Jumlah kandungan berkaitan 10000

Linguistik dalam Kepintaran Buatan: Model Bahasa dalam Pemprosesan Bahasa Asli Python
Pengenalan Artikel:Pemprosesan bahasa semulajadi (NLP) ialah satu bidang sains komputer yang memfokuskan kepada membolehkan komputer berkomunikasi secara berkesan menggunakan bahasa semula jadi. Model bahasa memainkan peranan penting dalam NLP Mereka boleh mempelajari pengedaran kebarangkalian dalam bahasa untuk melaksanakan pelbagai tugas pemprosesan pada teks, seperti penjanaan teks, terjemahan mesin dan analisis sentimen. Jenis Model Bahasa Terdapat dua jenis model bahasa utama: n-gram model bahasa: menganggap n perkataan sebelumnya untuk meramalkan kebarangkalian perkataan seterusnya, n dipanggil susunan. Model Bahasa Neural: Gunakan rangkaian saraf untuk mempelajari hubungan yang kompleks dalam bahasa. Model bahasa dalam Python Terdapat banyak perpustakaan dalam Python yang boleh melaksanakan model bahasa, termasuk: nltk.lm: Menyediakan pelaksanaan model bahasa n-gram. ge
2024-03-21
komen 0
1196

Perbezaan antara model bahasa besar dan model pembenaman perkataan
Pengenalan Artikel:Model bahasa besar dan model pembenaman perkataan ialah dua konsep utama dalam pemprosesan bahasa semula jadi. Kedua-duanya boleh digunakan pada analisis dan penjanaan teks, tetapi prinsip dan senario aplikasi adalah berbeza. Model bahasa berskala besar terutamanya berdasarkan model statistik dan probabilistik dan sesuai untuk menjana teks berterusan dan pemahaman semantik. Model embedding perkataan boleh menangkap hubungan semantik antara perkataan dengan memetakan perkataan ke ruang vektor, dan sesuai untuk inferens makna perkataan dan klasifikasi teks. 1. Model benam perkataan Model benam perkataan ialah teknologi yang memproses maklumat teks dengan memetakan perkataan ke dalam ruang vektor berdimensi rendah. Ia menukar perkataan dalam bahasa kepada bentuk vektor supaya komputer dapat memahami dan memproses teks dengan lebih baik. Model pembenaman perkataan yang biasa digunakan termasuk Word2Vec dan GloVe. Model ini digunakan secara meluas dalam tugas pemprosesan bahasa semula jadi
2024-01-23
komen 0
1443

Sifat autoregresif model bahasa
Pengenalan Artikel:Model bahasa autoregresif ialah model pemprosesan bahasa semula jadi berdasarkan kebarangkalian statistik. Ia menjana urutan teks berterusan dengan memanfaatkan urutan perkataan sebelumnya untuk meramalkan taburan kebarangkalian perkataan seterusnya. Model ini sangat berguna dalam pemprosesan bahasa semula jadi dan digunakan secara meluas dalam penjanaan bahasa, terjemahan mesin, pengecaman pertuturan dan bidang lain. Dengan menganalisis data sejarah, model bahasa autoregresif dapat memahami undang-undang dan struktur bahasa untuk menghasilkan teks dengan koheren dan ketepatan semantik. Ia bukan sahaja boleh digunakan untuk menjana teks, tetapi juga untuk meramalkan perkataan seterusnya, memberikan maklumat berguna untuk tugas pemprosesan teks berikutnya. Oleh itu, model bahasa autoregresif adalah teknik yang penting dan praktikal dalam pemprosesan bahasa semula jadi. 1. Konsep model autoregresif Model autoregresif ialah model yang menggunakan pemerhatian terdahulu untuk
2024-01-22
komen 0
683

6 Model Bahasa Besar Terbaik pada 2023
Pengenalan Artikel:Musim ini, dan syarikat teknologi membuat model bahasa besar seperti roti dari kedai roti.Model baharu dikeluarkan secara cepat, dan ia menjadi terlalu sukar untuk menyimpan trek. Tetapi di tengah-tengah kesibukan keluaran baharu, hanya model yang selamat untuk digunakan.
2024-06-14
komen 0
905

Pengenalan kepada model matematik dalam bahasa Java
Pengenalan Artikel:Bahasa Java ialah bahasa pengaturcaraan peringkat tinggi yang sangat sesuai untuk pembinaan dan analisis model matematik. Model matematik ialah aplikasi konsep matematik dalam dunia sebenar Ia sering digunakan untuk menyelesaikan masalah praktikal, seperti meramalkan arah aliran masa depan, mengoptimumkan pengeluaran dan pembuatan, dsb. Artikel ini akan memperkenalkan model matematik biasa dan aplikasinya dalam bahasa Java. Pengaturcaraan linear Pengaturcaraan linear ialah kaedah pengoptimuman yang digunakan secara meluas dalam menyelesaikan masalah seperti pembuatan keputusan perusahaan yang optimum, peruntukan sumber dan perancangan pengeluaran. Dalam bahasa Java, anda boleh menggunakan Apache Commons
2023-06-10
komen 0
1468

Cara menyampaikan maksud kepada model bahasa menggunakan tatabahasa
Pengenalan Artikel:Tatabahasa sangat penting dalam pemprosesan bahasa semula jadi dan model bahasa, kerana ia membantu model memahami struktur dan hubungan antara komponen bahasa. Tatabahasa ialah satu set peraturan yang menerangkan struktur, susunan, dan hubungan perkataan dan frasa dalam sesuatu bahasa. Peraturan ini boleh dinyatakan dalam bentuk tatabahasa formal atau teks bahasa semula jadi. Peraturan ini kemudiannya boleh diubah menjadi bentuk yang boleh difahami komputer seperti tatabahasa bebas konteks (CFG) atau tatabahasa kebergantungan (DG). Peraturan tatabahasa formal ini menyediakan asas untuk pemprosesan bahasa komputer, membolehkan komputer memahami dan memproses bahasa manusia. Dengan menggunakan peraturan ini, kami boleh melakukan operasi seperti analisis sintaks, penjanaan pokok sintaks dan penghuraian semantik untuk mencapai tugas seperti pemprosesan bahasa semula jadi dan terjemahan mesin. Dalam pemprosesan bahasa semula jadi, tatabahasa
2024-01-22
komen 0
1072
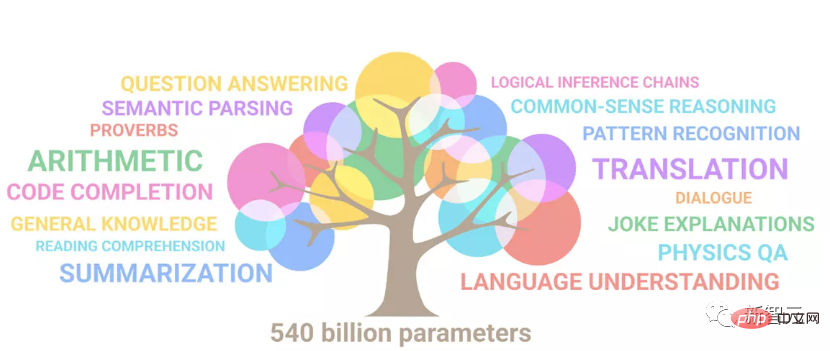
Melatih ViT terbesar dalam sejarah dengan mudah? Google meningkatkan model bahasa visual PaLI: menyokong 100+ bahasa
Pengenalan Artikel:Kemajuan pemprosesan bahasa semula jadi dalam beberapa tahun kebelakangan ini sebahagian besarnya datang daripada model bahasa berskala besar Setiap model baharu yang dikeluarkan mendorong jumlah parameter dan data latihan ke tahap tertinggi baharu, dan pada masa yang sama, kedudukan penanda aras yang sedia ada akan disembelih. Sebagai contoh, pada April tahun ini, Google mengeluarkan model bahasa 540 bilion parameter PaLM (Model Bahasa Laluan), yang berjaya mengatasi manusia dalam satu siri ujian bahasa dan penaakulan, terutamanya prestasi cemerlangnya dalam senario pembelajaran sampel kecil beberapa pukulan. PaLM dianggap sebagai hala tuju pembangunan model bahasa generasi akan datang. Dengan cara yang sama, model bahasa visual sebenarnya berfungsi dengan hebat, dan prestasi boleh dipertingkatkan dengan meningkatkan saiz model. Sudah tentu, jika ia hanya model bahasa visual pelbagai tugas
2023-04-12
komen 0
1323

Kaedah biasa: mengukur kebingungan model bahasa baharu
Pengenalan Artikel:Terdapat banyak cara untuk menilai model bahasa baharu, sesetengah daripadanya berdasarkan penilaian oleh pakar manusia, manakala yang lain berdasarkan penilaian automatik. Setiap kaedah ini mempunyai kelebihan dan kekurangan. Artikel ini akan menumpukan pada kaedah kebingungan berdasarkan penilaian automatik. Kekeliruan ialah metrik yang digunakan untuk menilai kualiti model bahasa. Ia mengukur kuasa ramalan model bahasa yang diberikan satu set data. Lebih kecil nilai kekeliruan, lebih baik keupayaan ramalan model. Metrik ini sering digunakan untuk menilai model pemprosesan bahasa semula jadi untuk mengukur keupayaan model untuk meramal perkataan seterusnya dalam teks tertentu. Kebingungan yang lebih rendah menunjukkan prestasi model yang lebih baik. Dalam pemprosesan bahasa semula jadi, tujuan model bahasa adalah untuk meramalkan kebarangkalian perkataan seterusnya dalam urutan. Diberikan rangkai kata
2024-01-22
komen 0
1154

Pemahaman mendalam tentang model coroutine dan concurrency bagi bahasa Go
Pengenalan Artikel:Memahami dengan mendalam model coroutine dan concurrency bahasa Go ialah bahasa pengaturcaraan yang telah meningkat pesat dalam beberapa tahun kebelakangan ini Model concurrency yang unik dan mekanisme coroutine telah menjadi salah satu sebab utama untuk popularitinya. Model konkurensi bahasa Go dan ciri coroutine menjadikan pengaturcaraan serentak lebih mudah dan lebih cekap. Artikel ini akan menyelidiki model coroutine dan concurrency bagi bahasa Go. Pertama, kita perlu memahami apa itu coroutine. Coroutine, juga dikenali sebagai benang ringan, ialah model pengaturcaraan serentak yang sangat fleksibel. Berbanding dengan benang tradisional, coroutine lebih mudah alih dan penciptaan serta pemusnahannya
2023-11-30
komen 0
1196

Kuasai model konkurensi dan mekanisme kunci dalam bahasa Go
Pengenalan Artikel:Kuasai model concurrency dan mekanisme kunci dalam bahasa Go Dengan perkembangan pesat Internet dan keperluan pengguna yang semakin meningkat, permintaan untuk bahasa pengaturcaraan berprestasi tinggi dan tinggi juga semakin tinggi. Sebagai bahasa pengaturcaraan sumber terbuka, bahasa Go telah menjadi bahasa pilihan pertama untuk membina program konkurensi tinggi dengan model konkurensi yang cekap dan mekanisme penguncian yang fleksibel. 1. Model Concurrency Bahasa Go menggunakan mekanisme benang ringan Goroutine untuk mencapai concurrency. Goroutine ialah benang yang sangat ringan, dikuasakan oleh masa jalan bahasa Go (runti
2023-11-30
komen 0
562

Kaedah dan pengenalan penyahgandingan model bahasa
Pengenalan Artikel:Model bahasa adalah salah satu tugas asas pemprosesan bahasa semula jadi, dan matlamat utamanya adalah untuk mempelajari taburan kebarangkalian bahasa. Ramalkan kebarangkalian perkataan seterusnya diberikan teks sebelumnya. Untuk melaksanakan model ini, rangkaian saraf seperti Rangkaian Neural Berulang (RNN) atau Transformer sering digunakan. Walau bagaimanapun, latihan dan aplikasi model bahasa sering dipengaruhi oleh isu gandingan. Gandingan merujuk kepada kebergantungan antara bahagian model, jadi pengubahsuaian pada satu bahagian mungkin mempunyai kesan pada bahagian lain. Fenomena gandingan ini merumitkan pengoptimuman dan penambahbaikan model, memerlukan interaksi antara pelbagai bahagian untuk ditangani sambil mengekalkan prestasi keseluruhan. Matlamat penyahgandingan adalah untuk mengurangkan kebergantungan, membolehkan bahagian model dilatih dan dioptimumkan secara bebas, dan meningkatkan prestasi dan kebolehskalaan.
2024-01-23
komen 0
684

Memperbaik kaedah anotasi data untuk model bahasa besar (LLM)
Pengenalan Artikel:Penalaan halus model bahasa berskala besar (LLM) melibatkan latihan semula model pra-latihan menggunakan data khusus domain untuk menyesuaikannya dengan tugas atau domain tertentu. Anotasi data memainkan peranan penting dalam proses penalaan halus dan melibatkan pelabelan data dengan maklumat khusus yang perlu difahami oleh model. 1. Prinsip anotasi data Anotasi data adalah untuk membantu model pembelajaran mesin memahami dan memproses data dengan lebih baik dengan menambahkan metadata, seperti teg, teg, dll., pada data. Untuk penalaan halus model bahasa besar, prinsip anotasi data adalah untuk menyediakan maklumat panduan untuk membantu model memahami bahasa dan konteks domain tertentu dengan lebih baik. Kaedah anotasi data biasa termasuk pengecaman entiti, analisis sentimen dan pengekstrakan perhubungan. 2. Kaedah anotasi data 2.1 Pengecaman entiti Pengiktirafan entiti ialah sejenis pengekstrakan maklumat
2024-01-22
komen 0
1112

Model bahasa besar LLM dan penjanaan peningkatan perolehan semula
Pengenalan Artikel:Model bahasa besar LLM biasanya dilatih menggunakan seni bina Transformer untuk meningkatkan keupayaan memahami dan menjana bahasa semula jadi melalui sejumlah besar data teks. Model ini digunakan secara meluas dalam chatbots, ringkasan teks, terjemahan mesin dan medan lain. Beberapa model bahasa besar LLM yang terkenal termasuk siri GPT OpenAI dan BERT Google. Dalam bidang pemprosesan bahasa semula jadi, penjanaan yang dipertingkatkan semula adalah teknik yang menggabungkan pengambilan dan penjanaan. Ia menjana teks yang memenuhi keperluan dengan mendapatkan semula maklumat yang berkaitan daripada korpora teks berskala besar dan menggunakan model generatif untuk menggabungkan semula dan menyusun maklumat ini. Teknik ini mempunyai pelbagai aplikasi, termasuk ringkasan teks, terjemahan mesin, penjanaan dialog dan tugasan lain. Peningkatan perolehan semula dengan memanfaatkan pengambilan semula dan penjanaan
2024-01-23
komen 0
1208

Metrik penilaian model bahasa yang besar
Pengenalan Artikel:Artikel ini mengkaji metrik yang paling banyak digunakan dan boleh dipercayai untuk menilai model bahasa besar (LLM). Artikel ini membincangkan kategori metrik yang berbeza, termasuk BLEU, ROUGE, METEOR dan NIST serta cara mereka mengukur prestasi L
2024-08-13
komen 0
1045

Senarai jenis fail bahasa Go
Pengenalan Artikel:Jenis fail bahasa Go dikenal pasti melalui akhiran Jenis biasa termasuk: .go: fail kod sumber.mod: fail perihalan modul_test.go: fail ujian.c: fail kod sumber bahasa C: fail kod sumber bahasa. Fail pengepala bahasa C
2024-04-08
komen 0
539

Aplikasi strategi penyahkodan dalam model bahasa besar
Pengenalan Artikel:Model bahasa berskala besar ialah teknologi utama dalam bidang pemprosesan bahasa semula jadi, menunjukkan prestasi yang kukuh dalam pelbagai tugas. Strategi penyahkodan adalah salah satu aspek penting penjanaan teks oleh model. Artikel ini akan memperincikan strategi penyahkodan dalam model bahasa besar dan membincangkan kelebihan dan kekurangannya. 1. Gambaran keseluruhan strategi penyahkodan Dalam model bahasa besar, strategi penyahkodan ialah kaedah untuk menjana jujukan teks. Strategi penyahkodan biasa termasuk carian tamak, carian rasuk dan carian rawak. Carian tamak ialah kaedah mudah dan mudah yang memilih perkataan dengan kebarangkalian tertinggi sebagai perkataan seterusnya setiap kali, tetapi mungkin mengabaikan kemungkinan lain. Carian rasuk menambah had lebar kepada carian tamak, mengekalkan hanya perkataan calon dengan kebarangkalian tertinggi, dengan itu meningkatkan kepelbagaian. Carian rawak memilih perkataan seterusnya secara rawak, yang boleh menghasilkan lebih pelbagai
2024-01-22
komen 0
1191

Adakah generik dalam bahasa Go benar-benar generik?
Pengenalan Artikel:Tidak, walaupun bahasa Go menyediakan mekanisme yang serupa dengan generik, ia tidak boleh dianggap sebagai generik sebenar. Bahasa Go menyediakan mekanisme yang dipanggil "antara muka" yang boleh digunakan untuk mensimulasikan kefungsian generik. Walaupun pendekatan ini boleh mensimulasikan kefungsian generik, ia tidak sefleksibel seperti generik dalam bahasa pengaturcaraan lain. Dalam bahasa Go, antara muka hanya boleh menentukan kaedah, bukan pembolehubah atau sifat, yang bermaksud bahawa struktur data generik tidak boleh ditakrifkan dalam antara muka seperti dalam bahasa pengaturcaraan lain.
2023-08-23
komen 0
856

Memindahkan aplikasi pembelajaran dan teknologi biasa dalam latihan model bahasa besar
Pengenalan Artikel:Model bahasa besar merujuk kepada model pemprosesan bahasa semula jadi dengan lebih daripada 100 juta parameter. Oleh kerana saiz dan kerumitannya yang besar, latihan model sedemikian memerlukan sumber dan data pengkomputeran yang ketara. Oleh itu, pembelajaran pemindahan telah menjadi kaedah penting untuk melatih model bahasa besar Dengan menggunakan model dan data sedia ada, proses latihan dapat dipercepatkan dan prestasi dapat ditingkatkan. Memindahkan pembelajaran boleh memindahkan parameter dan pengetahuan model yang dilatih pada tugas lain kepada tugas sasaran, dengan itu mengurangkan keperluan data dan masa latihan. Pendekatan ini digunakan secara meluas dalam kedua-dua penyelidikan dan industri, meletakkan asas untuk membina model bahasa yang lebih berkuasa. Memindahkan pembelajaran ialah kaedah yang menggunakan model yang sudah terlatih untuk melaraskan parameternya atau beberapa komponen semasa menyelesaikan tugasan lain. Dalam bidang pemprosesan bahasa semula jadi, pembelajaran pemindahan boleh
2024-01-22
komen 0
880

Pemikiran terbalik: Model bahasa penaakulan matematik baharu MetaMath melatih model besar
Pengenalan Artikel:Penaakulan matematik yang kompleks ialah penunjuk penting untuk menilai keupayaan penaakulan model bahasa yang besar Pada masa ini, set data penaakulan matematik yang biasa digunakan mempunyai saiz sampel yang terhad dan kepelbagaian masalah yang tidak mencukupi, mengakibatkan fenomena "kutukan pembalikan" dalam model bahasa besar, yang. ialah, seseorang yang dilatih tentang "A ialah B" "Model bahasa tidak boleh digeneralisasikan kepada "B ialah A" [1]. Bentuk khusus fenomena ini dalam tugasan penaakulan matematik ialah: memandangkan masalah matematik, model bahasa pandai menggunakan penaakulan hadapan untuk menyelesaikan masalah tetapi tidak mempunyai keupayaan untuk menyelesaikan masalah dengan penaakulan songsang. Penaakulan songsang adalah sangat biasa dalam masalah matematik, seperti yang ditunjukkan dalam dua contoh berikut. 1. Soalan klasik - Penaakulan hadapan ayam dan arnab dalam sangkar yang sama: Terdapat 23 ekor ayam dan 12 ekor arnab di dalam sangkar tersebut. Alasan terbalik: Terdapat beberapa ekor ayam dan arnab dalam sangkar yang sama
2023-10-11
komen 0
951

Lebih banyak perkataan dalam dokumen, lebih teruja model itu! KOSMOS-2.5: Model bahasa besar berbilang modal untuk membaca 'imej padat teks'
Pengenalan Artikel:Trend yang jelas pada masa ini adalah ke arah membina model yang lebih besar dan lebih kompleks dengan puluhan/ratusan bilion parameter yang mampu menghasilkan output bahasa yang mengagumkan Walau bagaimanapun, model bahasa berskala besar sedia ada tertumpu terutamanya pada maklumat teks, tidak dapat memahami maklumat visual. Kemajuan dalam bidang model bahasa besar berbilang mod (MLLM) bertujuan untuk menangani had ini MLLM menggabungkan maklumat visual dan teks ke dalam satu model berasaskan Transformer, membolehkan model mempelajari dan menjana kandungan berdasarkan kedua-dua modaliti. MLLM menunjukkan potensi dalam pelbagai aplikasi praktikal, termasuk pemahaman imej semula jadi dan pemahaman imej teks. Model ini memanfaatkan pemodelan bahasa sebagai antara muka biasa untuk mengendalikan masalah multimodal, membolehkan mereka membuat model
2023-09-29
komen 0
661
