

Thinkphp 3.2 中词分词 加权搜寻

Thinkphp 3.2 中词分词 加权搜索
原文地址:http://www.cnblogs.com/kekukele/p/4544349.html
前段时间,利用业余时间做了一个磁力搜索的网站Btdog,其中使用到了简单的中文分词与加权搜索,在这里分享给大家,供大家参考。
在我的网站中,中文分词使用的是SCWS分词系统,这个分词系统提供PHP两种使用方式:一种是你可以采用源码安装,具体安装步骤请参考这里;
另外一种是使用其提供的API接口,具体方法参考这里。
下面,我们假设你已经掌握了SCWS的使用,事实上,其使用也非常简单,若你不会其使用,也不影响本文下面的阅读。
SCWS系统中其每个分好的词包括以下属性/键值:
- word 词的内容
- off 该词在未分词文本中的偏移位置
- idf 该词的 IDF 值
- attr 词性 (北大标注格式) 参见这里。
在这里我们重点介绍下分词属性中的idf,这个是我们在我们的分词算法中需要用到的。
IDF全称inverse document frequency(逆向文档频率)是一个词普遍重要性的度量,某一特定词的IDF值,用总文件数除以包含该词的文章数量,再将得到的商取对数(log)。计算公式:IDF = log(D/Dt),D为文章总数,Dt为该词出现的文章数量。IDF的主要思想是:如果包含词条t的文档越少,也就是Dt越小,IDF越大,则说明词条t具有很好的类别区分能力。
我们举例说明下,如 搜索内容 ”复仇者的联盟“,其SCWS的分词结果如下:

可以看出,其分词结果中,关键词”复仇者“的idf为9.06,最具区分能力,而关键词”的“的idf值为0,基本没有区分能力,”联盟“的idf为4.34也具有较强的区别能力。因此,我们在我们的分词搜索中,可以简单地使用idf值作为加权排序的依据。
在scws分词系统中,其idf的取值为0-10,因此在我们下面给出的算法中,我们把内容全文匹配的权重设为10,即最大。其他分词后关键词的权重值设为其idf值,然后根据权重大小将结果逆序排列。这要我们就实现了简单的中文分词加权排序。核心代码具体如下:
<em id="__mceDel"><em id="__mceDel"> [email protected]:需要分词的内容<em id="__mceDel"> <br>//Return:mysql查询条件字符串,加权排序字符串,关键词</em> <br> <span style="color: #0000ff;">private</span> <span style="color: #0000ff;">function</span> split_words(<span style="color: #800080;">$text</span><span style="color: #000000;">){ </span><span style="color: #800080;">$split_words</span> =<span style="color: #000000;"> scws_new(); </span><span style="color: #800080;">$split_words</span>->set_charset('utf-8'<span style="color: #000000;">); </span><span style="color: #800080;">$split_words</span>->set_ignore(<span style="color: #0000ff;">true</span><span style="color: #000000;">); </span><span style="color: #800080;">$split_words</span>->set_dict('/usr/local/scws/etc/dict.utf8.xdb'<span style="color: #000000;">); </span><span style="color: #800080;">$split_words</span>->set_rule('/usr/local/scws/etc/rules.utf8.ini'<span style="color: #000000;">); </span><span style="color: #800080;">$split_words</span>->send_text(<span style="color: #800080;">$text</span><span style="color: #000000;">); </span><span style="color: #800080;">$weight</span>=10<span style="color: #000000;">; </span><span style="color: #800080;">$condition</span>['where'] = "name LIKE '%".<span style="color: #800080;">$text</span>."%'"<span style="color: #000000;">; </span><span style="color: #800080;">$condition</span>['order'] = "(CASE WHEN name LIKE '%".<span style="color: #800080;">$text</span>."%' THEN <span style="color: #800080;">$weight</span> ELSE 0 END)"<span style="color: #000000;">; //设置全文匹配最大权重</span> <span style="color: #0000ff;">while</span> (<span style="color: #800080;">$words_result</span> = <span style="color: #800080;">$split_words</span>-><span style="color: #000000;">get_result()) { </span><span style="color: #0000ff;">foreach</span>(<span style="color: #800080;">$words_result</span> <span style="color: #0000ff;">as</span> <span style="color: #800080;">$word_arr</span><span style="color: #000000;">){</span> <span style="color: #800080;">$condition</span>['where'] .= " OR name LIKE '%".<span style="color: #800080;">$word_arr</span>['word']."%'"<span style="color: #000000;">;<br> //设置分词后关键词的权重为其idf的值<br></span> <span style="color: #800080;">$condition</span>['order'] .= " + (CASE WHEN name LIKE '%".<span style="color: #800080;">$word_arr</span>['word']."%' THEN ".<span style="color: #800080;">$word_arr</span>['idf']." ELSE 0 END)"<span style="color: #000000;">; </span> <span style="color: #800080;">$condition</span>['keywords'][<span style="color: #800080;">$cnt</span>++] = <span style="color: #800080;">$word_arr</span>['word'<span style="color: #000000;">]; } } </span><span style="color: #800080;">$split_words</span>-><span style="color: #000000;">close(); </span><span style="color: #0000ff;">return</span> <span style="color: #800080;">$condition</span><span style="color: #000000;">; }</span></em></em>当然,更复杂的分词还要考虑词的词频TF,不过即使简单的这样,我们也基本能达到比较好的效果了,具体效果,大家可以到http://btdog.com.cn体验下。

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

Video Face Swap
Swap faces in any video effortlessly with our completely free AI face swap tool!

Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics
 1672
1672
 14
1428
52
1332
25
1276
29
1256
24
14
1428
52
1332
25
1276
29
1256
24

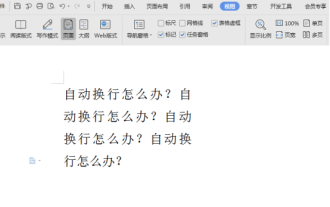 How to cancel automatic word wrapping in word
Mar 19, 2024 pm 10:16 PM
How to cancel automatic word wrapping in word
Mar 19, 2024 pm 10:16 PM
When editing content in a word document, lines may automatically wrap. If no adjustment is made at this time, it will have a great impact on our editing and make people very headache. What is going on? In fact, it is a problem with the ruler. Below, I will introduce the solution to how to cancel automatic word wrapping in word. I hope it can help everyone! After opening a Word document and entering text, when you try to copy and paste, the text may jump to a new line. In this case, you need to adjust the settings to solve this problem. 2. To solve this problem, we must first know the cause of this problem. At this time we click View under the toolbar. 3. Then click the "Ruler" option below. 4. At this time we will find that a ruler appears above the document with several conical markers on it.
 Detailed explanation of how to display the ruler in Word and how to operate the ruler!
Mar 20, 2024 am 10:46 AM
Detailed explanation of how to display the ruler in Word and how to operate the ruler!
Mar 20, 2024 am 10:46 AM
When we use Word, in order to edit the content more beautifully, we often use rulers. You should know that the rulers in Word include horizontal rulers and vertical rulers, which are used to display and adjust the document's page margins, paragraph indents, tabs, etc. So, how do you display the ruler in Word? Next, I will teach you how to set the ruler display. Students in need should quickly collect it! The steps are as follows: 1. First, we need to bring up the word ruler. The default word document does not display the word ruler. We only need to click the [View] button in word. 2. Then, we find the option of [Ruler] and check it. In this way, we can adjust the word ruler! Yes or no
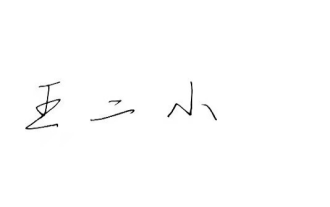 How to add handwritten signature to word document
Mar 20, 2024 pm 08:56 PM
How to add handwritten signature to word document
Mar 20, 2024 pm 08:56 PM
Word documents are widely used due to their powerful functions. Not only can various formats be inserted into Word, such as pictures and tables, etc., but now for the integrity and authenticity of the files, many files require a manual signature at the end of the document. It sounds like this How to solve complex problems? Today I will teach you how to add a handwritten signature to a word document. Use a scanner, camera or mobile phone to scan or photograph the handwritten signature, and then use PS or other image editing software to perform necessary cropping on the image. 2. Select "Insert - Picture - From File" in the Word document where you want to insert the handwritten signature, and select the cropped handwritten signature. 3. Double-click the handwritten signature picture (or right-click the picture and select "Set Picture Format"), and the "Set Picture Format" pops up.
 How to set page margins for Word
Mar 19, 2024 pm 10:00 PM
How to set page margins for Word
Mar 19, 2024 pm 10:00 PM
Among office software, Word is one of our most commonly used software. The text documents we produce are generally operated with Word. Some documents need to be submitted in paper version as required. Before printing, the layout must be set before it can be presented. produce better results. So the question is, how do you set page margins in Word? We have specific course explanations to help you solve your doubts. 1. Open or create a new word document and click the "Page Layout" menu on the menu bar. 2. Click the "Margins" button of the "Page Setup" option. 3. Select a commonly used page margin in the list. 4. If there are no suitable margins in the list, click "Custom Margins". 5. The "Page Setup" dialog box pops up, enter the "Margins" option respectively.
 How to draw a table in Word
Mar 19, 2024 pm 11:50 PM
How to draw a table in Word
Mar 19, 2024 pm 11:50 PM
Word is a very powerful office software. Compared with WPS, Word has more advantages in detail processing. Especially when the document description is too complex, it is generally more worry-free to use Word. Therefore, when you enter the society, you must learn some tips on using word. Some time ago, my cousin asked me a question like this. I often see other people drawing tables when using Word, and I feel very high-level. I laughed at that time. It seemed like high-level content, but actually it only took 3 steps to operate. Do you know how to draw a table in Word? 1. Open word, select the place where you want to insert the table, and find the "Insert" option in the upper menu bar. 2. Click the "Table" option, and densely packed small cubes will appear.
 Where is the shading setting in word?
Mar 20, 2024 am 08:16 AM
Where is the shading setting in word?
Mar 20, 2024 am 08:16 AM
We often use word for office work, but do you know where the shading settings are in word? Today I will share with you the specific operation steps. Come and take a look, friends! 1. First, open the word document, select a paragraph of text paragraph information that needs to be added with shading, then click the [Start] button on the toolbar, find the paragraph area, and click the drop-down button on the right (as shown in the red circle in the figure below) ). 2. After clicking the drop-down box button, in the pop-up menu options, click the [Border and Shading] option (as shown in the red circle in the figure below). 3. In the pop-up [Border and Shading] dialog box, click the [Shading] option (as shown in the red circle in the figure below). 4. In the filled column, select a color
 How to draw a dotted line in word
Mar 19, 2024 pm 10:25 PM
How to draw a dotted line in word
Mar 19, 2024 pm 10:25 PM
Word is a software that we often use in our office. It has many functions that can facilitate our operations. For example, for a large article, we can use the search function inside to find out that a word in the full text is wrong, so we can directly replace it. Make changes one by one; when submitting the document to your superiors, you can beautify the document to make it look better, etc. Below, the editor will share with you the steps on how to draw a dotted line in Word. Let's learn together! 1. First, we open the word document on the computer, as shown in the figure below: 2. Then, enter a string of text in the document, as shown in the red circle in the figure below: 3. Next, press and hold [ctrl+A] Select all the text, as shown in the red circle in the figure below: 4. Click [Start] on the top of the menu bar
 Specific steps to delete down arrow in Word!
Mar 19, 2024 pm 08:50 PM
Specific steps to delete down arrow in Word!
Mar 19, 2024 pm 08:50 PM
In daily office work, if you copy a piece of text from a website and paste it directly into Word, you will often see a [down arrow]. This [down arrow] can be deleted by selecting it, but if there are too many such symbols, So is there a quick way to delete all arrows? So today I will share with you the specific steps to delete the downward arrow in Word! First of all, the [Down Arrow] in Word actually represents [Manual Line Break]. We can replace all [Down Arrows] with [Paragraph Mark] symbols, as shown in the figure below. 2. Then, we select the [Find and Replace] option on the menu bar (as shown in the red circle in the figure below). 3. Then, click the [Replace] command, a pop-up box will pop up, click [Special Symbols]
