

This article brings you relevant knowledge about mysql, which mainly introduces the related issues of explain. The explain in Mysql can be called the performance optimization analysis tool of Mysql. We can use it to Analyzing the corresponding execution of SQL statements, I hope it will be helpful to everyone.

Recommended learning: mysql video tutorial
Database performance optimization is one of the basic skills that every back-end programmer must have , and explain in Mysql can be called Mysql's performance optimization analysis artifact. We can use it to analyze how the corresponding execution plan of the SQL statement is executed at the bottom of Mysql. It is useful for us to evaluate the execution efficiency of SQL and determine the performance of Mysql. The optimization direction is of great significance. However, many students are still confused about how to conduct in-depth execution analysis of existing SQL based on explain. Therefore, this article elaborates on locating database performance problems through explain analysis.
For each SQL, when it is sent to the Mysql server by the client, it will be analyzed by the Mysql optimizer component, mainly including some special processing, The execution sequence is changed to ensure optimal execution efficiency, and the corresponding execution plan is finally generated. The so-called execution plan actually refers to how to obtain data at the storage engine level. Whether to obtain data through an index or a full table scan, whether it is necessary to return the table after obtaining the data, etc. A simple understanding is the process of obtaining data in Mysql. .
Next, let’s take a closer look at what this explanation is and why it can guide us in performance optimization. When we execute the following statement:
explain SELECT * FROM user_info where NAME='mufeng'
After executing the explain statement, we will get the following execution results. This 12 fields similar to the database table are actually a detailed description of the execution plan executed by Mysql. Let's take a closer look at what these 12 fields mean. Only by understanding their meanings can we understand how Mysql performs data queries.

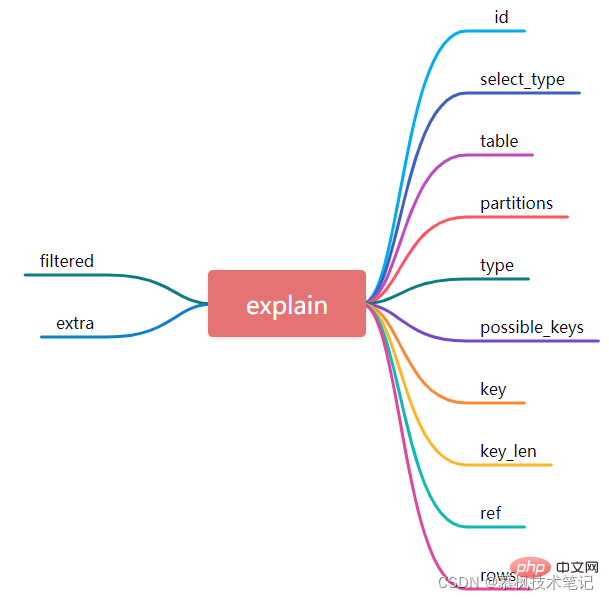
1. id
In fact, each select query will correspond to an id. It represents the order of SQL execution. The larger the id value is, the higher the execution priority of the corresponding SQL statement is. Some complex query SQL statements often contain some subqueries, then the id serial number will be incremented. If there is a nested query, we can find that the innermost query corresponds to the largest id, so it will be executed first.

As shown in the figure above, in the SQL query statement, the id of the first execution plan is 1, the id of the second execution plan is 2, and the execution with id 1 The table corresponding to the plan is order, and the table corresponding to the execution plan with ID 2 is user_info. Combined with the SQL statement, we know that the subquery select id from user_info is executed first, and then the data query about the table order is executed.
2. select_type
select_type indicates what type of query corresponds to the execution plan. Common query types mainly include ordinary queries, joint queries, and subqueries. SIMPLE (the query statement is a simple query and does not contain subqueries), PRIMARY (when the query statement contains subqueries, it corresponds to the outermost query type), UNION (the query type corresponding to the select statement that appears after union will mark this type), SUBQUERY (subquery will be marked as this type), DEPENDENT SUBQUERY (depends on the outer query)

##3, table
table represents the table name and indicates which table to query. Of course, it is not necessarily the name of the real table, it may be an alias of the table or a temporary table.4, partitions
partitions represents the concept of partition, which means that when querying, if the corresponding table will be a dead partition table, Then the specific partition information will be displayed here.5. type
type is a very core attribute that needs to be mastered. It indicates the current method of accessing the database table.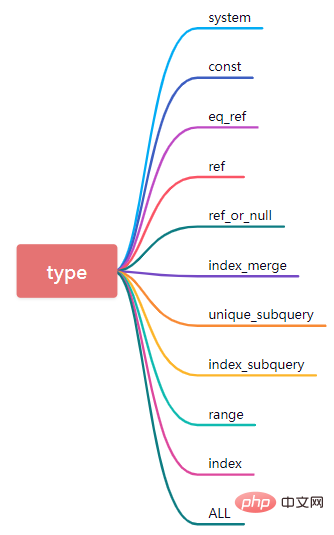
The table has only one row (equivalent to the system table), the data volume is small, and the query speed is very fast. System is a special case of the const type.
(2) const
If type is const, it means that the primary key or unique index is hit during data query. This type of data query is very fast.

(3) eq_ref
In the process of data query, if the SQL statement can be based on a clustered index or non-null in the case of table connection The unique index of the value remembers the data scan, then the value corresponding to type will be displayed as eq_ref.
(4)ref
When querying data, if the index hit is a secondary index and not a unique index, the test query speed will be very fast, but the type is ref. In addition, if it is a multi-field joint index, then according to the leftmost matching principle, equality comparison of fields in multiple consecutive columns starting from the leftmost side of the joint index is also a ref type.

(5) ref_or_null
This connection type is similar to ref, except that MySQL will additionally search for rows containing NULL values.
(7)unique_subquery
The set of subquery conditions about in in the where condition
(8)index_subquery
Different from unique_subquery, used Non-unique index, can return duplicate values.
(9)range
Use the index to retrieve row data, and only retrieve row data within the specified range. In other words, data is retrieved in a specified range for an indexed field. When using bettween...and, <, >, <=, in and other conditional query types in the where statement, the type is range.

(10) index
Index and ALL actually read the entire table. The difference is that index reads by traversing the index tree, while ALL reads from the hard disk. read in.
(11)all
Traverse the entire table for data matching. The data query performance at this time is the worst.
6. possible_keys
indicates which indexes can be selected by the Mysql optimizer, that is, what index candidates are there.
7, key
The index actually selected in possible_keys
8, key_len
indicates the length of the index, which is related to the actual field attributes and whether it is null.
9, ref
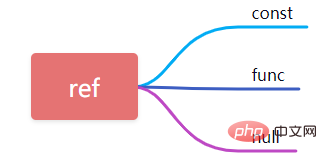
#When using fields for constant equivalent query, ref here is const, when used in query conditions If there is no expression or function, the ref will be displayed as func, and the others will be displayed as null.
10, rows
The rows column shows the number of rows that MySQL thinks it must check when executing the query. The fewer rows, the more efficient!
11. filtered
filtered This is a percentage value, the percentage of the number of records in the table that meet the conditions. To put it simply, this field represents the proportion of the remaining records that meet the conditions after filtering the data returned by the storage engine.
12, extra
Extra information will not be displayed in other columns but will be displayed in this column.
(1) Using index
When performing data query, the database uses a covering index, that is, the queried column is covered by the index, and the query speed will be very fast when using the covering index. Instead of using select *, use select phone_number, which will use the covering index.

(2) Using where
When querying, no available index is found, and then the required data is obtained through where condition filtering, but it should be noted that there is no Not all queries with where statements will display Using where.

(3) Using temporary
means that the query results need to be stored in a temporary table, which is generally used when sorting or grouping queries.
(4) Using filesort
This type indicates that the specified sorting operation cannot be completed using the index, that is, the ORDER BY field does not actually have an index, so this type of SQL needs to be optimized.
上文中我们阐述了explain在分析SQL语句时,可以通过12个属性来分析SQL的大致执行过程,并以此来判断SQL存在的性能问题。那么接下来我们通过一个实际的例子,来具体看下如何结合explain来实现SQL的性能分析。
其实所谓的Mysql性能问题,大部分都指的是平台出现了慢查询问题。慢查询实际上是可以通过配置进行记录的,把执行时间超过某个设定的阈值的sql都记录下来,当出现问题的时候可以通过记录的慢查询日志进行问题的定位。但是有的时候,出现大量慢查询会导致数据库连接给占满,导致整个平台的出现异常。
实际上我们在产品评价表product_evaluation中是建立了索引的,正常来说应该是可以使用到对应的索引字段进行查询的。但是实际上查询耗时有几十秒的时间,远远超过我们的预期。那我们猜测是不是由于某种原因导致Mysql优化器没有选择对应的索引进行数据检索,最后造成慢查询的发生。到底执行计划是怎样的,还是得借助于explain来看下。

如上文所说,虽然explain有12个字段属性帮助我们进行执行计划的分析,但是实际上常用的核心字段也就几个。我们可以看的出来在possible_key中实际上包含了我们设置的索引的,但是实际上Mysql却选择了PRIMARY作为其实际使用的。那么问题来了,为什么明明设置了索引,但是实际并没有用上,呗Mysql吃了吗?另外为什么之前的业务中没有出现这个问题,而现在出现了?我们需要进行进一步的分析。
我们所建立的idx_evaluation_type实际上是一个二级索引(叶子节点是主键id),对于数千万一张的大表来说,实际上这个二级索引也是非常大的,而且这个字段本身的值就三个,变化不大。因此Mysql的优化器在分析这个SQL的时候发现,如果按照SQL中的索引来获取数据后再根据where条件进行筛选,筛选后的数据还需要回表到聚簇索引中获取实际的数据。
假如通过二级索引筛选出来的数据有几万条,而后还需要进行排序,这些操作都是基于临时磁盘我恩建进行的,Mysql判断这种方式的性能可能会很差,因此优化器放弃了原有的数据查询方式,直接通过主键id对应的聚簇索引来进行数据的获取,因为id本身就是有序的。
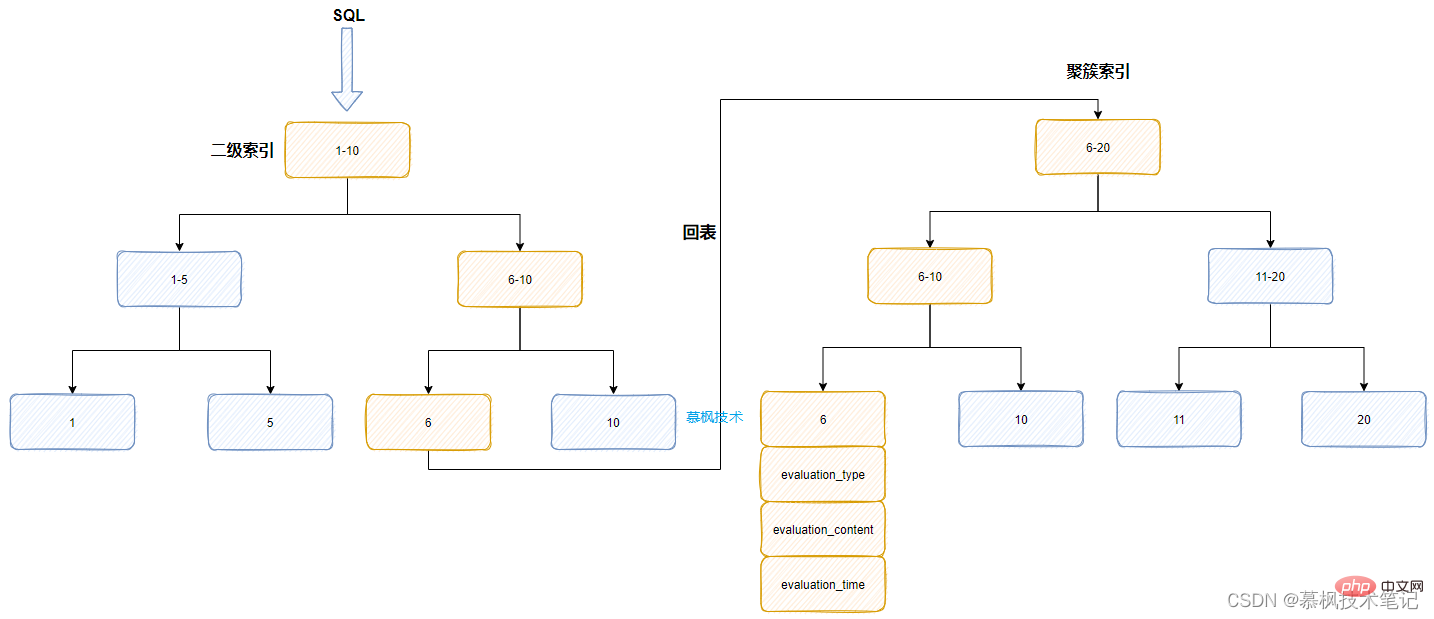
那么知道了查询慢的原因,我们应该怎么进行优化呢?实际上可以在SQL语句中增加force idnex,强制Mysql使用我们设置的二级索引。
SELECT * FROM product_evaluation force index(idx_product_id)WHERE product_id =1 and evaluation_type='GOOD' ORDER BY id desc LIMIT 200
通过上文对于explain使用的介绍,大家在遇到慢SQL问题的时候,可以先通过explain来进行初步的分析,主要明确SQL在Mysql中实际的执行过程是怎样的,如果查询字段没有索引则增加索引,如果有索引就要分析为什么没有用到索引。只要明确具体的执行过程,我们才能确定具体的查询优化方案。
推荐学习:mysql视频教程
The above is the detailed content of Completely master Mysql explain. For more information, please follow other related articles on the PHP Chinese website!


















![[Web front-end] Node.js quick start](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



