

This article mainly introduces the grayscale processing, binarization, noise reduction and tesserocr recognition of the python verification code recognition tutorial. It has a certain reference value. Now I share it with you. Friends in need can refer to it
Preface
An unavoidable problem when writing crawlers is the verification code. Now there are about 4 types of verification codes:
Image class
Sliding class
Click class
Voice Category
Today, let’s take a look at the image category. Most of these verification codes are a combination of numbers and letters, and Chinese characters are also used in China. On this basis, noise, interference lines, deformation, overlap, different font colors and other methods are added to increase the difficulty of recognition.
Correspondingly, verification code recognition can be roughly divided into the following steps:
Grayscale processing
Increase contrast (optional)
Binarization
Noise reduction
Tilt correction segmentation characters
Establish training database
Recognition
Because it is experimental in nature , the verification codes used in this article are all generated by programs rather than downloading real website verification codes in batches. The advantage of this is that there can be a large number of data sets with clear results.
When you need to obtain data in a real environment, you can use various large-code platforms to build a data set for training.
To generate the verification code, I use the Claptcha (local download) library. Of course, the Captcha (local download) library is also a good choice.
In order to generate the simplest purely digital, interference-free verification code, we first need to make some modifications to _drawLine on line 285 of claptcha.py. I directly let this function return None and then start generating verification. Code:
from claptcha import Claptcha
c = Claptcha("8069","/usr/share/fonts/truetype/freefont/FreeMono.ttf")
t,_ = c.write('1.png')You need to pay attention to the font path of ubuntu here, you can also download other fonts online for use. The verification code is generated as follows:
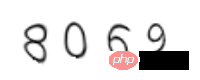
It can be seen that the verification code is deformed. For this type of simplest verification code, you can directly use Google's open source tesserocr to identify it.
First install:
apt-get install tesseract-ocr libtesseract-dev libleptonica-dev pip install tesserocr
Then Start recognition:
from PIL import Image import tesserocr p1 = Image.open('1.png') tesserocr.image_to_text(p1) '8069\n\n'
It can be seen that for this simple verification code, the recognition rate is already very high without basically doing anything. Taller. Interested friends can use more data to test, but I will not go into details here.
Next, add noise to the background of the verification code to see:
c = Claptcha("8069","/usr/share/fonts/truetype/freefont/FreeMono.ttf",noise=0.4)
t,_ = c.write('2.png')Generate the verification code as follows:

Identification:
p2 = Image.open('2.png') tesserocr.image_to_text(p2) '8069\n\n'
The effect is okay. Next, generate an alphanumeric combination:
c2 = Claptcha("A4oO0zZ2","/usr/share/fonts/truetype/freefont/FreeMono.ttf")
t,_ = c2.write('3.png') Generate a verification code as follows:
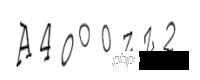
The third one is the lowercase letter o, the fourth one is the uppercase letter O, the fifth one is the number 0, the sixth one is the lowercase letter z, the seventh one is the uppercase letter Z, and the last one is the number 2. Is it true that human eyes have already knelt down! But now general verification codes do not strictly distinguish between upper and lower case. Let’s see what the automatic recognition looks like:
p3 = Image.open('3.png') tesserocr.image_to_text(p3) 'AMOOZW\n\n'
Of course a computer that can even kneel with human eyes is useless. . However, for some cases where the interference is small and the deformation is not serious, it is very simple and convenient to use tesserocr. Then restore line 285 of the modified claptcha.py _drawLine to see if interference lines are added.

p4 = Image.open('4.png') tesserocr.image_to_text(p4) ''
After adding an interference line, it cannot be recognized at all. So is there any way to remove the interference line?
Although the picture looks black and white, it still needs to be processed in grayscale. Otherwise, using the load() function, you will get an RGB tuple of a certain pixel instead of a single value. The processing is as follows:
def binarizing(img,threshold):
"""传入image对象进行灰度、二值处理"""
img = img.convert("L") # 转灰度
pixdata = img.load()
w, h = img.size
# 遍历所有像素,大于阈值的为黑色
for y in range(h):
for x in range(w):
if pixdata[x, y] < threshold:
pixdata[x, y] = 0
else:
pixdata[x, y] = 255
return imgThe processed picture is as follows:

You can see the processing Afterwards, the picture was sharpened a lot. Next, I tried to remove the interference lines using the common 4-neighborhood and 8-neighborhood algorithms. The so-called X neighborhood algorithm can refer to the nine-square grid input method on mobile phones. Button 5 is the pixel to be judged. Neighbor 4 is to judge up, down, left and right, and neighborhood 8 is to judge the surrounding 8 pixels. If the number of 255 among these 4 or 8 points is greater than a certain threshold, this point is judged to be noise. The threshold can be modified according to the actual situation.
def depoint(img):
"""传入二值化后的图片进行降噪"""
pixdata = img.load()
w,h = img.size
for y in range(1,h-1):
for x in range(1,w-1):
count = 0
if pixdata[x,y-1] > 245:#上
count = count + 1
if pixdata[x,y+1] > 245:#下
count = count + 1
if pixdata[x-1,y] > 245:#左
count = count + 1
if pixdata[x+1,y] > 245:#右
count = count + 1
if pixdata[x-1,y-1] > 245:#左上
count = count + 1
if pixdata[x-1,y+1] > 245:#左下
count = count + 1
if pixdata[x+1,y-1] > 245:#右上
count = count + 1
if pixdata[x+1,y+1] > 245:#右下
count = count + 1
if count > 4:
pixdata[x,y] = 255
return imgThe processed pictures are as follows:

好像……根本没卵用啊?!确实是这样的,因为示例中的图片干扰线的宽度和数字是一样的。对于干扰线和数据像素不同的,比如Captcha生成的验证码:

从左到右依次是原图、二值化、去除干扰线的情况,总体降噪的效果还是比较明显的。另外降噪可以多次执行,比如我对上面的降噪后结果再进行依次降噪,可以得到下面的效果:

再进行识别得到了结果:
p7 = Image.open('7.png') tesserocr.image_to_text(p7) '8069 ,,\n\n'
另外,从图片来看,实际数据颜色明显和噪点干扰线不同,根据这一点可以直接把噪点全部去除,这里就不展开说了。
第一篇文章,先记录如何将图片进行灰度处理、二值化、降噪,并结合tesserocr来识别简单的验证码,剩下的部分在下一篇文章中和大家一起分享。
相关推荐:
The above is the detailed content of Python verification code recognition tutorial: grayscale processing, binarization, noise reduction and tesserocr recognition. For more information, please follow other related articles on the PHP Chinese website!
















![[Web front-end] Node.js quick start](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



