
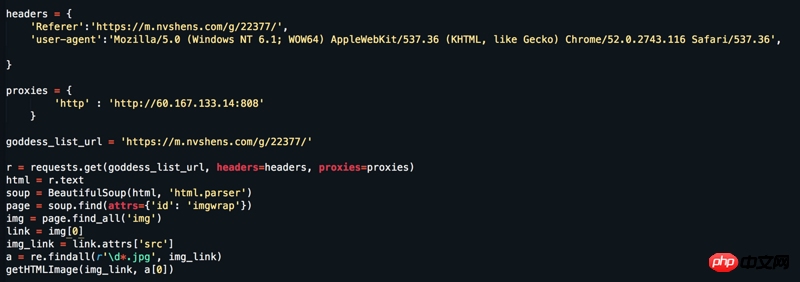
Laman web: https://www.nvshens.com/g/22377/ Buka laman web terus dengan penyemak imbas dan kemudian klik kanan pada imej untuk memuat turunnya kemudian saya Saya menukar tajuk dan menyediakan proksi IP, tetapi ia masih tidak berfungsi. Tetapi melihat pada tangkapan paket, ia bukan data yang dimuatkan secara dinamik! ! ! Sila jawab = =














![[Web front-end] Permulaan pantas Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)




Gadis itu agak cantik.

Ia memang boleh dibuka dengan klik kanan, tetapi selepas disegarkan, ia menjadi gambar hotlink. Secara amnya, untuk mengelakkan hotlinking, pelayan akan menyemak sama ada
Referer字段,这就是为什么刷新后就不是原图的原因(刷新后Refererdalam pengepala permintaan telah berubah).Adakah anda terlepas sebarang parameter dengan menangkap paket semasa mendapatkan gambar?
Saya hanya melihat kandungan laman web dan hampir terlupa bahawa ia adalah rasmi.
Anda boleh mengikuti semua maklumat yang anda minta
Kemudian cubalah
Referer Mengikut reka bentuk laman web ini, setiap halaman harus lebih sesuai dengan tingkah laku berlagak seperti manusia, bukannya menggunakan satu Referer
Berikut adalah kod lengkap yang boleh dijalankan untuk menangkap semua gambar di muka surat 18