count(*) tidak mengira nilai setiap lajur (tidak kira sama ada ia batal), tetapi secara langsung mengira bilangan baris, yang lebih cekap;
Anda juga boleh menggunakan kaedah penghapusan Sebagai contoh, jika platform adalah qq dan terdapat banyak data, anda boleh menggunakan jumlah data untuk menolak data platform=other;
.
Dari perspektif perniagaan, kos untuk mendapatkan nilai yang tepat adalah sangat tinggi, tetapi kos nilai anggaran lebih rendah Jika keperluan tidak ketat, nilai anggaran boleh digunakan; 🎜#
Anda juga boleh mempertimbangkan untuk menggunakan "pangkalan data memori" seperti redis untuk mengekalkan pemerolehan data yang memakan masa ini;
1 Jika saya menghadapi masalah seperti itu, penyelesaian saya ialah membuat jadual baharu, seperti playfrom_count untuk statistik Adalah lebih baik menggunakan kaedah after_insert dan after_delete dalam rangka kerja, jika tidak Tulis sahaja. satu sendiri. 2 Jika kelantangan pertanyaan sedemikian tidak begitu besar, atau jika ia tidak begitu tepat, anda boleh membuat tugasan untuk mengemas kininya sekali-sekala . Tidak kira anda Sama ada innodb atau myisam, kerana anda menambah di mana, keseluruhan jadual akan diimbas, anda boleh meningkatkan kelajuan perolehan dengan menambah kunci utama.
Pilihan 1. Buat jadual partition untuk platform Pilihan 2. Pisahkan jadual dengan platform Pilihan 3. Buat indeks berasingan untuk platform, tetapi pertimbangkan bahawa set nilai platform anda hendaklah tidak terlalu besar, jadi Tidak sesuai untuk pengindeksan
Masalah ini akan dihadapi dalam pangkalan data hubungan klasik Penyelesaian umum adalah untuk mengakses jadual sistem, yang mengandungi bilangan baris data dalam setiap jadual, yang tidak terkira kali lebih pantas daripada COUNT(*) anda.
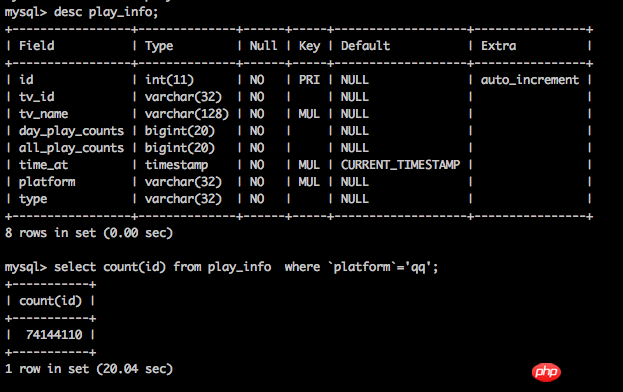
Naik taraf mesin anda walaupun kiraan mudah mengambil masa 20 saat Walaupun terdapat banyak kaedah seperti jadual partition, saya rasa pelaburan itu tidak berbaloi.
Adalah disyorkan untuk mempertimbangkan keperluan senario perniagaan terlebih dahulu Kos penyelesaian teknikal semata-mata adalah terlalu tinggi, dan dalam banyak kes ia pada dasarnya mustahil untuk melaksanakannya. Penyelesaian yang boleh dilakukan ialah: 1. Pisahkan jadual: Bahagikan kepada beberapa jadual mengikut platform Enjin storan ialah MyISAM kecekapan pertanyaan adalah sangat tinggi. Adalah perlu untuk mempertimbangkan beban kerja transformasi sistem yang disebabkan oleh sub-jadual dan sama ada MyISAM boleh memenuhi keperluan sistem kerana MyISAM tidak menyokong transaksi.
2. Buat jadual atau medan berlebihan dan kira semula data yang perlu diringkaskan apabila ia berubah Anda perlu mempertimbangkan sama ada sejumlah besar operasi kemas kini akan meningkatkan beban pada sistem.
3. Jika keputusan pertanyaan tidak perlu tepat sepenuhnya, keputusan boleh dikira secara tetap dan disimpan Apabila membuat pertanyaan, jadual asal tidak ditanya secara langsung.
Dalam kes ini, ia boleh dibahagikan kepada beberapa jadual statistik mengikut bulan atau suku Contohnya, jika anda mempunyai 8 juta data, buat jadual baharu dan setiap baris mewakili jumlah rekod sebulan. Dengan cara ini statistik akan menjadi lebih cepat.















![[Web front-end] Permulaan pantas Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)




count(*) tidak mengira nilai setiap lajur (tidak kira sama ada ia batal), tetapi secara langsung mengira bilangan baris, yang lebih cekap;
Anda juga boleh menggunakan kaedah penghapusan Sebagai contoh, jika platform adalah qq dan terdapat banyak data, anda boleh menggunakan jumlah data untuk menolak data platform=other;
.Dari perspektif perniagaan, kos untuk mendapatkan nilai yang tepat adalah sangat tinggi, tetapi kos nilai anggaran lebih rendah Jika keperluan tidak ketat, nilai anggaran boleh digunakan; 🎜#
Anda juga boleh mempertimbangkan untuk menggunakan "pangkalan data memori" seperti redis untuk mengekalkan pemerolehan data yang memakan masa ini;1 Jika saya menghadapi masalah seperti itu, penyelesaian saya ialah membuat jadual baharu, seperti playfrom_count untuk statistik
Adalah lebih baik menggunakan kaedah after_insert dan after_delete dalam rangka kerja, jika tidak Tulis sahaja. satu sendiri.
2 Jika kelantangan pertanyaan sedemikian tidak begitu besar, atau jika ia tidak begitu tepat, anda boleh membuat tugasan untuk mengemas kininya sekali-sekala . Tidak kira anda Sama ada innodb atau myisam, kerana anda menambah di mana, keseluruhan jadual akan diimbas, anda boleh meningkatkan kelajuan perolehan dengan menambah kunci utama.
Pilihan 1. Buat jadual partition untuk platform
Pilihan 2. Pisahkan jadual dengan platform
Pilihan 3. Buat indeks berasingan untuk platform, tetapi pertimbangkan bahawa set nilai platform anda hendaklah tidak terlalu besar, jadi Tidak sesuai untuk pengindeksan
Masalah ini akan dihadapi dalam pangkalan data hubungan klasik Penyelesaian umum adalah untuk mengakses jadual sistem, yang mengandungi bilangan baris data dalam setiap jadual, yang tidak terkira kali lebih pantas daripada COUNT(*) anda.
Naik taraf mesin anda walaupun kiraan mudah mengambil masa 20 saat Walaupun terdapat banyak kaedah seperti jadual partition, saya rasa pelaburan itu tidak berbaloi.
Adalah disyorkan untuk mempertimbangkan keperluan senario perniagaan terlebih dahulu Kos penyelesaian teknikal semata-mata adalah terlalu tinggi, dan dalam banyak kes ia pada dasarnya mustahil untuk melaksanakannya.
Penyelesaian yang boleh dilakukan ialah:
1. Pisahkan jadual: Bahagikan kepada beberapa jadual mengikut platform Enjin storan ialah MyISAM kecekapan pertanyaan adalah sangat tinggi. Adalah perlu untuk mempertimbangkan beban kerja transformasi sistem yang disebabkan oleh sub-jadual dan sama ada MyISAM boleh memenuhi keperluan sistem kerana MyISAM tidak menyokong transaksi.
2. Buat jadual atau medan berlebihan dan kira semula data yang perlu diringkaskan apabila ia berubah Anda perlu mempertimbangkan sama ada sejumlah besar operasi kemas kini akan meningkatkan beban pada sistem.
3. Jika keputusan pertanyaan tidak perlu tepat sepenuhnya, keputusan boleh dikira secara tetap dan disimpan Apabila membuat pertanyaan, jadual asal tidak ditanya secara langsung.
Dalam kes ini, ia boleh dibahagikan kepada beberapa jadual statistik mengikut bulan atau suku Contohnya, jika anda mempunyai 8 juta data, buat jadual baharu dan setiap baris mewakili jumlah rekod sebulan. Dengan cara ini statistik akan menjadi lebih cepat.