
我在爬取凤凰网却出现
UnicodeEncodeError: 'gbk' codec can't encode character 'xa0' in position 151120: illegal multibyte sequence
这是我的代码
__author__ = 'my'
import urllib.request
url = 'http://www.ifeng.com/'
req = urllib.request.urlopen(url)
req = req.read()
req = req.decode('utf-8')
print(req)
为什么utf8却报错GBK?














![[Web front-end] Permulaan pantas Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)




Ini adalah masalah dengan cmd.exe, perisian lain boleh menyahkodnya dengan betul. Contohnya, pad nota, penyemak imbas. . . .
Ditambah:
Malah, anda juga boleh mengubah suai pengekodan cmd.exe kepada utf-8 (cp65001)
Langkah:
1 Jalankan CMD.exe
2, chcp 65001
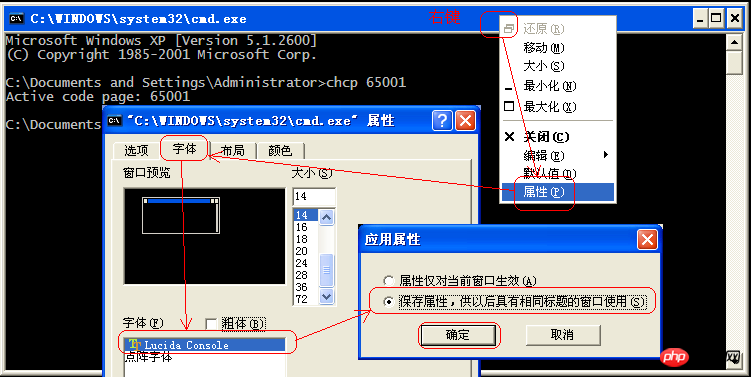
3. Ubah suai fon sifat tetingkap
Klik kanan pada bar tajuk tetingkap CMD, pilih "Properties"->"Font", dan tukar fon kepada True Type fon "Lucida Console"
Seperti yang ditunjukkan:
4. Jalankan ular sawa
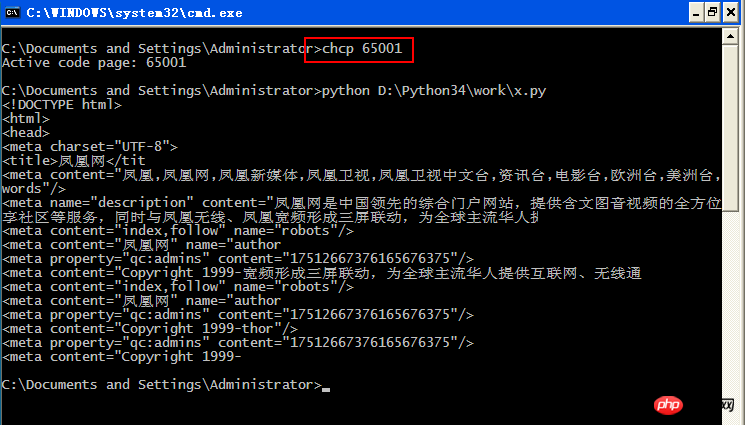
Kandungan x.py:
Saya hanya meletakkan kod soalan ke dalam pycharm, dan masalah ini tidak berlaku. Kemudian saya menggunakan command prompt Windows untuk menaip baris demi baris, dan masalah ini berlaku. Gesaan arahan windows menggunakan pengekodan gbk, dan halaman web itu sendiri menggunakan utf-8 untuk pengekodan. Jika anda ingin menjalankannya dari baris arahan, anda perlu menulis:
Di sini
req = req.decode('gbk', 'ignore')biar saya terangkan: untuk dipaparkan dalam command prompt windows, ia perlu dinyahkodkan menjadi gbk, tetapi beberapa aksara utf-8 sendiri menggunakan gbkPenyahkodan akan gagal lagi, jadi parameter kedua abaikan diperlukan.Sebagai tambahan, pengekodan juga mungkin menghadapi masalah ini. Contohnya, jika anda menggunakan perpustakaan permintaan untuk meminta, ia akan menjadi rentetan yang diminta dan bukannya jenis bait Jika anda menghadapi masalah dengan pengekodan, anda juga boleh menggunakan str .encode('encoding', 'ingore').decode('decoding') untuk menyelesaikan masalah yang serupa.
Jika anda tidak faham, anda boleh membaca blog saya
Untuk menjawab soalan daripada subjek, sesetengah halaman web adalah baik. Mungkin sesetengah halaman web menggunakan pengekodan GBK atau teksnya serasi dengan GBK dan UTF-8
Dianggarkan pengekodan lalai sistem anda ialah gbk, anda boleh mencubanya
Adakah anda menjalankannya menggunakan konsol windows? Kerana pengekodan lalai konsol ialah gbk.
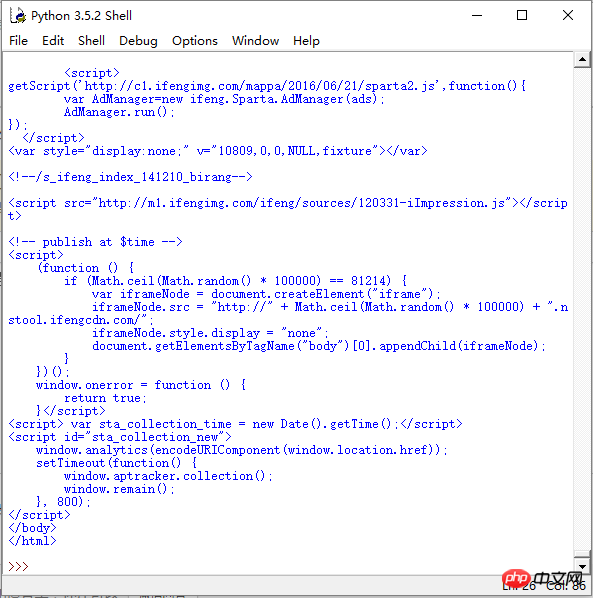
Tidak mengapa untuk menggunakan penterjemah yang disertakan dengan ular sawa:
Atau gunakan alatan lain dan bukannya konsol.
# _*_ coding: utf-8 _*_Nyatakan pengekodan fail
Nyatakan pengekodan program anda.