

This article brings you relevant knowledge about mysql, which mainly introduces the related issues about how an update statement is executed. When executing the update update operation, the query cache related to the table is will be invalid, so the statement will clear all cached results on the table. Let’s take a look at it together. I hope it will be helpful to everyone.

Recommended learning: mysql tutorial
First create a table, and then insert three pieces of data :
CREATE TABLE T( ID int(11) NOT NULL AUTO_INCREMENT, c int(11) NOT NULL, PRIMARY KEY (ID)) ENGINE=InnoDB DEFAULT CHARSET=utf8 COMMENT='测试表';INSERT INTO T(c) VALUES (1), (2), (3);
Let the update operation be performed afterwards:
update T set c=c+1 where ID=2;
Before talking about the update operation, let’s take a look at the execution process of the sql statement in MySQL~
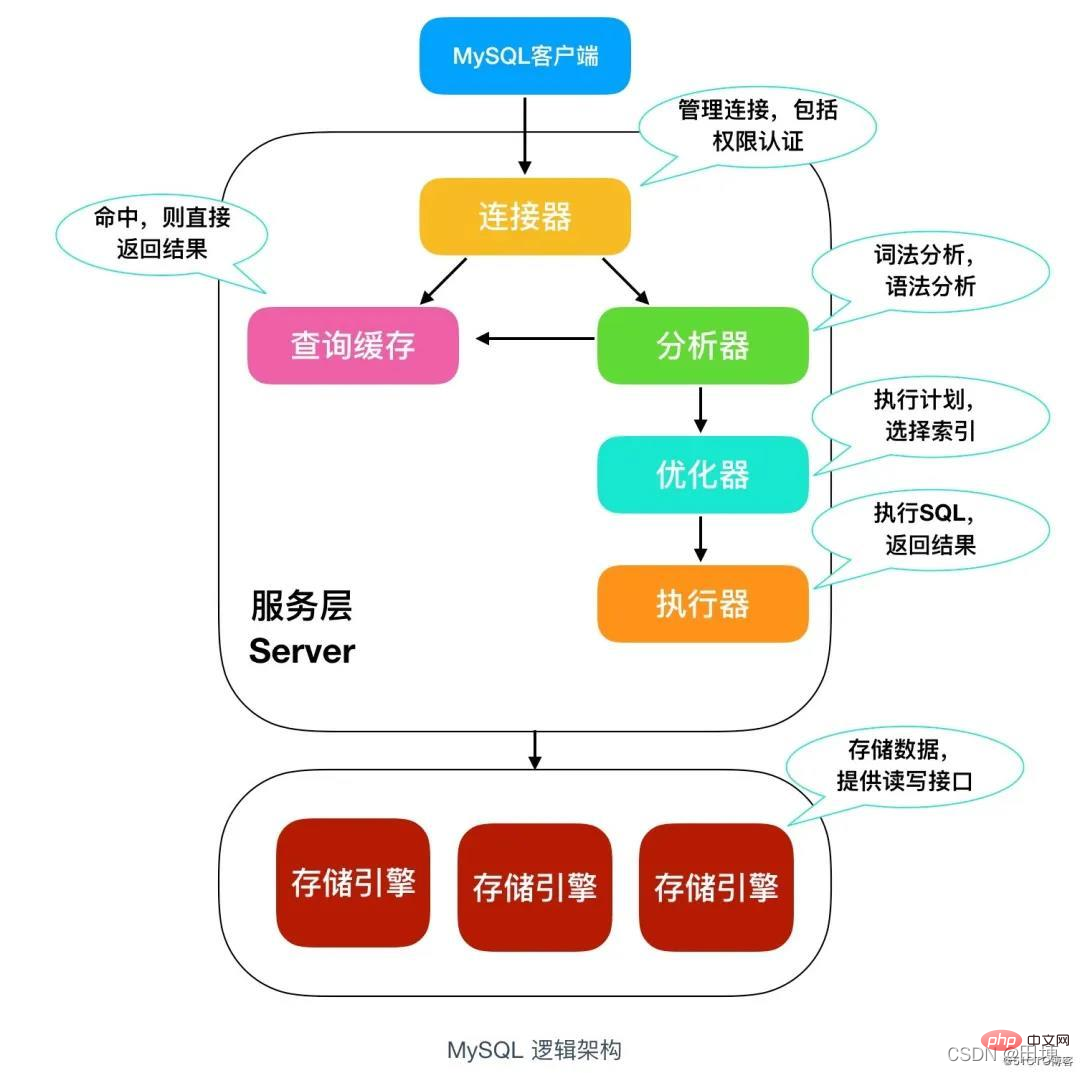
As shown in the figure: MySQL database is mainly divided into two levels: Service layer and Storage engine layer Service layer: The server layer includes connectors, query caches, analyzers, optimizers, and executors, including most of the core functions in MySQL. All cross-storage engine functions are also implemented in this layer, including stored procedures, triggers, views, etc. . Storage engine layer: The storage engine layer includes common MySQL storage engines, including MyISAM, InnoDB, and Memory. The most commonly used one is InnoDB, which is also the default storage engine of MySQL.
Connector: MySQL client login is required and a connector is required. Connect the user to the MySQL database, "mysql -u username -p password" to log in to MySQL. After completing the TCP handshake, the connector will verify the login identity based on the entered username and password.
Query cache: After receiving an execution request, MySQL will first search in the query cache to see whether this SQL statement has been executed and whether the statement has been executed before. And the results will be placed in memory in the form of key-value pairs. The key is the query statement, and the value is the result of the query. If this SQL statement can be found through the key, the SQL execution result will be returned directly. If it does not exist in the cache, the subsequent execution phase will continue. After the execution is completed, the execution results will be placed in the query cache. The advantage is high efficiency. However, the use of query cache is not recommended, because if a certain table is updated in MySQL, all query caches will become invalid. For databases that are frequently updated, the hit rate of query cache is very low. Note: In MySQL version 8.0, the query cache function has been deleted, and there is no query cache function.
Analyzer: is divided into lexical analysis and grammar Analysis
After analyzer After analysis, the SQL is legal, but before execution, it needs to be processed by the optimizer. The optimizer will determine which index to use and which connection to use. The role of the optimizer is to determine the most efficient execution plan.
In the execution phase, MySQL will first determine whether there is permission to execute the statement. If there is no permission, it will return an error of no permission; if there is permission, Just open the table and continue execution. When a table is opened, the executor will use the interface provided by the target engine according to the definition of the engine. For tables with indexes, the execution logic is similar.
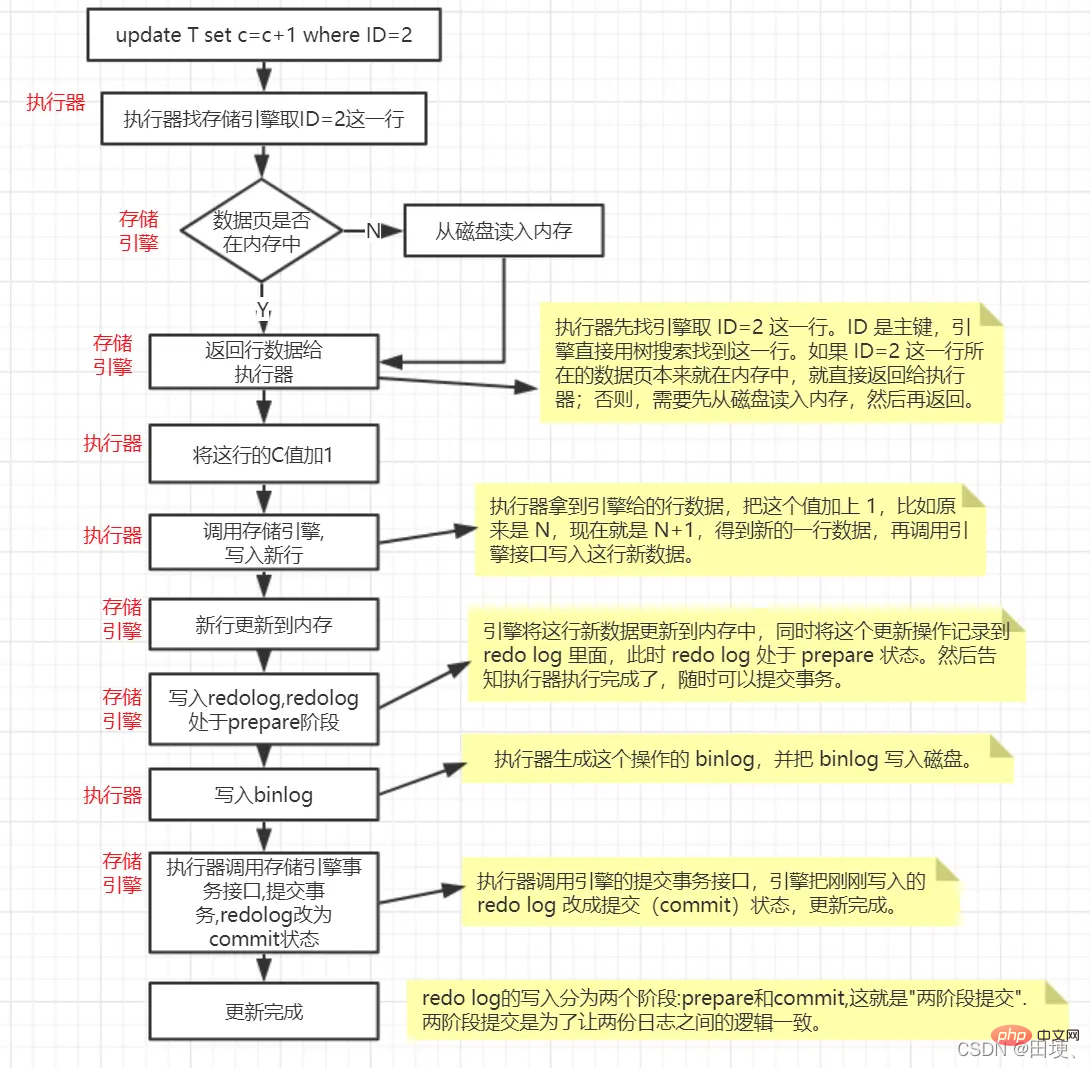
is executed. Update statement analysis
update T set c=c+1 where ID=2;
update updateoperation, the query cache related to this table will become invalid, so this statement will All cached results on table T are cleared. Next, the analyzer will go through syntax analysis and lexical analysis. After knowing that this is an update statement, the optimizer decides which index to use, and then the executor is responsible for the specific execution. It first finds the row and then updates it.
According to our usual idea, find this record, change its value, and save it. But let's dig into the details. Since it involves modifying data, it involves logs. The update operation involves two important log modules. redo log(redo log), bin log(archive log). These two logs in MySQL are also must-learn.
Write-Ahead Logging. The key point is that write the log first and then write to the disk. After listening to the above introduction to the redo log, friends may ask: Where is the redo log stored? , The database information is saved on the disk, and the redo log is also saved on the disk. Why should it be written to the redo log first and then to the database? , What should I do if the redo log is full of data? etc. Let’s answer these questions next.
The InnoDB engine first writes the records to the redo log. Wherever the redo log is, it is also on the disk. This is also a process of writing to the disk, but what is different from the update process is that the update process It is random IO on the disk, which is time-consuming. Writing redo log is sequential IO on the disk. Be efficient.
First of all, don’t worry that the redo log will run out of space, because it is recycled. For example, the redo log log is configured as a set of 4 files, each file is 1G. The process of writing it is as follows: 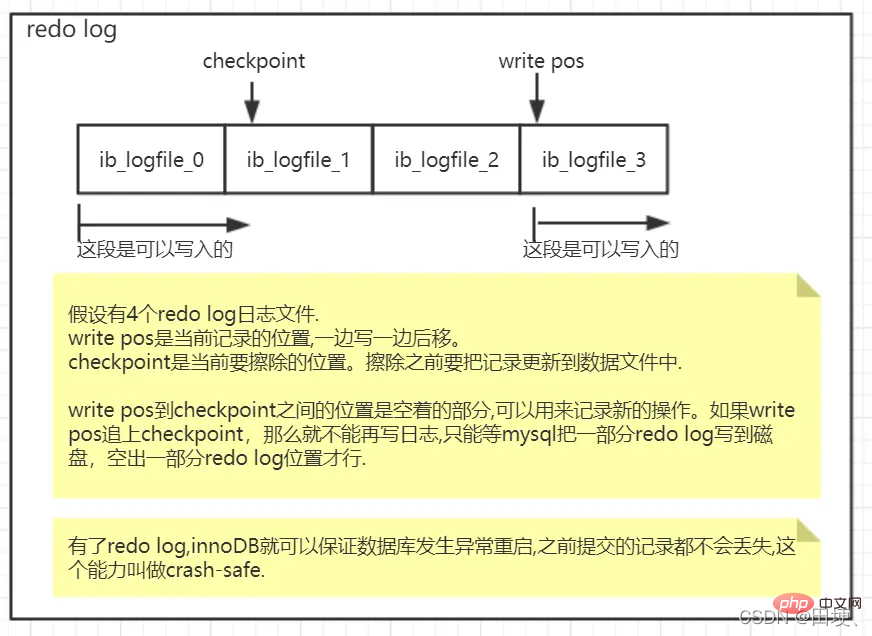
A brief summary: The redo log is a unique mechanism of the Innodb storage engine and can be used to deal with Abnormal recovery, Crash-safe, redo can ensure that when mysql restarts abnormally, uncommitted transactions will be rolled back and submitted transactions will be safely dropped into the database.
crash-safe: With redo log, InnoDB can ensure that even if the database restarts abnormally, previously submitted records will not be lost. This capability is called crash-safe .
The redo log is a log unique to the innoDB engine. Binlog is the log of the mysql server layer.
In fact, the bin log log appeared earlier than the redo log, because MySQL did not have an InnoDB storage engine at first, and it was MyISAM before 5.5. However, MyISAM does not have crash-safe capabilities, and binlog logs can only be used for archiving. InnoDB was introduced to MySQL in the form of a plug-in by another company. Since relying only on binlog does not have crash-safe capabilities, InnoDB uses another log system, that is, redo log, to achieve crash-safe capabilities.
redo log和bin log的总结redo log和bin log的区别:update T set c=c+1 where ID=2;
手动用begin开启事务,然后执行update语句,再然后执行commit语句,那上面的update更新流程之前 哪些是update语句执行之后做的,哪些是commit语句执行之后做的?
事实上,redo log在内存中有一个
redo log buffer,binlog 也有一个binlog cache.所以在手动开启的事务中,你执行sql语句,其实是写到redo log buffer和binlog cache中去的(肯定不可能是直接写磁盘日志,一个是性能差一个是回滚的时候不可能去回滚磁盘日志吧),然后当你执行commit的时候,首先要将redo log的提交状态游prepare改为commit状态,然后就要把binlog cache刷新到binlog日志(可能也只是flush到操作系统的page cache,这个就看你的mysql配置),redo log buffer刷新到redo log 日志(刷新时机也是可以配置的)。 如果你回滚的话,就只用把binlog cache和redo log buffer中的数据清除就行了。
如果redolog写入了,处于prepare状态,binlog还没写入,那么宕机重启后,redolog中的这个事务就直接回滚了。
如果redolog写入了,binlog也写入了,但redolog还没有更新为commit状态,那么宕机重启以后,mysql会去检查对应事务在binlog中是否完整。如果是,就提交事务;如果不是,就回滚事务。 (redolog处于prepare状态,binlog完整启动时就提交事务,为啥要这么设计? 主要是因为binlog写入了,那么就会被从库或者用这个binlog恢复出来的库使用,为了数据一致性就采用了这个策略)
redo log和binlog是通过xid这个字段关联起来的。
推荐学习:mysql教程
The above is the detailed content of Let's analyze how MySQL's update statement is executed.. For more information, please follow other related articles on the PHP Chinese website!

















![[Web front-end] Node.js quick start](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



