Jumlah kandungan berkaitan 10000

Bagaimana untuk melaksanakan algoritma yang diedarkan dan latihan model dalam perkhidmatan mikro PHP
Pengenalan Artikel:Cara melaksanakan algoritma teragih dan latihan model dalam perkhidmatan mikro PHP Pengenalan: Dengan perkembangan pesat pengkomputeran awan dan teknologi data besar, permintaan untuk pemprosesan data dan latihan model semakin meningkat. Algoritma dan latihan model yang diedarkan adalah kunci untuk mencapai kecekapan, kelajuan dan kebolehskalaan. Artikel ini akan memperkenalkan cara melaksanakan algoritma teragih dan latihan model dalam perkhidmatan mikro PHP dan menyediakan beberapa contoh kod khusus. 1. Apakah yang dimaksudkan dengan latihan algoritma dan model yang diedarkan ialah teknologi yang menggunakan pelbagai mesin atau sumber pelayan untuk melaksanakan pemprosesan data dan latihan model secara serentak.
2023-09-25
komen 0
1465

Kepentingan prapemprosesan data dalam latihan model
Pengenalan Artikel:Kepentingan prapemprosesan data dalam latihan model dan contoh kod khusus Pengenalan: Dalam proses melatih pembelajaran mesin dan model pembelajaran mendalam, prapemprosesan data ialah pautan yang sangat penting dan penting. Tujuan prapemprosesan data adalah untuk mengubah data mentah kepada bentuk yang sesuai untuk latihan model melalui satu siri langkah pemprosesan untuk meningkatkan prestasi dan ketepatan model. Artikel ini bertujuan untuk membincangkan kepentingan prapemprosesan data dalam latihan model dan memberikan beberapa contoh kod prapemprosesan data yang biasa digunakan. 1. Kepentingan prapemprosesan data Pembersihan data Pembersihan data ialah
2023-10-08
komen 0
1296

Teknologi asas Python didedahkan: cara melaksanakan latihan dan ramalan model
Pengenalan Artikel:Mendedahkan teknologi asas Python: Cara melaksanakan latihan dan ramalan model, contoh kod khusus diperlukan Sebagai bahasa pengaturcaraan yang mudah dipelajari dan mudah digunakan, Python digunakan secara meluas dalam bidang pembelajaran mesin. Python menyediakan sejumlah besar perpustakaan dan alatan pembelajaran mesin sumber terbuka, seperti Scikit-Learn, TensorFlow, dsb. Penggunaan dan enkapsulasi perpustakaan sumber terbuka ini memberikan kami banyak kemudahan, tetapi jika kami ingin mempunyai pemahaman yang mendalam tentang teknologi asas pembelajaran mesin, hanya menggunakan perpustakaan dan alatan ini tidak mencukupi. Artikel ini akan pergi secara mendalam
2023-11-08
komen 0
1704

Kesan kekurangan data terhadap latihan model
Pengenalan Artikel:Kesan kekurangan data pada latihan model memerlukan contoh kod khusus Dalam bidang pembelajaran mesin dan kecerdasan buatan, data ialah salah satu elemen teras untuk model latihan. Walau bagaimanapun, masalah yang sering kita hadapi dalam realiti adalah kekurangan data. Kekurangan data merujuk kepada jumlah data latihan yang tidak mencukupi atau kekurangan data beranotasi Dalam kes ini, ia akan memberi kesan tertentu pada latihan model. Masalah kekurangan data terutamanya dicerminkan dalam aspek-aspek berikut: Overfitting: Apabila jumlah data latihan tidak mencukupi, model terdedah kepada overfitting. Overfitting merujuk kepada model yang terlalu menyesuaikan diri dengan data latihan.
2023-10-08
komen 0
1439

Amalan gabungan dan latihan model MongoDB dan kecerdasan buatan
Pengenalan Artikel:Apabila teknologi kecerdasan buatan (AI) terus berkembang, aplikasinya dalam pelbagai bidang semakin meluas. Sebagai teknologi pangkalan data yang sedang berkembang, MongoDB juga telah menunjukkan potensi besar dalam bidang kecerdasan buatan. Artikel ini akan meneroka gabungan amalan dan latihan model MongoDB dan kecerdasan buatan, serta impak berfaedah yang dibawa bersama. 1. Aplikasi MongoDB dalam kecerdasan buatan MongoDB ialah sistem pengurusan pangkalan data berorientasikan dokumen yang menggunakan struktur data yang serupa dengan JSON. Berbanding dengan pangkalan data hubungan tradisional
2023-11-02
komen 0
1508
python如何实现线性回归
Pengenalan Artikel:Python语言实现线性回归的步骤有:导入所要用到的库,读取数据并进行预处理。分析数据以及建立线性回归模型,并进行模型训练检验模型效果
2019-04-08
komen 0
11579

Bagaimana untuk menggunakan SVM untuk klasifikasi dalam Python?
Pengenalan Artikel:SVM ialah algoritma klasifikasi yang biasa digunakan, yang digunakan secara meluas dalam bidang pembelajaran mesin dan perlombongan data. Dalam Python, pelaksanaan SVM sangat mudah dan boleh diselesaikan dengan menggunakan perpustakaan yang berkaitan. Artikel ini akan memperkenalkan cara menggunakan SVM untuk pengelasan dalam Python, termasuk prapemprosesan data, latihan model dan penalaan parameter. 1. Prapemprosesan Data Sebelum menggunakan SVM untuk pengelasan, kita perlu pramemproses data untuk memastikan data memenuhi keperluan algoritma SVM. Biasanya, prapemprosesan data termasuk yang berikut
2023-06-03
komen 0
2103

Panduan latihan model ChatGPT Python: langkah untuk menyesuaikan chatbot
Pengenalan Artikel:Panduan latihan model ChatGPTPython: Gambaran keseluruhan langkah untuk menyesuaikan robot sembang: Dalam beberapa tahun kebelakangan ini, dengan peningkatan pembangunan teknologi NLP (pemprosesan bahasa semula jadi), robot sembang telah menarik lebih banyak perhatian. ChatGPT OpenAI ialah model bahasa pra-latihan yang berkuasa yang boleh digunakan untuk membina chatbot berbilang domain. Artikel ini akan memperkenalkan langkah-langkah untuk menggunakan Python untuk melatih model ChatGPT, termasuk penyediaan data, latihan model dan penjanaan sampel dialog. Langkah 1: Penyediaan, pengumpulan dan pembersihan data
2023-10-24
komen 0
1344

Aplikasi ungkapan Python Lambda dalam kecerdasan buatan: meneroka kemungkinan yang tidak terhingga
Pengenalan Artikel:Ekspresi Lambda ialah fungsi tanpa nama dalam Python yang boleh memudahkan kod dan meningkatkan kecekapan. Dalam bidang kecerdasan buatan, ungkapan Lambda boleh digunakan untuk pelbagai tugas, seperti prapemprosesan data, latihan model dan ramalan. 1. Senario aplikasi ungkapan Lambda Prapemprosesan data: Ekspresi Lambda boleh digunakan untuk pramemproses data, seperti penormalan, penyeragaman dan pengekstrakan ciri. #Data biasanORMalized_data=senarai(peta(lambdax:(x-min(data))/(maks(data)-min(data)),data))#Data standardized_data=senarai(m
2024-02-24
komen 0
643

Latihan model AI: algoritma pengukuhan dan algoritma evolusi
Pengenalan Artikel:Algoritma pembelajaran tetulang (RL) dan algoritma evolusi (EA) adalah dua algoritma unik dalam bidang pembelajaran mesin Walaupun kedua-duanya tergolong dalam kategori pembelajaran mesin, terdapat perbezaan yang jelas dalam kaedah dan konsep penyelesaian masalah. Algoritma pembelajaran pengukuhan: Pembelajaran pengukuhan ialah kaedah pembelajaran mesin yang terasnya terletak pada ejen yang berinteraksi dengan persekitaran dan mempelajari strategi tingkah laku optimum melalui percubaan dan kesilapan untuk memaksimumkan ganjaran terkumpul. Kunci kepada pembelajaran pengukuhan ialah ejen sentiasa mencuba pelbagai tingkah laku dan menyesuaikan strateginya berdasarkan isyarat ganjaran. Dengan berinteraksi dengan persekitaran, ejen secara beransur-ansur mengoptimumkan proses membuat keputusannya untuk mencapai matlamat yang ditetapkan. Kaedah ini meniru cara manusia belajar, meningkatkan prestasi melalui percubaan dan kesilapan berterusan dan pelarasan, membolehkan ejen melaksanakan tugas yang kompleks, termasuk komponen utama pembelajaran pengukuhan.
2024-03-25
komen 0
700

Bagaimana untuk mengendalikan data tidak berstruktur dan separa berstruktur dalam C++?
Pengenalan Artikel:Memproses data tidak berstruktur dalam C++ melibatkan prapemprosesan data, pengekstrakan ciri dan latihan model. Memproses data separa berstruktur termasuk penghuraian data, pengekstrakan dan transformasi. Langkah-langkah khusus adalah seperti berikut: Data tidak berstruktur: Prapemprosesan data: penyingkiran hingar dan normalisasi. Pengekstrakan ciri: Ekstrak ciri daripada data. Latihan model: Gunakan algoritma pembelajaran mesin untuk mempelajari corak. Data separa berstruktur: Penghuraian data: penukaran kepada format yang sesuai (XML, JSON, YAML). Pengekstrakan data: Dapatkan maklumat yang anda perlukan. Penukaran data: ke dalam format yang sesuai untuk pemprosesan selanjutnya.
2024-06-01
komen 0
893

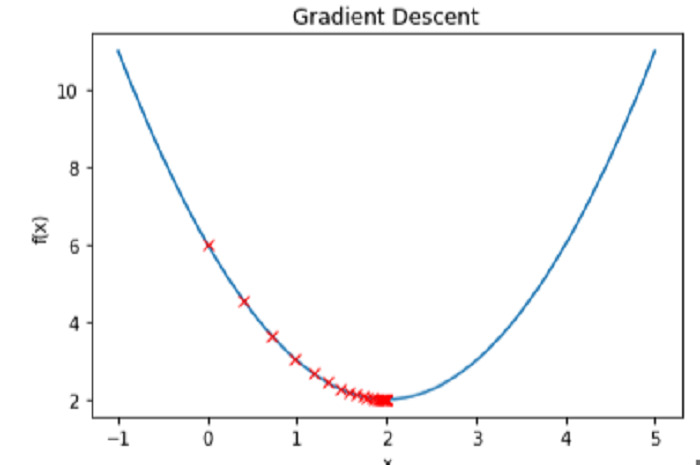
Bagaimana untuk melaksanakan algoritma keturunan kecerunan dalam Python untuk mencari minima tempatan?
Pengenalan Artikel:Penurunan kecerunan ialah kaedah pengoptimuman penting dalam pembelajaran mesin, digunakan untuk meminimumkan fungsi kehilangan model. Dalam istilah awam, ia memerlukan berulang kali menukar parameter model sehingga julat nilai ideal yang meminimumkan fungsi kehilangan ditemui. Kaedah ini berfungsi dengan mengambil langkah-langkah kecil ke arah kecerunan negatif fungsi kehilangan, atau lebih khusus, di sepanjang laluan keturunan paling curam. Kadar pembelajaran ialah hiperparameter yang mengawal pertukaran antara kelajuan dan ketepatan algoritma, dan ia mempengaruhi saiz saiz langkah. Banyak kaedah pembelajaran mesin, termasuk regresi linear, regresi logistik dan rangkaian saraf, untuk menamakan beberapa, menggunakan keturunan kecerunan. Aplikasi utamanya ialah latihan model, di mana matlamatnya adalah untuk meminimumkan perbezaan antara nilai jangkaan dan sebenar pembolehubah sasaran. Dalam siaran ini kita akan melihat pelaksanaan kecerunan dalam Python
2023-09-06
komen 0
810

Teknologi Golang mempercepatkan latihan model dalam pembelajaran mesin
Pengenalan Artikel:Dengan memanfaatkan konkurensi berprestasi tinggi Go, latihan model pembelajaran mesin boleh dipercepatkan: 1. Pemuatan data selari, menggunakan sepenuhnya Goroutine untuk memuatkan data 2. Algoritma pengoptimuman, pengkomputeran teragih melalui mekanisme saluran; menggunakan sokongan rangkaian asli Latih pada berbilang mesin.
2024-05-09
komen 0
888

Dengan ModelScope-Agent, orang baru juga boleh mencipta ejen eksklusif, dengan disertakan tutorial peringkat pengasuh
Pengenalan Artikel:ModelScope-Agent menyediakan rangka kerja Ejen universal yang boleh disesuaikan untuk memudahkan pengguna mencipta ejen mereka sendiri. Rangka kerja ini adalah berdasarkan model bahasa besar sumber terbuka (LLM) sebagai teras dan menyediakan perpustakaan sistem yang mesra pengguna dengan ciri-ciri berikut: Rangka kerja yang boleh disesuaikan dan komprehensif: Menyediakan reka bentuk enjin yang boleh disesuaikan, meliputi pengumpulan data, pengambilan alat , pendaftaran alat, penyimpanan pengurusan, latihan model tersuai dan aplikasi praktikal, dsb., boleh digunakan untuk melaksanakan aplikasi dengan cepat dalam senario sebenar. LLM sumber terbuka sebagai komponen teras: Menyokong latihan model pada berbilang LLM sumber terbuka dalam komuniti ModelScope, dan sumber terbuka set data arahan alat bahasa Cina dan Inggeris yang menyokong MSAgent-Bench
2023-09-20
komen 0
1257

Langkah-langkah untuk Mencipta Penyelesaian AI ML
Pengenalan Artikel:Pelan hala tuju terperinci yang akan membimbing anda melalui pengumpulan data, latihan model dan penggunaan. Proses ini adalah berulang, jadi anda selalunya akan kembali ke langkah awal sambil anda memperhalusi penyelesaian anda.
Langkah 1: Fahami Masalah
Sebelum g
2024-12-24
komen 0
587

Manipulasi Tatasusunan JavaScript
Pengenalan Artikel:Memanipulasi tatasusunan 2d, 3d atau 4d dalam JavaScript diperlukan untuk latihan model AI dan analisis imej/audio/video.
Di bawah ialah beberapa fungsi berguna untuk manipulasi tatasusunan menggunakan JavaScript tulen tanpa pakej matriks seperti Tensorflow.js.
Transpose
2024-09-01
komen 0
1215

Penalaan halus LLaMA mengurangkan separuh keperluan memori, Tsinghua mencadangkan pengoptimum 4-bit
Pengenalan Artikel:Latihan dan penalaan halus model besar mempunyai keperluan yang tinggi pada memori video, dan keadaan pengoptimuman adalah salah satu perbelanjaan utama memori video. Baru-baru ini, pasukan Zhu Jun dan Chen Jianfei dari Universiti Tsinghua mencadangkan pengoptimum 4-bit untuk latihan rangkaian saraf, yang menjimatkan overhed memori latihan model dan boleh mencapai ketepatan yang setanding dengan pengoptimum ketepatan penuh. Pengoptimum 4-bit telah diuji pada pelbagai tugas pra-latihan dan penalaan halus dan boleh mengurangkan overhed memori penalaan halus LLaMA-7B sehingga 57% sambil mengekalkan ketepatan. Kertas: https://arxiv.org/abs/2309.01507 Kod: https://github.com/thu-ml/low-bit-optimizers Kesesakan memori dalam latihan model
2023-09-12
komen 0
656

Gunakan Python untuk membuat alat ramalan harga rumah!
Pengenalan Artikel:Salam semua. Ini adalah kes ramalan harga rumah, yang datang dari laman web Kaggle Ia adalah soalan persaingan pertama untuk ramai pemula algoritma. Kes ini mempunyai proses lengkap untuk menyelesaikan masalah pembelajaran mesin, termasuk EDA, kejuruteraan ciri, latihan model, gabungan model, dsb. Ikuti saya di bawah mengenai proses ramalan harga rumah untuk mengetahui tentang kes ini. Tiada perkataan panjang, tiada kod berlebihan, hanya penerangan ringkas. 1. EDA Tujuan Analisis Data Penerokaan (EDA) adalah untuk memberi kita pemahaman penuh tentang set data. Pada langkah ini, kami meneroka kandungan berikut: Kandungan EDA 1.1 Set data input train = pd.read_csv('
2023-04-12
komen 0
1382