Nilai cincang berada pada kedudukan dalam gambar di atas.
Gambar ini adalah respons
#coding=utf-8 permintaan import daripada import bs4 BeautifulSoup
get_url="http://www.szhec.gov.cn/pages/szepb/kqzl/TGzfwHjKqzlzs.jsp?FLAG=FIRSTFW"#获取hash值 post_url="http://www.szhec.gov.cn/pages/szepb/kqzl/TGzfwHjKqzlzs.jsp" #Dapatkan Masa Kualiti Udara html=requests.get(get_url) #Gunakan beautiful untuk menghuraikan halaman web dan dapatkan nilai cincang html_soup=BeautifulSoup(html.text,"html.parser") hash=html_soup.select("input[name=hash]") hash=hash [0].get('value') #Construct data data={
Bersambung: Saya mungkin mencuba kod ini, tetapi program ini tidak melaporkan ralat atau menghasilkan sebarang hasil. apa salahnya permintaan import import xlwt daripada import bs4 BeautifulSoup tarikh tarikh import import tqdm
def datelist(mula, tamat):
start_date = datetime.datetime(*start)
end_date = datetime.datetime(*end)
result = []
curr_date = start_date
while curr_date != end_date:
result.append("%04d-%02d-%02d-%02d" % (curr_date.year, curr_date.month, curr_date.day,curr_date.hour))
return result
def get_html():
global h
s = requests.session()
url = 'http://www.szhec.gov.cn/pages/szepb/kqzl/TGzfwHjKqzlzs.jsp'
headers = {
'User-Agent':'Mozilla/5.0 (iPhone; U; CPU iPhone OS 4_0_1 like Mac OS X; ja-jp) AppleWebKit/532.9 (KHTML, like Gecko) Version/4.0.5 Mobile/8A306 Safari/6531.22.7',
'Referer':'http://www.szhec.gov.cn/pages/szepb/kqzl/TGzfwHjKqzlzs.jsp',
'Host':'www.szhec.gov.cn',
'Cookie':'JSESSIONID=1F7389E70413F613C3A166D8F5A963C4',
'Connection':'keep-alive',
'Accept-Language':'zh-CN,zh;q=0.8,en-US;q=0.5,en;q=0.3',
'Accept-Encoding':'gzip, deflate',
'Accept':'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8'
}
r = s.post(url, data=dt, headers=headers)
h = r.content.decode('utf-8')
def get_excel():
book = xlwt.Workbook(encoding = 'utf-8',style_compression=0)
sheet = book.add_sheet('data',cell_overwrite_ok = True)
global dt
j = 0
for each in datelist((2016, 3, 1,0), (2016, 3, 31,23)):
dt = {'cdateEnd':each,'pageNo1':'1','pageNo2':''}
get_html()
soup = BeautifulSoup(h, "html.parser")
#j = 0
for tabb in soup.find_all('tr'):
i=0;
for tdd in tabb.find_all('td'):
#print (tdd.get_text()+",",)
sheet.write(j,i,tdd.get_text())
i = i+1
j=j+1
book.save(r'.\re'+each+'.xls')















![[Web front-end] Permulaan pantas Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)




Minta menggunakan requests.post
URL imej di atas
Nilai cincang berada pada kedudukan dalam gambar di atas.
Gambar ini adalah respons

#coding=utf-8
permintaan import
daripada import bs4 BeautifulSoup
get_url="http://www.szhec.gov.cn/pages/szepb/kqzl/TGzfwHjKqzlzs.jsp?FLAG=FIRSTFW"#获取hash值
post_url="http://www.szhec.gov.cn/pages/szepb/kqzl/TGzfwHjKqzlzs.jsp" #Dapatkan Masa Kualiti Udara
html=requests.get(get_url)
#Gunakan beautiful untuk menghuraikan halaman web dan dapatkan nilai cincang
html_soup=BeautifulSoup(html.text,"html.parser")
hash=html_soup.select("input[name=hash]")
hash=hash [0].get('value')
#Construct data
data={
}
#Pada ketika ini, maklumat masa kawalan kualiti telah diperoleh dengan betul
tqHtml=requests.post(post_url,data=data)
print tqHtml.text
Klik kanan untuk memeriksa elemen, melihat rangkaian, memilih carian masa dan melihat alamat API ajax yang dipanggil:
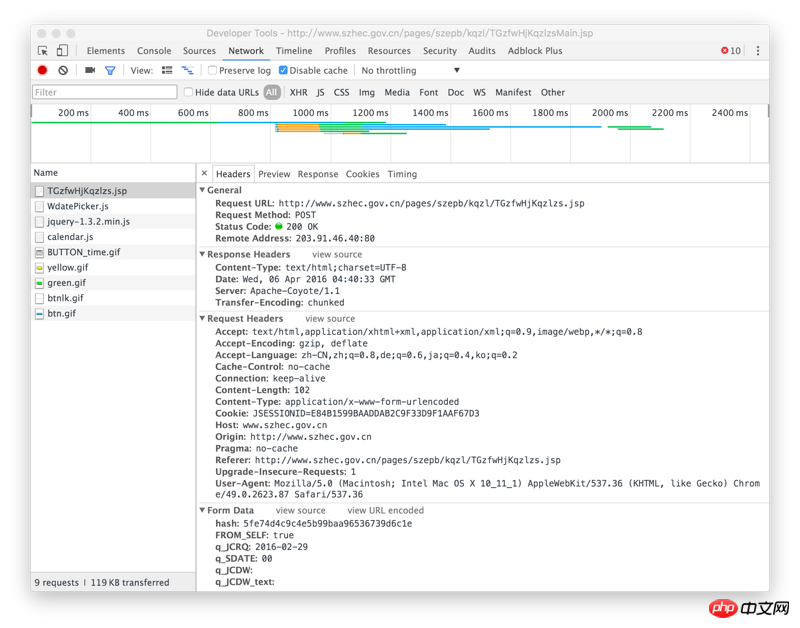
Bersambung:
Saya mungkin mencuba kod ini, tetapi program ini tidak melaporkan ralat atau menghasilkan sebarang hasil. apa salahnya
permintaan import
import xlwt
daripada import bs4 BeautifulSoup
tarikh tarikh import
import tqdm
def datelist(mula, tamat):
def get_html():
def get_excel():
get_excel()