Jumlah kandungan berkaitan 10000

Bagaimanakah cara menggunakan bahasa Go untuk menjalankan penyelidikan pembelajaran peneguhan mendalam?
Pengenalan Artikel:Pembelajaran Peneguhan Dalam (DeepReinforcementLearning) ialah teknologi canggih yang menggabungkan pembelajaran mendalam dan pembelajaran peneguhan Ia digunakan secara meluas dalam pengecaman pertuturan, pengecaman imej, pemprosesan bahasa semula jadi dan bidang lain. Sebagai bahasa pengaturcaraan yang pantas, cekap dan boleh dipercayai, bahasa Go boleh memberikan bantuan untuk penyelidikan pembelajaran pengukuhan yang mendalam. Artikel ini akan memperkenalkan cara menggunakan bahasa Go untuk menjalankan penyelidikan pembelajaran peneguhan mendalam. 1. Pasang bahasa Go dan perpustakaan berkaitan dan mula menggunakan bahasa Go untuk pembelajaran pengukuhan yang mendalam.
2023-06-10
komen 0
1220
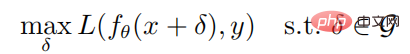
Serangan dan pertahanan musuh dalam pembelajaran peneguhan mendalam
Pengenalan Artikel:01 Pengenalan Kertas kerja ini adalah mengenai kerja pembelajaran peneguhan mendalam terhadap serangan. Dalam makalah ini, penulis mengkaji keteguhan strategi pembelajaran peneguhan mendalam kepada serangan musuh dari perspektif pengoptimuman yang mantap. Di bawah rangka kerja pengoptimuman yang teguh, serangan musuh yang optimum diberikan dengan meminimumkan pulangan jangkaan strategi, dan sewajarnya, mekanisme pertahanan yang baik dicapai dengan meningkatkan prestasi strategi dalam menghadapi senario kes terburuk. Memandangkan penyerang biasanya tidak dapat menyerang dalam persekitaran latihan, penulis mencadangkan algoritma serangan tamak yang cuba meminimumkan pulangan jangkaan strategi tanpa berinteraksi dengan persekitaran di samping itu, penulis juga mencadangkan algoritma pertahanan yang latihan Adversarial; algoritma pembelajaran pengukuhan mendalam menggunakan permainan max-min. Keputusan eksperimen dalam persekitaran permainan Atari menunjukkan bahawa
2023-04-08
komen 0
1326
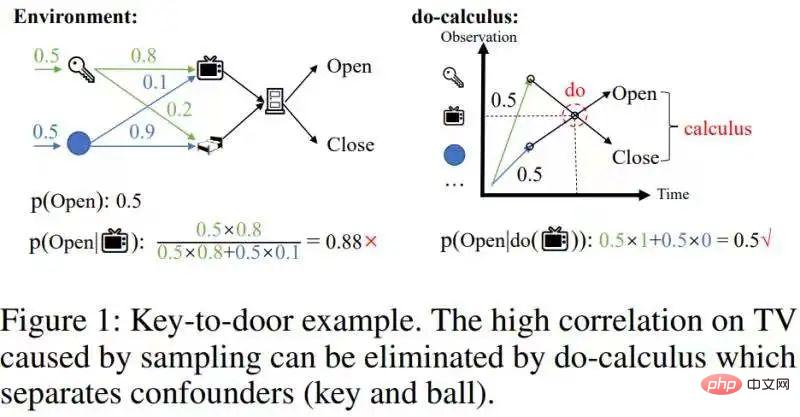
Diperkenalkan buat pertama kali! Menggunakan inferens sebab untuk melakukan pembelajaran peneguhan separa boleh diperhatikan
Pengenalan Artikel:Artikel "Inferens Balas Pantas untuk Pembelajaran Peneguhan Berasaskan Sejarah" mencadangkan algoritma inferens sebab yang pantas yang mengurangkan kerumitan pengiraan inferens sebab - ke tahap yang boleh digabungkan dengan pembelajaran pengukuhan dalam talian. Sumbangan teori artikel ini terutamanya merangkumi dua perkara: 1. Mencadangkan konsep kesan sebab akibat purata masa 2. Melanjutkan kriteria pintu belakang yang terkenal daripada anggaran kesan campur tangan univariat kepada anggaran kesan campur tangan berbilang pembolehubah, yang dipanggil kriteria pintu belakang langkah. Latar belakang memerlukan penyediaan pengetahuan asas tentang pembelajaran peneguhan yang boleh diperhatikan dan inferens sebab akibat. Tanpa pergi ke terlalu banyak pengenalan di sini, mari berikan beberapa portal: Peningkatan Separa Dapat Diperhatikan
2023-04-15
komen 0
1081

Pembelajaran peneguhan songsang: definisi, prinsip dan aplikasi
Pengenalan Artikel:Pembelajaran peneguhan songsang (IRL) ialah teknik pembelajaran mesin yang menggunakan tingkah laku yang diperhatikan untuk menyimpulkan motivasi yang mendasarinya. Tidak seperti pembelajaran pengukuhan tradisional, IRL tidak memerlukan isyarat ganjaran yang jelas, sebaliknya menyimpulkan potensi fungsi ganjaran melalui tingkah laku. Kaedah ini menyediakan cara yang berkesan untuk memahami dan mensimulasikan tingkah laku manusia. Prinsip kerja IRL adalah berdasarkan rangka kerja Proses Keputusan Markov (MDP). Dalam MDP, ejen berinteraksi dengan persekitaran dengan memilih tindakan yang berbeza. Persekitaran akan memberi isyarat ganjaran berdasarkan tindakan ejen. Matlamat IRL adalah untuk membuat kesimpulan fungsi ganjaran yang tidak diketahui daripada tingkah laku ejen yang diperhatikan untuk menerangkan tingkah laku ejen. Dengan menganalisis tindakan yang dipilih oleh ejen di negeri yang berbeza, IRL boleh memodelkan ejen
2024-01-22
komen 0
885

Kaedah untuk mengoptimumkan AB menggunakan pembelajaran peneguhan kecerunan dasar
Pengenalan Artikel:Ujian AB ialah teknik yang digunakan secara meluas dalam eksperimen dalam talian. Tujuan utamanya adalah untuk membandingkan dua atau lebih versi halaman atau aplikasi untuk menentukan versi yang mencapai matlamat perniagaan yang lebih baik. Matlamat ini boleh berupa kadar klikan, kadar penukaran, dsb. Sebaliknya, pembelajaran pengukuhan ialah kaedah pembelajaran mesin yang menggunakan pembelajaran percubaan dan kesilapan untuk mengoptimumkan strategi membuat keputusan. Pembelajaran peneguhan kecerunan dasar ialah kaedah pembelajaran pengukuhan khas yang bertujuan untuk memaksimumkan ganjaran terkumpul dengan mempelajari dasar yang optimum. Kedua-duanya mempunyai aplikasi yang berbeza dalam mengoptimumkan matlamat perniagaan. Dalam ujian AB, kami menganggap versi halaman yang berbeza sebagai tindakan yang berbeza dan matlamat perniagaan boleh dianggap sebagai penunjuk penting isyarat ganjaran. Untuk mencapai matlamat perniagaan yang maksimum, kita perlu merangka strategi yang boleh dipilih
2024-01-24
komen 0
995

pembelajaran peneguhan hierarki
Pengenalan Artikel:Pembelajaran Pengukuhan Hierarki (HRL) ialah kaedah pembelajaran pengukuhan yang mempelajari tingkah laku dan keputusan peringkat tinggi secara hierarki. Berbeza daripada kaedah pembelajaran pengukuhan tradisional, HRL menguraikan tugasan kepada berbilang subtugas dan mempelajari strategi tempatan dalam setiap subtugasan, dan kemudian menggabungkan strategi tempatan ini untuk membentuk strategi global. Kaedah pembelajaran hierarki ini boleh mengurangkan kesukaran pembelajaran yang disebabkan oleh persekitaran berdimensi tinggi dan tugas yang kompleks, dan meningkatkan kecekapan dan prestasi pembelajaran. Melalui strategi hierarki, HRL boleh membuat keputusan pada tahap yang berbeza untuk mencapai tingkah laku pintar peringkat lebih tinggi. Pendekatan ini mempunyai aplikasi dalam banyak bidang seperti kawalan robot, permainan dan pemanduan autonomi.
2024-01-22
komen 0
1411

Isu reka bentuk fungsi ganjaran dalam pembelajaran pengukuhan
Pengenalan Artikel:Isu reka bentuk fungsi ganjaran dalam pembelajaran peneguhan Pengenalan Pembelajaran peneguhan ialah kaedah yang mempelajari strategi optimum melalui interaksi antara ejen dan persekitaran. Dalam pembelajaran pengukuhan, reka bentuk fungsi ganjaran adalah penting untuk kesan pembelajaran ejen. Artikel ini akan meneroka isu reka bentuk fungsi ganjaran dalam pembelajaran pengukuhan dan memberikan contoh kod khusus. Peranan fungsi ganjaran dan fungsi ganjaran sasaran merupakan bahagian penting dalam pembelajaran peneguhan dan digunakan untuk menilai nilai ganjaran yang diperolehi oleh ejen dalam keadaan tertentu. Reka bentuknya membantu membimbing ejen untuk memaksimumkan keletihan jangka panjang dengan memilih tindakan yang optimum.
2023-10-09
komen 0
1724

Isu pemilihan algoritma dalam pembelajaran pengukuhan
Pengenalan Artikel:Masalah pemilihan algoritma dalam pembelajaran peneguhan memerlukan contoh kod khusus Pembelajaran peneguhan ialah satu bidang pembelajaran mesin yang mempelajari strategi optimum melalui interaksi antara ejen dan persekitaran. Dalam pembelajaran pengukuhan, memilih algoritma yang sesuai adalah penting untuk kesan pembelajaran. Dalam artikel ini, kami meneroka isu pemilihan algoritma dalam pembelajaran pengukuhan dan menyediakan contoh kod konkrit. Terdapat banyak algoritma untuk dipilih dalam pembelajaran pengukuhan, seperti Q-Learning, DeepQNetwork (DQN), Actor-Critic, dsb. Pilih algoritma yang betul
2023-10-08
komen 0
1197

Bagaimana untuk melaksanakan pembelajaran pengukuhan mendalam dan terjemahan bahasa semula jadi dalam PHP?
Pengenalan Artikel:Dalam pembangunan teknologi moden, pembelajaran pengukuhan mendalam dan terjemahan bahasa semula jadi adalah dua bidang aplikasi yang paling mewakili. PHP, sebagai bahasa pengaturcaraan yang mudah dan mudah dipelajari, juga boleh mengambil bahagian dalam kedua-dua bidang ini, memberikan lebih banyak kemungkinan untuk aplikasi meluas teknologi AI. 1. Pembelajaran peneguhan mendalam Pembelajaran peneguhan mendalam ialah hala tuju penyelidikan yang popular dalam bidang kecerdasan buatan dan telah digunakan secara meluas dalam banyak bidang termasuk permainan, pemanduan autonomi, kawalan robot, dsb. Idea teras adalah untuk melatih rangkaian saraf yang mendalam dengan input dan output sasaran yang diberikan
2023-05-22
komen 0
723

Bagaimana untuk melaksanakan pembelajaran pengukuhan mendalam dan analisis tingkah laku pengguna dalam PHP?
Pengenalan Artikel:Dengan pembangunan berterusan teknologi pembelajaran mendalam, kecerdasan buatan semakin digunakan dalam pelbagai industri. Di antara pelbagai bahasa pengaturcaraan, PHP, sebagai bahasa sebelah pelayan yang popular, juga boleh menggunakan teknologi pembelajaran pengukuhan mendalam untuk analisis tingkah laku pengguna. Pembelajaran mendalam ialah teknologi pembelajaran mesin yang menemui corak dan ketetapan dengan melatih sejumlah besar data. Pembelajaran peneguhan mendalam ialah kaedah yang menggabungkan pembelajaran mendalam dan pembelajaran peneguhan serta digunakan untuk menyelesaikan masalah membuat keputusan yang kompleks. Untuk melaksanakan pembelajaran pengukuhan mendalam dalam PHP, anda perlu menggunakan perpustakaan dan kotak PHP yang berkaitan
2023-05-26
komen 0
1003


Daripada tikus berjalan dalam mez kepada AlphaGo mengalahkan manusia, pembangunan pembelajaran pengukuhan
Pengenalan Artikel:Apabila bercakap tentang pembelajaran pengukuhan, banyak adrenalin penyelidik melonjak secara tidak terkawal! Ia memainkan peranan yang sangat penting dalam sistem AI permainan, robot moden, sistem reka bentuk cip dan aplikasi lain. Terdapat pelbagai jenis algoritma pembelajaran pengukuhan, tetapi ia terbahagi kepada dua kategori: "berasaskan model" dan "bebas model". Dalam perbualan dengan TechTalks, ahli sains saraf dan pengarang "The Birth of Intelligence" Daeyeol Lee membincangkan model pembelajaran pengukuhan yang berbeza dalam manusia dan haiwan, kecerdasan buatan dan kecerdasan semula jadi serta hala tuju penyelidikan masa depan. Pembelajaran peneguhan tanpa model Pada akhir abad ke-19, "Undang-undang Kesan" yang dicadangkan oleh ahli psikologi Edward Thorndike menjadi asas pembelajaran peneguhan tanpa model. Th
2023-05-09
komen 0
877

Pakar teknikal AI Xishanju Huang Hongbo: Penyepaduan praktikal pembelajaran pengukuhan dan pokok tingkah laku dalam permainan
Pengenalan Artikel:Dari 6 hingga 7 Ogos 2022, Persidangan Teknologi Kepintaran Buatan Global AISummit akan diadakan seperti yang dijadualkan. Di sub-forum "Penjelajahan Sempadan Kecerdasan Buatan" yang diadakan pada petang ke-7, pakar teknikal Xishanju AI, Huang Hongbo membawakan perkongsian tema "Kombinasi Praktikal Pembelajaran Pengukuhan dan Pokok Tingkah Laku dalam Permainan", berkongsi secara terperinci kesan peneguhan. pembelajaran dalam bidang permainan. Huang Hongbo berkata bahawa pelaksanaan teknologi pembelajaran tetulang tidak terletak pada mengubah algoritma menjadi lebih berkuasa, tetapi dalam menggabungkan teknologi pembelajaran tetulang dengan pembelajaran mendalam dan perancangan permainan untuk membentuk satu set penyelesaian yang lengkap dan melaksanakannya. Pembelajaran peneguhan menjadikan permainan lebih pintar Pelaksanaan pembelajaran pengukuhan dalam permainan dapat menjadikan permainan lebih pintar dan lebih mudah dimainkan.
2023-04-09
komen 0
1828

PromptPG: Apabila pembelajaran peneguhan memenuhi model bahasa berskala besar
Pengenalan Artikel:Penaakulan matematik adalah keupayaan teras kecerdasan manusia, tetapi pemikiran abstrak dan penaakulan logik masih menjadi cabaran besar untuk mesin. Model bahasa pra-latihan berskala besar, seperti GPT-3 dan GPT-4, telah mencapai kemajuan yang ketara dalam penaakulan matematik berasaskan teks (seperti masalah perkataan matematik). Walau bagaimanapun, pada masa ini tidak jelas sama ada model ini boleh mengendalikan masalah yang lebih kompleks yang melibatkan maklumat heterogen seperti data jadual. Untuk mengisi jurang ini, penyelidik dari UCLA dan Allen Institute for Artificial Intelligence (AI2) memperkenalkan Tabular Math Word Problems (TabMWP), set data sebanyak 38,431 masalah domain terbuka yang memerlukan
2023-04-07
komen 0
1230

Sejauh manakah Transformer telah berkembang dalam pembelajaran pengukuhan? Universiti Tsinghua, Universiti Peking dan lain-lain bersama-sama mengeluarkan ulasan TransformRL
Pengenalan Artikel:Pembelajaran pengukuhan (RL) menyediakan bentuk matematik untuk membuat keputusan berurutan, dan pembelajaran pengukuhan mendalam (DRL) juga telah mencapai kemajuan yang besar dalam beberapa tahun kebelakangan ini. Walau bagaimanapun, isu kecekapan sampel menghalang penggunaan meluas kaedah pembelajaran peneguhan mendalam dalam dunia sebenar. Untuk menyelesaikan masalah ini, mekanisme yang berkesan ialah memperkenalkan bias induktif dalam rangka kerja DRL. Dalam pembelajaran peneguhan mendalam, penghampir fungsi adalah sangat penting. Walau bagaimanapun, berbanding dengan reka bentuk seni bina dalam pembelajaran terselia (SL), isu reka bentuk seni bina dalam DRL masih jarang dikaji. Kebanyakan kerja sedia ada pada seni bina RL telah didorong oleh komuniti pembelajaran diselia/separa penyeliaan. Sebagai contoh, untuk memproses input berdasarkan imej berdimensi tinggi dalam DRL, pendekatan biasa ialah memperkenalkan rangkaian neural convolutional (CNN) [
2023-04-13
komen 0
779
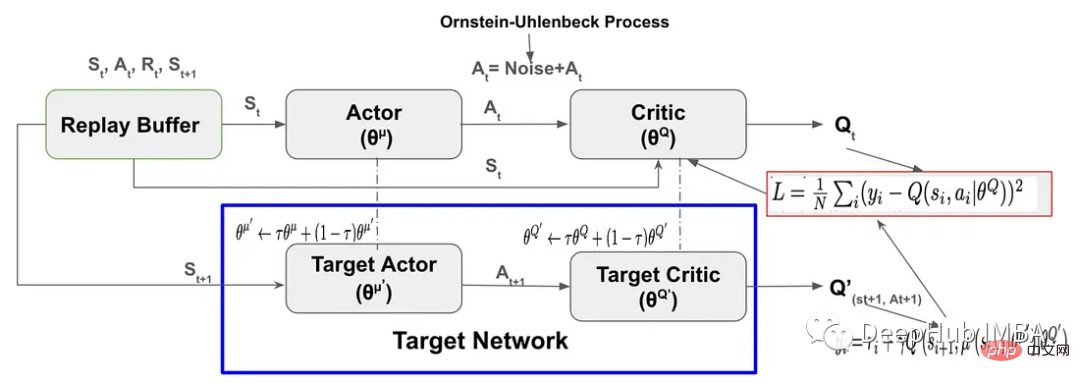
Pelaksanaan kod PyTorch dan penjelasan langkah demi langkah pembelajaran pengukuhan DDPG
Pengenalan Artikel:Kecerunan Dasar Deterministik Dalam (DDPG) ialah algoritma peneguhan dalam tanpa model yang diilhamkan oleh Deep Q-Network Ia berdasarkan Actor-Critic menggunakan kecerunan dasar Artikel ini akan menggunakan pytorch sepenuhnya komponen utama DDPG ialah Replay BufferActor-Critic neural networkExploration NoiseTarget network Kemas Kini Sasaran Lembut untuk Target Network
2023-04-13
komen 0
1752

Apakah pembelajaran pengukuhan mendalam dalam Python?
Pengenalan Artikel:Apakah pembelajaran pengukuhan mendalam dalam Python? Pembelajaran Pengukuhan Dalam (DRL) telah menjadi fokus penyelidikan utama dalam bidang kecerdasan buatan sejak beberapa tahun kebelakangan ini, terutamanya dalam aplikasi seperti permainan, robot dan pemprosesan bahasa semula jadi. Pembelajaran pengukuhan dan perpustakaan pembelajaran mendalam berdasarkan bahasa Python, seperti TensorFlow, PyTorch, Keras, dll., membolehkan kami melaksanakan algoritma DRL dengan lebih mudah. Asas teori pembelajaran peneguhan mendalam
2023-06-04
komen 0
1826

Bagaimana untuk menaik taraf peminat memancing kepada tutorial peralatan canggih untuk peminat memancing untuk menaik taraf peralatan
Pengenalan Artikel:Ini adalah tutorial untuk peminat memancing untuk menaik taraf peralatan mereka. Saya percaya ramai pemain juga sangat prihatin tentang bagaimana untuk meningkatkan peralatan mereka. Mari lihat kandungan khusus bahagian ini saya harap anda akan menyukainya. 1. Mulakan pengukuhan Klik pada pancing dalam antara muka peralatan anda sendiri, dan kemudian anda akan melihat butang pengukuhan, seperti yang ditunjukkan dalam gambar Klik untuk memasuki antara muka pengukuhan. 2. Penambahbaikan biasa mempunyai dua pilihan: peningkatan biasa dan peningkatan tunai mungkin gagal dinaik taraf, manakala peningkatan tunai boleh memastikan kejayaan 100% dalam peningkatan. Peningkatan tidak akan gagal sebelum +4, jadi adalah disyorkan bahawa pemain menggunakan syiling emas untuk mengukuhkannya terlebih dahulu. 3. Peneguhan yang berjaya Selepas peneguhan yang berjaya, kerosakan pancing akan dipertingkatkan. Kerosakan itu akan menjejaskan tahap kekuatan fizikal ikan yang digunakan setiap kali Semakin tinggi kerosakan, semakin banyak kekuatan fizikal yang akan digunakan setiap kali. Jika anda ingin menangkap ikan besar yang jarang berlaku, anda perlu
2024-07-20
komen 0
508

Aplikasi pembelajaran mesin Golang dalam pembelajaran pengukuhan
Pengenalan Artikel:Pengenalan kepada aplikasi pembelajaran mesin Golang dalam pembelajaran peneguhan Pembelajaran tetulang ialah kaedah pembelajaran mesin yang mempelajari tingkah laku optimum dengan berinteraksi dengan persekitaran dan berdasarkan maklum balas ganjaran. Bahasa Go mempunyai ciri seperti selari, konkurensi dan keselamatan ingatan, memberikan kelebihan dalam pembelajaran pengukuhan. Kes praktikal: Pembelajaran pengukuhan Go Dalam tutorial ini, kami akan menggunakan bahasa Go dan algoritma AlphaZero untuk melaksanakan model pembelajaran pengukuhan Go. Langkah 1: Pasang kebergantungan gogetgithub.com/tensorflow/tensorflow/tensorflow/gogogetgithub.com/golang/protobuf/ptypes/times
2024-05-08
komen 0
510

Isu reka bentuk ganjaran dalam pembelajaran pengukuhan
Pengenalan Artikel:Masalah reka bentuk ganjaran dalam pembelajaran pengukuhan memerlukan contoh kod khusus ialah kaedah pembelajaran mesin yang matlamatnya adalah untuk mempelajari cara mengambil tindakan yang memaksimumkan ganjaran terkumpul melalui interaksi dengan persekitaran. Dalam pembelajaran peneguhan, ganjaran memainkan peranan penting Ia merupakan isyarat dalam proses pembelajaran ejen dan digunakan untuk membimbing tingkah lakunya. Walau bagaimanapun, reka bentuk ganjaran adalah masalah yang mencabar, dan reka bentuk ganjaran yang munasabah boleh mempengaruhi prestasi algoritma pembelajaran pengukuhan. Dalam pembelajaran pengukuhan, ganjaran boleh dianggap sebagai ejen berbanding persekitaran
2023-10-08
komen 0
1446
