Jumlah kandungan berkaitan 10000

Gambar rajah model pangkalan data kejuruteraan songsang dalam Visio2010
Pengenalan Artikel:1. Buat gambarajah model pangkalan data baharu dalam Visio Buka Visio2010, Fail->Baharu->Pangkalan Data->Rajah Model Pangkalan Data. Selepas mencipta rajah model pangkalan data, terdapat item menu tambahan [Pangkalan Data] dalam bar menu. Lihat gambar di bawah Terdapat item pangkalan data tambahan dalam bar menu 2. Item menu Kejuruteraan Terbalik Pangkalan Data - "Kejuruteraan Terbalik." Mulakan wizard kejuruteraan songsang dan lengkapkan tetapan kejuruteraan songsang langkah demi langkah. 2.1. Wujudkan sambungan dengan pangkalan data. Jenis pemacu Visio yang dipilih menentukan jenis pangkalan data yang boleh disambungkan dan pilihan yang tersedia. Sumber data menentukan lokasi pangkalan data dan maklumat sambungan. Di sini kami memilih pemacu Visio sebagai MicrosoftSqlServer dan sumber data sebagai BASICDATA yang baru dibuat. 2.2
2024-06-02
komen 0
1203
Kaedah terperinci untuk mencipta rajah model pangkalan data dalam Visio2010
Pengenalan Artikel:1. Buat gambarajah model pangkalan data baharu dalam Visio Buka Visio2010, Fail->Baharu->Pangkalan Data->Rajah Model Pangkalan Data. Selepas mencipta rajah model pangkalan data, terdapat item menu tambahan [Pangkalan Data] dalam bar menu. Lihat gambar di bawah. Terdapat item pangkalan data tambahan dalam bar menu model lukisan [Entiti] dan tahan butang kiri tetikus , seret terus ke kawasan lukisan dengan pembaris di tengah-tengah Kerja utama seterusnya adalah untuk menetapkan sifat jadual. Lihat tetapan sifat di bahagian bawah tetingkap antara muka utama program Sekarang pilih [Definisi] dalam kategori di sebelah kiri Masukkan nama fizikal dan nama konsep jadual data dalam urutan nama tidak konsisten
2024-06-12
komen 0
404

ICLR 2024 Spotlight |
Pengenalan Artikel:Pengarang|Unit PengfeiZheng|USTC,HKBUTMLRGroup Dalam beberapa tahun kebelakangan ini, perkembangan pesat AI generatif telah menyuntik dorongan kuat ke dalam bidang yang menarik perhatian seperti penjanaan teks ke imej dan penjanaan video. Teras teknik ini terletak pada aplikasi model resapan. Model resapan mula-mula menukar secara beransur-ansur gambar kepada hingar Gaussian dengan mentakrifkan proses ke hadapan yang menambah hingar secara berterusan, dan kemudian secara beransur-ansur menyahbunyi hingar Gaussian melalui proses terbalik dan mengubahnya menjadi gambar yang jelas untuk mendapatkan sampel sebenar. Model pembezaan biasa resapan digunakan untuk menginterpolasi nilai imej yang dijana, yang mempunyai potensi aplikasi yang hebat dalam menjana video dan beberapa kreatif pengiklanan. Walau bagaimanapun, kami mendapati bahawa apabila kaedah ini digunakan pada imej semula jadi, kesan imej interpolasi selalunya tidak memuaskan. wujud
2024-05-06
komen 0
1128

在数据库设计中,将er图转换成关系数据模型的过程属于什么
Pengenalan Artikel:在数据库设计中,将E-R图转换成关系数据模型的过程属于“逻辑设计阶段”。E-R图是用来描述现实世界的概念模型;而逻辑设计阶段的主要工作是将现实世界的概念数据模型设计成数据库的一种逻辑模式,即适应于某种特定数据库管理系统所支持的逻辑数据模式。
2021-05-07
komen 0
30495
Kaedah terperinci untuk melihat rajah model pangkalan data dalam Visio
Pengenalan Artikel:1. Buka Visio, seperti yang ditunjukkan di bawah. 2. Klik Fail, Baharu, Perisian dan Pangkalan Data, seperti yang ditunjukkan di bawah. 3. Pilih gambar rajah model pangkalan data, klik Cipta, dan kemudian berjaya mencipta fail vsd. Seperti yang ditunjukkan di bawah. 4. Pilih alat di sebelah kiri dan seret entiti ke dalam halaman, seperti yang ditunjukkan di bawah. 5. Di bahagian bawah halaman, edit maklumat entiti yang berkaitan (iaitu jadual), seperti yang ditunjukkan di bawah. 6. Klik pada lajur, di sini kita boleh menetapkan nama kunci dan format data, seperti yang ditunjukkan di bawah. 7. Semak pk untuk menetapkan kunci utama jadual, seperti yang ditunjukkan di bawah.
2024-06-11
komen 0
1126
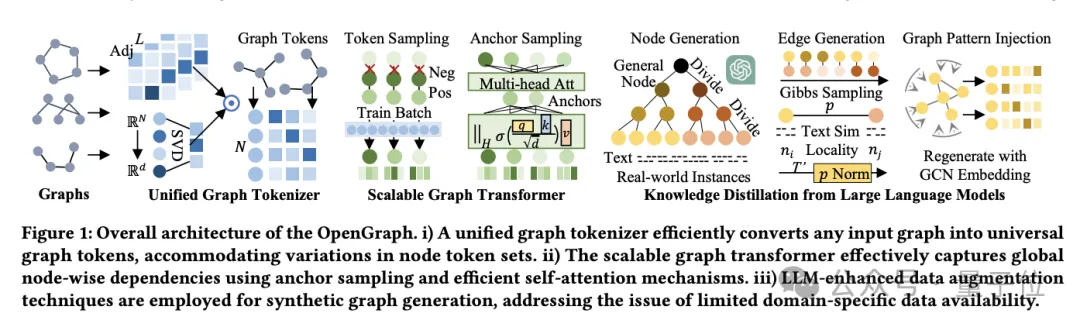
Model asas graf sumber terbuka besar HKU OpenGraph: keupayaan generalisasi yang kuat, penyebaran ke hadapan untuk meramalkan data baharu
Pengenalan Artikel:Terdapat cara baharu untuk mengurangkan masalah kebuluran data dalam bidang pembelajaran graf! OpenGraph, model berasaskan graf asas yang direka khusus untuk ramalan pukulan sifar pada pelbagai set data graf. Pasukan Chao Huang, ketua Makmal Perisikan Data di Universiti Hong Kong, turut mencadangkan teknik penambahbaikan dan pelarasan untuk model untuk meningkatkan kebolehsesuaian model kepada tugasan baharu. Pada masa ini, kerja ini telah disiarkan di GitHub. Memperkenalkan teknik penambahan data, kerja ini memfokuskan pada penerokaan strategi yang mendalam untuk meningkatkan keupayaan generalisasi model grafik (terutamanya apabila terdapat perbezaan ketara dalam data latihan dan ujian). OpenGraph ialah model struktur graf umum yang melakukan perambatan ke hadapan melalui ramalan perambatan untuk mencapai ramalan sampel sifar data baharu. Untuk mencapai matlamat mereka, pasukan
2024-05-09
komen 0
380


Dengan bantuan modul SectionReader Go, bagaimana untuk mengendalikan pembacaan dan penulisan data pangkalan data yang besar dengan cekap?
Pengenalan Artikel:Dengan bantuan modul SectionReader Go, bagaimana untuk mengendalikan pembacaan dan penulisan data pangkalan data yang besar dengan cekap? Pangkalan data adalah bahagian yang sangat diperlukan dalam aplikasi moden, dan membaca dan menulis data dalam pangkalan data yang besar adalah operasi yang sangat memakan masa. Untuk meningkatkan kecekapan, kami boleh menggunakan modul SectionReader bagi bahasa Go untuk mengendalikan operasi ini. SectionReader ialah sejenis dalam pustaka standard Go, yang melaksanakan io.ReaderAt, io.Writ
2023-07-21
komen 0
925
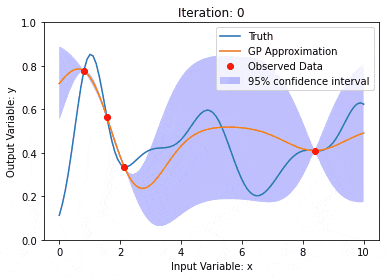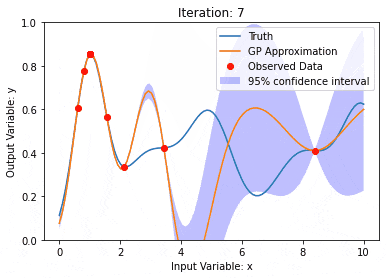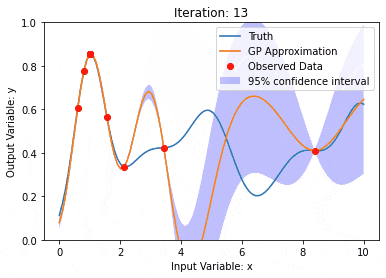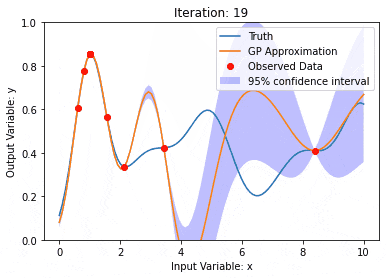
Pemodelan data menggunakan Kernel Model Gaussian Processes (KMGPs)
Pengenalan Artikel:Proses Gaussian Model Kernel (KMGPs) ialah alat canggih untuk mengendalikan kerumitan pelbagai set data. Ia memanjangkan konsep proses Gaussian tradisional melalui fungsi kernel. Artikel ini akan membincangkan secara terperinci asas teori, aplikasi praktikal dan cabaran KMGP. Model kernel Proses Gaussian ialah lanjutan daripada proses Gaussian tradisional dan digunakan dalam pembelajaran mesin dan statistik. Sebelum memahami kmgp, anda perlu menguasai pengetahuan asas proses Gaussian, dan kemudian memahami peranan model kernel. Proses Gaussian (GP) ialah satu set pembolehubah rawak, bilangan pembolehubah terhingga yang diedarkan bersama dengan taburan Gaussian, dan digunakan untuk menentukan taburan kebarangkalian fungsi. Proses Gaussian biasanya digunakan dalam regresi dan tugas klasifikasi dalam pembelajaran mesin dan boleh digunakan untuk menyesuaikan taburan kebarangkalian data. Ciri penting proses Gaussian ialah keupayaan mereka untuk memberikan anggaran dan ramalan ketidakpastian
2024-01-30
komen 0
1021

Tutorial Lanjutan Vue dan ECharts4Taro3: Cara Melaksanakan Visualisasi Data Jenis Carta Campuran
Pengenalan Artikel:Tutorial Lanjutan Vue dan ECharts4Taro3: Cara Melaksanakan Visualisasi Data Jenis Carta Campuran Pengenalan: Dalam analisis dan visualisasi data moden, paparan data jenis carta campuran telah menjadi keperluan biasa. Jenis carta hibrid biasa termasuk carta garisan, carta bar, carta pai dan banyak lagi. Artikel ini akan memperkenalkan cara menggunakan rangka kerja Vue dan perpustakaan ECharts4Taro3 untuk melaksanakan visualisasi data jenis carta bercampur. 1. Persekitaran pemasangan dan konfigurasi Pertama, kita perlu memasang Vue dan Taro dan mencipta yang baharu
2023-07-21
komen 0
1434

Mencari penyelesaian data AI berkualiti tinggi: Cabaran untuk perusahaan dalam era model besar
Pengenalan Artikel:Kedatangan era model besar mempercepatkan transformasi pembangunan kecerdasan buatan daripada berpusatkan model kepada berpusatkan data. "Laporan Panorama Industri Anotasi Data AIGC China" Qubit Think Tank menunjukkan bahawa pada masa ini penyelesaian data model besar sedang berkembang pesat di banyak tempat, memfokuskan pada perkhidmatan sehenti, tersuai, memfokuskan pada keseluruhan kitaran hayat pembangunan model besar (termasuk pra-latihan , penyeliaan dan penalaan halus, RLHF, ujian pasukan merah, ujian penanda aras, dsb.), penyedia perkhidmatan data profesional, syarikat model besar, syarikat AI dan pihak lain telah menghasilkan penyelesaian data yang berkaitan, yang kebanyakannya adalah sehenti, perkhidmatan yang disesuaikan. Menggunakan data pengukuran awan sebagai kajian kes untuk penyelesaian data model besar untuk industri menegak, penyelesaian itu boleh menyediakan data yang berkualiti tinggi dan cekap untuk proses hujung ke hujung model industri berskala besar, termasuk pra-latihan berterusan, mikro tugas. -pemprosesan, dsb.
2023-11-27
komen 0
995
Meningkatkan nilai data AI dan mempercepatkan pembangunan industri model besar
Pengenalan Artikel:Dengan perkembangan pesat industri kecerdasan buatan, kecerdasan buatan sedang dikomersialkan dalam semua arah. Teknologi AI telah dilaksanakan dalam banyak bidang seperti kewangan, penjagaan perubatan, pembuatan, pendidikan dan keselamatan Senario aplikasi menjadi semakin kaya, dan kepentingan data menjadi semakin menonjol. Sebagai pautan penting dalam rantaian industri kecerdasan buatan, kualiti dan kuantiti data memainkan peranan penting dalam meningkatkan ketepatan dan kebolehpercayaan model AI. Hari ini, kecerdasan buatan (AI) berkembang dengan lebih pesat dengan model besar sebagai terasnya, dan memasuki era baharu pada kelajuan penuh. Sebagai wakil perkhidmatan data kecerdasan buatan berasaskan senario berkualiti tinggi, Data Pengukuran Awan bergantung pada keupayaan teknikalnya yang terkemuka, kualiti perkhidmatan yang cemerlang dan pengalaman industri yang kaya untuk menyediakan perkhidmatan data AI yang profesional, cekap dan selamat untuk industri kecerdasan buatan.
2023-11-03
komen 0
853
Kekurangan data berkualiti tinggi untuk melatih model besar? Kami menemui penyelesaian baharu
Pengenalan Artikel:Data, sebagai salah satu daripada tiga faktor utama yang menentukan prestasi model pembelajaran mesin, menjadi halangan yang menyekat pembangunan model besar. Seperti kata pepatah "Sampah masuk, sampah keluar" [1], tidak kira betapa baiknya algoritma anda dan sehebat mana sumber pengkomputeran anda, kualiti model secara langsung bergantung pada data yang anda gunakan untuk melatih model. Dengan kemunculan pelbagai model besar sumber terbuka, kepentingan data telah menjadi lebih diketengahkan, terutamanya data industri berkualiti tinggi. Bloomberg membina model besar kewangan BloombergGPT berdasarkan rangka kerja GPT-3 sumber terbuka, membuktikan kebolehlaksanaan membangunkan model industri menegak yang besar berdasarkan rangka kerja model besar sumber terbuka. Malah, membina atau menyesuaikan model besar ringan sumber tertutup untuk industri menegak ialah perkara yang dilakukan oleh kebanyakan syarikat permulaan model besar di China.
2023-09-18
komen 0
846

Mengintegrasikan data berbilang omik, model rangkaian saraf graf pasukan BGI SpatialGlue telah diterbitkan dalam sub-jurnal Nature
Pengenalan Artikel:Editor: KX Spatial Transcriptomics dan Multi-omics Data Integration Transkriptomics spatial ialah perkembangan utama selepas transkriptomics sel tunggal, menjadikan penyepaduan data multi-omics penting. SpatialGlue: Model rangkaian saraf graf dengan mekanisme dua perhatian daripada Agensi Sains, Teknologi dan Penyelidikan Singapura (A*STAR), BGI dan Hospital Renji yang Bergabung dengan Sekolah Perubatan Universiti Jiao Tong Shanghai mencadangkan rangkaian saraf graf yang dipanggil SpatialGlue. . model, yang mengintegrasikan data berbilang omik melalui mekanisme perhatian dwi untuk mendedahkan struktur sampel tisu yang berkaitan secara histologi dengan cara yang sedar dari segi ruang. Kelebihan SpatialGlue SpatialGlue dapat menggabungkan pelbagai modaliti data dengan konteks spatial masing-masing. Berbanding dengan kaedah lain
2024-07-03
komen 0
579

Memperkukuh keupayaan bekalan data berkualiti tinggi dan menggalakkan inovasi dalam bidang model besar kecerdasan buatan am
Pengenalan Artikel:Dalam tahun-tahun kebelakangan ini, model pra-latihan berskala besar telah menjadi salah satu daya penggerak penting untuk penemuan dalam kecerdasan buatan, mempercepatkan proses pembangunan kejuruteraan kecerdasan buatan dan popularisasi, dan dijangka menjadi asas kepada teknologi pintar generasi baharu. . Kejayaan dalam model kecerdasan buatan besar berpunca daripada pembangunan berterusan data berkualiti tinggi Meningkatkan keupayaan bekalan data berkualiti tinggi adalah kunci untuk mempromosikan inovasi dalam bidang kecerdasan buatan umum model besar model berkaitan dengan parameter dan datanya Terdapat undang-undang pembangunan undang-undang kuasa antara jumlah pengiraan dan jumlah pengiraan, iaitu, "ScalingLaws". Parameter, data dan jumlah pengiraan model meningkat secara eksponen, manakala kehilangan model pada set ujian berkurangan secara eksponen, menunjukkan bahawa prestasi model adalah lebih baik, apabila jumlah pengiraan ditetapkan dan skala parameter adalah kecil
2023-08-08
komen 0
1414

Platform penyumberan ramai yang fleksibel memperkasakan industri model berskala besar dengan data berkualiti tinggi dan penjajaran manusia yang cekap
Pengenalan Artikel:Pada 23 Ogos, Dr. Wu Runze, pengarah teknikal Kumpulan Potret Pengguna NetEase Fuxi, telah dijemput untuk menyertai forum tema industri model besar dengan tema "Boiling Capital, AGI Riding the Waves". Di forum itu, beliau menyampaikan ucapan mengenai tema "Penjajaran Manusia yang Cekap untuk Aplikasi Pelaksanaan Model Besar". cara membina gelung tertutup data model besar pada kos rendah dan pengalaman berasaskan data berkualiti tinggi. Antara tiga elemen model besar—data, kuasa pengkomputeran dan algoritma—menguatkan skala model pra-latihan dan meningkatkan kualiti data adalah kaedah utama untuk mencapai kesan kecerdasan buatan yang lebih baik. Walau bagaimanapun, hanya meningkatkan saiz model tidak semestinya membawa kepada hasil yang lebih baik. Meningkatkan model di mana subjektiviti wujud dalam banyak tugas dunia sebenar
2024-01-22
komen 0
920

Penyelidikan terkini daripada Google MIT menunjukkan bahawa mendapatkan data berkualiti tinggi tidak sukar, dan model besar adalah penyelesaiannya
Pengenalan Artikel:Mendapatkan data berkualiti tinggi telah menjadi halangan utama dalam latihan model besar semasa. Beberapa hari lalu, OpenAI telah disaman oleh New York Times dan menuntut pampasan berbilion dolar. Aduan itu menyenaraikan pelbagai bukti plagiarisme oleh GPT-4. The New York Times malah menggesa pemusnahan hampir semua model besar seperti GPT. Banyak nama besar dalam industri AI telah lama percaya bahawa "data sintetik" mungkin merupakan penyelesaian terbaik untuk masalah ini. Sebelum ini, pasukan Google turut mencadangkan RLAIF, kaedah yang menggunakan LLM untuk menggantikan keutamaan pelabelan manusia, dan kesannya tidak kalah dengan manusia. Kini, penyelidik di Google dan MIT telah mendapati bahawa pembelajaran daripada model besar boleh membawa kepada perwakilan model terbaik yang dilatih menggunakan data sebenar. Kaedah terbaru ini dipanggil SynCLR, yang sepenuhnya diperoleh daripada imej sintetik dan rendering sintetik.
2024-01-14
komen 0
1296

Dengan bantuan modul SectionReader Go, bagaimana untuk mengendalikan pengisihan dan ringkasan fail data besar dengan cekap?
Pengenalan Artikel:Dengan bantuan modul SectionReader Go, bagaimana untuk mengendalikan pengisihan dan ringkasan fail data besar dengan cekap? Apabila memproses fail data yang besar, kita selalunya perlu mengisih dan meringkaskannya. Walau bagaimanapun, kaedah tradisional membaca keseluruhan fail sekali gus tidak sesuai untuk fail data besar kerana ia mungkin melebihi had memori. Nasib baik, modul SectionReader dalam bahasa Go menyediakan cara yang cekap untuk menangani masalah ini. SectionReader ialah pakej dalam bahasa Go,
2023-07-23
komen 0
1162

Apakah jenis imej yang disimpan oleh mysql?
Pengenalan Artikel:Mysql menyimpan imej dalam tiga jenis: BLOB, MEDIUMBLOB dan LONGBLOB. Pengenalan khusus: 1. Jenis BLOB boleh menyimpan data binari, sesuai untuk menyimpan beberapa gambar yang lebih kecil, seperti avatar, ikon, dll. 2. Jenis MEDIUMBLOB boleh menyimpan data binari bersaiz sederhana, sesuai untuk menyimpan beberapa gambar yang lebih besar; Jenis LONGBLOB Ia boleh menyimpan data binari yang lebih besar dan sesuai untuk menyimpan gambar besar atau gambar yang perlu disimpan dalam definisi tinggi.
2023-07-18
komen 0
10655