
代码
'{"code":"A00185","data":"\\u5bf9\\u4e0d\\u8d77\\uff0c\\u60a8\\u77ed\\u65f6\\u95f4\\u53d1\\u8868\\u535a\\u6587\\u8fc7\\u591a\\uff0c\\u8bf7\\u591a\\u4f11\\u606f\\uff0c\\u6ce8\\u610f\\u8eab\\u4f53\\uff01\\u611f\\u8c22\\u60a8\\u5bf9\\u65b0\\u6d6a\\u535a\\u5ba2\\u7684\\u652f\\u6301\\u548c\\u5173\\u6ce8\\uff01"}'用正则不行,用replace不行,应该是\是属于转义符,不过因为访问的源码中,想把这个替换一下,要怎么处理!?
问题补充:
我是想把\\替换成\ 请问要怎么处理?
错如如下!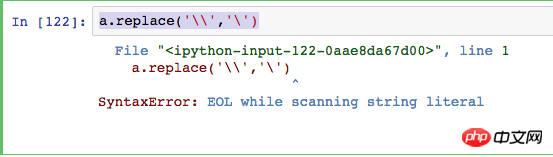
楼下一楼的大哥一直答不对题,我也是比较郁闷.我就想把一个字符串
\\的替换成\
然后想要如下结果:

其他的原理什么的其实我一点也不关心,最好是用一行代码就能回答问题的,万分感谢!














![[Web front-end] Permulaan pantas Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)




Dalam kes
pemindahan aksara,
\=.Poster asal berkata tidak, jadi saya mengujinya secara khusus.
Hasilnya ialah
Saya melihat coretan kod dalam siaran baharu poster dan mengemas kininya semula Poster itu bertukar merah tanpa melihat gesaan kod?
Ayat ini pada asalnya ditulis dengan salah, kerana selepas
'melarikan diri terlepas daripada tanda petikan penutup, rentetan kedua tidak lengkap, dan sudah tentu ralat akan dilaporkan.Selain itu, mengikut permintaan penyoal, tidak perlu menggantikannya, kerana rentetan ini pada asalnya adalah
Apabila mentakrifkan rentetan, menulis dua\adalah bersamaan dengansebenar. .Boleh disahkan dengan kod berikut:
Hasil keluaran
Selepas beberapa rundingan, akhirnya saya mengetahui tujuan soalan itu, iaitu untuk menghuraikan bahasa Cina dalam json. . .
Sangat mudah
Output