
Kursus Maju 13831
Pengenalan Kursus:Isu ini masih merupakan pengajaran siaran langsung oleh pakar industri, menyasarkan pelajar yang tidak mempunyai pengetahuan asas atau pelajar yang telah bertukar dari bahagian belakang ke bahagian hadapan. Reka bentuk kursus dibahagikan kepada empat peringkat, dengan jumlah 50 hari pembelajaran, berdasarkan projek asal HTML5+CSS3+JS+Vue3+Vant. Vue3+Vite+TS+ElementPlus yang paling popular pada masa ini telah ditambah untuk melengkapkan pembangunan berbilang hujung bagi bahagian hadapan pusat membeli-belah, sistem pengurusan bahagian belakang pusat beli-belah, program mini, APP, dsb. Untuk pertanyaan terperinci, sila hubungi WeChat: phpcn01 (Guru Yueyue)

Kursus Pertengahan 11272
Pengenalan Kursus:"Tutorial Video Pengimbangan Beban Linux Rangkaian IT Kajian sendiri" terutamanya melaksanakan pengimbangan beban Linux dengan melaksanakan operasi skrip pada web, lvs dan Linux di bawah nagin.

Kursus Maju 17597
Pengenalan Kursus:"Tutorial Video MySQL Shang Xuetang" memperkenalkan anda kepada proses dari pemasangan hingga menggunakan pangkalan data MySQL, dan memperkenalkan operasi khusus setiap pautan secara terperinci.
Kemas kini versi Bootstrap dalam projek Laravel yang besar
2023-09-03 19:24:13 0 1 606
Laman web PHP Cina siaran langsung berskala besar pos pendaftaran kelas percuma kebajikan awam. . .
2018-06-04 13:03:08 32 848 64206
2018-10-17 09:05:25 1 1 2974
2018-01-22 11:04:52 29 418 53877
Mengapa __all__ Python tidak boleh menghalang "kandungan yang tidak dieksport tidak boleh diakses"?
2017-05-18 10:50:54 0 2 747
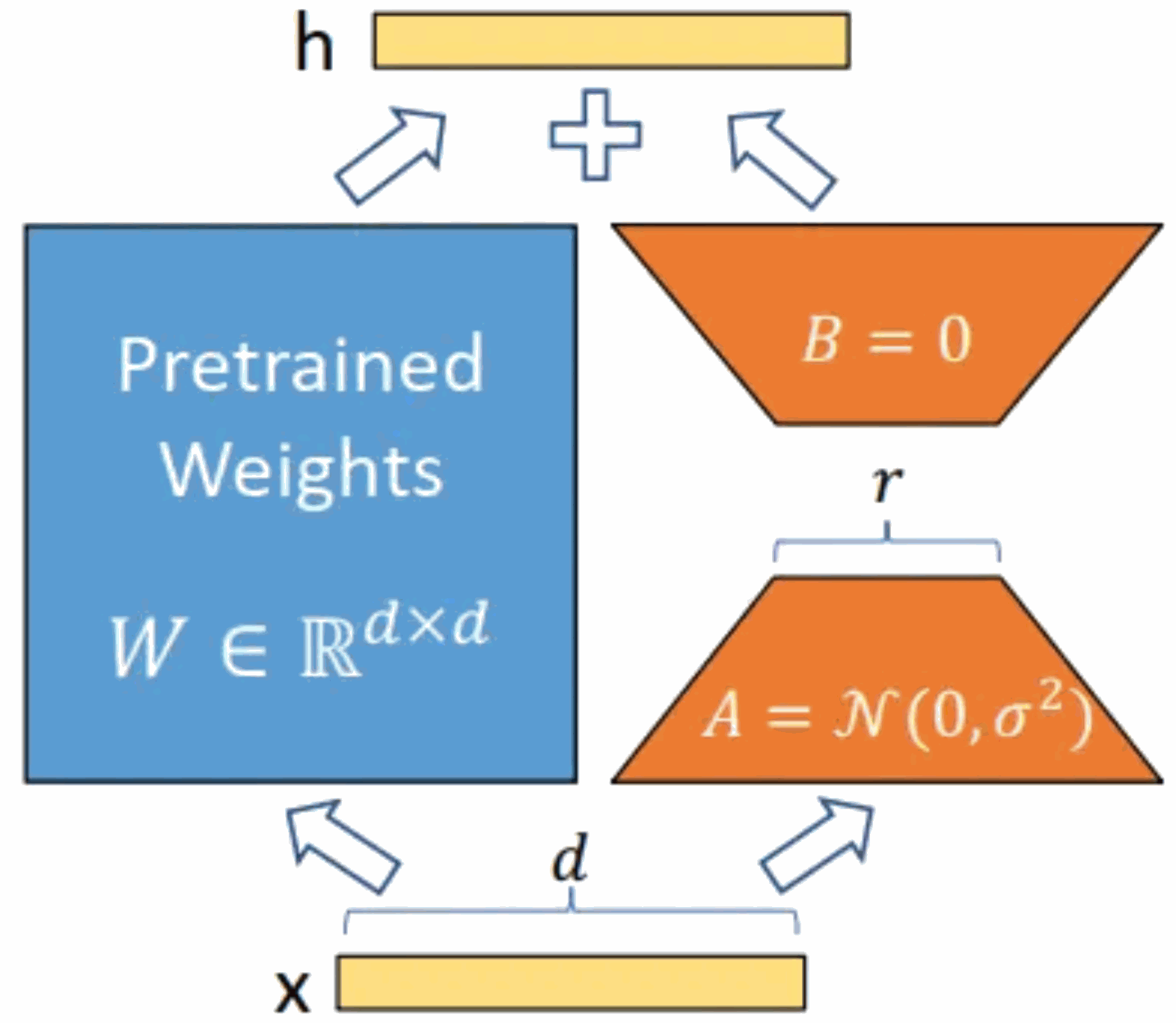
Pengenalan Kursus:Pengenalan model: Model Alpaca ialah model sumber terbuka LLM (Model Bahasa Besar, bahasa besar) yang dibangunkan oleh Universiti Stanford Ia diperhalusi daripada model LLaMA7B (sumber terbuka 7B oleh syarikat Meta) pada arahan 52K parameter model (lebih besar parameter model, lebih besar parameter model, lebih kuat keupayaan penaakulan model, sudah tentu, lebih tinggi kos latihan model). LoRA, nama penuh bahasa Inggeris ialah Low-RankAdaptation of Large Language Models, diterjemahkan secara literal sebagai penyesuaian tahap rendah bagi model bahasa besar Ini adalah teknologi yang dibangunkan oleh penyelidik Microsoft untuk menyelesaikan penalaan halus model bahasa besar. Jika anda mahu model bahasa besar yang telah dilatih untuk dapat melaksanakan domain tertentu
2023-06-01 komen 0 1828

Pengenalan Kursus:Model bahasa besar dan model pembenaman perkataan ialah dua konsep utama dalam pemprosesan bahasa semula jadi. Kedua-duanya boleh digunakan pada analisis dan penjanaan teks, tetapi prinsip dan senario aplikasi adalah berbeza. Model bahasa berskala besar terutamanya berdasarkan model statistik dan probabilistik dan sesuai untuk menjana teks berterusan dan pemahaman semantik. Model embedding perkataan boleh menangkap hubungan semantik antara perkataan dengan memetakan perkataan ke ruang vektor, dan sesuai untuk inferens makna perkataan dan klasifikasi teks. 1. Model benam perkataan Model benam perkataan ialah teknologi yang memproses maklumat teks dengan memetakan perkataan ke dalam ruang vektor berdimensi rendah. Ia menukar perkataan dalam bahasa kepada bentuk vektor supaya komputer dapat memahami dan memproses teks dengan lebih baik. Model pembenaman perkataan yang biasa digunakan termasuk Word2Vec dan GloVe. Model ini digunakan secara meluas dalam tugas pemprosesan bahasa semula jadi
2024-01-23 komen 0 1460

Pengenalan Kursus:Model bahasa berskala besar ialah teknologi utama dalam bidang pemprosesan bahasa semula jadi, menunjukkan prestasi yang kukuh dalam pelbagai tugas. Strategi penyahkodan adalah salah satu aspek penting penjanaan teks oleh model. Artikel ini akan memperincikan strategi penyahkodan dalam model bahasa besar dan membincangkan kelebihan dan kekurangannya. 1. Gambaran keseluruhan strategi penyahkodan Dalam model bahasa besar, strategi penyahkodan ialah kaedah untuk menjana jujukan teks. Strategi penyahkodan biasa termasuk carian tamak, carian rasuk dan carian rawak. Carian tamak ialah kaedah mudah dan mudah yang memilih perkataan dengan kebarangkalian tertinggi sebagai perkataan seterusnya setiap kali, tetapi mungkin mengabaikan kemungkinan lain. Carian rasuk menambah had lebar kepada carian tamak, mengekalkan hanya perkataan calon dengan kebarangkalian tertinggi, dengan itu meningkatkan kepelbagaian. Carian rawak memilih perkataan seterusnya secara rawak, yang boleh menghasilkan lebih pelbagai
2024-01-22 komen 0 1201

Pengenalan Kursus:Risiko terbesar yang dihadapi oleh teknologi kecerdasan buatan pada masa ini ialah pembangunan dan kelajuan aplikasi model bahasa besar (LLM) dan teknologi kecerdasan buatan generatif telah jauh melebihi kelajuan keselamatan dan tadbir urus. Penggunaan AI generatif dan produk model bahasa besar daripada syarikat seperti OpenAI, Anthropic, Google dan Microsoft berkembang dengan pesat. Pada masa yang sama, penyelesaian model bahasa besar sumber terbuka juga berkembang pesat komuniti kecerdasan buatan sumber terbuka seperti HuggingFace telah menyediakan sejumlah besar model sumber terbuka, set data dan aplikasi AI. Untuk menggalakkan pembangunan kecerdasan buatan, organisasi industri seperti OWASP, OpenSSF dan CISA sedang giat membangun dan menyediakan aset utama untuk keselamatan dan tadbir urus kecerdasan buatan, seperti OWASPAIExchange,
2024-04-17 komen 0 1058

Pengenalan Kursus:Artikel ini mengkaji metrik yang paling banyak digunakan dan boleh dipercayai untuk menilai model bahasa besar (LLM). Artikel ini membincangkan kategori metrik yang berbeza, termasuk BLEU, ROUGE, METEOR dan NIST serta cara mereka mengukur prestasi L
2024-08-13 komen 0 1058
