Jumlah kandungan berkaitan 10000

Model pra-latihan Teks-ke-SQL dua peringkat berbilang tugas MIGA berdasarkan T5
Pengenalan Artikel:Semakin banyak kerja telah membuktikan bahawa model bahasa pra-latihan (PLM) mengandungi pengetahuan yang kaya Untuk tugasan yang berbeza, menggunakan kaedah latihan yang sesuai untuk memanfaatkan PLM boleh meningkatkan keupayaan model dengan lebih baik. Dalam tugas Text-to-SQL, penjana arus perdana semasa adalah berdasarkan pepohon sintaks dan perlu direka bentuk untuk sintaks SQL. Baru-baru ini, NetEase Interactive Entertainment AI Lab bekerjasama dengan Guangdong University of Foreign Studies dan Columbia University untuk mencadangkan dua peringkat model pra-latihan pelbagai tugas MIGA berdasarkan kaedah pra-latihan model bahasa pra-latihan T5. MIGA memperkenalkan tiga tugas tambahan dalam peringkat pra-latihan dan menyusunnya ke dalam paradigma tugas penjanaan bersatu, yang boleh menyepadukan semua set data Teks-ke-SQL
2023-04-13
komen 0
1306

Model pra-latihan khusus untuk domain NLP bioperubatan: PubMedBERT
Pengenalan Artikel:Perkembangan pesat model bahasa besar tahun ini telah menyebabkan model seperti BERT kini dipanggil model "kecil". Dalam pertandingan peperiksaan sains LLM Kaggle, pemain yang menggunakan deberta mencapai tempat keempat, yang merupakan keputusan yang cemerlang. Oleh itu, dalam domain atau keperluan tertentu, model bahasa yang besar tidak semestinya diperlukan sebagai penyelesaian terbaik, dan model kecil juga mempunyai tempatnya. Oleh itu, apa yang akan kami perkenalkan hari ini ialah PubMedBERT, sebuah kertas kerja yang diterbitkan oleh Microsoft Research di ACM pada tahun 2022. Model ini melatih BERT dari awal dengan menggunakan korpora khusus domain Berikut adalah perkara utama kertas kerja: Untuk pengguna dengan domain khusus dengan sejumlah besar teks tidak berlabel, seperti bioperubatan, pra-latihan dari awal
2023-11-27
komen 0
1235

Analisis teknikal PHP ChatGPT: Cara menggunakan model terlatih untuk membina aplikasi sembang pintar
Pengenalan Artikel:Analisis teknikal ChatGPTPHP: Cara menggunakan model terlatih untuk membina aplikasi sembang pintar Dalam era maklumat hari ini, aplikasi sembang pintar telah menjadi bahagian yang amat diperlukan dalam kehidupan dan perniagaan harian. Aplikasi sembang pintar boleh membantu pengguna berkomunikasi dalam bahasa semula jadi dan memberikan jawapan masa nyata kepada soalan dan cadangan. Projek ChatGPT sumber terbuka baru-baru ini memberikan kami cara yang berkesan untuk membina aplikasi sembang pintar. Artikel ini akan memperkenalkan secara terperinci cara menggunakan bahasa pengaturcaraan PHP digabungkan dengan model pra-latihan untuk membina aplikasi sembang pintar, dan menyediakan
2023-10-24
komen 0
1098


CMU bergabung tenaga dengan Adobe: Model GAN menyambut era pra-latihan, hanya memerlukan 1% sampel latihan
Pengenalan Artikel:Selepas memasuki era pra-latihan, prestasi model pengecaman visual telah berkembang pesat, tetapi model penjanaan imej, seperti rangkaian musuh generatif (GAN), nampaknya telah ketinggalan. Biasanya latihan GAN dilakukan dari awal tanpa pengawasan, yang memakan masa dan memerlukan tenaga kerja "ilmu" yang dipelajari melalui data besar dalam pra-latihan berskala besar tidak digunakan. Selain itu, penjanaan imej itu sendiri perlu dapat menangkap dan mensimulasikan data statistik yang kompleks dalam fenomena visual dunia sebenar Jika tidak, imej yang dihasilkan tidak akan mematuhi undang-undang dunia fizikal dan akan dikenal pasti secara langsung sebagai "palsu" pada sesuatu. sepintas lalu. Model pra-latihan memberikan pengetahuan, dan model GAN menyediakan keupayaan penjanaan Gabungan kedua-duanya boleh menjadi perkara yang indah! Persoalannya, model pra-latihan manakah dan cara menggabungkannya boleh meningkatkan keupayaan penjanaan model GAN
2023-05-11
komen 0
1467

Satu lagi revolusi dalam pembelajaran pengukuhan! DeepMind mencadangkan 'penyulingan algoritma': Transformer pembelajaran tetulang pra-latihan yang boleh diterokai
Pengenalan Artikel:Dalam tugas pemodelan jujukan semasa, Transformer boleh dikatakan sebagai seni bina rangkaian saraf yang paling berkuasa, dan model Transformer yang telah terlatih boleh menggunakan gesaan sebagai syarat atau pembelajaran dalam konteks untuk menyesuaikan diri dengan tugas hiliran yang berbeza. Keupayaan generalisasi model Transformer pra-latihan berskala besar telah disahkan dalam pelbagai bidang, seperti pelengkapan teks, pemahaman bahasa, penjanaan imej, dsb. Sejak tahun lepas, terdapat kerja yang relevan membuktikan bahawa dengan menganggap pembelajaran pengukuhan luar talian (RL luar talian) sebagai masalah ramalan jujukan, model itu boleh mempelajari dasar daripada data luar talian. Tetapi pendekatan semasa sama ada mempelajari dasar daripada data yang tidak mengandungi pembelajaran
2023-04-12
komen 0
1848

Tidak menemui model pra-latihan pertuturan Cina? Versi Cina Wav2vec 2.0 dan HuBERT akan datang
Pengenalan Artikel:Model pra-latihan pertuturan seperti Wav2vec 2.0 [1], HuBERT [2] dan WavLM [3] telah meningkatkan pembelajaran automatik dengan ketara melalui pembelajaran penyeliaan kendiri pada puluhan ribu jam data pertuturan tidak berlabel (seperti Libri-light). Prestasi tugasan hiliran pertuturan seperti Automatic Speech Recognition (ASR), Text-to-speech (TTS) dan Voice Conversion (VC). Walau bagaimanapun, model ini tidak mempunyai versi Cina awam, menjadikannya menyusahkan untuk digunakan dalam senario penyelidikan pertuturan Cina. WenetSpeech [4] Ya
2023-04-08
komen 0
1926

Teknologi Mininglamp mengeluarkan TensorBoard.cpp sumber terbuka percuma untuk mempromosikan pra-latihan model besar
Pengenalan Artikel:Baru-baru ini, Kumpulan Teknologi Mininglamp telah melaksanakan antara muka C++ TensorBoard, alat visualisasi pembelajaran mesin, yang memperkayakan lagi set alatan projek model besar berasaskan C++, menjadikan pemantauan proses pra-latihan model besar lebih mudah dan cekap, dan mempercepatkan besar. model pra-latihan dalam proses pemasaran. Alat ini adalah sumber terbuka pada Github. TensorBoard ialah alat visualisasi pembelajaran mesin yang dibangunkan oleh Google dan sering digunakan untuk memantau pelbagai penunjuk proses pembelajaran mesin. Zhao Liang, pengarah teknikal kanan Mininglamp Technology, berkata: "Dalam proses latihan model besar, pemantauan data adalah dimensi penting, dan TensorBoard menggambarkan pelbagai parameter dan keputusan dalam model, seperti merekodkan perubahan Kerugian dan set pengesahan semasa besar. proses latihan model.
2023-08-14
komen 0
821

CVPR 2024 |. Pra-latihan ruang masa empat dimensi model dunia pemanduan autonomi
Pengenalan Artikel:Universiti Peking dan pasukan inovasi EVLO bersama-sama mencadangkan DriveWorld, algoritma pra-latihan ruang masa empat dimensi untuk pemanduan autonomi. Kaedah ini menggunakan model dunia untuk pra-latihan, mereka bentuk model ruang keadaan memori untuk pemodelan spatio-temporal empat dimensi, dan mengurangkan ketidakpastian rawak dan ketidakpastian pengetahuan yang dihadapi oleh pemanduan autonomi dengan meramalkan grid pekerjaan tempat kejadian. Kertas kerja ini telah diterima oleh CVPR2024. Tajuk kertas: DriveWorld: 4DPPre-trainedSceneUnderstandingviaWorldModelsforAutonomousDriving Paper pautan: https://arxiv.org/abs/2405.04390 1. Motion
2024-08-07
komen 0
841

Daripada BERT ke ChatGPT, tinjauan menyeluruh sembilan institusi penyelidikan terkemuka termasuk Universiti Beihang: 'model asas pra-latihan' yang telah kami usahakan bersama selama ini
Pengenalan Artikel:Prestasi menakjubkan ChatGPT dalam senario beberapa pukulan dan sifar pukulan telah menjadikan penyelidik lebih bertekad bahawa "pra-latihan" adalah laluan yang betul. Model asas pra-latihan (PretrainedFoundationModels,PFM) dianggap sebagai asas untuk pelbagai tugas hiliran di bawah mod data yang berbeza, iaitu, berdasarkan data berskala besar, model asas pra-latihan seperti BERT, GPT-3, MAE, DALLE- E dan ChatGPT dilatih, menyediakan permulaan parameter yang munasabah untuk aplikasi hiliran. Idea pra-latihan di sebalik PFM memainkan peranan penting dalam aplikasi model besar Berbeza daripada kaedah pengekstrakan ciri sebelum ini menggunakan modul konvolusi dan rekursif, yang baharu
2023-04-15
komen 0
1458

Apple menggunakan model bahasa autoregresif untuk pra-melatih model imej
Pengenalan Artikel:1. Latar Belakang Selepas kemunculan model besar seperti GPT, kaedah pemodelan Transformer + autoregressive model bahasa, yang merupakan tugas pra-latihan untuk meramal nexttoken, telah mencapai kejayaan besar. Jadi, bolehkah kaedah pemodelan autoregresif ini mencapai hasil yang lebih baik dalam model visual? Artikel yang diperkenalkan hari ini ialah artikel yang diterbitkan oleh Apple baru-baru ini tentang melatih model visual berdasarkan latihan pra-latihan Transformer+autoregressive Izinkan saya memperkenalkan karya ini kepada anda. Tajuk kertas gambar: ScalablePra-trainingofLargeAutoregressiveImageModels Alamat muat turun: https://ar
2024-01-29
komen 0
1019

Bagaimana untuk melakukan carian imej dengan cekap dan tepat? Lihatlah model pra-latihan penglihatan ringan
Pengenalan Artikel:Adakah anda pernah menghadapi masalah dengan mendapatkan semula imej? Sama ada sukar untuk mencari imej yang diperlukan dengan tepat dalam jumlah besar imej, atau ia tidak memuaskan dalam perolehan semula berasaskan teks. Mengenai masalah ini, penyelidik dari Microsoft Research Asia dan Bahagian Pengkomputeran Awan dan Kecerdasan Buatan Microsoft menjalankan penyelidikan mendalam tentang model visual ringan dan mencadangkan satu siri kaedah reka bentuk dan mampatan untuk model pra-latihan visual untuk merealisasikan keperluan penggunaan Visual Lightweight . Pada masa ini, kaedah dan model ini telah berjaya digunakan pada enjin carian Bing Microsoft, mencapai penaakulan yang tepat dan pantas serta mendapatkan semula berpuluh bilion imej. Artikel ini akan memberikan penjelasan yang mendalam tentang pembangunan, teknologi utama, aplikasi dan potensi model pra-latihan visual ringan, serta peluang dan cabaran masa depan saya harap semua orang dapat memahami dengan lebih baik
2023-04-08
komen 0
1365

Penjelasan terperinci tentang model pra-latihan pembelajaran mendalam dalam Python
Pengenalan Artikel:Dengan perkembangan kecerdasan buatan dan pembelajaran mendalam, model pra-latihan telah menjadi teknologi popular dalam pemprosesan bahasa semula jadi (NLP), penglihatan komputer (CV), pengecaman pertuturan dan bidang lain. Sebagai salah satu bahasa pengaturcaraan yang paling popular pada masa ini, Python secara semula jadi memainkan peranan penting dalam penerapan model pra-latihan. Artikel ini akan menumpukan pada model pra-latihan pembelajaran mendalam dalam Python, termasuk definisi, jenis, aplikasi dan cara menggunakan model pra-latihan. Apakah model pralatihan? Kesukaran utama model pembelajaran mendalam adalah untuk menganalisis sejumlah besar model yang berkualiti tinggi
2023-06-11
komen 0
2010

Latihan tersuai bagi model pembelajaran mendalam menggunakan teknik pembelajaran pemindahan
Pengenalan Artikel:Penterjemah |. Pengulas oleh Zhu Xianzhong |. Sun Shujuan Transfer learning ialah satu kaedah yang digunakan pada rangkaian saraf yang telah dilatih atau dilatih, dan rangkaian saraf yang telah dilatih ini dibina menggunakan berjuta-juta data yang terlatih. mata. Penggunaan teknologi ini yang paling terkenal pada masa ini adalah untuk melatih rangkaian saraf dalam, kerana kaedah ini telah menunjukkan prestasi yang baik dalam melatih rangkaian saraf dalam menggunakan kurang data. Malah, teknik ini juga berguna dalam bidang sains data, kerana kebanyakan data dunia sebenar biasanya tidak mempunyai berjuta-juta titik data untuk melatih model pembelajaran mendalam yang mantap. Pada masa ini, banyak model wujud yang dilatih menggunakan berjuta-juta titik data dan boleh digunakan untuk melatih rangkaian saraf pembelajaran mendalam yang kompleks dengan ketepatan maksimum.
2023-04-23
komen 0
1701


Panduan latihan model ChatGPT Python: langkah untuk menyesuaikan chatbot
Pengenalan Artikel:Panduan latihan model ChatGPTPython: Gambaran keseluruhan langkah untuk menyesuaikan robot sembang: Dalam beberapa tahun kebelakangan ini, dengan peningkatan pembangunan teknologi NLP (pemprosesan bahasa semula jadi), robot sembang telah menarik lebih banyak perhatian. ChatGPT OpenAI ialah model bahasa pra-latihan yang berkuasa yang boleh digunakan untuk membina chatbot berbilang domain. Artikel ini akan memperkenalkan langkah-langkah untuk menggunakan Python untuk melatih model ChatGPT, termasuk penyediaan data, latihan model dan penjanaan sampel dialog. Langkah 1: Penyediaan, pengumpulan dan pembersihan data
2023-10-24
komen 0
1334

Analisis RNA pelbagai fungsi, model bahasa RNA pasukan Baidu berdasarkan Transformer diterbitkan dalam sub-jurnal Alam
Pengenalan Artikel:Editor |. Model bahasa pra-latihan teras lobak telah menunjukkan janji yang baik dalam menganalisis jujukan nukleotida, tetapi masih terdapat cabaran dalam menggunakan set berat pra-latihan tunggal untuk mencapai model berbilang fungsi yang berfungsi dengan baik dalam tugasan yang berbeza. Pasukan Baidu Big Data Lab (BDL) dan Shanghai Jiao Tong University membangunkan RNAErnie, model pra-latihan berpusat RNA berdasarkan seni bina Transformer. Para penyelidik menilai model pada tujuh set data dan lima tugas, menunjukkan keunggulan RNAErnie dalam kedua-dua pembelajaran diselia dan tidak diselia. RNAErnie melepasi garis dasar, meningkatkan ketepatan klasifikasi sebanyak 1.8%, ketepatan ramalan interaksi sebanyak 2.2%, dan ramalan struktur skor F1 sebanyak 3.3%.
2024-06-10
komen 0
599
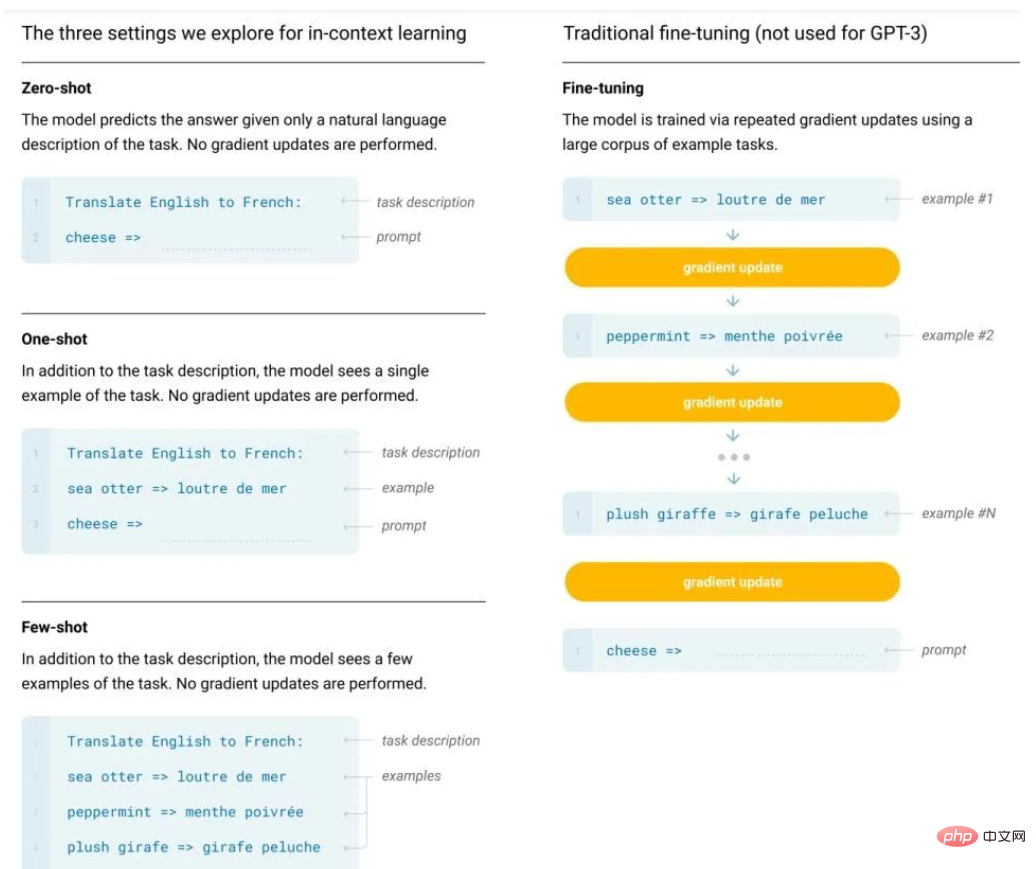
Mengapakah Pembelajaran Dalam Konteks, didorong oleh GPT, berfungsi? Model melakukan penurunan kecerunan secara rahsia
Pengenalan Artikel:Berikutan BERT, penyelidik telah melihat potensi model pra-latihan berskala besar, dan tugas pra-latihan yang berbeza, seni bina model, strategi latihan, dsb. telah dicadangkan. Walau bagaimanapun, model jenis BERT biasanya mempunyai dua kelemahan utama: satu adalah terlalu bergantung pada data berlabel; yang lain ialah fenomena pemasangan yang berlebihan; Khususnya, model bahasa semasa cenderung mempunyai rangka kerja dua peringkat, iaitu pra-latihan + penalaan halus tugas hiliran Walau bagaimanapun, sejumlah besar sampel diperlukan semasa proses penalaan halus untuk tugasan hiliran, jika tidak, kesannya akan berlaku menjadi miskin. Walau bagaimanapun, kos pelabelan data adalah tinggi. Terdapat juga data berlabel terhad, dan model hanya boleh memuatkan pengedaran data latihan Walau bagaimanapun, jika terdapat kurang data, ia adalah mudah untuk menyebabkan overfitting, yang akan mengurangkan keupayaan generalisasi model. Sebagai perintis model besar, model bahasa pra-latihan berskala besar, terutamanya GPT-3
2023-04-25
komen 0
1546

Universiti Peking & Perisikan Wangshi mencadangkan model baharu: merapatkan jurang antara pra-latihan tindak balas kimia dan penjanaan molekul bersyarat!
Pengenalan Artikel:Tindak balas kimia adalah asas reka bentuk ubat dan penyelidikan kimia organik. Terdapat keperluan yang semakin meningkat dalam kalangan komuniti penyelidikan untuk rangka kerja pembelajaran mendalam berskala besar yang boleh menangkap peraturan asas tindak balas kimia dengan berkesan. Baru-baru ini, pasukan penyelidik dari Universiti Peking dan Wangshi Intelligence mencadangkan kaedah baharu untuk merapatkan jurang antara tugas pra-latihan dan penjanaan molekul berasaskan tindak balas. Diilhamkan oleh mekanisme kimia organik, penyelidik membangunkan rangka kerja pra-latihan baharu yang membolehkannya menggabungkan bias induktif ke dalam model. Rangka kerja yang dicadangkan ini mencapai hasil terkini apabila melaksanakan tugas hiliran yang mencabar. Dengan memanfaatkan pengetahuan kimia, rangka kerja itu mengatasi batasan model penjanaan molekul semasa yang bergantung pada sebilangan kecil templat tindak balas. Dalam eksperimen yang meluas, model itu menghasilkan struktur seperti ubat yang boleh disintesis berkualiti tinggi Secara keseluruhannya, model
2023-12-14
komen 0
620
