

1. Apakah itu Unicode?
Unicode berasal daripada idea yang sangat mudah: masukkan semua aksara di dunia dalam satu set Selagi komputer menyokong set aksara ini, ia boleh memaparkan semua aksara dan tidak akan ada lagi aksara yang bercelaru.
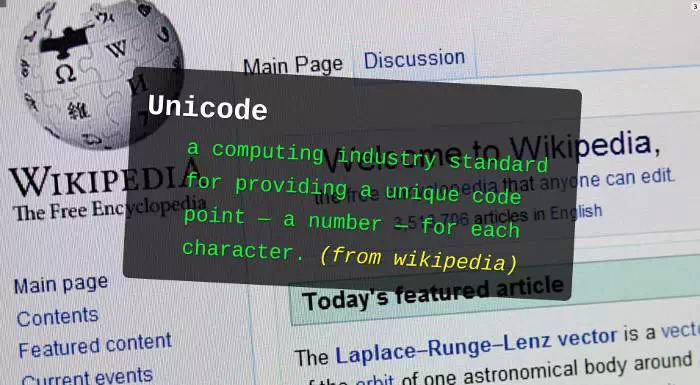
Ia bermula dari 0 dan memberikan nombor kepada setiap simbol, yang dipanggil "titik kod". Sebagai contoh, simbol untuk titik kod 0 adalah nol (bermaksud bahawa semua bit binari adalah 0).
Dalam formula di atas, U menunjukkan bahawa nombor perenambelasan serta-merta berikut ialah titik kod Unicode.

Pada masa ini, versi terkini Unicode ialah versi 7.0, yang mengandungi sejumlah 109,449 simbol, termasuk 74,500 aksara Cina, Jepun dan Korea. Ia boleh dianggarkan bahawa lebih daripada dua pertiga daripada simbol sedia ada di dunia berasal daripada skrip Asia Timur. Sebagai contoh, titik kod untuk "baik" dalam bahasa Cina ialah 597D dalam perenambelasan.
Dengan begitu banyak simbol, Unicode tidak ditakrifkan sekali, tetapi dalam sekatan. Setiap kawasan boleh menyimpan 65536 (216) aksara, yang dipanggil satah. Pada masa ini, terdapat 17 (25) pesawat secara keseluruhan, bermakna saiz keseluruhan set aksara Unicode kini ialah 221.
Bit aksara pertama 65536 dipanggil satah asas (singkatan BMP julat titik kodnya ialah dari 0 hingga 216-1 Ditulis dalam heksadesimal, ia adalah dari U 0000 hingga U FFFF. Semua aksara yang paling biasa diletakkan pada pesawat ini, yang merupakan pesawat yang pertama kali ditakrifkan dan diumumkan oleh Unicode.
Aksara yang tinggal diletakkan dalam satah tambahan (disingkatkan sebagai SMP), dan titik kod berjulat dari U 010000 hingga U 10FFFF.

2. UTF-32 dan UTF-8
Unicode hanya menetapkan titik kod setiap aksara Apakah jenis susunan bait yang digunakan untuk mewakili titik kod ini melibatkan kaedah pengekodan.
Kaedah pengekodan yang paling intuitif ialah setiap titik kod diwakili oleh empat bait dan kandungan bait sepadan dengan titik kod satu-satu. Kaedah pengekodan ini dipanggil UTF-32. Sebagai contoh, titik kod 0 diwakili oleh empat bait 0, dan titik kod 597D didahului oleh dua bait 0.

Kelebihan UTF-32 ialah peraturan penukaran adalah mudah dan intuitif serta kecekapan carian adalah tinggi. Kelemahannya ialah ia membazir ruang Untuk teks bahasa Inggeris yang sama, ia akan menjadi empat kali lebih besar daripada pengekodan ASCII. Kelemahan ini sangat membawa maut sehingga tiada siapa yang benar-benar menggunakan kaedah pengekodan ini Piawaian HTML5 dengan jelas menetapkan bahawa halaman web tidak boleh dikodkan ke dalam UTF-32.

Apa yang orang benar-benar perlukan ialah kaedah pengekodan penjimatan ruang, yang membawa kepada kelahiran UTF-8. UTF-8 ialah kaedah pengekodan panjang boleh ubah, dengan panjang aksara antara 1 bait hingga 4 bait. Lebih banyak aksara yang digunakan, lebih pendek bait 128 aksara pertama hanya diwakili oleh 1 bait, yang sama persis dengan kod ASCII.
Bait julat nombor 0x0000 - 0x007F10x0080 - 0x07FF20x0800 - 0xFFFF30x010000 - 0x10FFFF4
Disebabkan ciri penjimatan ruang UTF-8, ia telah menjadi pengekodan halaman web yang paling biasa di Internet. Walau bagaimanapun, ia mempunyai sedikit kaitan dengan topik hari ini, jadi saya tidak akan pergi ke mendalam Untuk kaedah transcoding tertentu, anda boleh merujuk kepada "Nota Pengekodan Aksara" yang saya tulis bertahun-tahun yang lalu.
3. Pengenalan kepada UTF-16
Pengekodan UTF-16 adalah antara UTF-32 dan UTF-8, dan menggabungkan ciri kaedah pengekodan panjang tetap dan panjang berubah-ubah.
Peraturan pengekodannya sangat mudah: aksara dalam satah asas menduduki 2 bait, dan aksara dalam satah tambahan menduduki 4 bait. Maksudnya, panjang pengekodan UTF-16 ialah sama ada 2 bait (U 0000 hingga U FFFF) atau 4 bait (U 010000 hingga U 10FFFF).

Jadi, terdapat satu soalan apabila kita menemui dua bait, bagaimana kita boleh mengetahui sama ada ia adalah aksara dengan sendirinya, atau adakah ia perlu ditafsirkan bersama dua bait yang lain?
Ia sangat bijak Saya tidak tahu sama ada ia adalah reka bentuk yang disengajakan, dari U D800 hingga U DFFF adalah segmen kosong, iaitu titik kod ini tidak sepadan dengan mana-mana aksara. Oleh itu, segmen kosong ini boleh digunakan untuk memetakan aksara satah tambahan.
Secara khusus, terdapat 220 bit aksara dalam satah tambahan, yang bermaksud bahawa sekurang-kurangnya 20 bit perduaan diperlukan untuk sepadan dengan aksara ini. UTF-16 membahagikan 20 bit ini kepada separuh 10 bit pertama dipetakan dari U D800 ke U DBFF (saiz ruang 210), dipanggil bit tinggi (H), dan 10 bit terakhir dipetakan dari U DC00 ke U DFFF (. saiz ruang 210 , dipanggil bit rendah (L). Ini bermakna watak satah tambahan dibahagikan kepada dua perwakilan satah asas.

Jadi, apabila kita menemui dua bait dan mendapati bahawa titik kodnya berada di antara U D800 dan U DBFF, kita boleh membuat kesimpulan bahawa titik kod dua bait berikut hendaklah antara U DC00 dan U DBFF, empat ini bait mesti dibaca bersama.
4. Formula transkoding UTF-16
Apabila menukar mata kod Unikod kepada UTF-16, mula-mula bezakan sama ada ini ialah aksara rata asas atau aksara rata tambahan. Jika ia adalah yang pertama, terus tukar titik kod kepada bentuk perenambelasan yang sepadan, dengan panjang dua bait.
Jika ia adalah aksara rata tambahan, Unicode versi 3.0 menyediakan formula transcoding.

Ambil aksara  sebagai contoh Ia adalah watak satah tambahan dengan titik kod U 1D306 Proses pengiraan menukarnya kepada UTF-16 adalah seperti berikut.
sebagai contoh Ia adalah watak satah tambahan dengan titik kod U 1D306 Proses pengiraan menukarnya kepada UTF-16 adalah seperti berikut.
Jadi, pengekodan UTF-16 aksara ialah 0xD834 DF06, dan panjangnya ialah empat bait.

5. Pengekodan manakah yang digunakan oleh JavaScript?

Bahasa JavaScript menggunakan set aksara Unicode, tetapi hanya menyokong satu kaedah pengekodan.
Pengekodan ini bukan UTF-16, bukan UTF-8, mahupun UTF-32. Tiada kaedah pengekodan di atas digunakan dalam JavaScript.
JavaScript menggunakan UCS-2!

6. Pengekodan UCS-2
Mengapa UCS-2 tiba-tiba muncul? Ini memerlukan sedikit sejarah.
Pada era sebelum Internet muncul, terdapat dua pasukan yang semuanya mahu mencipta set watak bersatu. Satu ialah pasukan Unicode yang ditubuhkan pada tahun 1988, dan satu lagi ialah pasukan UCS yang ditubuhkan pada tahun 1989. Apabila mereka mengetahui kewujudan satu sama lain, mereka dengan cepat mencapai persetujuan: dunia tidak memerlukan dua set watak bersatu.
Pada Oktober 1991, kedua-dua pasukan memutuskan untuk menggabungkan set watak. Dalam erti kata lain, mulai sekarang, hanya satu set aksara akan dikeluarkan, iaitu Unicode, dan set aksara yang dikeluarkan sebelum ini akan disemak semula Titik kod UCS akan selaras sepenuhnya dengan Unicode.

Kemajuan pembangunan UCS lebih pantas daripada Unicode Kaedah pengekodan pertama UCS-2 diumumkan pada tahun 1990, menggunakan 2 bait untuk mewakili aksara yang sudah mempunyai titik kod. (Pada masa itu, hanya terdapat satu satah, satah asas, jadi 2 bait sudah mencukupi.) Pengekodan UTF-16 tidak diumumkan sehingga Julai 1996, dan ia telah diumumkan dengan jelas bahawa ia adalah superset UCS-2, iaitu , aksara satah asas telah diwarisi, pengekodan UCS-2, aksara satah tambahan mentakrifkan kaedah perwakilan 4-bait.
Ringkasnya, hubungan antara keduanya ialah UTF-16 menggantikan UCS-2, atau UCS-2 disepadukan ke dalam UTF-16. Jadi, kini hanya ada UTF-16, tiada UCS-2.
7. Latar belakang kelahiran JavaScript
Jadi, mengapa JavaScript tidak memilih UTF-16 yang lebih maju, tetapi menggunakan UCS-2 yang usang?
Jawapannya mudah: sama ada anda tidak mahu atau tidak. Kerana apabila bahasa JavaScript muncul, tiada pengekodan UTF-16.
Pada bulan Mei 1995, Brendan Eich menghabiskan 10 hari mereka bentuk bahasa JavaScript pada bulan Oktober, enjin tafsiran pertama dikeluarkan pada bulan November tahun berikutnya, Netscape secara rasmi menyerahkan standard bahasa kepada ECMA (untuk butiran mengenai keseluruhan proses, lihat "Kelahiran JavaScript" ). Membandingkan masa keluaran UTF-16 (Julai 1996), anda akan faham bahawa Netscape tidak mempunyai pilihan lain pada masa itu, hanya UCS-2 tersedia sebagai kaedah pengekodan!

8. Had fungsi aksara JavaScript
Memandangkan JavaScript hanya boleh mengendalikan pengekodan UCS-2, semua aksara dalam bahasa ini adalah 2 bait Jika ia ialah aksara 4-bait, ia akan dianggap sebagai dua aksara bait dua. Fungsi aksara JavaScript semuanya dipengaruhi oleh ini dan tidak dapat mengembalikan hasil yang betul.

Mari kita ambil watak sebagai contoh Pengekodan UTF-16nya ialah 4 bait 0xD834DF06. Masalah timbul. Pengekodan 4-bait bukan milik UCS-2 JavaScript tidak mengenalinya dan hanya akan menganggapnya sebagai dua aksara berasingan, U D834 dan U DF06. Seperti yang dinyatakan sebelum ini, kedua-dua titik kod ini kosong, jadi JavaScript akan berfikir bahawa ialah rentetan yang terdiri daripada dua aksara kosong!

Kod di atas menunjukkan bahawa JavaScript menganggap panjang aksara sebagai 2, aksara pertama yang diperoleh ialah aksara nol, dan titik kod aksara pertama yang diperoleh ialah 0xDB34. Tiada satu pun daripada keputusan ini betul!

Untuk menyelesaikan masalah ini, anda mesti membuat pertimbangan pada titik kod dan kemudian melaraskannya secara manual. Berikut ialah cara yang betul untuk melintasi rentetan.
Kod di atas menunjukkan bahawa apabila melintasi rentetan, pertimbangan mesti dibuat pada titik kod Selagi ia berada dalam julat dari 0xD800 hingga 0xDBFF, ia mesti dibaca bersama-sama dengan 2 bait berikut
Masalah serupa wujud dengan semua fungsi manipulasi aksara JavaScript.
String.prototype.replace()
String.prototype.substring()
String.prototype.slice()
...
Fungsi di atas hanya sah untuk titik kod 2-bait. Untuk mengendalikan titik kod 4-bait dengan betul, anda mesti menggunakan versi anda sendiri satu demi satu untuk menentukan julat titik kod aksara semasa.
9. ECMAScript 6

Versi JavaScript seterusnya, ECMAScript 6 (pendek kata ES6), meningkatkan sokongan Unicode dan pada asasnya menyelesaikan masalah ini.
(1) Kenal pasti watak dengan betul
ES6 boleh mengecam titik kod 4-bait secara automatik. Oleh itu, mengulangi rentetan adalah lebih mudah.
Namun, untuk mengekalkan keserasian, atribut length masih berkelakuan dalam cara asalnya. Untuk mendapatkan panjang rentetan yang betul, anda boleh menggunakan kaedah berikut.
(2) Perwakilan titik kod
JavaScript membolehkan anda menggunakan titik kod secara langsung untuk mewakili aksara Unikod Kaedah penulisan ialah "titik kod u segaris ke belakang".
Walau bagaimanapun, perwakilan ini tidak sah untuk titik kod 4-bait. ES6 membetulkan masalah ini, dan titik kod boleh dikenali dengan betul selagi ia diletakkan dalam kurungan kerinting.

(3) Fungsi pemprosesan rentetan
ES6 menambah beberapa fungsi baharu yang mengendalikan titik kod 4-bait secara khusus.
String.fromCodePoint(): Mengembalikan aksara yang sepadan daripada titik kod Unicode
String.prototype.codePointAt(): Mengembalikan titik kod yang sepadan daripada aksara
String.prototype.at(): Mengembalikan aksara pada kedudukan yang diberikan dalam rentetan
(4) Ungkapan biasa
ES6 menyediakan pengubah suai u, yang menyokong penambahan titik kod 4-bait pada ungkapan biasa.

(5) Penyelarasan Unikod
Sesetengah aksara mempunyai simbol tambahan sebagai tambahan kepada huruf. Contohnya, dalam Pinyin Cina Ǒ, nada di atas huruf adalah simbol tambahan. Bagi kebanyakan bahasa Eropah, tanda nada adalah sangat penting.

Unicode menyediakan dua kaedah perwakilan. Satu ialah aksara tunggal dengan simbol tambahan, iaitu, satu titik kod mewakili satu aksara, contohnya, titik kod Ǒ ialah U 01D1; iaitu dua kod Titik A mewakili aksara, contohnya Ǒ boleh ditulis sebagai O (U 004F) ˇ (U 030C).
Kedua-dua perwakilan adalah sama secara visual dan semantik dan harus dianggap sebagai setara. Walau bagaimanapun, JavaScript tidak dapat memberitahu.
ES6 menyediakan kaedah normalize, membenarkan "Unicode normalization", iaitu menukar dua kaedah kepada jujukan yang sama.
Untuk pengenalan lanjut kepada ES6, sila lihat "Pengenalan kepada ECMAScript 6".
















![[Web front-end] Permulaan pantas Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



