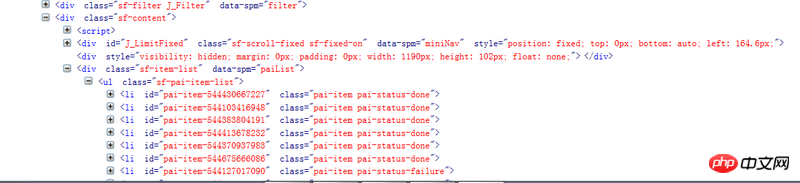
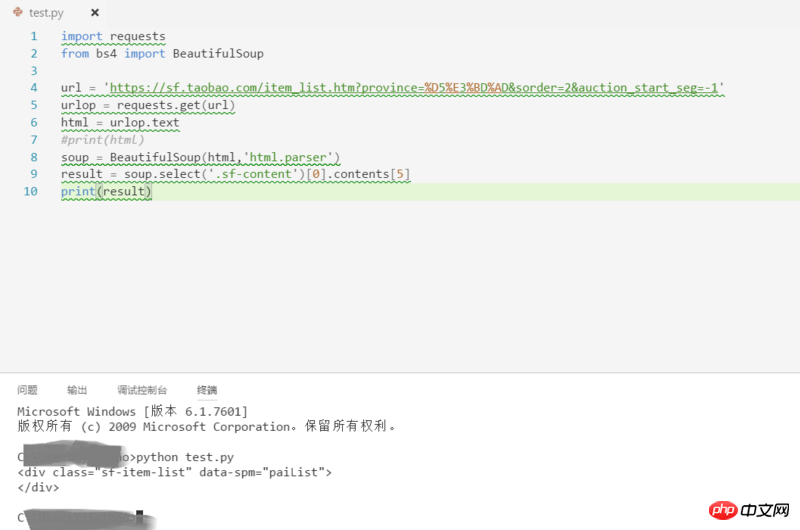
Penanya, jika anda menggunakan Chrome F12 untuk melihatnya, akan ada kandungan yang dimuatkan secara dinamik dan anda tidak boleh mendapatkan kandungan ini dengan meminta terus URL halaman tersebut. Anda disyorkan untuk mengklik kanan untuk melihat kod sumber halaman web dan membandingkannya dengan kandungan dalam F12 Jika tiada kandungan dalam kod sumber, semak permintaan lain dalam Rangkaian untuk melihat jika terdapat sebarang data anda perlukan.
















![[Web front-end] Permulaan pantas Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)




Pernahkah anda mempertimbangkan pemuatan dinamik dengan javascript?
Penanya, jika anda menggunakan Chrome F12 untuk melihatnya, akan ada kandungan yang dimuatkan secara dinamik dan anda tidak boleh mendapatkan kandungan ini dengan meminta terus URL halaman tersebut. Anda disyorkan untuk mengklik kanan untuk melihat kod sumber halaman web dan membandingkannya dengan kandungan dalam F12 Jika tiada kandungan dalam kod sumber, semak permintaan lain dalam Rangkaian untuk melihat jika terdapat sebarang data anda perlukan.