
 Peranti teknologi
AI
LLM sudah selesai! OmniDrive: Mengintegrasikan persepsi 3D dan perancangan penaakulan (terbaharu NVIDIA)
Peranti teknologi
AI
LLM sudah selesai! OmniDrive: Mengintegrasikan persepsi 3D dan perancangan penaakulan (terbaharu NVIDIA)
LLM sudah selesai! OmniDrive: Mengintegrasikan persepsi 3D dan perancangan penaakulan (terbaharu NVIDIA)

Ditulis di hadapan & pemahaman peribadi pengarang
Kertas kerja ini didedikasikan untuk menyelesaikan cabaran utama model bahasa besar berbilang mod semasa (MLLM) dalam aplikasi pemanduan autonomi, iaitu, memperluaskan MLLM daripada pemahaman 2D kepada ruang 3D soalan. Peluasan ini amat penting kerana kenderaan autonomi (AV) perlu membuat keputusan yang tepat tentang persekitaran 3D. Pemahaman spatial 3D adalah penting untuk AV kerana ia memberi kesan langsung kepada keupayaan kenderaan untuk membuat keputusan termaklum, meramalkan keadaan masa depan dan berinteraksi dengan selamat dengan alam sekitar.
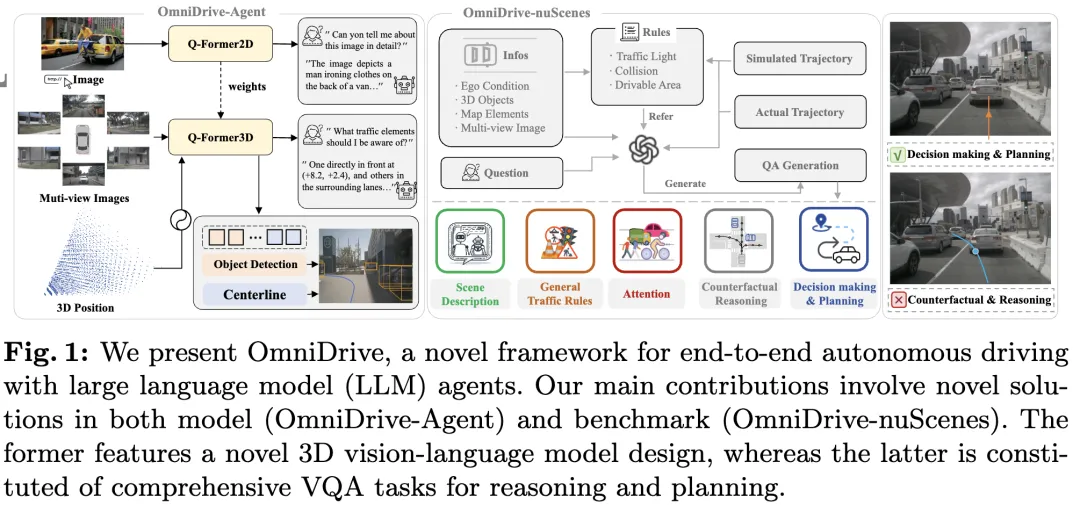
Model bahasa besar berbilang mod semasa (seperti LLaVA-1.5) biasanya hanya boleh mengendalikan input imej resolusi rendah (contohnya) disebabkan oleh pengehadan resolusi pengekod visual, pengehadan panjang jujukan LLM . Walau bagaimanapun, aplikasi pemanduan autonomi memerlukan input video berbilang paparan resolusi tinggi untuk memastikan kenderaan dapat melihat persekitaran dan membuat keputusan yang selamat dalam jarak jauh. Tambahan pula, banyak seni bina model 2D sedia ada bergelut untuk mengendalikan input ini dengan cekap kerana ia memerlukan sumber pengkomputeran dan storan yang luas. Untuk menangani isu ini, penyelidik sedang berusaha untuk membangunkan seni bina model baharu dan sumber storan.
Dalam konteks ini, kertas kerja ini mencadangkan seni bina MLLM 3D baharu, melukis pada reka bentuk gaya Q-Former. Seni bina menggunakan penyahkod perhatian silang untuk memampatkan maklumat visual resolusi tinggi kepada pertanyaan yang jarang, menjadikannya lebih mudah untuk menskalakan kepada input resolusi tinggi. Seni bina ini mempunyai persamaan dengan model keluarga pandangan seperti DETR3D, PETR(v2), StreamPETR dan Far3D, kerana kesemuanya memanfaatkan mekanisme pertanyaan 3D yang jarang. Dengan menambahkan pengekodan kedudukan 3D pada pertanyaan ini dan berinteraksi dengan input berbilang paparan, seni bina kami mencapai pemahaman spatial 3D dan dengan itu memanfaatkan pengetahuan pra-latihan dalam imej 2D dengan lebih baik.
Selain inovasi seni bina model, artikel ini juga mencadangkan penanda aras-OmniDrive-nuScenes yang lebih mencabar. Penanda aras meliputi pelbagai tugas kompleks yang memerlukan pemahaman spatial 3D dan penaakulan jarak jauh, dan memperkenalkan penanda aras penaakulan balas fakta untuk menilai keputusan dengan mensimulasikan penyelesaian dan trajektori. Penanda aras ini secara berkesan mengimbangi masalah berat sebelah ke arah trajektori pakar tunggal dalam penilaian terbuka semasa, sekali gus mengelakkan keterlaluan pada trajektori pakar.
Kertas kerja ini memperkenalkan OmniDrive, rangka kerja pemanduan autonomi menyeluruh menyeluruh yang menyediakan model penaakulan dan perancangan 3D yang berkesan berdasarkan agen LLM dan membina penanda aras yang lebih mencabar yang memacu perkembangan selanjutnya dalam bidang pemanduan autonomi. Sumbangan khusus adalah seperti berikut:
- Mencadangkan seni bina 3D Q-Former sesuai untuk pelbagai tugas berkaitan pemanduan, termasuk pengesanan sasaran, pengesanan lorong, kedudukan visual 3D, membuat keputusan dan perancangan.
- Memperkenalkan penanda aras OmniDrive-nuScenes, penanda aras QA pertama yang direka untuk menyelesaikan cabaran berkaitan perancangan, meliputi maklumat spatial 3D yang tepat.
- Mencapai prestasi terbaik dalam merancang tugas.
Penjelasan terperinci tentang OmniDrive
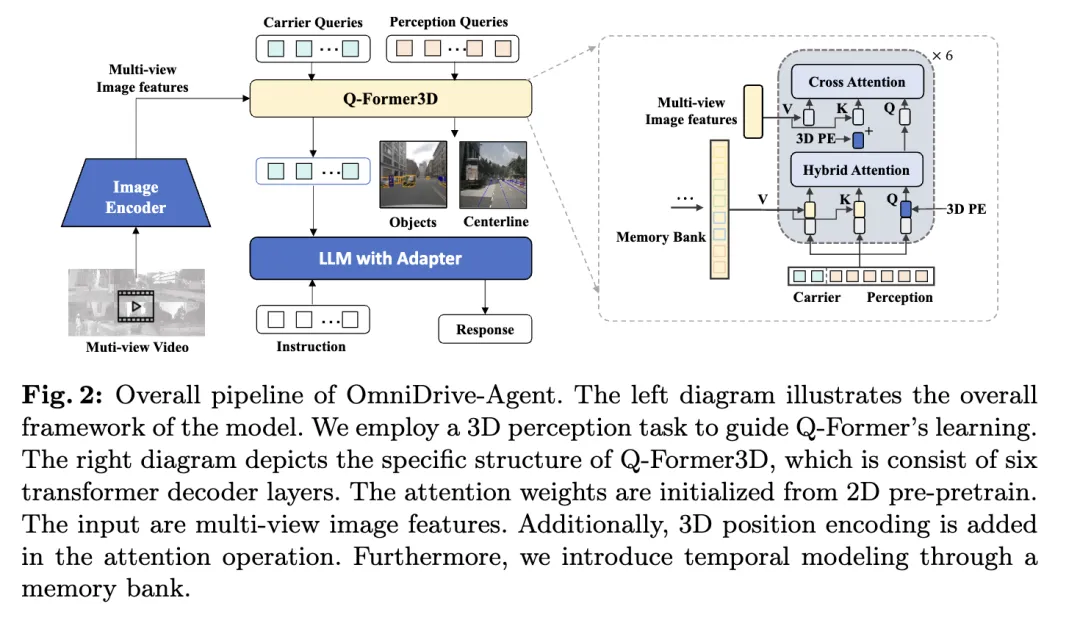
Struktur keseluruhan
OmniDrive-Agent yang dicadangkan dalam artikel ini menggabungkan kelebihan model Q-Drive untuk perolehan 3 yang cekap dan pertanyaan dalam pelbagai -lihat ciri imej, menyelesaikan persepsi 3D dan merancang tugas dalam pemanduan autonomi. Keseluruhan seni bina ditunjukkan dalam rajah.
- Pengekod Visual: Pertama, pengekod visual kongsi digunakan untuk mengekstrak ciri imej berbilang paparan.
- Pengekodan kedudukan: Ciri imej yang diekstrak dimasukkan ke dalam Q-Former3D bersama pengekodan kedudukan.
- Modul Q-Former3D: Antaranya, mewakili operasi penyambungan. Demi ringkasnya, pengekodan kedudukan diabaikan daripada formula. Selepas langkah ini, koleksi pertanyaan menjadi yang berinteraksi. Antaranya, mewakili pengekodan kedudukan 3D dan ialah ciri imej berbilang paparan.
- Koleksi ciri imej berbilang paparan: Seterusnya, pertanyaan ini mengumpulkan maklumat daripada imej berbilang paparan:
- Permulaan pertanyaan dan perhatian diri: Dalam Q-Former3D, pertanyaan pengesanan dan pertanyaan vektor dimulakan, dan Operasi perhatian kendiri dilakukan untuk bertukar-tukar maklumat antara mereka:
- Pemprosesan output:
- Ramalan tugasan persepsi: Ramalkan kategori dan menggunakan unsur-unsur persepsi latar depan
- Penjajaran pertanyaan pembawa dan penjanaan teks: Pertanyaan pembawa diselaraskan dengan dimensi token LLM (seperti dimensi 4096 dalam LLaMA) melalui MLP satu lapisan, dan seterusnya digunakan untuk penjanaan teks.
- Peranan pertanyaan pembawa
Melalui reka bentuk seni bina ini, OmniDrive-Agent boleh memperoleh maklumat spatial 3D yang kaya daripada imej berbilang paparan, dan menggabungkannya dengan LLM untuk penjanaan ruang teks dan Pemanduan Autonomi menawarkan penyelesaian baharu.
Pemodelan Pelbagai tugas dan Temporal
Kaedah pengarang mendapat manfaat daripada pembelajaran pelbagai tugas dan pemodelan temporal. Dalam pembelajaran berbilang tugas, pengarang boleh menyepadukan modul Q-Former3D khusus untuk setiap tugasan persepsi dan menggunakan strategi pemulaan bersatu (lihat cref{Strategi Latihan}). Dalam tugasan yang berbeza, pertanyaan pembawa boleh mengumpul maklumat tentang elemen trafik yang berbeza. Pelaksanaan pengarang meliputi tugas seperti pembinaan garis tengah dan pengesanan objek 3D. Semasa fasa latihan dan inferens, modul ini berkongsi pengekodan kedudukan 3D yang sama. Kaedah kami memperkayakan tugas seperti pembinaan garis tengah dan pengesanan objek 3D. Semasa fasa latihan dan inferens, modul ini berkongsi pengekodan kedudukan 3D yang sama. Kaedah kami memperkayakan tugas seperti pembinaan garis tengah dan pengesanan objek 3D. Semasa fasa latihan dan inferens, modul ini berkongsi pengekodan kedudukan 3D yang sama.
Berkenaan pemodelan temporal, pengarang menyimpan pertanyaan persepsi dengan skor klasifikasi top-k dalam bank memori dan menyebarkannya bingkai demi bingkai. Pertanyaan yang disebarkan berinteraksi dengan pertanyaan persepsi dan pertanyaan pembawa bagi bingkai semasa melalui perhatian silang, dengan itu memanjangkan keupayaan pemprosesan model untuk input video.
Strategi Latihan
Strategi latihan OmniDrive-Agent dibahagikan kepada dua peringkat: pra-latihan 2D dan penalaan halus 3D. Pada peringkat awal, pengarang terlebih dahulu melatih model besar berbilang modal (MLLM) pada tugas imej 2D untuk memulakan pertanyaan Q-Former dan vektor. Selepas mengalih keluar pertanyaan pengesanan, model OmniDrive boleh dianggap sebagai model bahasa visual standard, yang mampu menjana teks berdasarkan imej. Oleh itu, penulis menggunakan strategi latihan dan data LLaVA v1.5 untuk melatih OmniDrive pada pasangan imej dan teks 558K. Semasa pra-latihan, semua parameter kekal beku kecuali Q-Former. Selepas itu, MLLM telah diperhalusi menggunakan set data penalaan arahan LLaVA v1.5. Semasa penalaan halus, pengekod imej kekal beku dan parameter lain boleh dilatih.
Dalam peringkat penalaan halus 3D, matlamatnya adalah untuk meningkatkan keupayaan kedudukan 3D model sambil mengekalkan keupayaan pemahaman semantik 2Dnya sebanyak mungkin. Untuk tujuan ini, pengarang menambah pengekodan kedudukan 3D dan modul pemasaan kepada Q-Former asal. Pada peringkat ini, penulis menggunakan teknologi LoRA untuk memperhalusi pengekod visual dan model bahasa besar dengan kadar pembelajaran yang kecil, dan melatih Q-Former3D dengan kadar pembelajaran yang agak besar. Dalam kedua-dua peringkat ini, pengiraan kerugian OmniDrive-Agent hanya merangkumi kehilangan penjanaan teks, tanpa mengambil kira pembelajaran kontrastif dan kerugian padanan dalam BLIP-2.
OmniDrive-nuScenes

Untuk menanda aras memandu ejen model besar berbilang mod, penulis mencadangkan OmniDrive-nuScenes, penanda aras novel berdasarkan set data nuScenes yang mengandungi set data visual QA yang mengandungi kualiti tinggi (berkualiti tinggi). tugasan persepsi, penaakulan dan perancangan dalam domain 3D.
Kemuncak OmniDrive-nuScenes ialah proses penjanaan QA automatik sepenuhnya, yang menggunakan GPT-4 untuk menjana soalan dan jawapan. Sama seperti LLaVA, saluran paip kami menyediakan anotasi sedar 3D sebagai maklumat kontekstual kepada GPT-4. Atas dasar ini, penulis selanjutnya menggunakan peraturan lalu lintas dan simulasi perancangan sebagai input tambahan untuk membantu GPT-4 lebih memahami persekitaran 3D. Penanda aras pengarang bukan sahaja menguji persepsi dan keupayaan penaakulan model, tetapi juga mencabar pemahaman ruang sebenar model dan keupayaan perancangan dalam ruang 3D melalui masalah jangka panjang yang melibatkan perhatian, penaakulan kontrafak dan perancangan gelung terbuka, kerana masalah ini memerlukan perancangan Memandu. dalam beberapa saat akan datang disimulasikan untuk sampai pada jawapan yang betul.
Selain proses penjanaan untuk soal jawab luar talian, penulis juga mencadangkan satu proses untuk penjanaan dalam talian soalan penentududukan yang pelbagai. Proses ini boleh dilihat sebagai kaedah peningkatan data tersirat untuk meningkatkan pemahaman spatial 3D model dan keupayaan penaakulan.
Menjawab Soalan Luar Talian
Dalam proses penjanaan QA luar talian, penulis menggunakan maklumat kontekstual untuk menjana pasangan QA pada nuScenes. Pertama, pengarang menggunakan GPT-4 untuk menjana penerangan pemandangan, dan menyambung pandangan hadapan tiga perspektif dan pandangan belakang tiga perspektif ke dalam dua imej bebas dan memasukkannya ke dalam GPT-4. Melalui input segera, GPT-4 boleh menerangkan maklumat seperti cuaca, masa, jenis pemandangan, dsb., dan mengenal pasti arah setiap sudut tontonan Pada masa yang sama, ia mengelakkan penerangan dengan sudut tontonan, tetapi menerangkan kandungan berbanding dengan kedudukan kenderaan sendiri.
Seterusnya, agar GPT-4V lebih memahami hubungan ruang relatif antara elemen lalu lintas, penulis mewakili hubungan antara objek dan garisan lorong ke dalam struktur seperti pokok fail, dan berdasarkan kotak sempadan 3D objek, maklumatnya Tukar kepada huraian bahasa semula jadi.
Kemudian, pengarang menjana trajektori dengan mensimulasikan niat pemanduan yang berbeza, termasuk menjaga lorong, menukar lorong kiri dan menukar lorong kanan, dan menggunakan algoritma carian kedalaman pertama untuk menyambungkan garis tengah lorong untuk menjana semua laluan pemanduan yang mungkin. Di samping itu, pengarang mengelompokkan trajektori kenderaan sendiri dalam set data nuScenes, laluan pemanduan wakil yang dipilih dan menggunakannya sebagai sebahagian daripada trajektori simulasi.
Akhir sekali, dengan menggabungkan maklumat kontekstual yang berbeza dalam proses penjanaan QA luar talian, pengarang dapat menjana berbilang jenis pasangan QA, termasuk perihalan adegan, pengecaman objek perhatian, penaakulan kontrafaktual dan perancangan keputusan. GPT-4 boleh mengenal pasti objek ancaman berdasarkan simulasi dan trajektori pakar, dan memberikan cadangan pemanduan yang munasabah dengan membuat alasan tentang keselamatan laluan pemanduan.

Jawab Soalan Dalam Talian
Untuk menggunakan sepenuhnya anotasi persepsi 3D dalam set data pemanduan autonomi, penulis menghasilkan sejumlah besar tugas penentududukan dalam talian semasa proses latihan. Tugasan ini direka bentuk untuk meningkatkan pemahaman spatial 3D model dan keupayaan penaakulan, termasuk:
- Penyetempatan 2D ke 3D: Memandangkan kotak sempadan 2D pada kamera tertentu, model perlu menyediakan atribut 3D objek yang sepadan, termasuk kategori, lokasi, Saiz, orientasi dan kelajuan.
- Jarak 3D: Berdasarkan koordinat 3D yang dijana secara rawak, kenal pasti elemen trafik berhampiran lokasi sasaran dan berikan atribut 3D mereka.
- Lane to Objects: Berdasarkan garis tengah lorong yang dipilih secara rawak, senaraikan semua objek pada lorong itu dan sifat 3Dnya.
Metrik
OmniDrive-nuScenes set data melibatkan perihalan adegan, perancangan gelung terbuka dan tugas penaakulan balas fakta. Setiap tugas memfokuskan pada aspek yang berbeza, menjadikannya sukar untuk menilai menggunakan satu metrik. Oleh itu, pengarang mereka bentuk kriteria penilaian yang berbeza untuk tugas yang berbeza.
Untuk tugasan berkaitan penerangan adegan (seperti penerangan adegan dan pemilihan objek perhatian), pengarang menggunakan penunjuk penilaian bahasa yang biasa digunakan, termasuk METEOR, ROUGE dan CIDEr untuk menilai persamaan ayat. Dalam tugas perancangan gelung terbuka, penulis menggunakan kadar perlanggaran dan kadar lintasan sempadan jalan untuk menilai prestasi model. Untuk tugas penaakulan berlawanan, penulis menggunakan GPT-3.5 untuk mengekstrak kata kunci dalam ramalan dan membandingkan kata kunci ini dengan kebenaran asas untuk mengira ketepatan dan mengingat untuk kategori kemalangan yang berbeza.
Hasil eksperimen
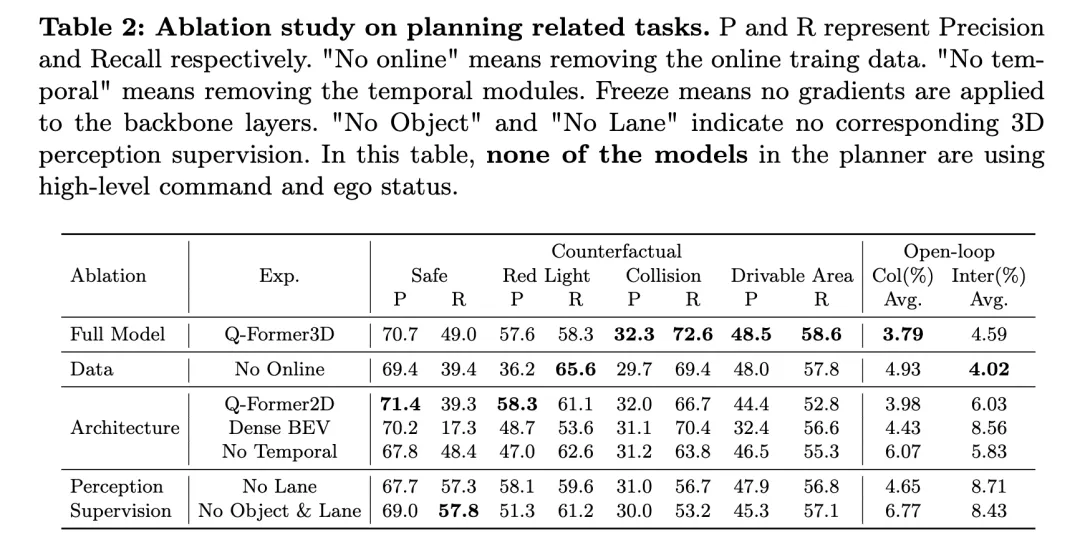
Jadual di atas menunjukkan hasil penyelidikan ablasi mengenai tugas berkaitan perancangan, termasuk penilaian prestasi penaakulan kontrafaktual dan perancangan gelung terbuka.
Model penuh, Q-Former3D, berfungsi dengan baik pada kedua-dua penaakulan kontrafaktual dan tugas perancangan gelung terbuka. Dalam tugas penaakulan balas fakta, model menunjukkan ketepatan tinggi dan kadar ingatan semula dalam kedua-dua kategori "pelanggaran lampu merah" dan "pelanggaran kawasan boleh diakses", iaitu masing-masing 57.6%/58.3% dan 48.5%/58.6%. Pada masa yang sama, model itu mencapai kadar ingatan tertinggi (72.6%) dalam kategori "perlanggaran". Dalam tugas perancangan gelung terbuka, Q-Former3D menunjukkan prestasi yang baik dalam kedua-dua kadar perlanggaran purata dan kadar persimpangan sempadan jalan, masing-masing mencapai 3.79% dan 4.59%.
Selepas mengalih keluar data latihan dalam talian (Tiada Dalam Talian), kadar panggil balik kategori "Pelanggaran Lampu Merah" dalam tugas penaakulan balas fakta meningkat (65.6%), tetapi prestasi keseluruhan menurun sedikit. Kadar ketepatan dan kadar ingat semula perlanggaran dan pelanggaran kawasan boleh dilalui adalah lebih rendah sedikit daripada model lengkap, manakala kadar perlanggaran purata tugas perancangan gelung terbuka meningkat kepada 4.93%, dan purata kadar lintasan sempadan jalan menurun kepada 4.02% , yang mencerminkan kepentingan data latihan dalam talian untuk Kepentingan meningkatkan prestasi keseluruhan perancangan model.
Dalam eksperimen ablasi seni bina, versi Q-Former2D mencapai ketepatan tertinggi (58.3%) dan ingatan semula tinggi (61.1%) pada kategori "Pelanggaran Lampu Merah", tetapi prestasi dalam kategori lain tidak sehebat penuh model, terutamanya " Ingat untuk kategori "Perlanggaran" dan "Pelanggaran Kawasan Boleh Dicapai" menurun dengan ketara. Dalam tugas perancangan gelung terbuka, kadar perlanggaran purata dan kadar persimpangan sempadan jalan adalah lebih tinggi daripada model penuh, masing-masing 3.98% dan 6.03%.
Model menggunakan seni bina Dense BEV berprestasi lebih baik pada semua kategori tugas penaakulan kontrafak, tetapi kadar penarikan semula keseluruhan adalah rendah. Purata kadar perlanggaran dan kadar persimpangan sempadan jalan dalam tugas perancangan gelung terbuka masing-masing mencapai 4.43% dan 8.56%.
Apabila modul temporal dialih keluar (Tiada Temporal), prestasi model dalam tugas penaakulan kontrafaktual menurun dengan ketara, terutamanya kadar perlanggaran purata meningkat kepada 6.07%, dan kadar lintasan sempadan jalan mencapai 5.83%.
Dari segi penyeliaan persepsi, selepas mengalih keluar penyeliaan garis lorong (Tiada Lorong), kadar penarikan semula model dalam kategori "perlanggaran" menurun dengan ketara, manakala prestasi kategori lain bagi tugas penaakulan kontrafak dan tugas perancangan gelung terbuka adalah agak stabil. Selepas mengalih keluar sepenuhnya pengawasan persepsi 3D terhadap objek dan garisan lorong (Tiada Objek & Lorong), kadar ketepatan dan ingatan semula setiap kategori tugas penaakulan balas fakta menurun, terutamanya kadar ingat semula kategori "perlanggaran" menurun kepada 53.2%. Kadar perlanggaran purata dan kadar persimpangan sempadan jalan dalam tugas perancangan gelung terbuka masing-masing meningkat kepada 6.77% dan 8.43%, yang jauh lebih tinggi daripada model penuh.
Seperti yang dapat dilihat daripada keputusan percubaan di atas, model lengkap berfungsi dengan baik dalam penaakulan kontrafak dan tugas perancangan gelung terbuka. Data latihan dalam talian, modul masa dan pengawasan persepsi 3D bagi garisan lorong dan objek memainkan peranan penting dalam meningkatkan prestasi model. Model lengkap boleh menggunakan maklumat pelbagai mod secara berkesan untuk perancangan dan membuat keputusan yang cekap, dan hasil percubaan ablasi mengesahkan lagi peranan utama komponen ini dalam tugas pemanduan autonomi.
En même temps, jetons un coup d'œil aux performances de NuScenes-QA : il démontre les performances d'OmniDrive dans les tâches de planification en boucle ouverte et les compare avec d'autres méthodes existantes. Les résultats montrent qu'OmniDrive++ (version complète) obtient les meilleures performances dans tous les indicateurs, en particulier en termes d'erreur moyenne de planification en boucle ouverte, de taux de collision et de taux d'intersection des limites de route, ce qui est meilleur que les autres méthodes.
Performance d'OmniDrive++ : Le modèle OmniDrive++ a des erreurs moyennes L2 de 0,14, 0,29 et 0,55 mètres dans le temps de prédiction de 1 seconde, 2 secondes et 3 secondes respectivement, et l'erreur moyenne finale n'est que de 0,33 mètre. De plus, le taux moyen de collisions et le taux moyen d'intersection des limites routières de ce modèle ont également atteint respectivement 0,30 % et 3,00 %, ce qui est bien inférieur à celui des autres méthodes. Surtout en termes de taux de collision, OmniDrive++ a atteint un taux de collision nul dans la période de prévision de 1 seconde et 2 secondes, démontrant pleinement ses excellentes capacités de planification et d'évitement d'obstacles.
Comparaison avec d'autres méthodes : Par rapport à d'autres modèles de référence avancés, tels que UniAD, BEV-Planner++ et Ego-MLP, OmniDrive++ surpasse tous les indicateurs clés. Lorsque UniAD utilise des commandes de haut niveau et des informations sur l'état du véhicule, son erreur moyenne L2 est de 0,46 mètre, tandis qu'OmniDrive++ a une erreur encore plus faible de 0,33 mètre avec les mêmes paramètres. Dans le même temps, le taux de collision et le taux d'intersection des routes d'OmniDrive++ sont également nettement inférieurs à ceux d'UniAD, en particulier le taux de collision est réduit de près de moitié.
Par rapport à BEV-Planner++, l'erreur L2 d'OmniDrive++ est considérablement réduite dans toutes les périodes de prédiction, en particulier dans la période de prédiction de 3 secondes, l'erreur est réduite de 0,57 mètre à 0,55 mètre. Dans le même temps, OmniDrive++ est également meilleur que BEV-Planner++ en termes de taux de collisions et de taux de franchissement des limites routières. Le taux de collisions a chuté de 0,34 % à 0,30 %, et le taux de franchissement des limites routières a chuté de 3,16 % à 3,00 %.
Expérience d'ablation : Afin d'évaluer plus en détail l'impact des modules clés de l'architecture OmniDrive sur les performances, l'auteur a également comparé les performances de différentes versions du modèle OmniDrive. OmniDrive (qui n'utilise pas de commandes de haut niveau ni d'informations sur l'état du véhicule autonome) est nettement inférieur au modèle complet en termes d'erreur de prédiction, de taux de collision et de taux de franchissement des limites routières, en particulier l'erreur L2 dans la période de prédiction de 3 secondes atteignant 2,84 mètres, avec une moyenne de Le taux de collision atteint 3,79 %.
En utilisant uniquement le modèle OmniDrive (sans commandes de haut niveau ni informations sur l'état du véhicule autonome), l'erreur de prédiction, le taux de collision et le taux d'intersection des routes se sont améliorés, mais il existe encore un écart par rapport au modèle complet. Cela montre que l'intégration de commandes de haut niveau et d'informations sur l'état du véhicule autonome a un effet significatif sur l'amélioration des performances globales de planification du modèle.
Dans l'ensemble, les résultats expérimentaux démontrent clairement les excellentes performances d'OmniDrive++ dans les tâches de planification en boucle ouverte. En intégrant des informations multimodales, des commandes de haut niveau et des informations sur l'état du véhicule autonome, OmniDrive++ permet une prévision de trajet plus précise et un taux de collision et d'intersection de routes plus faible dans les tâches de planification complexes, fournissant ainsi des informations pour la planification de la conduite autonome et la prise de décision solide. soutien.
Discussion

L'agent OmniDrive et l'ensemble de données OmniDrive-nuScenes proposés par l'auteur introduisent un nouveau paradigme dans le domaine des grands modèles multimodaux, capables de résoudre des problèmes de conduite dans des environnements 3D et de fournir une nouvelle plateforme pour de tels modèles L'évaluation fournit une référence complète. Cependant, chaque nouvelle méthode et chaque nouvel ensemble de données présente ses avantages et ses inconvénients.
L'agent OmniDrive propose une stratégie de formation en deux étapes : pré-formation 2D et mise au point 3D. Au cours de la phase de pré-entraînement 2D, un meilleur alignement entre les caractéristiques de l'image et les grands modèles de langage est obtenu en pré-entraînant les requêtes Q-Former et Carrier à l'aide de l'ensemble de données appariées image-texte de LLaVA v1.5. Lors de l'étape de réglage fin 3D, des modules de codage des informations de position 3D et de temps sont introduits pour améliorer les capacités de positionnement 3D du modèle. En tirant parti de LoRA pour affiner l'encodeur visuel et le modèle de langage, OmniDrive maintient sa compréhension de la sémantique 2D tout en améliorant sa maîtrise de la localisation 3D. Cette stratégie de formation par étapes libère pleinement le potentiel du grand modèle multimodal, en lui donnant de meilleures capacités de perception, de raisonnement et de planification dans des scénarios de conduite 3D. D'autre part, OmniDrive-nuScenes sert de nouvelle référence spécialement conçue pour évaluer la capacité à piloter de grands modèles. Son processus de génération d'assurance qualité entièrement automatisé génère des paires question-réponse de haute qualité via GPT-4, couvrant différentes tâches, de la perception à la planification. De plus, la tâche de positionnement générée en ligne fournit également une amélioration implicite des données pour le modèle, l'aidant ainsi à mieux comprendre l'environnement 3D. L'avantage de cet ensemble de données est qu'il teste non seulement les capacités de perception et de raisonnement du modèle, mais évalue également les capacités de compréhension spatiale et de planification du modèle à travers des problèmes à long terme. Ce benchmark complet apporte un soutien solide au développement de futurs grands modèles multimodaux.
Cependant, l'agent OmniDrive et l'ensemble de données OmniDrive-nuScenes présentent également certaines lacunes. Premièrement, étant donné que l'agent OmniDrive doit affiner l'ensemble du modèle pendant la phase de réglage fin 3D, les besoins en ressources de formation sont élevés, ce qui augmente considérablement le temps de formation et les coûts matériels. De plus, la génération de données d'OmniDrive-nuScenes repose entièrement sur GPT-4. Bien que cela garantisse la qualité et la diversité des questions, cela amène également les questions générées à être plus inclinées vers des modèles dotés de fortes capacités de langage naturel, ce qui peut rendre le modèle plus performant. dépend davantage de tests de référence basés sur les caractéristiques linguistiques plutôt que sur la capacité réelle de conduite. Bien qu'OmniDrive-nuScenes fournisse une référence complète en matière d'assurance qualité, sa couverture des scénarios de conduite est encore limitée. Les règles de circulation et les simulations de planification impliquées dans l'ensemble de données sont uniquement basées sur l'ensemble de données nuScenes, ce qui rend difficile la représentation complète des problèmes générés par divers scénarios de conduite dans le monde réel. De plus, en raison de la nature hautement automatisée du processus de génération de données, les questions générées sont inévitablement affectées par les biais des données et par une conception rapide.
Conclusion
L'agent OmniDrive et l'ensemble de données OmniDrive-nuScenes proposés par l'auteur apportent une nouvelle perspective et une nouvelle référence d'évaluation à la recherche multimodale de grands modèles dans des scènes de conduite 3D. La stratégie de formation en deux étapes de l'agent OmniDrive combine avec succès la pré-formation 2D et le réglage fin 3D, ce qui donne naissance à des modèles qui excellent en matière de perception, de raisonnement et de planification. En tant que nouvelle référence en matière d'assurance qualité, OmniDrive-nuScenes fournit des indicateurs complets pour évaluer les grands modèles de conduite. Cependant, des recherches supplémentaires sont encore nécessaires pour optimiser les besoins en ressources de formation du modèle, améliorer le processus de génération d'ensembles de données et garantir que les questions générées représentent plus précisément l'environnement de conduite réel. Dans l’ensemble, la méthode et l’ensemble de données de l’auteur sont d’une grande importance pour faire progresser la recherche multimodale sur grands modèles dans le domaine de la conduite automobile, posant ainsi une base solide pour les travaux futurs.
Atas ialah kandungan terperinci LLM sudah selesai! OmniDrive: Mengintegrasikan persepsi 3D dan perancangan penaakulan (terbaharu NVIDIA). Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!

Alat AI Hot

Undresser.AI Undress
Apl berkuasa AI untuk mencipta foto bogel yang realistik

AI Clothes Remover
Alat AI dalam talian untuk mengeluarkan pakaian daripada foto.

Undress AI Tool
Gambar buka pakaian secara percuma

Clothoff.io
Penyingkiran pakaian AI

Video Face Swap
Tukar muka dalam mana-mana video dengan mudah menggunakan alat tukar muka AI percuma kami!

Artikel Panas
Alat panas

Notepad++7.3.1
Editor kod yang mudah digunakan dan percuma

SublimeText3 versi Cina
Versi Cina, sangat mudah digunakan

Hantar Studio 13.0.1
Persekitaran pembangunan bersepadu PHP yang berkuasa

Dreamweaver CS6
Alat pembangunan web visual

SublimeText3 versi Mac
Perisian penyuntingan kod peringkat Tuhan (SublimeText3)
Topik panas
 1664
1664
 14
1423
52
1317
25
1268
29
1246
24
14
1423
52
1317
25
1268
29
1246
24

 Model MoE sumber terbuka paling berkuasa di dunia ada di sini, dengan keupayaan bahasa Cina setanding dengan GPT-4, dan harganya hanya hampir satu peratus daripada GPT-4-Turbo
May 07, 2024 pm 04:13 PM
Model MoE sumber terbuka paling berkuasa di dunia ada di sini, dengan keupayaan bahasa Cina setanding dengan GPT-4, dan harganya hanya hampir satu peratus daripada GPT-4-Turbo
May 07, 2024 pm 04:13 PM
Bayangkan model kecerdasan buatan yang bukan sahaja mempunyai keupayaan untuk mengatasi pengkomputeran tradisional, tetapi juga mencapai prestasi yang lebih cekap pada kos yang lebih rendah. Ini bukan fiksyen sains, DeepSeek-V2[1], model MoE sumber terbuka paling berkuasa di dunia ada di sini. DeepSeek-V2 ialah gabungan model bahasa pakar (MoE) yang berkuasa dengan ciri-ciri latihan ekonomi dan inferens yang cekap. Ia terdiri daripada 236B parameter, 21B daripadanya digunakan untuk mengaktifkan setiap penanda. Berbanding dengan DeepSeek67B, DeepSeek-V2 mempunyai prestasi yang lebih kukuh, sambil menjimatkan 42.5% kos latihan, mengurangkan cache KV sebanyak 93.3% dan meningkatkan daya pemprosesan penjanaan maksimum kepada 5.76 kali. DeepSeek ialah sebuah syarikat yang meneroka kecerdasan buatan am
 Bagaimana untuk menyelesaikan masalah ekor panjang dalam senario pemanduan autonomi?
Jun 02, 2024 pm 02:44 PM
Bagaimana untuk menyelesaikan masalah ekor panjang dalam senario pemanduan autonomi?
Jun 02, 2024 pm 02:44 PM
Semalam semasa temu bual, saya telah ditanya sama ada saya telah membuat sebarang soalan berkaitan ekor panjang, jadi saya fikir saya akan memberikan ringkasan ringkas. Masalah ekor panjang pemanduan autonomi merujuk kepada kes tepi dalam kenderaan autonomi, iaitu, kemungkinan senario dengan kebarangkalian yang rendah untuk berlaku. Masalah ekor panjang yang dirasakan adalah salah satu sebab utama yang kini mengehadkan domain reka bentuk pengendalian kenderaan autonomi pintar satu kenderaan. Seni bina asas dan kebanyakan isu teknikal pemanduan autonomi telah diselesaikan, dan baki 5% masalah ekor panjang secara beransur-ansur menjadi kunci untuk menyekat pembangunan pemanduan autonomi. Masalah ini termasuk pelbagai senario yang berpecah-belah, situasi yang melampau dan tingkah laku manusia yang tidak dapat diramalkan. "Ekor panjang" senario tepi dalam pemanduan autonomi merujuk kepada kes tepi dalam kenderaan autonomi (AVs) kes Edge adalah senario yang mungkin dengan kebarangkalian yang rendah untuk berlaku. kejadian yang jarang berlaku ini
 Apr 09, 2024 am 11:52 AM
Apr 09, 2024 am 11:52 AM
AI memang mengubah matematik. Baru-baru ini, Tao Zhexuan, yang telah mengambil perhatian terhadap isu ini, telah memajukan keluaran terbaru "Buletin Persatuan Matematik Amerika" (Buletin Persatuan Matematik Amerika). Memfokuskan pada topik "Adakah mesin akan mengubah matematik?", ramai ahli matematik menyatakan pendapat mereka Seluruh proses itu penuh dengan percikan api, tegar dan menarik. Penulis mempunyai barisan yang kuat, termasuk pemenang Fields Medal Akshay Venkatesh, ahli matematik China Zheng Lejun, saintis komputer NYU Ernest Davis dan ramai lagi sarjana terkenal dalam industri. Dunia AI telah berubah secara mendadak Anda tahu, banyak artikel ini telah dihantar setahun yang lalu.
 Hello, Atlas elektrik! Robot Boston Dynamics hidup semula, gerakan pelik 180 darjah menakutkan Musk
Apr 18, 2024 pm 07:58 PM
Hello, Atlas elektrik! Robot Boston Dynamics hidup semula, gerakan pelik 180 darjah menakutkan Musk
Apr 18, 2024 pm 07:58 PM
Boston Dynamics Atlas secara rasmi memasuki era robot elektrik! Semalam, Atlas hidraulik hanya "menangis" menarik diri daripada peringkat sejarah Hari ini, Boston Dynamics mengumumkan bahawa Atlas elektrik sedang berfungsi. Nampaknya dalam bidang robot humanoid komersial, Boston Dynamics berazam untuk bersaing dengan Tesla. Selepas video baharu itu dikeluarkan, ia telah pun ditonton oleh lebih sejuta orang dalam masa sepuluh jam sahaja. Orang lama pergi dan peranan baru muncul. Ini adalah keperluan sejarah. Tidak dinafikan bahawa tahun ini adalah tahun letupan robot humanoid. Netizen mengulas: Kemajuan robot telah menjadikan majlis pembukaan tahun ini kelihatan seperti manusia, dan tahap kebebasan adalah jauh lebih besar daripada manusia Tetapi adakah ini benar-benar bukan filem seram? Pada permulaan video, Atlas berbaring dengan tenang di atas tanah, seolah-olah terlentang. Apa yang berikut adalah rahang-jatuh
 KAN, yang menggantikan MLP, telah diperluaskan kepada konvolusi oleh projek sumber terbuka
Jun 01, 2024 pm 10:03 PM
KAN, yang menggantikan MLP, telah diperluaskan kepada konvolusi oleh projek sumber terbuka
Jun 01, 2024 pm 10:03 PM
Awal bulan ini, penyelidik dari MIT dan institusi lain mencadangkan alternatif yang sangat menjanjikan kepada MLP - KAN. KAN mengatasi MLP dari segi ketepatan dan kebolehtafsiran. Dan ia boleh mengatasi prestasi MLP berjalan dengan bilangan parameter yang lebih besar dengan bilangan parameter yang sangat kecil. Sebagai contoh, penulis menyatakan bahawa mereka menggunakan KAN untuk menghasilkan semula keputusan DeepMind dengan rangkaian yang lebih kecil dan tahap automasi yang lebih tinggi. Khususnya, MLP DeepMind mempunyai kira-kira 300,000 parameter, manakala KAN hanya mempunyai kira-kira 200 parameter. KAN mempunyai asas matematik yang kukuh seperti MLP berdasarkan teorem penghampiran universal, manakala KAN berdasarkan teorem perwakilan Kolmogorov-Arnold. Seperti yang ditunjukkan dalam rajah di bawah, KAN telah
 Robot Tesla bekerja di kilang, Musk: Tahap kebebasan tangan akan mencapai 22 tahun ini!
May 06, 2024 pm 04:13 PM
Robot Tesla bekerja di kilang, Musk: Tahap kebebasan tangan akan mencapai 22 tahun ini!
May 06, 2024 pm 04:13 PM
Video terbaru robot Tesla Optimus dikeluarkan, dan ia sudah boleh berfungsi di kilang. Pada kelajuan biasa, ia mengisih bateri (bateri 4680 Tesla) seperti ini: Pegawai itu juga mengeluarkan rupanya pada kelajuan 20x - pada "stesen kerja" kecil, memilih dan memilih dan memilih: Kali ini ia dikeluarkan Salah satu sorotan video itu ialah Optimus menyelesaikan kerja ini di kilang, sepenuhnya secara autonomi, tanpa campur tangan manusia sepanjang proses. Dan dari perspektif Optimus, ia juga boleh mengambil dan meletakkan bateri yang bengkok, memfokuskan pada pembetulan ralat automatik: Berkenaan tangan Optimus, saintis NVIDIA Jim Fan memberikan penilaian yang tinggi: Tangan Optimus adalah robot lima jari di dunia paling cerdik. Tangannya bukan sahaja boleh disentuh
 Yang terbaru dari Universiti Oxford! Mickey: Padanan imej 2D dalam SOTA 3D! (CVPR\'24)
Apr 23, 2024 pm 01:20 PM
Yang terbaru dari Universiti Oxford! Mickey: Padanan imej 2D dalam SOTA 3D! (CVPR\'24)
Apr 23, 2024 pm 01:20 PM
Pautan projek ditulis di hadapan: https://nianticlabs.github.io/mickey/ Memandangkan dua gambar, pose kamera di antara mereka boleh dianggarkan dengan mewujudkan kesesuaian antara gambar. Biasanya, surat-menyurat ini adalah 2D hingga 2D, dan anggaran pose kami adalah skala-tak tentu. Sesetengah aplikasi, seperti realiti tambahan segera pada bila-bila masa, di mana-mana sahaja, memerlukan anggaran pose metrik skala, jadi mereka bergantung pada penganggar kedalaman luaran untuk memulihkan skala. Makalah ini mencadangkan MicKey, proses pemadanan titik utama yang mampu meramalkan korespondensi metrik dalam ruang kamera 3D. Dengan mempelajari padanan koordinat 3D merentas imej, kami dapat membuat kesimpulan relatif metrik
 Mari kita bincangkan tentang sistem pemanduan autonomi hujung ke hujung dan generasi seterusnya, serta beberapa salah faham tentang pemanduan autonomi hujung ke hujung?
Apr 15, 2024 pm 04:13 PM
Mari kita bincangkan tentang sistem pemanduan autonomi hujung ke hujung dan generasi seterusnya, serta beberapa salah faham tentang pemanduan autonomi hujung ke hujung?
Apr 15, 2024 pm 04:13 PM
Pada bulan lalu, atas sebab-sebab yang diketahui umum, saya telah mengadakan pertukaran yang sangat intensif dengan pelbagai guru dan rakan sekelas dalam industri. Topik yang tidak dapat dielakkan dalam pertukaran secara semula jadi adalah hujung ke hujung dan Tesla FSDV12 yang popular. Saya ingin mengambil kesempatan ini untuk menyelesaikan beberapa buah fikiran dan pendapat saya pada masa ini untuk rujukan dan perbincangan anda. Bagaimana untuk mentakrifkan sistem pemanduan autonomi hujung ke hujung, dan apakah masalah yang sepatutnya dijangka diselesaikan hujung ke hujung? Menurut definisi yang paling tradisional, sistem hujung ke hujung merujuk kepada sistem yang memasukkan maklumat mentah daripada penderia dan secara langsung mengeluarkan pembolehubah yang membimbangkan tugas. Sebagai contoh, dalam pengecaman imej, CNN boleh dipanggil hujung-ke-hujung berbanding kaedah pengekstrak ciri + pengelas tradisional. Dalam tugas pemanduan autonomi, masukkan data daripada pelbagai penderia (kamera/LiDAR
