Saya rasa perkara ini tidak dapat digambarkan dengan jelas dalam satu atau dua ayat.
Entri blog ini yang saya rujuk sebelum ini, saya harap ia dapat membantu anda.
Izinkan saya bercakap tentang pemahaman peribadi saya.
scrapy menggunakan python milik collection.deque yang dipertingkatkan untuk menyimpan request yang hendak dirangkak Bagaimana dua atau lebih Spider berkongsi deque ini?
Baris gilir untuk dirangkak tidak boleh dikongsi dan pengedaran adalah karut. scrapy-redis menyediakan penyelesaian, menggantikan collection.deque dengan pangkalan data redis dan berbilang perangkak menyimpan redis untuk dirangkak daripada pelayan request yang sama, supaya berbilang spider boleh pergi ke yang sama Baca dalam pangkalan data, supaya masalah utama pengedaran diselesaikan.
Nota: tidak menggantikan redis untuk menyimpan request, scrapy boleh diedarkan terus!
berkaitan secara langsung dengan
ialah penjadual scrapy. 待爬队列SchedulerRujuk struktur
scrapyIa bertanggungjawab untuk beratur
baharu, mengeluarkan
seterusnya untuk dirangkak, dsb. Oleh itu, selepas menggantikan redis, komponen lain mesti ditukar. requestrequestJadi, pemahaman peribadi saya ialah agak mudah untuk menggunakan perangkak yang sama pada berbilang mesin, penempatan teragih
, alamat rujukan
blog saya. Dan tugasan ini, termasuk penyahduplikasi URL, adalah fungsi rangka kerja redis yang telah ditulis. scrapy-redisAlamat rujukan ada di sini Anda boleh memuat turun contoh untuk melihat pelaksanaan khusus. Saya juga telah mengusahakannya baru-baru ini
, dan saya akan mengemas kini jawapan ini apabila saya telah menggunakannya.
scrapy-redisJika anda mempunyai sebarang kemajuan baharu, anda boleh berkongsi dengan kami.
@伟兴 Hello, saya melihat komen ini pada 15.10.11 Adakah anda mempunyai sebarang keputusan sekarang? Bolehkah anda mengesyorkan beberapa blog anda Terima kasih~ Anda boleh menghubungi saya chenjian158978@gmail.com
















![[Web front-end] Permulaan pantas Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)




Saya rasa perkara ini tidak dapat digambarkan dengan jelas dalam satu atau dua ayat.
Entri blog ini yang saya rujuk sebelum ini, saya harap ia dapat membantu anda.
Izinkan saya bercakap tentang pemahaman peribadi saya.
scrapymenggunakanpythonmilikcollection.dequeyang dipertingkatkan untuk menyimpanrequestyang hendak dirangkak Bagaimana dua atau lebihSpiderberkongsidequeini?Baris gilir untuk dirangkak tidak boleh dikongsi dan pengedaran adalah karut.
scrapy-redismenyediakan penyelesaian, menggantikancollection.dequedengan pangkalan dataredisdan berbilang perangkak menyimpanredisuntuk dirangkak daripada pelayanrequestyang sama, supaya berbilangspiderboleh pergi ke yang sama Baca dalam pangkalan data, supaya masalah utama pengedaran diselesaikan.Nota: tidak menggantikan
berkaitan secara langsung denganredisuntuk menyimpanrequest,scrapyboleh diedarkan terus!ialah penjadual
scrapy.待爬队列SchedulerRujuk struktur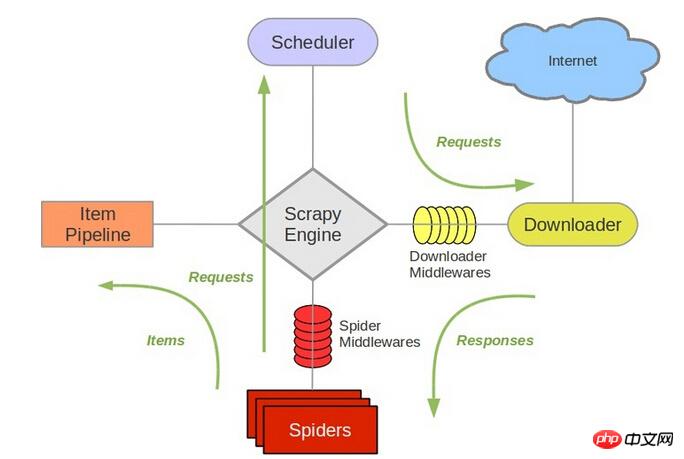 Ia bertanggungjawab untuk beratur
Ia bertanggungjawab untuk beratur
baharu, mengeluarkanscrapyseterusnya untuk dirangkak, dsb. Oleh itu, selepas menggantikan redis, komponen lain mesti ditukar.
, alamat rujukanrequestrequestJadi, pemahaman peribadi saya ialah agak mudah untuk menggunakan perangkak yang sama pada berbilang mesin, penempatan teragihblog saya. Dan tugasan ini, termasuk penyahduplikasi URL, adalah fungsi rangka kerja
, dan saya akan mengemas kini jawapan ini apabila saya telah menggunakannya.redisyang telah ditulis.scrapy-redisAlamat rujukan ada di sini Anda boleh memuat turun contoh untuk melihat pelaksanaan khusus. Saya juga telah mengusahakannya baru-baru iniscrapy-redisJika anda mempunyai sebarang kemajuan baharu, anda boleh berkongsi dengan kami.@伟兴 Hello, saya melihat komen ini pada 15.10.11 Adakah anda mempunyai sebarang keputusan sekarang?
Bolehkah anda mengesyorkan beberapa blog anda Terima kasih~
Anda boleh menghubungi saya chenjian158978@gmail.com