
根据网页所给的字符编码将其字节数据decode('gb2312')
用的是scrapy,从给出的url获取body
def parse(self, response):
body = response.body.decode('gb2312')
print(body)
学分:1.5 # body就是这样之类的,中间的冒号是中文的冒号
# 想弄成的效果就是['学分','1.5']
body = body.split(':') # 就这样使用中文的冒号符来分割,但是出错
SyntaxError: (unicode error) 'utf-8' codec can't decode byte 0xa3 in position 0: invalid start byte
请问怎么解决?















![[Web front-end] Permulaan pantas Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)




Melihat ralat di atas sekali lagi, ia ialah
bait 0xa3Jadi saya mencubanya beberapa kali pada terminal dan mendapati bahawa kolon ialah pengekodan gb2312
Jadi sepatutnya python menggunakan utf-8 lalai untuk menyahkod badan gb2312, jadi satu cara yang boleh saya fikirkan ialah mengubah suai nilai pengekodan lalai, iaitu pernyataan pada baris pertama:
# -*- pengekodan: gb2312 -*-Kemudian operasi itu berjaya.
Python3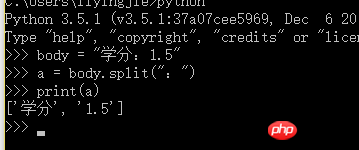
Selepas penyahkodan, badan hendaklah dikodkan unikod, gunakan kaedah berikut:
Isu pengekodan lain, anda boleh merujuk kepada: Pengekodan Aksara untuk Interaksi Manusia-Komputer dan Kalahkan Pengekodan Aksara Python dalam Lima Minit.