本人最近在特运通的电脑客户端内发现了感兴趣的信息,我现在想把里面的数据信息通过爬虫的形式获取下来,我想问下可以通过什么样的思路实现?
现在的基本思路是,通过fiddle或者Wireshark抓包,通过抓包的信息查看数据原链接,然后找规律去用python爬取,但是抓包的数据不知道如何使用,所以求大神指教~~
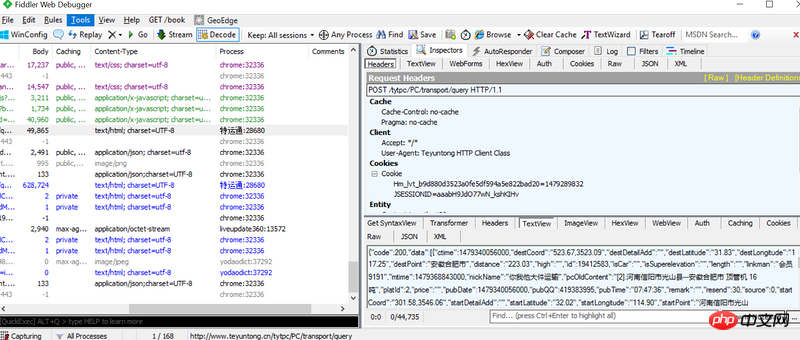
下图是抓包数据
认证高级PHP讲师
Masih tiada jawapan~~~~
Hanya bawa parameter ke permintaan, jana url dan dapatkan kandungan url Lihat tangkapan skrin anda, data json yang dikembalikan, ini mudah dihuraikan. Saya tidak tahu langkah mana yang anda menghadapi masalah sekarang.

















![[Web front-end] Permulaan pantas Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)




Masih tiada jawapan~~~~
Hanya bawa parameter ke permintaan, jana url dan dapatkan kandungan url
Lihat tangkapan skrin anda, data json yang dikembalikan, ini mudah dihuraikan. Saya tidak tahu langkah mana yang anda menghadapi masalah sekarang.