Mysql Video Tutorial column introduces InnoDB’s insertion buffer.

The InnoDB engine has several key features that bring better performance and reliability:
- Insert Buffer )
- Double Write
- Adaptive Hash Index
- Async IO
- Refresh adjacency Page (Flush Neighbor Page)
Today our topic is Insert Buffer (Insert Buffer) , because the underlying data of the InnoDB engine is stored in a structured B-tree, and for the index we have aggregation Indexes and nonclustered indexes.
Inserting data will inevitably cause changes in the index. Needless to say, clustered indexes are generally in ascending order. Non-clustered indexes are not necessarily data, and their discrete nature leads to continuous changes in the structure during insertion, resulting in reduced insertion performance.
So in order to solve the problem of non-clustered index insertion performance, the InnoDB engine created the Insert Buffer.
Storage of Insert Buffer
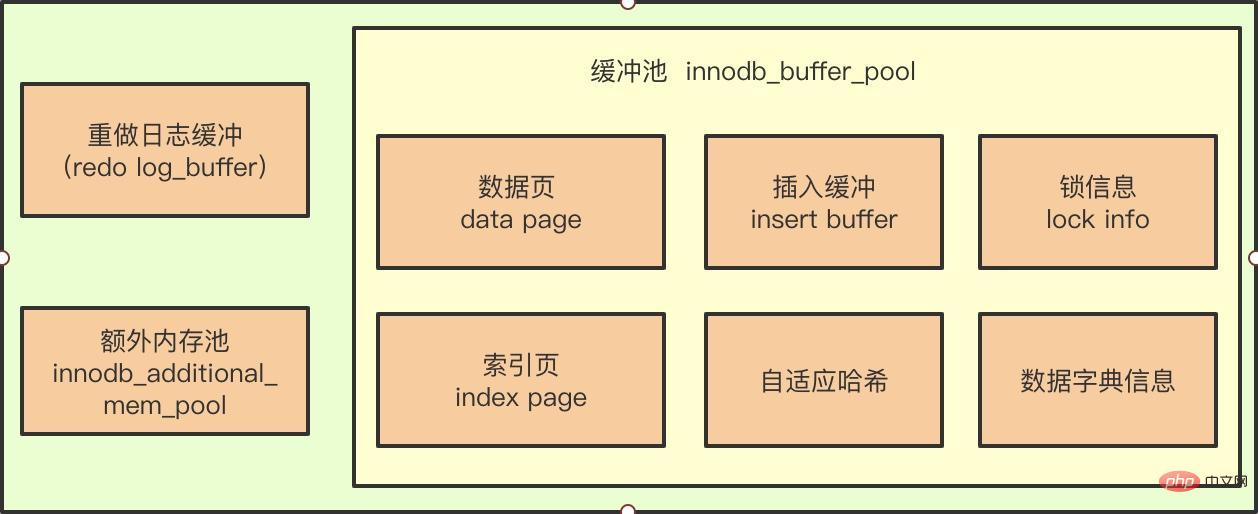
#Seeing the picture above, you may think that Insert Buffer is a component of the InnoDB buffer pool.
**Key point: **In fact, it is true or false. The InnoDB buffer pool does contain the information of the Insert Buffer, but the Insert Buffer actually exists physically like the data page (a shared table exists in the form of a B-tree) in space).
The role of Insert Buffer
Let me talk about a few points first:
A table can only have one primary key index. That's because its physical storage is a B-tree. (Don’t forget the data stored in the clustered index leaf nodes, and there is only one copy of the data)
The non-clustered index leaf nodes store the primary key of the clustered index
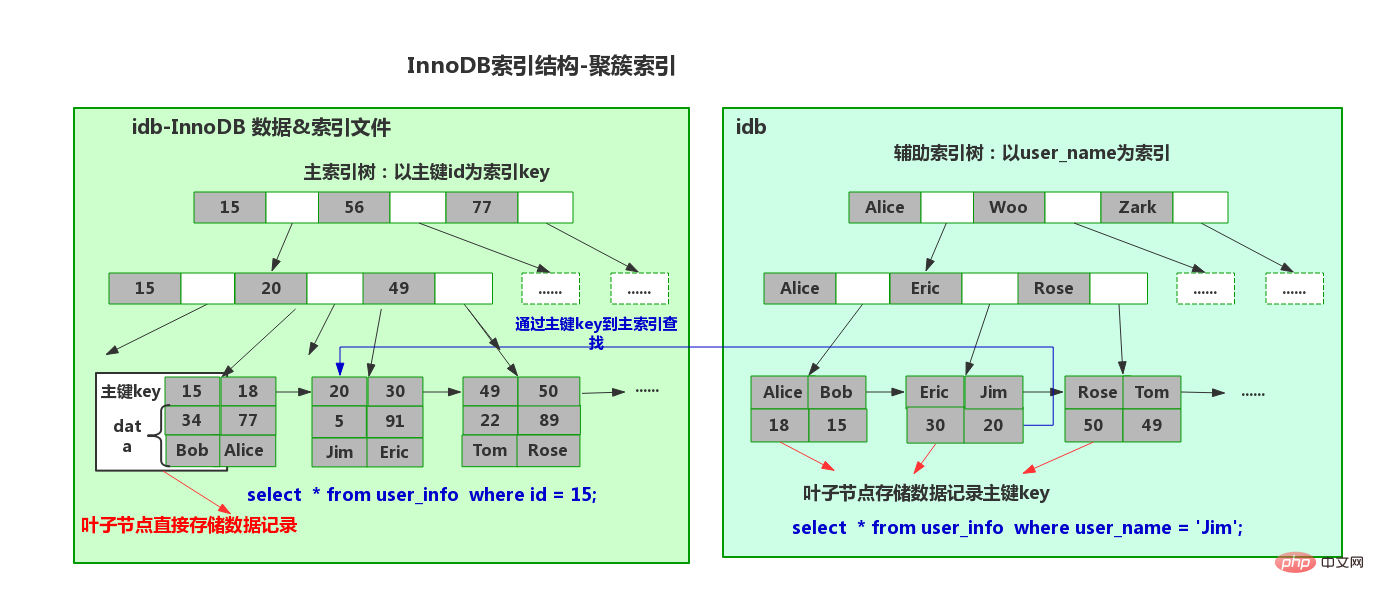
Insertion into clustered index
First of all, we know that in the InnoDB storage engine, the primary key is the unique identifier of the row (that is, we often Clustered index). We usually insert data incrementally according to the primary key, so the clustered index is sequential and does not require random reading from the disk.
For example, table:
CREATE TABLE test(
id INT AUTO_INCREMENT,
name VARCHAR(30),
PRIMARY KEY(id)
);复制代码
Copy after login
As above, I created a primary key id, which has the following characteristics:
- The Id column is auto-increasing
- When a NULL value is inserted into the Id column, its value will be incremented due to AUTO_INCREMENT
- At the same time, the row records in the data page are stored in order according to the id value
Generally, due to The orderliness of the clustered index does not require random reading of data in the page, because this type of sequential insertion is very fast.
But if you insert the column ID into data such as UUID, then your insertion will be as random as a non-clustered index. It will cause your B tree structure to keep changing, and the performance will inevitably be affected.
Insertion of non-clustered index
Many times our table will have many non-clustered indexes. For example, I query according to the b field, and the b field is not unique. As shown in the following table:
CREATE TABLE test(
id INT AUTO_INCREMENT,
name VARCHAR(30),
PRIMARY KEY(id),
KEY(name)
);复制代码
Copy after login
Here I created an x table, which has the following characteristics:
- There is a clustered index id
- There is a non-unique non-clustered index Index name
- When inserting data, the data pages are stored in order according to the primary key id
- The data insertion of the auxiliary index name is not sequential
The non-clustered index is also the same It is a B-tree, but the leaf nodes store the primary key and name value of the clustered index.
Because there is no guarantee that the data in the name column is sequential, the insertion of the non-clustered index tree must not be sequential.
Of course, if the name column inserts time type data, the insertion of the non-clustered index is also sequential.
The arrival of Insert Buffer
It can be seen that the discrete nature of non-clustered index insertion leads to a decrease in insertion performance, so the InnoDB engine designed the Insert Buffer to improve insertion performance. .
Let me take a look at how to insert using Insert Buffer:
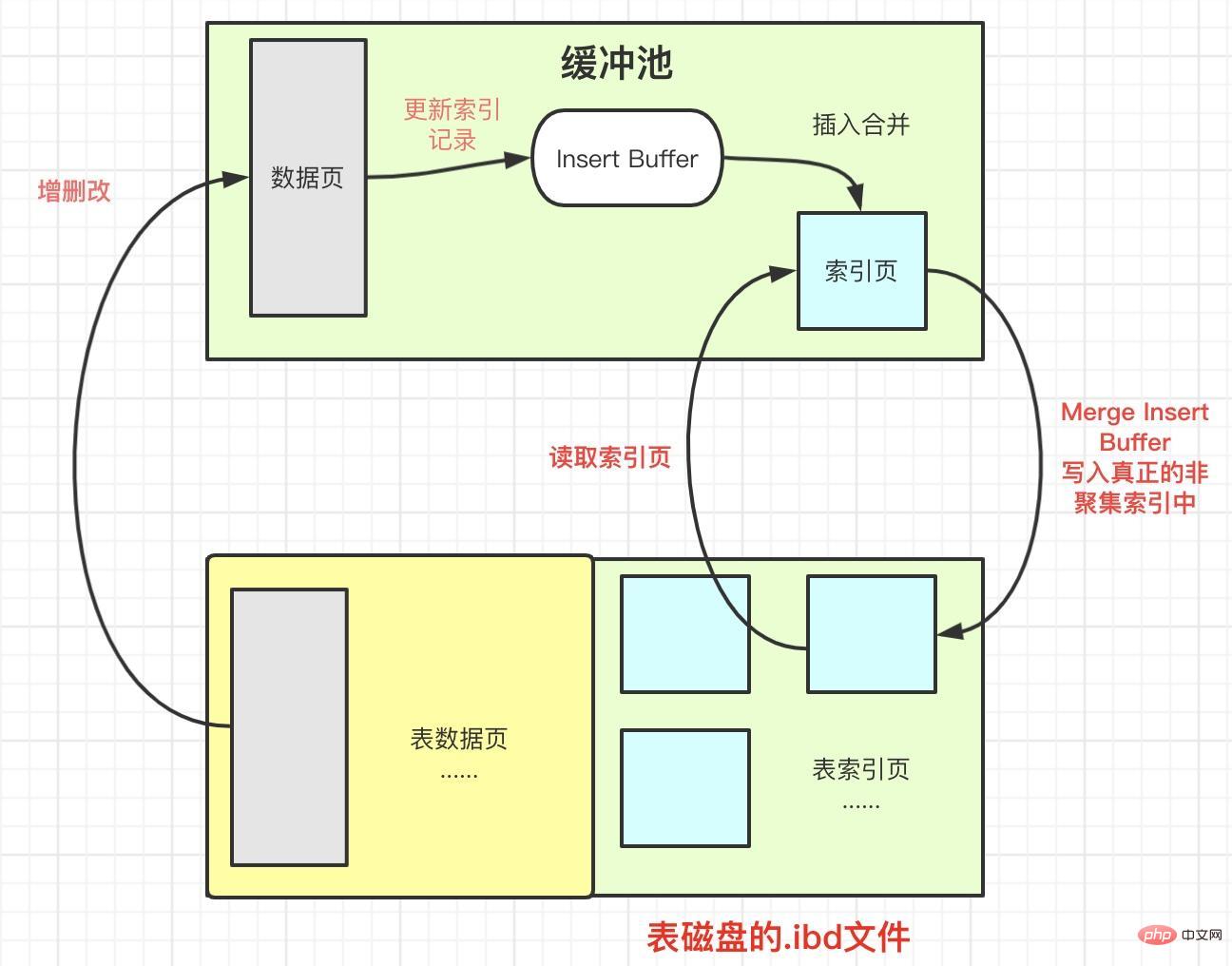
Firstly, for the insert or update operation of non-clustered index, Instead of inserting directly into the index page each time, it first determines whether the inserted non-clustered index page is in the buffer pool.
If it is there, insert it directly; if it is not there, put it into an Insert Buffer object first.
It feels to the outside as if the tree has inserted the leaf nodes of the non-clustered index, but in fact they are stored in other locations
Perform Insert Buffer and auxiliary index pages with a certain frequency and situation The merge operation of child nodes usually merges multiple insertion operations together, which greatly improves the insertion performance of non-clustered indexes.
Insert Buffer的使用要求:
只有满足上面两个必要条件时,InnoDB存储引擎才会使用Insert Buffer来提高插入性能。
那为什么必须满足上面两个条件呢?
第一点索引是非聚集索引就不用说了,人家聚集索引本来就是顺序的也不需要你
第二点必须不是唯一(unique)的,因为在写入Insert Buffer时,数据库并不会去判断插入记录的唯一性。如果再去查找肯定又是离散读取的情况了,这样InsertBuffer就失去了意义。
Insert Buffer信息查看
我们可以使用命令SHOW ENGINE INNODB STATUS来查看Insert Buffer的信息:
-------------------------------------
INSERT BUFFER AND ADAPTIVE HASH INDEX
-------------------------------------
Ibuf: size 7545, free list len 3790, seg size 11336,
8075308 inserts,7540969 merged sec, 2246304 merges
...复制代码
Copy after login
使用命令后,我们会看到很多信息,这里我们只看下INSERT BUFFER 的:
merges:merged recs大约为1∶3,代表了Insert Buffer 将对于非聚集索引页的离散IO逻辑请求大约降低了2/3
Insert Buffer的问题
说了这么多针对于Insert Buffer的好处,但目前Insert Buffer也存在一个问题:
即在写密集的情况下,插入缓冲会占用过多的缓冲池内存(innodb_buffer_pool),默认最大可以占用到1/2的缓冲池内存。
占用了过大的缓冲池必然会对其他缓冲池操作带来影响
Insert Buffer的优化
MySQL5.5之前的版本中其实都叫做Insert Buffer,之后优化为 Change Buffer 可以看做是 Insert Buffer 的升级版。
插入缓冲( Insert Buffer)这个其实只针对 INSERT 操作做了缓冲,而Change Buffer 对INSERT、DELETE、UPDATE都进行了缓冲,所以可以统称为写缓冲,其可以分为:
Insert Buffer
Delete Buffer
Purgebuffer
总结:
Insert Buffer到底是个什么?
其实Insert Buffer的数据结构就是一棵B+树。
在MySQL 4.1之前的版本中每张表有一棵Insert Buffer B+树
目前版本是全局只有一棵Insert Buffer B+树,负责对所有的表的辅助索引进行Insert Buffer
这棵B+树存放在共享表空间ibdata1中
以下几种情况下 Insert Buffer会写入真正非聚集索引,也就是所说的Merge Insert Buffer
- 当辅助索引页被读取到缓冲池中时
- Insert Buffer Bitmap页追踪到该辅助索引页已无可用空间时
- Master Thread线程中每秒或每10秒会进行一次Merge Insert Buffer的操作
一句话概括下:
Insert Buffer 就是用于提升非聚集索引页的插入性能的,其数据结构类似于数据页的一个B+树,物理存储在共享表空间ibdata1中 。
相关免费学习推荐:mysql视频教程
The above is the detailed content of Introducing important knowledge points: InnoDB's insertion buffer. For more information, please follow other related articles on the PHP Chinese website!
































![[Web front-end] Node.js quick start](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



