antara data latihan dan ujian).
OpenGraph ialah model struktur graf umum yang melakukan perambatan ke hadapan melalui ramalan perambatan untuk mencapai ramalan sampel sifar data baharu.
Untuk mencapai matlamat, pasukan menyelesaikan 3 cabaran berikut:
- Perbezaan token antara set data: Set data graf yang berbeza selalunya mempunyai model token graf yang berbeza, dan kami memerlukan set token graf yang berbeza. dapat merentas set data Membuat ramalan.
- Pemodelan perhubungan nod: Apabila membina model graf umum, adalah penting untuk memodelkan perhubungan nod secara berkesan, yang berkaitan dengan kebolehskalaan dan kecekapan model.
- Kekurangan data: Menghadapi masalah pemerolehan data, kami melakukan peningkatan data melalui model bahasa yang besar untuk mensimulasikan hubungan struktur graf yang kompleks dan meningkatkan kualiti latihan model.
Melalui satu siri kaedah inovatif, seperti Tokenizer BERT yang sedar topologi dan Transformer graf berasaskan anchor, OpenGraph menangani cabaran di atas dengan berkesan. Keputusan ujian pada berbilang set data menunjukkan keupayaan generalisasi model yang sangat baik dan membolehkan penilaian berkesan terhadap keupayaan generalisasi warna model.
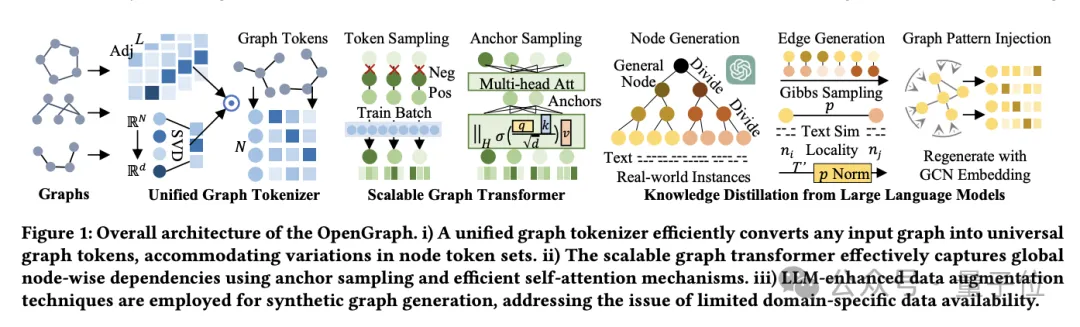
Model OpenGraph
Seni bina model OpenGraph terutamanya terdiri daripada 3 bahagian teras:
- Tokenizer graf bersatu.
- Pengubah graf boleh dipanjangkan.
- Teknologi penyulingan pengetahuan berdasarkan model bahasa besar.
Pertama, mari bercakap tentang Tokenizer graf bersatu.
Untuk menyesuaikan diri dengan perbezaan dalam nod dan tepi dalam set data yang berbeza, pasukan membangunkan Tokenizer graf bersatu, yang menormalkan data graf ke dalam jujukan token.
Proses ini termasuk pelicinan matriks bersebelahan tertib tinggi dan pemetaan sedar topologi.
Pelicinan matriks bersebelahan tertib tinggi menggunakan kuasa tertib tinggi matriks bersebelahan untuk menyelesaikan masalah sambungan jarang, manakala pemetaan sedar topologi menukar matriks bersebelahan kepada jujukan nod dan menggunakan penguraian nilai tunggal pantas (SVD) untuk meminimumkan kehilangan maklumat, mengekalkan lebih banyak maklumat struktur graf.
Yang kedua ialah Transformer graf boleh dipanjangkan.
Selepas tokenisasi, OpenGraph menggunakan seni bina Transformer untuk mensimulasikan kebergantungan antara nod, dan terutamanya menggunakan teknologi berikut untuk mengoptimumkan prestasi dan kecekapan model:
Pertama, pensampelan jujukan token menggunakan teknologi pensampelan untuk mengurangkan bilangan perhubungan yang diperlukan model untuk memproses, dengan itu mengurangkan kerumitan masa dan ruang.
Yang kedua ialah mekanisme perhatian kendiri bagi pensampelan sauh. Kaedah ini mengurangkan lagi kerumitan pengiraan dan secara berkesan meningkatkan kecekapan latihan dan kestabilan model melalui pemindahan maklumat antara nod pembelajaran secara berperingkat.
Langkah terakhir ialah penyulingan pengetahuan model bahasa besar.
Untuk menangani isu privasi data dan kepelbagaian kategori yang dihadapi semasa melatih model graf am, pasukan mendapat inspirasi daripada pengetahuan dan keupayaan pemahaman model bahasa besar (LLM) dan menggunakan LLM untuk menjana pelbagai data struktur graf.
Mekanisme peningkatan data ini secara berkesan meningkatkan kualiti dan kepraktisan data dengan mensimulasikan ciri-ciri graf dunia sebenar.
Pasukan juga mula-mula menjana set nod yang disesuaikan dengan aplikasi tertentu, dengan setiap nod mempunyai penerangan teks untuk penjanaan tepi.
Apabila berhadapan dengan set nod berskala besar seperti platform e-dagang, penyelidik menangani perkara ini dengan membahagikan nod kepada subkategori yang lebih khusus.
Sebagai contoh, daripada "produk elektronik" kepada "telefon mudah alih" tertentu, "komputer riba", dsb., proses ini diulang sehingga nod ditapis cukup untuk mendekati kejadian sebenar.
Algoritma pokok segera membahagikan nod mengikut struktur pokok dan menjana entiti yang lebih terperinci.
Mulakan daripada kategori umum seperti "produk", secara beransur-ansur memperhalusinya kepada subkategori tertentu, dan akhirnya membentuk pepohon nod.
Bagi penjanaan kelebihan, menggunakan pensampelan Gibbs, penyelidik membentuk tepi berdasarkan set nod yang dihasilkan.
Untuk mengurangkan beban pengiraan, kami tidak terus melintasi semua tepi yang mungkin melalui LLM Sebaliknya, kami mula-mula menggunakan LLM untuk mengira persamaan teks antara nod, dan kemudian menggunakan algoritma mudah untuk menentukan hubungan nod.
Atas dasar ini, pasukan memperkenalkan beberapa pelarasan teknikal:
- Penormalan kebarangkalian dinamik: Petakan persamaan ke dalam julat kebarangkalian yang lebih sesuai untuk pensampelan melalui pelarasan dinamik.
- Lokasi nod: Memperkenalkan konsep lokaliti dan hanya mewujudkan sambungan antara subset tempatan nod untuk mensimulasikan lokaliti rangkaian dalam dunia nyata.
- Suntikan corak topologi graf: Gunakan rangkaian konvolusi graf untuk mengubah suai perwakilan nod agar lebih menyesuaikan diri dengan ciri struktur graf dan mengurangkan sisihan taburan.
Langkah di atas memastikan data graf yang dihasilkan bukan sahaja kaya dan pelbagai, tetapi juga dekat dengan corak sambungan dan ciri struktur dunia sebenar.
Pengesahan eksperimen dan analisis prestasi
Perlu diambil perhatian bahawa percubaan ini memfokuskan pada melatih model OpenGraph menggunakan set data yang dijana hanya oleh LLM dan mengujinya pada set data senario kehidupan sebenar yang pelbagai, meliputi pengelasan nod dan tugas ramalan pautan.
Reka bentuk eksperimen adalah seperti berikut:
Tetapan sampel sifar.
Untuk menilai prestasi OpenGraph pada data yang tidak kelihatan, kami melatih model pada set latihan yang dijana dan kemudian menilainya pada set ujian dunia sebenar yang berbeza sama sekali. Ia memastikan bahawa data latihan dan ujian tidak mempunyai pertindihan dalam nod, tepi dan ciri.
Kurang tetapan sampel.
Memandangkan sukar bagi banyak kaedah untuk melaksanakan ramalan sifar pukulan dengan berkesan, kami memperkenalkan tetapan beberapa pukulan Selepas model garis dasar dilatih terlebih dahulu pada data pra-latihan, sampel k-shot digunakan untuk penalaan halus. .
Keputusan pada 2 tugasan dan 8 set ujian menunjukkan bahawa OpenGraph dengan ketara mengatasi kaedah sedia ada dalam ramalan pukulan sifar.
Selain itu, model pra-latihan sedia ada kadangkala berprestasi lebih teruk daripada model yang dilatih dari awal mengenai tugasan silang data.
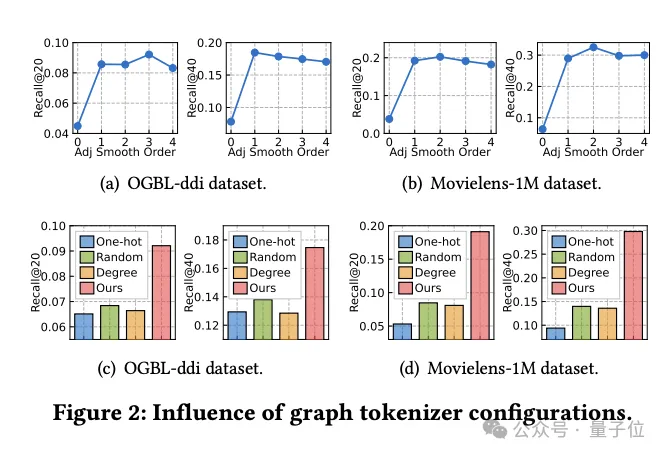
Kajian tentang kesan reka bentuk Tokenizer graf
Pada masa yang sama, pasukan meneroka cara reka bentuk Tokenizer graf mempengaruhi prestasi model.
Pertama sekali, didapati melalui eksperimen bahawa tidak melakukan pelicinan matriks bersebelahan (perintah pelicinan ialah 0) akan mengurangkan prestasi dengan ketara, menunjukkan keperluan pelicinan.
Para penyelidik kemudian mencuba beberapa alternatif mudah mengetahui topologi: ID yang dikodkan satu panas merentas set data, pemetaan rawak dan perwakilan berasaskan darjah nod.
Hasil eksperimen menunjukkan bahawa prestasi alternatif ini tidak ideal.
Secara khusus, perwakilan ID merentas set data adalah yang paling teruk, dan perwakilan berasaskan darjah juga berprestasi rendah, manakala pemetaan rawak, walaupun lebih baik sedikit, mempunyai jurang prestasi yang ketara berbanding dengan pemetaan sedar topologi yang dioptimumkan.
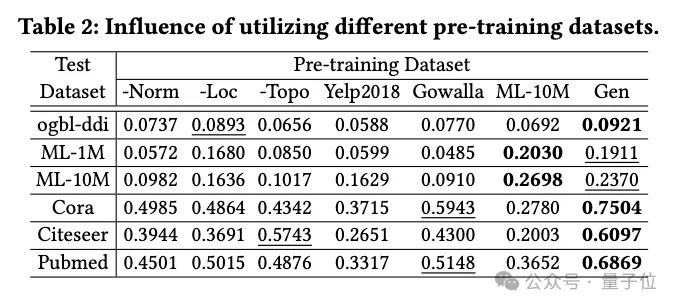
Impak teknik penjanaan data
Pasukan menyiasat kesan set data pra-latihan yang berbeza pada prestasi OpenGraph, termasuk set data yang dijana menggunakan kaedah penyulingan pengetahuan berasaskan LLM, serta beberapa set data sebenar.
Set data pra-latihan yang dibandingkan dalam eksperimen termasuk set data selepas mengalih keluar teknologi tertentu daripada kaedah penjanaan pasukan, 2 set data sebenar (Yelp2018 dan Gowalla) yang tidak berkaitan dengan set data ujian, 1 data set dengan data ujian Tetapkan set data sebenar yang serupa (ML-10M) .
Keputusan eksperimen menunjukkan bahawa set data yang dijana menunjukkan prestasi yang baik pada semua set ujian penyingkiran teknik tiga generasi dengan ketara mempengaruhi prestasi, mengesahkan keberkesanan teknik ini.
Apabila berlatih dengan set data sebenar (seperti Yelp dan Gowalla) yang tidak berkaitan dengan set ujian, prestasi kadangkala merosot, yang mungkin disebabkan oleh perbezaan taburan antara set data yang berbeza.
set data ML-10M mencapai prestasi terbaik pada set data ujian yang serupa seperti ML-1M dan ML-10M , menyerlahkan kepentingan persamaan antara set data latihan dan ujian.
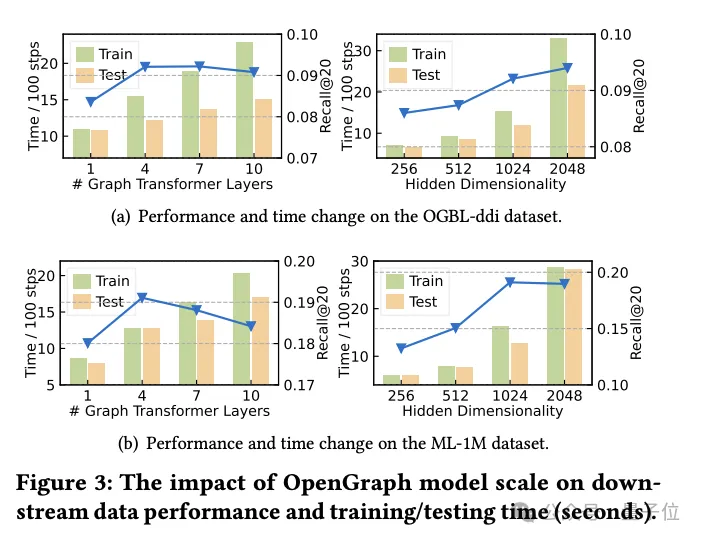
Penyelidikan tentang teknologi pensampelan Transformer
Dalam bahagian eksperimen ini, pasukan penyelidik meneroka dua teknologi pensampelan yang digunakan dalam modul Transformer graf:
pensampelan jujukan token (Seq) (Anc)
Mereka menjalankan eksperimen ablasi terperinci mengenai kedua-dua kaedah pensampelan ini untuk menilai kesan khusus mereka terhadap prestasi model.
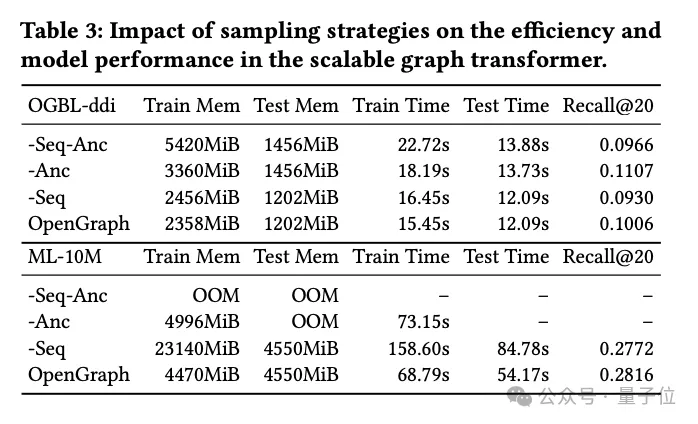
Hasil eksperimen menunjukkan bahawa sama ada ia adalah pensampelan jujukan token atau pensampelan titik anchor, kedua-duanya boleh mengurangkan kerumitan ruang dan masa model secara berkesan semasa peringkat latihan dan ujian. Ini amat penting untuk memproses data graf berskala besar dan boleh meningkatkan kecekapan dengan ketara.
Dari perspektif prestasi, pensampelan jujukan token mempunyai kesan positif ke atas prestasi keseluruhan model. Strategi pensampelan ini mengoptimumkan perwakilan graf dengan memilih token utama, dengan itu meningkatkan keupayaan model untuk mengendalikan struktur graf yang kompleks.
Sebaliknya, eksperimen pada set data ddi menunjukkan bahawa pensampelan utama mungkin mempunyai kesan negatif ke atas prestasi model. Persampelan anchor memudahkan struktur graf dengan memilih nod tertentu sebagai titik penambat, tetapi kaedah ini mungkin mengabaikan beberapa maklumat struktur graf utama, sekali gus menjejaskan ketepatan model.
Ringkasnya, walaupun kedua-dua teknik pensampelan mempunyai kelebihannya, dalam aplikasi praktikal, strategi pensampelan yang sesuai perlu dipilih dengan teliti berdasarkan set data dan keperluan tugasan tertentu.
Kesimpulan Penyelidikan
Penyelidikan ini bertujuan untuk membangunkan rangka kerja yang boleh disesuaikan dengan tepat yang boleh mengenal pasti dan menghuraikan corak topologi kompleks pelbagai struktur graf dengan tepat.
Para penyelidik menyasarkan untuk meningkatkan dengan ketara keupayaan generalisasi model dalam tugas pembelajaran graf sifar, termasuk pelbagai aplikasi hiliran, dengan memanfaatkan sepenuhnya keupayaan model yang dicadangkan.
Model ini dibina dengan sokongan seni bina Transformer graf boleh skala dan mekanisme penambahan data yang dipertingkatkan LLM untuk meningkatkan kecekapan dan keteguhan OpenGraph.
Melalui ujian meluas pada berbilang set data standard, pasukan menunjukkan prestasi generalisasi model yang sangat baik.
Difahamkan bahawa sebagai percubaan awal untuk membina model berasaskan graf, pada masa hadapan, kerja pasukan akan menumpukan pada meningkatkan keupayaan automasi rangka kerja, termasuk mengenal pasti sambungan bising secara automatik dan menjalankan pembelajaran kontrafaktual.
Pada masa yang sama, pasukan merancang untuk mempelajari dan mengekstrak corak lazim dan boleh dipindah milik pelbagai struktur graf untuk mempromosikan lagi skop aplikasi dan kesan model.
Pautan rujukan:
[1] Kertas: https://arxiv.org/pdf/2403.01121.pdf.
[2] Pustaka kod sumber: https://github.com/HKUDS/OpenGraph.
Atas ialah kandungan terperinci Model asas graf sumber terbuka besar HKU OpenGraph: keupayaan generalisasi yang kuat, penyebaran ke hadapan untuk meramalkan data baharu. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!

Alat AI Hot

Undresser.AI Undress
Apl berkuasa AI untuk mencipta foto bogel yang realistik

AI Clothes Remover
Alat AI dalam talian untuk mengeluarkan pakaian daripada foto.

Undress AI Tool
Gambar buka pakaian secara percuma

Clothoff.io
Penyingkiran pakaian AI

AI Hentai Generator
Menjana ai hentai secara percuma.

Artikel Panas
Alat panas

Notepad++7.3.1
Editor kod yang mudah digunakan dan percuma

SublimeText3 versi Cina
Versi Cina, sangat mudah digunakan

Hantar Studio 13.0.1
Persekitaran pembangunan bersepadu PHP yang berkuasa

Dreamweaver CS6
Alat pembangunan web visual

SublimeText3 versi Mac
Perisian penyuntingan kod peringkat Tuhan (SublimeText3)
Topik panas
 1376
1376
 52
52

 Perpustakaan apa yang digunakan untuk operasi nombor terapung di GO?
Apr 02, 2025 pm 02:06 PM
Perpustakaan apa yang digunakan untuk operasi nombor terapung di GO?
Apr 02, 2025 pm 02:06 PM
Perpustakaan yang digunakan untuk operasi nombor terapung dalam bahasa Go memperkenalkan cara memastikan ketepatannya ...
 GITEE PAGES PENYEDIAAN LAMAN WEB STATIC Gagal: Bagaimana menyelesaikan masalah dan menyelesaikan kesilapan fail tunggal 404?
Apr 04, 2025 pm 11:54 PM
GITEE PAGES PENYEDIAAN LAMAN WEB STATIC Gagal: Bagaimana menyelesaikan masalah dan menyelesaikan kesilapan fail tunggal 404?
Apr 04, 2025 pm 11:54 PM
Giteepages Statik Laman Web Penggunaan Gagal: 404 Penyelesaian Masalah dan Resolusi Ralat Semasa Menggunakan Gitee ...
 Cara Menjalankan Projek H5
Apr 06, 2025 pm 12:21 PM
Cara Menjalankan Projek H5
Apr 06, 2025 pm 12:21 PM
Menjalankan projek H5 memerlukan langkah -langkah berikut: memasang alat yang diperlukan seperti pelayan web, node.js, alat pembangunan, dan lain -lain. Membina persekitaran pembangunan, membuat folder projek, memulakan projek, dan menulis kod. Mulakan pelayan pembangunan dan jalankan arahan menggunakan baris arahan. Pratonton projek dalam penyemak imbas anda dan masukkan URL Server Pembangunan. Menerbitkan projek, mengoptimumkan kod, menggunakan projek, dan menyediakan konfigurasi pelayan web.
 Perpustakaan mana yang dibangunkan oleh syarikat besar atau disediakan oleh projek sumber terbuka yang terkenal?
Apr 02, 2025 pm 04:12 PM
Perpustakaan mana yang dibangunkan oleh syarikat besar atau disediakan oleh projek sumber terbuka yang terkenal?
Apr 02, 2025 pm 04:12 PM
Perpustakaan mana yang dibangunkan oleh syarikat besar atau projek sumber terbuka yang terkenal? Semasa pengaturcaraan di GO, pemaju sering menghadapi beberapa keperluan biasa, ...
 Bagaimana cara menentukan pangkalan data yang berkaitan dengan model dalam beego orm?
Apr 02, 2025 pm 03:54 PM
Bagaimana cara menentukan pangkalan data yang berkaitan dengan model dalam beego orm?
Apr 02, 2025 pm 03:54 PM
Di bawah rangka kerja beegoorm, bagaimana untuk menentukan pangkalan data yang berkaitan dengan model? Banyak projek beego memerlukan pelbagai pangkalan data untuk dikendalikan secara serentak. Semasa menggunakan beego ...
 Bagaimana menyelesaikan masalah penukaran jenis user_id semasa menggunakan aliran redis untuk melaksanakan beratur mesej dalam bahasa Go?
Apr 02, 2025 pm 04:54 PM
Bagaimana menyelesaikan masalah penukaran jenis user_id semasa menggunakan aliran redis untuk melaksanakan beratur mesej dalam bahasa Go?
Apr 02, 2025 pm 04:54 PM
Masalah menggunakan redisstream untuk melaksanakan beratur mesej dalam bahasa Go menggunakan bahasa Go dan redis ...
 Adakah pengeluaran halaman H5 memerlukan penyelenggaraan berterusan?
Apr 05, 2025 pm 11:27 PM
Adakah pengeluaran halaman H5 memerlukan penyelenggaraan berterusan?
Apr 05, 2025 pm 11:27 PM
Halaman H5 perlu dikekalkan secara berterusan, kerana faktor -faktor seperti kelemahan kod, keserasian pelayar, pengoptimuman prestasi, kemas kini keselamatan dan peningkatan pengalaman pengguna. Kaedah penyelenggaraan yang berkesan termasuk mewujudkan sistem ujian lengkap, menggunakan alat kawalan versi, kerap memantau prestasi halaman, mengumpul maklum balas pengguna dan merumuskan pelan penyelenggaraan.
 Bagaimana untuk mendapatkan data kawasan perkapalan versi luar negara? Apakah beberapa sumber siap sedia ada?
Apr 01, 2025 am 08:15 AM
Bagaimana untuk mendapatkan data kawasan perkapalan versi luar negara? Apakah beberapa sumber siap sedia ada?
Apr 01, 2025 am 08:15 AM
Penerangan Soalan: Bagaimana untuk mendapatkan data kawasan perkapalan versi luar negara? Adakah sumber sedia ada yang ada? Dapatkan tepat dalam e-dagang rentas sempadan atau perniagaan global ...
