

has been introduced before SCHEMA. This article will introduce Rule and Server together ~
This is the first Rule. In this file For the rules of sharding, this time we only extract some methods with relatively high usage rates. Let’s first look at the contents of the configuration file.
The upper part of the screenshot describes the definition of the rule, and the lower part shows the actual segmentation rules corresponding to the rule. Here the chief engineer introduces the following four segmentation methods~murmur has been cheated~
- -------------------------------------------------- ----------------------------------------Hash-int------- -------------------------------------------------- --------------------------
Let's look at hash-int first. Under this segmentation rule, there is a mapfile, which means that the segmentation rule is determined based on the content of partition-hash-int, then take a look at this text file
Very simple content, this means that in the base column used for segmentation, when the value is 10000, it is placed in the first DN (dn1), and when the value is 10010, it is placed in the second DN (dn2)
You can take a look at the actual effect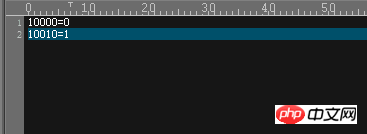
Debug log, these two statements are assigned to dn1 and dn2, and the corresponding data is also inserted into the database.
(Excavator rolls rough~), if the value of the reference column in the inserted data is not the value stated in this file, what will be the effect? 
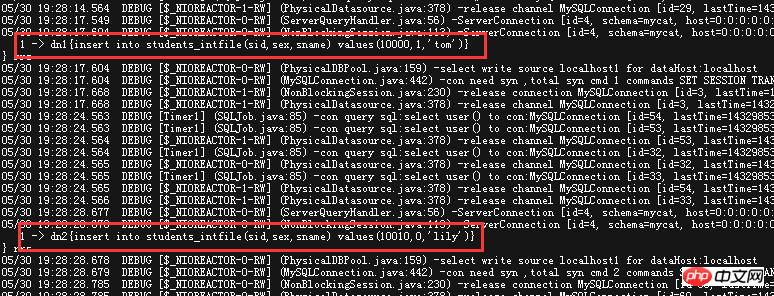 ## , which can be roughly understood as
## , which can be roughly understood as
enumeration partition
, which is more suitable for situations where the value is fixed, such as gender (0,1), province (fixed value, which will not be used in the short term) Let’s take back the Japanese province~), channel dealer
or ID of various platforms And, with a comma separation, multiple values can be placed in a partition, so you can comprehensively formulate the division strategy according to the actual data/traffic/access volume; Not an all-powerful warrior╮(╯_╰)╭
##---------------------- -------------------------------------------------- ------------------range-long--------------------------------- -------------------------------------------------- ---
The second division method, Range-Long, if you look closely, it is more similar to Hash-I. From the content of the file, it can be seen that this is a way to divide the range, formulate the range of the benchmark column, and then put all the data of this range on a DN. This The method is basically the same as Hash-I, so there is no screenshot. (Lazy cancer is not enough!)
This kind of cutting strategy, I personally feel that there will be fewer use scenarios in the business database, because this cut is divided The method needs to predetermine the overall quantity, which determines that it cannot be used for data that grows infinitely. After all, it will be very troublesome to change this segmentation strategy. Divide it evenly according to a certain number, such as a business that fixes X pieces of data a day (temperature collection? Data collection? and so on), and then build multiple DNs (libraries) in advance.
# # A DN is set to store 1000W pieces of data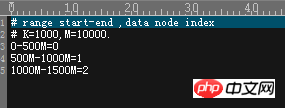
), then at this time, a certain DN (sub-database) will have very high IO pressure, while several other DNs (sub-databases) will have no IO operations at all. There will be a
phenomenon similar to the common hot block/hot disk in DB, and MySQL often uses auto-incrementing primary keys, so there will be many more opportunities for a large number of "sequential" insertions in MySQL tables
. -------------------------------------------------- ---------------------------------------------mod- long---------------------------------------------------------------- ---------------------------------- mod-long, from the mod point of view this should be It is a method of taking the remainder. Let’s take a look at the specific configuration information. Reading the data uniformly on four DN (of course, the number of count & lt; dn is not a problem) Look at the actual effect
Look at mycat's debug logs, see that mycat is the How to deal with it
’ ’ ’ ’ I U dollars U dollars U dollars U dollars dollars dollars dollars dollars dollars dollars dollars dollars dollars dollars dollars dollars dollars ourselves ourselves ourselves ourselves ourselves ourselves ourselves Wheneverbidbid Big Big Big Good take the the most of the the most DN-like to the DN--base-data-database DN-database? Multiple DN (libraries) above
Compared with the range method above, This segmentation strategy will better disperse the pressure of database writing, but the problem is also obvious. Once a range query occurs, MyCAT needs to be merged Result , when the amount of data is high, the time consumed by this kind of cross-database query + merged results may increase a lot, especially when order occurs.
by.
, when querying personal account information, some tables with user information can be redundant, and then use this method to provide more efficient queries (after all, the bank has a large number of users, eh~)
---------------------------------------- ---------------------------------------------partition-by-long------ -------------------------------------------------- -------------------------- partition-by-long, in range-long and mod -long
A slightly compromised partitioning strategy, the specific partitioning situation is described as follows: With 1024 as a unit, each DN stores partitionLength amount of data, and, partitionCount x partitionLength =1024
It seems a bit difficult to understand. To describe it vividly, take
partitionCount(4) x partitionLength(256) as an example. sid%1024=0-255 is placed in DN1,256-511 placed in DN2, and so on Tried to insert eight pieces of data with an offset value of 128, look directly at the MyCAT log
" Inside a DN~
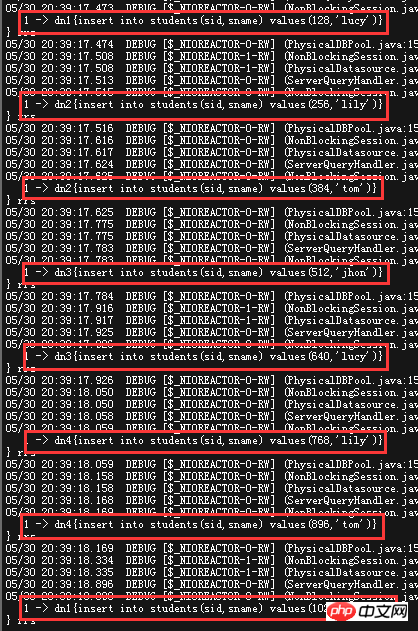
 This two pictures basically also explain the division strategy of this non -uniform distribution. # This division strategy takes a compromise between
This two pictures basically also explain the division strategy of this non -uniform distribution. # This division strategy takes a compromise between
range-long and mod-long. At the same time, it is relatively flexible and can be divided non-uniformly according to different situations. It can actually be applied There will be slightly more scenarios, or in other words, it can be used in many scenarios, which relatively reduces the cross-DN situation, and splits the data evenly, and single-point query will not be too slow. 
-------------------------------- -------------------------------------------------- ----Write it at the end------------------------------------------------ ------------------------------------------
In fact, MyCAT supports many segmentation methods. For example, segmentation strategies based on time can be segmented by month, day, etc. There is no way to include all the strategies here. I put them all up, sorry o( ̄ヘ ̄o#)In fact, from a personal point of view, there is no problem in dividing time according to the partitioning strategy of the database itself. Semi-annual and quarterly data are still the same. You will need to query...PS: _(:з ∠)_I am really not lazy... It can be said that the key points of MyCAT's sub-database and table are basically reflected in this rule. The table must be Don't divide it. How to divide the table data needs to be decided based on the actual business. The most appropriate division strategy should be determined based on the characteristics of the business~
The above is the detailed content of Detailed analysis of the MyCAT (3) rule of MySQL distributed cluster (picture and text). For more information, please follow other related articles on the PHP Chinese website!
















![[Web front-end] Node.js quick start](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



