

This article mainly introduces about php parsing word and obtaining the pictures in the document, which has a certain reference value. Now I share it with everyone. Friends in need can refer to it
I was writing a function some time ago: using native PHP to obtain the content in word and import it into the website system. Because there are formulas, pictures, tables, etc. in the document, writing is more troublesome.
The general idea is to first convert the document formatted as doc in word into docx, and then use the preprocessing program to convert the formulas in the document into swf image format. Convert word to xml format, and then convert the content in xml to json format.
1. Understand the basics of xml
xml is an extensible markup Language is an important tool for Internet data transmission. XML can realize cross-Internet platforms without being restricted by programming languages and operating systems. It can be said to be a data carrier with the highest level pass on the Internet.
xml is the current technology used in processing structured document information, which helps shuttle structured issuance between servers, allowing developers to more conveniently control the storage and transmission of data
xml is a markup language used to mark electronic documents to make them structural. It can be used to mark data and define data types. It is a source language that allows users to define their own markup language. It is a subset of the standard general-purpose language and is well suited for web transmission.
2. Two different storage methods of word
Two storage formats of word documents: doc and docx
doc: Traditionally called word, it uses binary to store data
docx: That is word2007, uses xml to store data
Then the suffix is obviously in docx format, why is it in xml format?
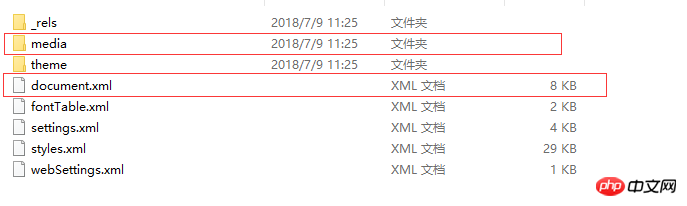
Select a test.docx, change the suffix name to .zip, and then unzip it to get the following directory structure:

So the docx you think is The document is actually a compressed file~
3. Understand DOM and PHP DOM XML parsing
DOM provides html and xml documents A standard set of objects, and a standard interface for accessing and manipulating these documents. XML DOM is a set of objects that defines a standard for documents. Using the PHP DOM extension, you can implement a series of operations on the DOM tree by PHP.
Use PHP DOM to read an XML document:
test.xml:
<?xml version="1.0" encoding="utf-8"?><teststore><test> <name>php dom test</name> <author>test-one</author></test><test> <title>php dom test 2</title> <author>test-two</author></test></teststore>
test.php:
<?php $doc = new DOMDocument();
$doc->load("test.xml"); //获取标签对象
$book=$doc->getElementsByTagName("test"); //输出第一个中的值
echo $book->item(0)->nodeValue;
echo "<br>----------------<br>";
$title=$doc->getElementsByTagName("name");
echo $title->item(0)->nodeValue;
echo "<br>----------------<br>"; //遍历所有book标签中的内容
foreach ($book as $note)
{
echo $note->nodeValue;
echo "<br>";
}Result:

#4. The definition format of xml in word
How is the data in word defined? ?
We will only introduce two files/folders:
One file is word/document.xml, which defines the content of the entire word document.
Another folder is word/media. This folder stores the multimedia content of the document. In other words, all the pictures, audio and video in the document are stored in this folder.
Overall structure definition in document.ml:
<w:document mc:ignorable="w14 w15 wp14" xmlns:m="http://schemas.openxmlformats.org/officeDocument/2006/math" xmlns:mc="http://schemas.openxmlformats.org/markup-compatibility/2006" xmlns:o="urn:schemas-microsoft-com:office:office" xmlns:r="http://schemas.openxmlformats.org/officeDocument/2006/relationships" xmlns:v="urn:schemas-microsoft-com:vml" xmlns:w="http://schemas.openxmlformats.org/wordprocessingml/2006/main" xmlns:w10="urn:schemas-microsoft-com:office:word" xmlns:w14="http://schemas.microsoft.com/office/word/2010/wordml" xmlns:w15="http://schemas.microsoft.com/office/word/2012/wordml" xmlns:wne="http://schemas.microsoft.com/office/word/2006/wordml" xmlns:wp="http://schemas.openxmlformats.org/drawingml/2006/wordprocessingDrawing" xmlns:wp14="http://schemas.microsoft.com/office/word/2010/wordprocessingDrawing" xmlns:wpc="http://schemas.microsoft.com/office/word/2010/wordprocessingCanvas" xmlns:wpg="http://schemas.microsoft.com/office/word/2010/wordprocessingGroup" xmlns:wpi="http://schemas.microsoft.com/office/word/2010/wordprocessingInk" xmlns:wps="http://schemas.microsoft.com/office/word/2010/wordprocessingShape" xmlns:wpscustomdata="http://www.wps.cn/officeDocument/2013/wpsCustomData">
<w:body>
<w:p>
<w:ppr>
<w:pstyle w:val="2">
</w:pstyle>
<w:keepnext w:val="0">
</w:keepnext>
<w:keeplines w:val="0">
</w:keeplines>
<w:widowcontrol>
</w:widowcontrol>
<w:suppresslinenumbers w:val="0">
</w:suppresslinenumbers>
<w:pbdr>
<w:top w:color="auto" w:space="0" w:sz="0" w:val="none">
</w:top>
<w:left w:color="auto" w:space="0" w:sz="0" w:val="none">
</w:left>
<w:bottom w:color="auto" w:space="0" w:sz="0" w:val="none">
</w:bottom>
<w:right w:color="auto" w:space="0" w:sz="0" w:val="none">
</w:right>
</w:pbdr>Document paragraph content:
<w:p>
<w:ppr>
<w:pstyle w:val="2">
</w:pstyle>
<w:keepnext w:val="0">
</w:keepnext>
<w:keeplines w:val="0">
</w:keeplines>
<w:widowcontrol>
</w:widowcontrol>
<w:suppresslinenumbers w:val="0">
</w:suppresslinenumbers>
<w:pbdr>
<w:top w:color="auto" w:space="0" w:sz="0" w:val="none">
</w:top>
<w:left w:color="auto" w:space="0" w:sz="0" w:val="none">
</w:left>
<w:bottom w:color="auto" w:space="0" w:sz="0" w:val="none">
</w:bottom>
<w:right w:color="auto" w:space="0" w:sz="0" w:val="none">
</w:right>
</w:pbdr>
<w:shd w:fill="FAFAFA" w:val="clear">
</w:shd>
<w:spacing w:after="150" w:afterautospacing="0" w:before="150" w:beforeautospacing="0" w:line="378" w:linerule="atLeast">
</w:spacing>
<w:ind w:firstline="0" w:left="0" w:right="0">
</w:ind>
<w:rpr>
<w:rfonts w:ascii="Verdana" w:cs="Verdana" w:hansi="Verdana" w:hint="default">
</w:rfonts>
<w:i w:val="0">
</w:i>
<w:caps w:val="0">
</w:caps>
<w:color w:val="404040">
</w:color>
<w:spacing w:val="0">
</w:spacing>
<w:sz w:val="21">
</w:sz>
<w:szcs w:val="21">
</w:szcs>
</w:rpr>
</w:ppr>
<w:r>
<w:rpr>
<w:rfonts w:ascii="Verdana" w:cs="Verdana" w:hansi="Verdana" w:hint="default">
</w:rfonts>
<w:i w:val="0">
</w:i>
<w:caps w:val="0">
</w:caps>
<w:color w:val="404040">
</w:color>
<w:spacing w:val="0">
</w:spacing>
<w:sz w:val="21">
</w:sz>
<w:szcs w:val="21">
</w:szcs>
<w:bdr w:color="auto" w:space="0" w:sz="0" w:val="none">
</w:bdr>
<w:shd w:fill="FAFAFA" w:val="clear">
</w:shd>
</w:rpr>
<w:t>
作者: Test </w:t>
</w:r>
</w:p>Image content definition:
<w:r>
<w:rpr>
<w:rfonts w:ascii="Verdana" w:cs="Verdana" w:hansi="Verdana" w:hint="default">
</w:rfonts>
<w:i w:val="0">
</w:i>
<w:caps w:val="0">
</w:caps>
<w:color w:val="404040">
</w:color>
<w:spacing w:val="0">
</w:spacing>
<w:sz w:val="21">
</w:sz>
<w:szcs w:val="21">
</w:szcs>
<w:bdr w:color="auto" w:space="0" w:sz="0" w:val="none">
</w:bdr>
<w:shd w:fill="FAFAFA" w:val="clear">
</w:shd>
</w:rpr>
<w:drawing>
<wp:inline distb="0" distl="114300" distr="114300" distt="0">
<wp:extent cx="5543550" cy="5543550">
</wp:extent>
<wp:effectextent b="0" l="0" r="0" t="0">
</wp:effectextent>
<wp:docpr descr="IMG_256" id="1" name="Picture 1">
</wp:docpr>
<wp:cnvgraphicframepr>
<a:graphicframelocks nochangeaspect="1" xmlns:a="http://schemas.openxmlformats.org/drawingml/2006/main">
</a:graphicframelocks>
</wp:cnvgraphicframepr>
<a:graphic xmlns:a="http://schemas.openxmlformats.org/drawingml/2006/main">
<a:graphicdata uri="http://schemas.openxmlformats.org/drawingml/2006/picture">
<pic:pic xmlns:pic="http://schemas.openxmlformats.org/drawingml/2006/picture">
<pic:nvpicpr>
<pic:cnvpr descr="IMG_256" id="1" name="Picture 1">
</pic:cnvpr>
<pic:cnvpicpr>
<a:piclocks nochangeaspect="1">
</a:piclocks>
</pic:cnvpicpr>
</pic:nvpicpr>
<pic:blipfill>
<a:blip r:embed="rId4">
</a:blip>
<a:stretch>
<a:fillrect>
</a:fillrect>
</a:stretch>
</pic:blipfill>
<pic:sppr>
<a:xfrm>
<a:off x="0" y="0">
</a:off>
<a:ext cx="5543550" cy="5543550">
</a:ext>
</a:xfrm>
<a:prstgeom prst="rect">
<a:avlst>
</a:avlst>
</a:prstgeom>
<a:nofill>
</a:nofill>
<a:ln w="9525">
<a:nofill>
</a:nofill>
</a:ln>
</pic:sppr>
</pic:pic>
</a:graphicdata>
</a:graphic>
</wp:inline>
</w:drawing>
</w:r>Conclusion:
<w:document> 定义整个文档的开始 <w:body> document的子节点,文档的主体内容 <w:p> body的子节点,一个段落,就是word文档中的段落 <w:r> p元素的子节点,一个Run定义了段落中具有相同格式的一段内容 <w:t> Run元素节点的子节点,就是文档的内容 <w:drawing> run元素的子节点,定义了一张图片 <w:inline> drawing子节点,具体应用没有研究 <a:graphic> 定义了图片内容 <pic:blipfill> graphic文档的子节点,定义了图片内容的索引.
Specifically speaking, if you use java, then XWPF parsing the docx document is to parse the xml document, obtain all the nodes and convert them into more useful attributes to provide API for use. In java Zhongpoi can get the resources corresponding to the picture based on this name, and the key to getting the location of the picture is here.
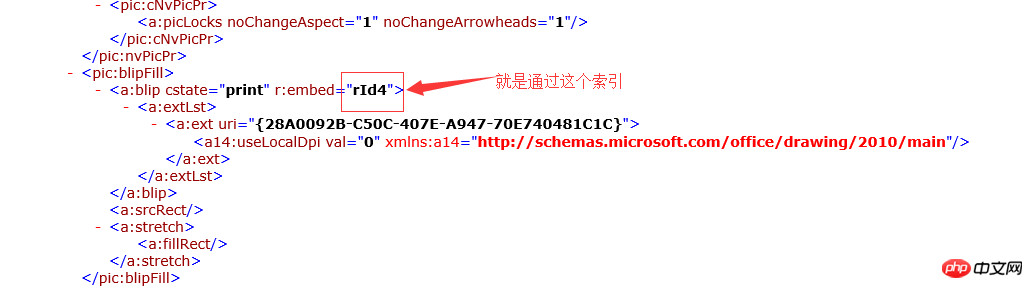
But unfortunately, I am using php~~~so we need to manually obtain the image through the relevant interface of php.
Let me talk about it The specific idea: Obtain the xml node of the docx document through PHP's built-in DOMDocument interface, traverse the xml node to find the node element that saves the image, and traverse down the image node Get the value of the r:embed index. Because the docx document is in a compressed package format, the docx document is traversed through the PHP built-in interface ZipArchive interface (essentially traversing the .zip compressed package), the corresponding image is found through the index, converted into binary data, and spliced The img tag displays image data in base64 format.
Convert to xml:
private $rels_xml;
private $doc_xml;
private function readZipPart($filename) {
$zip = new ZipArchive();
$_xml = 'word/document.xml';
$_xml_rels = 'word/_rels/document.xml.rels';
if (true === $zip->open($filename)) {
if (($index = $zip->locateName($_xml)) !== false) {
$xml = $zip->getFromIndex($index);
}
$zip->close();
} else die('non zip file');
if (true === $zip->open($filename)) {
if (($index = $zip->locateName($_xml_rels)) !== false) {
$xml_rels = $zip->getFromIndex($index);
}
$zip->close();
} else die('non zip file');
$this->doc_xml = new DOMDocument();
$this->doc_xml->encoding = mb_detect_encoding($xml);
$this->doc_xml->preserveWhiteSpace = false;
$this->doc_xml->formatOutput = true;
$this->doc_xml->loadXML($xml);
$this->doc_xml->saveXML();
$this->rels_xml = new DOMDocument();
$this->rels_xml->encoding = mb_detect_encoding($xml);
$this->rels_xml->preserveWhiteSpace = false;
$this->rels_xml->formatOutput = true;
$this->rels_xml->loadXML($xml_rels);
$this->rels_xml->saveXML();
}Determine whether it is a picture node:
if($paragraph->name === 'w:drawing') {
(strstr($ts,'…封…') != false || strstr($ts,'…线…') != false) ? $t .= '' : $t .= $this->analysisDrawing($paragraph);
}Get the picture index:
private function analysisDrawing(&$drawingXml) {
while($drawingXml->read()) {
if ($drawingXml->nodeType == XMLREADER::ELEMENT && $drawingXml->name === 'a:blip') {
$rId = $drawingXml->getAttribute('r:embed');
$rIdIndex = substr($rId,3);
return $this->checkImageFormating($rIdIndex);
}
}
}Display the picture file in the compressed package:
private function checkImageFormating($rIdIndex) {
$imgname = 'word/media/image'.($rIdIndex-8);
$zipfileName = __DIR__.DIRECTORY_SEPARATOR.'b'.DIRECTORY_SEPARATOR.'test.docx';
$zip=zip_open($zipfileName);
while($zip_entry = zip_read($zip)) {//读依次读取包中的文件
$file_name=zip_entry_name($zip_entry);//获取zip中的文件名
if(strstr($file_name,$imgname) != '' ) {
$a = ($rIdIndex-8 < 10) ? mb_substr($file_name,mb_strlen($imgname,"utf-8"),1, 'utf-8') : '';
if($rIdIndex-8 < 10 && $a != '.') continue;
if ($enter_zp = zip_entry_open($zip, $zip_entry, "r")) { //读取包中文件
$ext = pathinfo(zip_entry_name ($zip_entry),PATHINFO_EXTENSION);//获取图片文件扩展名
$content = zip_entry_read($zip_entry,zip_entry_filesize($zip_entry));//读取文件二进制数据
return sprintf('<img src="data:image/%s;base64,%s">', $ext, base64_encode($content));//利用base64_encode函数转换读取到的二进制数据并输入输出到页面中
}
zip_entry_close($zip_entry); //关闭zip中打开的项目
}
}
zip_close($zip);//关闭zip文件
}以上就是本文的全部内容,希望对大家的学习有所帮助,更多相关内容请关注PHP中文网!
相关推荐:
The above is the detailed content of How to use php to get the parsing of images in documents. For more information, please follow other related articles on the PHP Chinese website!
















![[Web front-end] Node.js quick start](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



