Jumlah kandungan berkaitan 10000

Kaedah pembelajaran pengukuhan untuk komunikasi komponen Vue
Pengenalan Artikel:Kaedah pembelajaran pengukuhan untuk komunikasi komponen Vue Dalam pembangunan Vue, komunikasi komponen adalah topik yang sangat penting. Ia melibatkan cara berkongsi data antara berbilang komponen, peristiwa pencetus, dsb. Pendekatan biasa ialah menggunakan kaedah props dan $emit untuk komunikasi antara komponen ibu bapa dan anak. Walau bagaimanapun, kaedah komunikasi mudah ini boleh menjadi rumit dan sukar untuk dikekalkan apabila aplikasi berkembang dalam saiz dan hubungan antara komponen menjadi kompleks. Pembelajaran pengukuhan ialah algoritma yang menggunakan percubaan dan ralat dan mekanisme ganjaran untuk mengoptimumkan penyelesaian masalah. Dalam komunikasi komponen, I
2023-07-17
komen 0
1293

Bagaimana untuk membina algoritma pembelajaran pengukuhan menggunakan PHP
Pengenalan Artikel:Cara membina algoritma pembelajaran pengukuhan menggunakan PHP Pengenalan: Pembelajaran pengukuhan ialah kaedah pembelajaran mesin yang mempelajari cara membuat keputusan yang optimum dengan berinteraksi dengan persekitaran. Dalam artikel ini, kami akan memperkenalkan cara membina algoritma pembelajaran pengukuhan menggunakan bahasa pengaturcaraan PHP dan menyediakan contoh kod untuk membantu pembaca memahami dengan lebih baik. 1. Apakah algoritma pembelajaran pengukuhan? Algoritma pembelajaran pengukuhan ialah kaedah pembelajaran mesin yang mempelajari cara membuat keputusan dengan memerhati maklum balas daripada persekitaran. Tidak seperti algoritma pembelajaran mesin lain, algoritma pembelajaran pengukuhan bukan hanya berdasarkan data sedia ada
2023-07-31
komen 0
712

Belajar memasang papan litar dalam masa 20 minit! Rangka kerja SERL sumber terbuka mempunyai kadar kejayaan kawalan ketepatan 100% dan tiga kali lebih pantas daripada manusia
Pengenalan Artikel:Kini, robot boleh mempelajari tugas kawalan kilang ketepatan. Dalam tahun-tahun kebelakangan ini, kemajuan ketara telah dicapai dalam bidang teknologi pembelajaran pengukuhan robot, seperti berjalan berkaki empat, menggenggam, manipulasi ketangkasan, dan lain-lain, tetapi kebanyakannya terhad kepada peringkat demonstrasi makmal. Menggunakan teknologi pembelajaran pengukuhan robot secara meluas kepada persekitaran pengeluaran sebenar masih menghadapi banyak cabaran, yang pada tahap tertentu mengehadkan skop aplikasinya dalam senario sebenar. Dalam proses aplikasi praktikal teknologi pembelajaran pengukuhan, adalah perlu untuk mengatasi pelbagai masalah kompleks termasuk penetapan mekanisme ganjaran, penetapan semula persekitaran, peningkatan kecekapan sampel, dan jaminan keselamatan tindakan. Pakar industri menekankan bahawa menyelesaikan banyak masalah dalam pelaksanaan sebenar teknologi pembelajaran tetulang adalah sama pentingnya dengan inovasi berterusan algoritma itu sendiri. Menghadapi cabaran ini, penyelidik dari Universiti California, Berkeley, Universiti Stanford, Universiti Washington, dan
2024-02-21
komen 0
1206

Kelajuan latihan meningkat sebanyak 17%. Rangka kerja penyelidikan pembelajaran tetulang sumber terbuka paradigma keempat menyokong latihan tunggal dan berbilang ejen.
Pengenalan Artikel:OpenRL ialah rangka kerja penyelidikan pembelajaran pengukuhan berasaskan PyTorch yang dibangunkan oleh pasukan pembelajaran pengukuhan Paradigma Keempat Ia menyokong latihan ejen tunggal, berbilang ejen, bahasa semula jadi dan tugas lain. OpenRL dibangunkan berdasarkan PyTorch, dengan matlamat untuk menyediakan komuniti penyelidikan pembelajaran pengukuhan dengan platform yang mudah digunakan, fleksibel, cekap dan boleh skala yang mampan. Pada masa ini, ciri yang disokong oleh OpenRL termasuk: antara muka biasa yang mudah digunakan dan menyokong latihan ejen tunggal dan berbilang ejen menyokong latihan pembelajaran pengukuhan untuk tugasan bahasa semula jadi (seperti tugasan dialog yang menyokong pengimportan model dan data daripada HuggingFace); ; menyokong LSTM, GRU, Model seperti Transformer menyokong pelbagai pecutan latihan, seperti: latihan ketepatan campuran automatik,
2023-05-11
komen 0
1078

Pakar teknikal AI Xishanju Huang Hongbo: Penyepaduan praktikal pembelajaran pengukuhan dan pokok tingkah laku dalam permainan
Pengenalan Artikel:Dari 6 hingga 7 Ogos 2022, Persidangan Teknologi Kepintaran Buatan Global AISummit akan diadakan seperti yang dijadualkan. Di sub-forum "Penjelajahan Sempadan Kecerdasan Buatan" yang diadakan pada petang ke-7, pakar teknikal Xishanju AI, Huang Hongbo membawakan perkongsian tema "Kombinasi Praktikal Pembelajaran Pengukuhan dan Pokok Tingkah Laku dalam Permainan", berkongsi secara terperinci kesan peneguhan. pembelajaran dalam bidang permainan. Huang Hongbo berkata bahawa pelaksanaan teknologi pembelajaran tetulang tidak terletak pada mengubah algoritma menjadi lebih berkuasa, tetapi dalam menggabungkan teknologi pembelajaran tetulang dengan pembelajaran mendalam dan perancangan permainan untuk membentuk satu set penyelesaian yang lengkap dan melaksanakannya. Pembelajaran peneguhan menjadikan permainan lebih pintar Pelaksanaan pembelajaran pengukuhan dalam permainan dapat menjadikan permainan lebih pintar dan lebih mudah dimainkan.
2023-04-09
komen 0
1834

Pembelajaran Mesin: 19 Projek Pembelajaran Pengukuhan (RL) Teratas di Github
Pengenalan Artikel:Pembelajaran pengukuhan (RL) ialah kaedah pembelajaran mesin di mana ejen belajar melalui percubaan dan kesilapan. Algoritma pembelajaran pengukuhan digunakan dalam banyak bidang, seperti permainan, robotik dan kewangan. Matlamat RL adalah untuk menemui strategi yang memaksimumkan jangkaan pulangan jangka panjang. Algoritma pembelajaran pengukuhan secara amnya dibahagikan kepada dua kategori: berasaskan model dan tanpa model. Algoritma berasaskan model menggunakan model persekitaran untuk merancang laluan tindakan yang optimum. Pendekatan ini bergantung pada pemodelan persekitaran yang tepat dan kemudian menggunakan model untuk meramalkan hasil tindakan yang berbeza. Sebaliknya, algoritma bebas model belajar secara langsung daripada interaksi dengan persekitaran tanpa memodelkan persekitaran secara eksplisit. Kaedah ini lebih sesuai untuk situasi di mana model persekitaran sukar diperoleh atau tidak tepat. Sebaliknya, dalam amalan, algoritma pembelajaran tetulang bebas model tidak
2024-03-19
komen 0
939
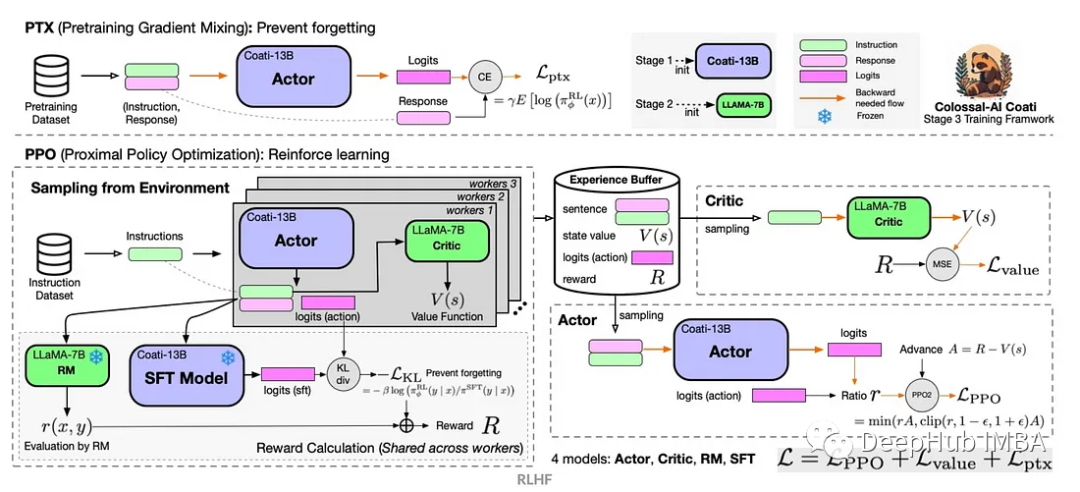
Pembelajaran pengukuhan Q-pembelajaran mendalam menggunakan simulasi lengan robot Panda-Gym
Pengenalan Artikel:Pembelajaran pengukuhan (RL) ialah kaedah pembelajaran mesin yang membolehkan ejen mempelajari cara berkelakuan dalam persekitarannya melalui percubaan dan kesilapan. Ejen diberi ganjaran atau dihukum kerana mengambil tindakan yang membawa kepada hasil yang diingini. Dari masa ke masa, ejen belajar untuk mengambil tindakan yang memaksimumkan ganjaran yang dijangkakan. Ejen RL biasanya dilatih menggunakan proses keputusan Markov (MDP), rangka kerja matematik untuk memodelkan masalah keputusan berjujukan. MDP terdiri daripada empat bahagian: Nyatakan: satu set kemungkinan keadaan persekitaran. Tindakan: Satu set tindakan yang boleh diambil oleh ejen. Fungsi peralihan: Fungsi yang meramalkan kebarangkalian peralihan kepada keadaan baharu memandangkan keadaan dan tindakan semasa. Fungsi ganjaran: Fungsi yang memberikan ganjaran kepada ejen untuk setiap penukaran. Matlamat ejen adalah untuk mempelajari fungsi polisi,
2023-10-31
komen 0
667

Kaedah untuk mengoptimumkan AB menggunakan pembelajaran peneguhan kecerunan dasar
Pengenalan Artikel:Ujian AB ialah teknik yang digunakan secara meluas dalam eksperimen dalam talian. Tujuan utamanya adalah untuk membandingkan dua atau lebih versi halaman atau aplikasi untuk menentukan versi yang mencapai matlamat perniagaan yang lebih baik. Matlamat ini boleh berupa kadar klikan, kadar penukaran, dsb. Sebaliknya, pembelajaran pengukuhan ialah kaedah pembelajaran mesin yang menggunakan pembelajaran percubaan dan kesilapan untuk mengoptimumkan strategi membuat keputusan. Pembelajaran peneguhan kecerunan dasar ialah kaedah pembelajaran pengukuhan khas yang bertujuan untuk memaksimumkan ganjaran terkumpul dengan mempelajari dasar yang optimum. Kedua-duanya mempunyai aplikasi yang berbeza dalam mengoptimumkan matlamat perniagaan. Dalam ujian AB, kami menganggap versi halaman yang berbeza sebagai tindakan yang berbeza dan matlamat perniagaan boleh dianggap sebagai penunjuk penting isyarat ganjaran. Untuk mencapai matlamat perniagaan yang maksimum, kita perlu merangka strategi yang boleh dipilih
2024-01-24
komen 0
1001
Daripada Transformer to Diffusion Model, pelajari tentang kaedah pembelajaran pengukuhan berdasarkan pemodelan jujukan dalam satu artikel
Pengenalan Artikel:Model generatif berskala besar telah membawa penemuan besar kepada pemprosesan bahasa semula jadi dan juga penglihatan komputer dalam dua tahun yang lalu. Baru-baru ini, trend ini turut menjejaskan pembelajaran pengukuhan, terutamanya pembelajaran peneguhan luar talian (RL luar talian), seperti Decision Transformer (DT)[1], Trajectory Transformer (TT)[2], Gato[3], Diffuser[4], dsb. Kaedah ini menganggap data pembelajaran pengukuhan (termasuk status, tindakan, ganjaran dan kembali untuk pergi) sebagai rentetan data jujukan yang dimusnahkan, dan memodelkan data jujukan ini sebagai tugas teras pembelajaran. Model ini semua boleh menggunakan kaedah pembelajaran yang diselia atau diselia sendiri
2023-04-14
komen 0
973

Memanjat, melompat, dan melintasi celah sempit, strategi pembelajaran pengukuhan sumber terbuka membolehkan anjing robot untuk parkour
Pengenalan Artikel:Parkour ialah sukan lasak Ia merupakan satu cabaran besar bagi robot, terutamanya anjing robot berkaki empat, yang perlu cepat mengatasi pelbagai halangan dalam persekitaran yang kompleks. Sesetengah kajian telah cuba menggunakan data haiwan rujukan atau ganjaran yang kompleks, tetapi pendekatan ini menjana kemahiran parkour yang sama ada pelbagai tetapi buta, atau berasaskan penglihatan tetapi khusus adegan. Walau bagaimanapun, parkour autonomi memerlukan robot untuk mempelajari kemahiran am berasaskan penglihatan dan pelbagai untuk melihat pelbagai senario dan bertindak balas dengan cepat. Baru-baru ini, video parkour anjing robot menjadi viral Anjing robot dalam video itu dengan pantas mengatasi pelbagai halangan dalam pelbagai senario. Sebagai contoh, melalui celah di bawah plat besi, memanjat kotak kayu, dan kemudian melompat ke kotak kayu lain, satu siri tindakan adalah lancar dan lancar: siri tindakan ini menunjukkan bahawa anjing robot itu telah menguasai merangkak, memanjat dan merangkak di atas tanah.
2023-09-20
komen 0
1099

Panduan untuk Mengintegrasikan Teknologi Kepintaran Buatan ke dalam Pengaturcaraan Grafik C++
Pengenalan Artikel:Dengan menyepadukan teknologi kecerdasan buatan ke dalam pengaturcaraan grafik C++, pembangun boleh mencipta aplikasi yang lebih pintar dan interaktif. Ini termasuk klasifikasi imej, pengesanan objek, penjanaan imej, AI permainan, perancangan laluan, penjanaan pemandangan dan fungsi lain. Teknologi kecerdasan buatan, seperti rangkaian saraf, pembelajaran pengukuhan, dan rangkaian musuh generatif, boleh disepadukan dengan C++ melalui rangka kerja seperti TensorFlow, OpenAIGym dan PyTorch untuk merealisasikan fungsi ini.
2024-06-02
komen 0
358

Apakah algoritma pembelajaran pengukuhan dalam Python?
Pengenalan Artikel:Dengan perkembangan teknologi kecerdasan buatan, pembelajaran pengukuhan, sebagai teknologi kecerdasan buatan yang penting, telah digunakan secara meluas dalam banyak bidang, seperti sistem kawalan, permainan, dll. Sebagai bahasa pengaturcaraan yang popular, Python juga menyediakan pelaksanaan banyak algoritma pembelajaran pengukuhan. Artikel ini akan memperkenalkan algoritma pembelajaran tetulang yang biasa digunakan dan ciri-cirinya dalam Python. Q-learningQ-learning ialah algoritma pembelajaran pengukuhan berdasarkan fungsi nilai Ia membimbing strategi tingkah laku dengan mempelajari fungsi nilai, membolehkan ejen memilih dalam persekitaran.
2023-06-04
komen 0
1414

GPU tunggal merealisasikan pembuatan keputusan dalam talian 20Hz, tafsiran kaedah perancangan trajektori yang cekap terkini berdasarkan model penjanaan jujukan
Pengenalan Artikel:Sebelum ini kami telah memperkenalkan aplikasi kaedah pemodelan jujukan berdasarkan Model Transformer dan Diffusion dalam pembelajaran pengukuhan khususnya dalam bidang kawalan berterusan luar talian. Antaranya, Trajectory Transformer (TT) dan Diffusser ialah algoritma perancangan berasaskan model Mereka menunjukkan ramalan trajektori berketepatan tinggi dan fleksibiliti yang baik, tetapi kelewatan membuat keputusan agak tinggi. Khususnya, TT mendiskrisikan setiap dimensi secara bebas sebagai simbol dalam jujukan, yang menjadikan keseluruhan jujukan sangat panjang, dan penggunaan masa penjanaan jujukan meningkat dengan cepat dengan dimensi keadaan dan tindakan.
2023-04-13
komen 0
1657

Dihasilkan bersama oleh Qingbei! Tinjauan untuk memahami selok-belok 'Transformer+Reinforcement Learning'
Pengenalan Artikel:Sejak dikeluarkan, model Transformer telah menjadi seni bina saraf arus perdana dalam tetapan pembelajaran yang diselia dalam bidang pemprosesan bahasa semula jadi dan penglihatan komputer. Walaupun kegilaan Transformer telah mula melanda seluruh bidang pembelajaran pengukuhan, kerana ciri-ciri RL itu sendiri, seperti keperluan untuk ciri-ciri unik, reka bentuk seni bina dan lain-lain, kombinasi semasa Transformer dan pembelajaran pengukuhan tidak lancar, dan laluan pembangunannya tidak mempunyai kertas yang relevan untuk menjalankan analisis menyeluruh. Baru-baru ini, penyelidik dari Universiti Tsinghua, Universiti Peking, dan Tencent bersama-sama menerbitkan kertas penyelidikan mengenai gabungan Transformer dan pembelajaran pengukuhan, mengkaji secara sistematik motivasi dan proses pembangunan menggunakan Transformer dalam pembelajaran pengukuhan. kertas
2023-04-13
komen 0
1123

Politeknik Nanyang mengeluarkan induk perdagangan kuantitatif TradeMaster, meliputi 15 algoritma pembelajaran pengukuhan
Pengenalan Artikel:Baru-baru ini, keluarga platform kuantitatif telah mengalu-alukan ahli baharu, platform sumber terbuka berdasarkan pembelajaran pengukuhan: TradeMaster—Master Dagangan. Dibangunkan oleh Universiti Teknologi Nanyang, TradeMaster ialah platform dagangan kuantitatif yang bersatu, hujung ke hujung, mesra pengguna meliputi empat pasaran kewangan utama, enam senario perdagangan utama, 15 algoritma pembelajaran pengukuhan dan satu siri alat penilaian visual! Alamat platform: https://github.com/TradeMaster-NTU/TradeMaster Latar Belakang Pengenalan Dalam beberapa tahun kebelakangan ini, teknologi kecerdasan buatan menduduki kedudukan yang semakin penting dalam strategi dagangan kuantitatif. Disebabkan keupayaan membuat keputusan yang cemerlang dalam persekitaran yang kompleks, teknologi pembelajaran pengukuhan digunakan
2023-04-11
komen 0
1082
Rasa ingin tahu AI bukan sahaja membunuh kucing! Algoritma pembelajaran pengukuhan baharu MIT, kali ini ejennya 'sukar dan mudah untuk mengambil semua'
Pengenalan Artikel:Semua orang pernah menghadapi masalah lama. Anda cuba memilih restoran untuk dimakan pada malam Jumaat tetapi tidak mempunyai tempahan. Sekiranya anda beratur di restoran kegemaran anda yang penuh sesak dengan orang ramai, atau mencuba restoran baharu dengan harapan untuk menemui beberapa kejutan yang lebih enak? Yang terakhir ini memang berpotensi untuk membawa kepada kejutan, tetapi tingkah laku yang didorong rasa ingin tahu ini datang dengan risiko: makanan di restoran baharu yang anda cuba mungkin lebih sedap. Rasa ingin tahu ialah daya penggerak AI untuk meneroka dunia, dan terdapat banyak contoh - navigasi autonomi, robot membuat keputusan, hasil pengesanan yang dioptimumkan, dsb. Dalam sesetengah kes, mesin menggunakan "pembelajaran pengukuhan" untuk mencapai matlamat, di mana ejen AI berulang kali belajar daripada diberi ganjaran untuk kelakuan yang baik dan dihukum kerana kelakuan buruk. Sama seperti ketika manusia memilih restoran
2023-04-13
komen 0
998

Kotak hitam AlphaZero dibuka! Kertas DeepMind diterbitkan dalam PNAS
Pengenalan Artikel:Catur sentiasa menjadi medan pembuktian untuk AI. 70 tahun yang lalu, Alan Turing membuat hipotesis bahawa adalah mungkin untuk membina mesin permainan catur yang boleh belajar sendiri dan terus meningkat daripada pengalamannya sendiri. "Deep Blue" yang muncul pada abad yang lalu mengalahkan manusia buat kali pertama, tetapi ia bergantung pada pakar untuk mengekod pengetahuan catur manusia, yang dilahirkan pada 2017, merealisasikan sangkaan Turing sebagai mesin pembelajaran tetulang yang didorong oleh rangkaian saraf. AlphaZero tidak perlu menggunakan sebarang heuristik rekaan tangan atau menonton manusia bermain catur, tetapi dilatih sepenuhnya dengan bermain menentang dirinya sendiri. Jadi, adakah ia benar-benar mempelajari konsep manusia tentang catur? Ini ialah masalah kebolehtafsiran rangkaian saraf. Dalam hal ini, AlphaZero's
2023-04-12
komen 0
1397
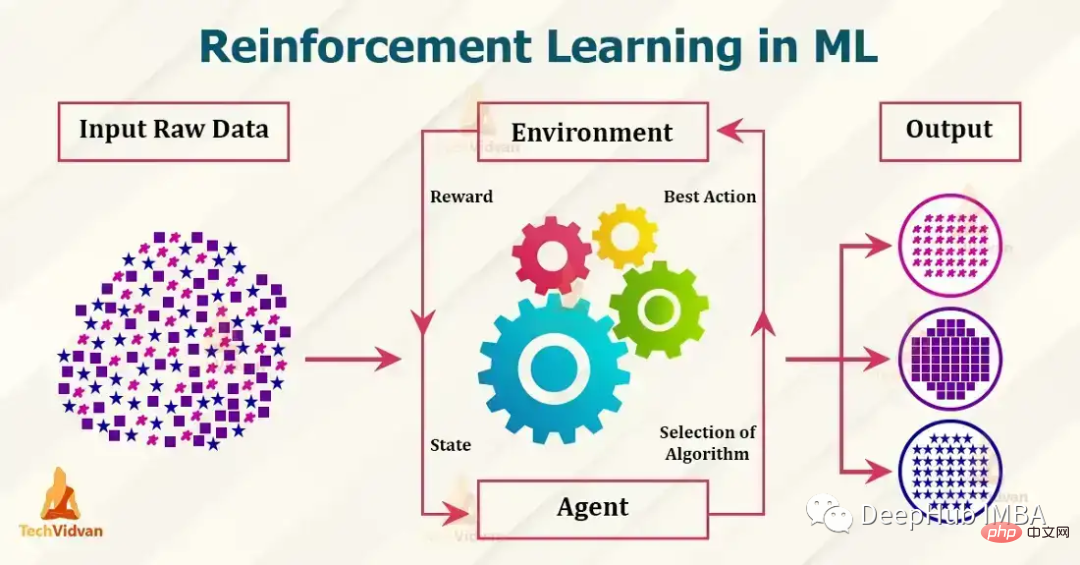
Tujuh algoritma pembelajaran tetulang popular dan pelaksanaan kod
Pengenalan Artikel:Algoritma pembelajaran tetulang yang popular pada masa ini termasuk Q-learning, SARSA, DDPG, A2C, PPO, DQN dan TRPO. Algoritma ini telah digunakan dalam pelbagai aplikasi seperti permainan, robotik dan membuat keputusan, dan algoritma popular ini sentiasa dibangunkan dan ditambah baik Dalam artikel ini, kami akan memberikan pengenalan ringkas kepada mereka. 1. Q-learningQ-learning: Q-learning ialah algoritma pembelajaran pengukuhan bukan strategi tanpa model. Ia menganggarkan fungsi nilai tindakan optimum menggunakan persamaan Bellman, yang secara berulang mengemas kini nilai anggaran untuk pasangan keadaan-tindakan tertentu. Q-pembelajaran terkenal dengan kesederhanaan dan keupayaannya untuk mengendalikan ruang keadaan berterusan yang besar.
2023-04-11
komen 0
1641

Daripada tikus berjalan dalam mez kepada AlphaGo mengalahkan manusia, pembangunan pembelajaran pengukuhan
Pengenalan Artikel:Apabila bercakap tentang pembelajaran pengukuhan, banyak adrenalin penyelidik melonjak secara tidak terkawal! Ia memainkan peranan yang sangat penting dalam sistem AI permainan, robot moden, sistem reka bentuk cip dan aplikasi lain. Terdapat pelbagai jenis algoritma pembelajaran pengukuhan, tetapi ia terbahagi kepada dua kategori: "berasaskan model" dan "bebas model". Dalam perbualan dengan TechTalks, ahli sains saraf dan pengarang "The Birth of Intelligence" Daeyeol Lee membincangkan model pembelajaran pengukuhan yang berbeza dalam manusia dan haiwan, kecerdasan buatan dan kecerdasan semula jadi serta hala tuju penyelidikan masa depan. Pembelajaran peneguhan tanpa model Pada akhir abad ke-19, "Undang-undang Kesan" yang dicadangkan oleh ahli psikologi Edward Thorndike menjadi asas pembelajaran peneguhan tanpa model. Th
2023-05-09
komen 0
879
