

This article brings you relevant knowledge about python, which mainly introduces the related issues of xpath. XPath, the full name of XML Path Language, is XML path language. It is a language in XML. Language to find information in the document, I hope this helps.

Recommended learning: python tutorial
XPath, the full name of XML Path Language, is XML path language. It is a language in XML A language for finding information in documents. It was originally used to search XML documents, but it is also suitable for searching HTML documents.
The selection function of XPath is very powerful. It provides a very concise path selection expression. In addition, it also provides more than 100 built-in functions for matching strings, values, and times, as well as processing nodes and sequences. Almost all nodes we want to locate can be selected using XPath
To implement label positioning: instantiate an etree object, and the parsed page source code data needs to be loaded into the object.
Call the xpath method in the etree object combined with the xpath expression to achieve label positioning and content capture.
pip install lxml
lxml is a parsing library for python, supports HTML and XML parsing, supports XPath parsing method, and the parsing efficiency is very high
1. Load the source code data in the local html document into the etree object:
etree. parse(filePath)#你的文件路径
2. You can obtain the source code data from the Internet Load into this object
etree.HtML('page_ text')#page_ text互联网中响应的数据| Expression | Description |
|---|---|
| nodename | Select all child nodes of this node |
| / | means starting from the root node. It represents a level. |
| // | represents multiple levels. It can mean starting positioning from any position. |
| . | Select the current node |
| … | Select the parent node of the current node |
| @ | Select attributes |
| * | Wildcard, select all element nodes and element names |
| @* | Select all attributes |
| [@attrib] | Select all elements with the given attribute |
| [@attrib='value'] | Select all elements with a given attribute that has a given value |
| [tag ] | Select all direct child nodes with the specified element |
| [tag='text'] | Select all nodes with the specified element and the text content is text node |
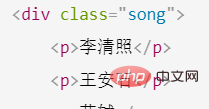
这是一个HTML的文档
<meta> <title>测试bs4</title> <p> </p><p>百里守约</p> <p> </p><p>李清照</p> <p>王安石</p> <p>苏轼</p> <p>柳宗元</p> <a> <span>this is span</span> 宋朝是最强大的王朝,不是军队的强大,而是经济很强大,国民都很有钱</a> <a>总为浮云能蔽日,长安不见使人愁</a> <img alt="python example detailed xpath analysis" > <p> </p>
从浏览器中打开是这样的
为了方便直观,我们对写个HTML文件进行本地读取进行测试
先来看子节点和子孙节点,我们从上往下找p这个节点,可以看到p的父节点是body,body父节点是html
定位到这个HTML的p对象中,看上面html源码,可以知道有三个p对象

我们通过三种不同的方法来输出这个节点的信息,可以看到输出的是三个一样的Element,也就是这三种方法实现的功能是一样的。
import requestsfrom lxml import etree
tree = etree.parse('test.html')r1=tree.xpath('/html/body/p') #直接从上往下挨着找节点r2=tree.xpath('/html//p')#跳跃了一个节点来找到这个p节点的对象r3=tree.xpath('//p')##跳跃上面所有节点来寻找p节点的对象r1,r2,r3>>([<element>,
<element>,
<element>],
[<element>,
<element>,
<element>],
[<element>,
<element>,
<element>])</element></element></element></element></element></element></element></element></element>如果我只想要p里面song这一个标签,就可以对其属性定位
当然返回的还是一个element
r4=tree.xpath('//p[@class="song"]')r4>>>[<element>]</element>如果我只想获得song里面的苏轼的这个标签
我们找到了song,/p可以返回里面的所有标签,
tree.xpath('//p[@class="song"]/p')>>[<element>,
<element>,
<element>,
<element>]</element></element></element></element>这个单独返回的苏轼的p标签,要注意的是这里的索引不是从0开始的,而是1
tree.xpath('//p[@class="song"]/p[3]')[<element>]</element>比如我想取杜牧这个文本内容
和上面一样,我们要定位到杜牧的这个a标签,首先要找到他的上一级 li ,这是第五个 li 里面的a所以就有了下面的写法,text()是把element转化为文本,当然上面的在后面加个text()都可以展示文本内容。
tree.xpath('//p[@class="tang"]//li[5]/a/text()')>>['杜牧']可以看到这个返回的是一个列表,如果我们想取里面的字符串,可以这样
tree.xpath('//p[@class="tang"]//li[5]/a/text()')[0]杜牧看一个更直接的,//li 直接定位到 li这个标签,//text()直接将这个标签下的文本提取出来。但要注意,这样会把所有的li标签下面的文本提取出来,有时候你并不想要的文本也会提取出来,所以最好还是写详细一点,如具体到哪个p里的li。
tree.xpath('//li//text()')['清明时节雨纷纷,路上行人欲断魂,借问酒家何处有,牧童遥指杏花村',
'秦时明月汉时关,万里长征人未还,但使龙城飞将在,不教胡马度阴山',
'岐王宅里寻常见,崔九堂前几度闻,正是江南好风景,落花时节又逢君',
'杜甫',
'杜牧',
'杜小月',
'度蜜月',
'凤凰台上凤凰游,凤去台空江自流,吴宫花草埋幽径,晋代衣冠成古丘']比如我想取下面这个属性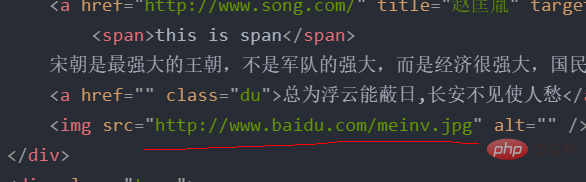
可以直接用@取属性
tree.xpath('//p[@class="song"]/img/@src')['http://www.baidu.com/meinv.jpg']或者如果我想取所有的href这个属性,可以看到tang和song的所有href属性
tree.xpath('//@href')['http://www.song.com/',
'',
'http://www.baidu.com',
'http://www.163.com',
'http://www.126.com',
'http://www.sina.com',
'http://www.dudu.com',
'http://www.haha.com']#导入必要的库import requestsfrom lxml import etree#URL就是网址,headers看图一url='https://sh.58.com/ershoufang/'headers={'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/83.0.4103.7 Safari/537.36'}#对网站发起请求page_test=requests.get(url=url,headers=headers).text# 这里是将从互联网上获取的源码数据加载到该对象中tree=etree.HTML(page_test)#先看图二的解释,这里li有多个,所里返回的li_list是一个列表li_list=tree.xpath('//ul[@class="house-list-wrap"]/li')#这里我们打开一个58.txt文件来保存我们的信息fp=open('58.txt','w',encoding='utf-8')#li遍历li_listfor li in li_list:
#这里 ./是对前面li的继承,相当于li/p...
title=li.xpath('./p[2]/h2/a/text()')[0]
print(title+'\n')
#把文件写入文件
fp.write(title+'\n')fp.close()图一: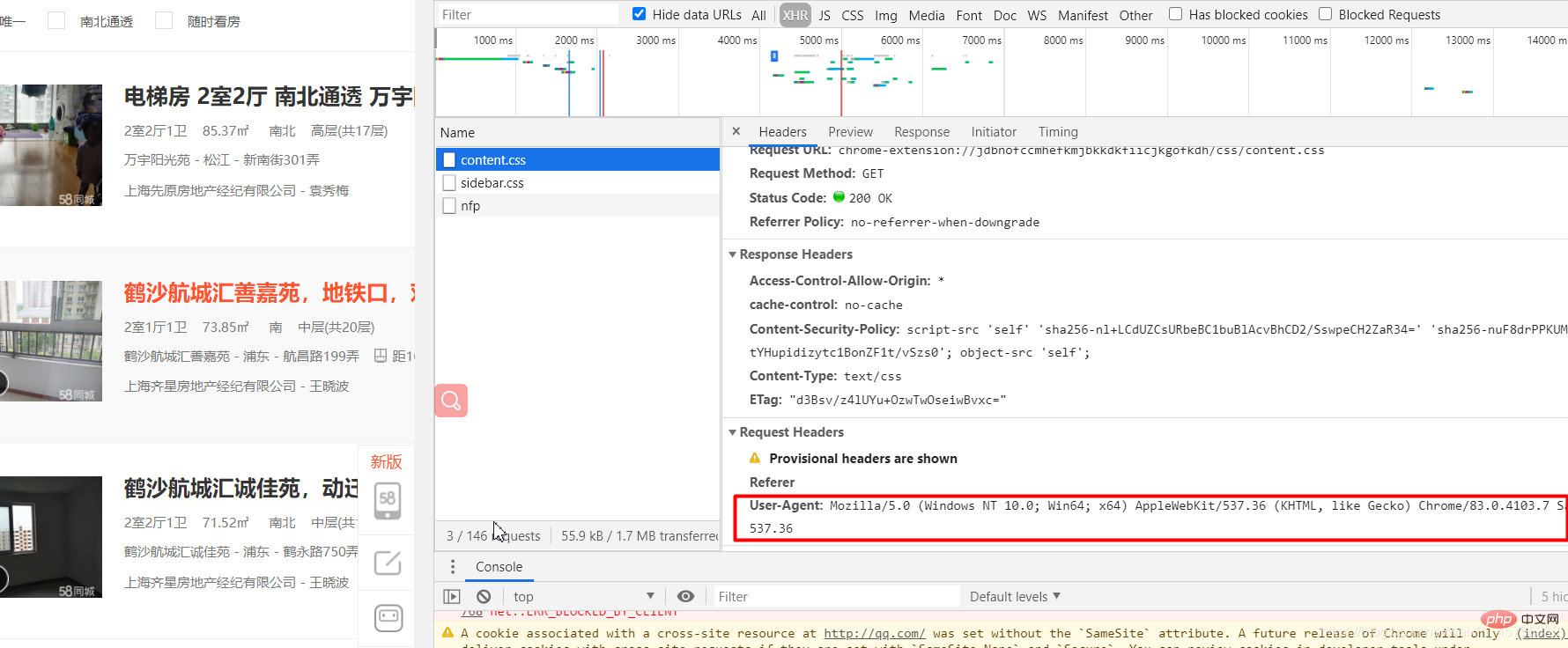
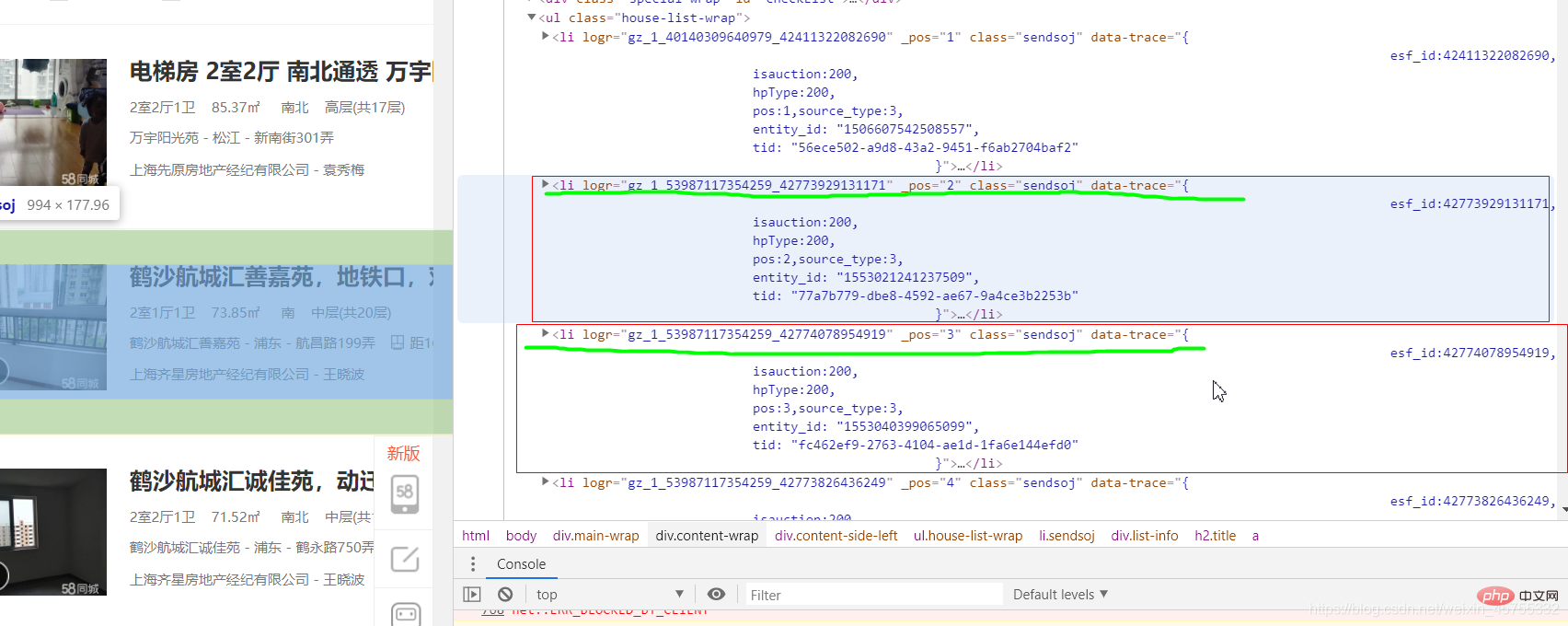
图二:.
这里我们要提取所有的房源信息,可以看到每个小节点的上一个节点都是一样的,我们要提取的是h2节点a里的房源信息,看图三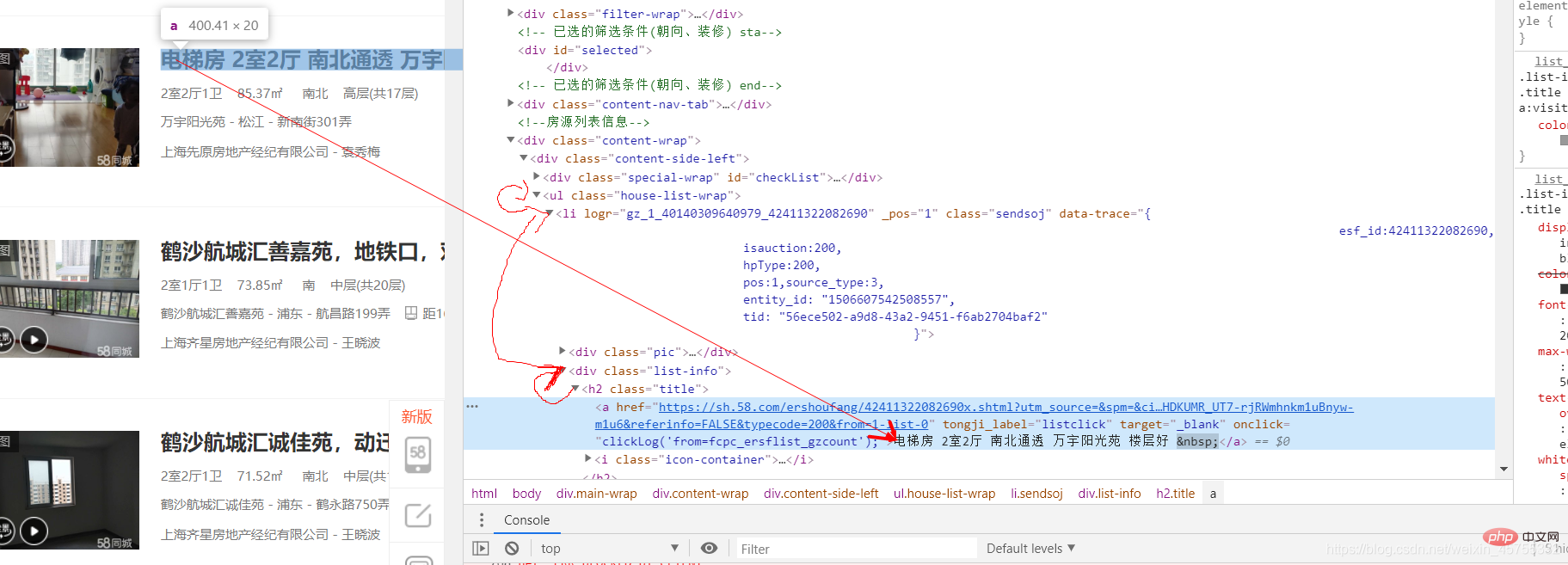
这里每个 /li 节点里面的子节点都是一样的,所以我们可以先找到所有的li节点,再往下找我们想要的信息
推荐学习:python教程
The above is the detailed content of python example detailed xpath analysis. For more information, please follow other related articles on the PHP Chinese website!

















![[Web front-end] Node.js quick start](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



