
This article will introduce you to the relevant knowledge of Redis and take you through master-slave replication, Sentinel, and clustering, so as to take your Redis level to a higher level!

Master-slave replication is the cornerstone of Redis distribution and the high availability of Redis Assure. In Redis, the server being replicated is called the master server (Master), and the server replicating the master server is called the slave server (Slave). [Related recommendations: Redis Video Tutorial]
The configuration of master-slave replication is very simple, and there are three ways (including IP-master server IP address/PORT -Main server Redis service port):
Configuration file - redis.conf file, configure slaveof ip port
command - enter Redis client executes slaveof ip port
Startup parameters——./redis-server --slaveof ip port
The master-slave replication mechanism of Redis was not as perfect as the 6.x version at the beginning, but it was iterated from version to version. It has generally gone through three versions of iteration:
Before 2.8
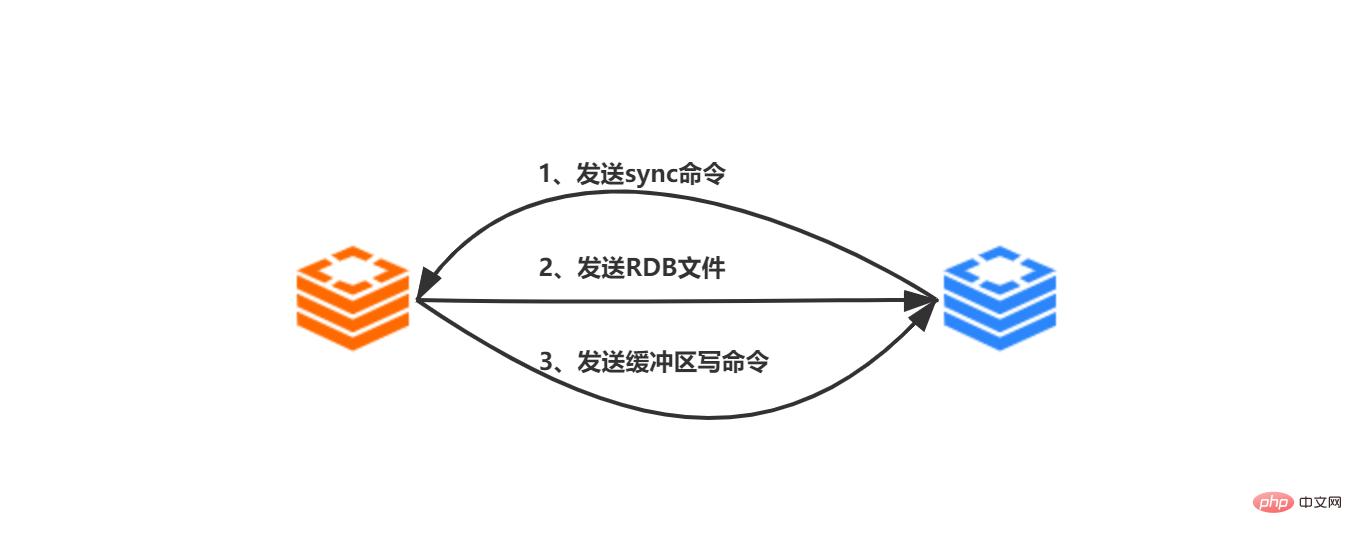
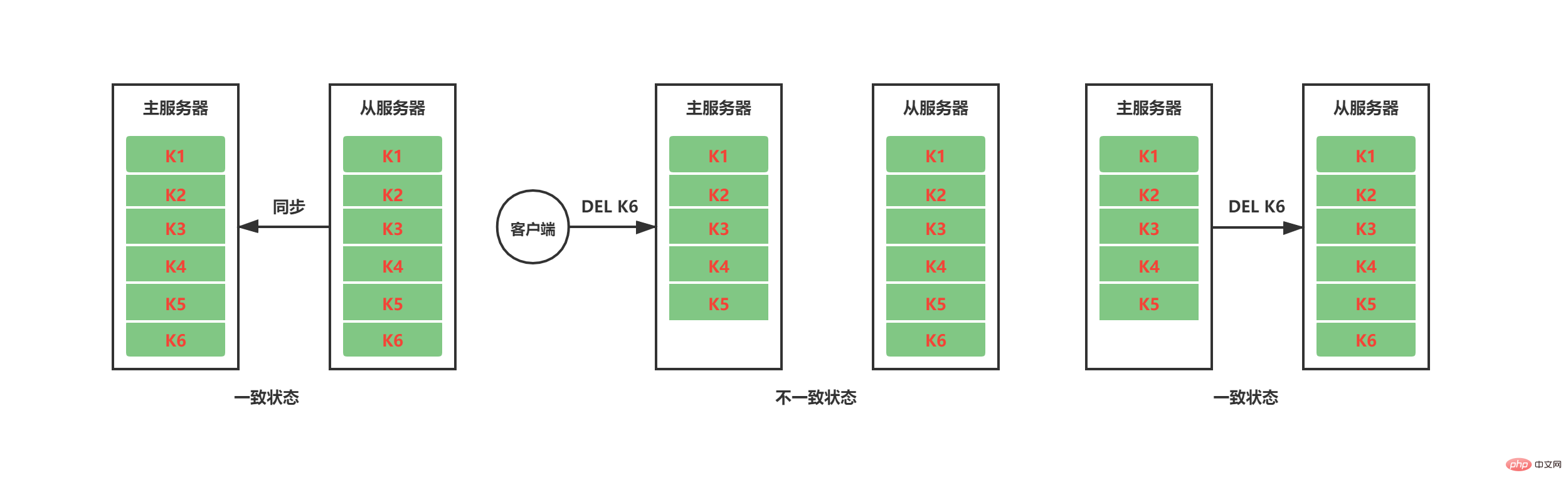
When the synchronization work is completed, the master-slave replication It is necessary to maintain the consistency of data status through command propagation. As shown in the figure below, after the synchronization work between the current master and slave servers is completed, the master service deletes K6 after receiving the DEL K6 instruction from the client. At this time, K6 still exists on the slave server, and the master-slave data status is inconsistent. In order to maintain the consistent status of the master and slave servers, the master server will propagate commands that cause its own data status to change to the slave server for execution. When the slave server also executes the same command, the data status between the master and slave servers will remain consistent.
 2.1.3 Defects
2.1.3 Defects
From the above, we can’t see any flaws in the master-slave replication of versions before 2.8. This is because we have not considered network fluctuations. Brothers who understand distribution must have heard of CAP theory. CAP theory is the cornerstone of distributed storage systems. In CAP theory, P (partition network partition) must exist, and Redis master-slave replication is no exception. When a network failure occurs between the master and slave servers, resulting in the failure of communication between the slave server and the master server for a period of time. When the slave server reconnects to the master server, if the data status of the master server changes during this period, then the master-slave server Inconsistencies in data status will occur between servers. In master-slave replication versions before Redis 2.8, the way to solve this data state inconsistency is to resend the sync command. Although sync can ensure that the data status of the master and slave servers is consistent, it is obvious that sync is a very resource-consuming operation.
When the sync command is executed, the resources required by the master and slave servers:
The master server executes BGSAVE to generate RDB files, which will occupy a large amount of CPU, disk I/O and memory resources.
The master server sends the generated RDB file to the slave server, which will occupy a lot of network bandwidth.
The slave server receives the RDB file and loads it , will cause the slave server to be blocked and unable to provide services
As can be seen from the above three points, the sync command will not only cause the response ability of the master server to decrease, but also cause the slave server to Refuse to provide services to outsiders.
2.2.1 Improvement points
For versions before 2.8, Redis will reconnect to the slave server after 2.8 Data status synchronization has been improved. The direction of improvement is to reduce the occurrence of full resynchronization and use partial resynchronization as much as possible. After version 2.8, the psync command is used instead of the sync command to perform synchronization operations. The psync command has both full synchronization and incremental synchronization functions:
Full synchronization with the previous version (sync) Consistent
In incremental synchronization, different measures will be taken according to the situation for replication after disconnection and reconnection; if conditions permit, only part of the data missing from the service will still be sent.
2.2.2 How to implement psync
In order to achieve incremental synchronization after disconnection and reconnection from the server, Redis adds three auxiliary parameters:
Replication offset
Replication backlog
Server running id (run id)
2.2.2.1 Replication offset
A replication offset will be maintained in both the master server and the slave server
The master server sends data to the slave service, propagating N bytes of data, and the replication offset of the master service is increased by N
from the slave server Receive the data sent by the master server, receive N bytes of data, and increase the replication offset of the slave server by N
The normal synchronization situation is as follows:
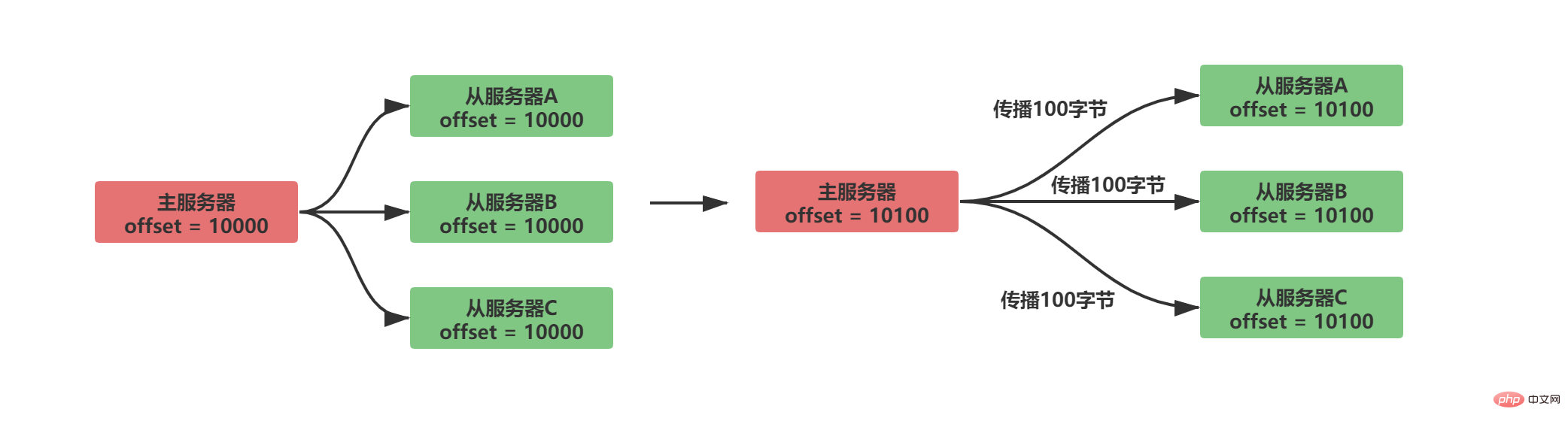
By comparing whether the replication offsets between the master and slave servers are equal, you can know whether the data status between the master and slave servers is consistent. Assuming that A/B propagates normally and C is disconnected from the server, the following situation will occur:
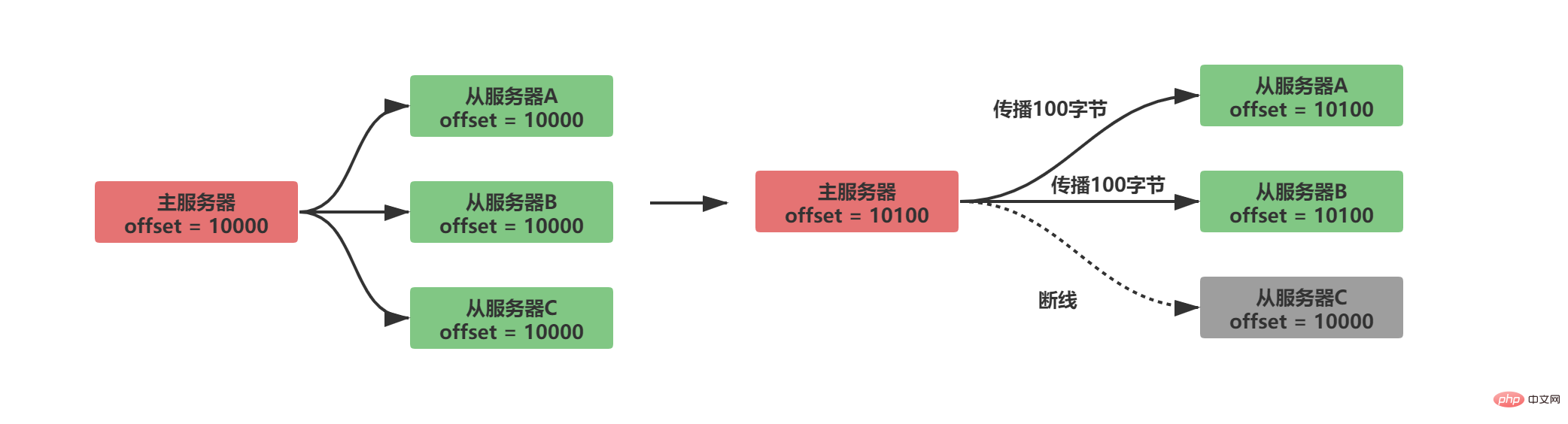
It is obvious that there is a copy offset Later, after the slave server C is disconnected and reconnected, the master server only needs to send the 100 bytes of data missing from the slave server. But how does the master server know what data is missing from the slave server?
2.2.2.2 Copy backlog buffer
The copy backlog buffer is a fixed-length queue with a default size of 1MB. When the data status of the master server changes, the master server synchronizes the data to the slave server and saves a copy to the replication backlog buffer.
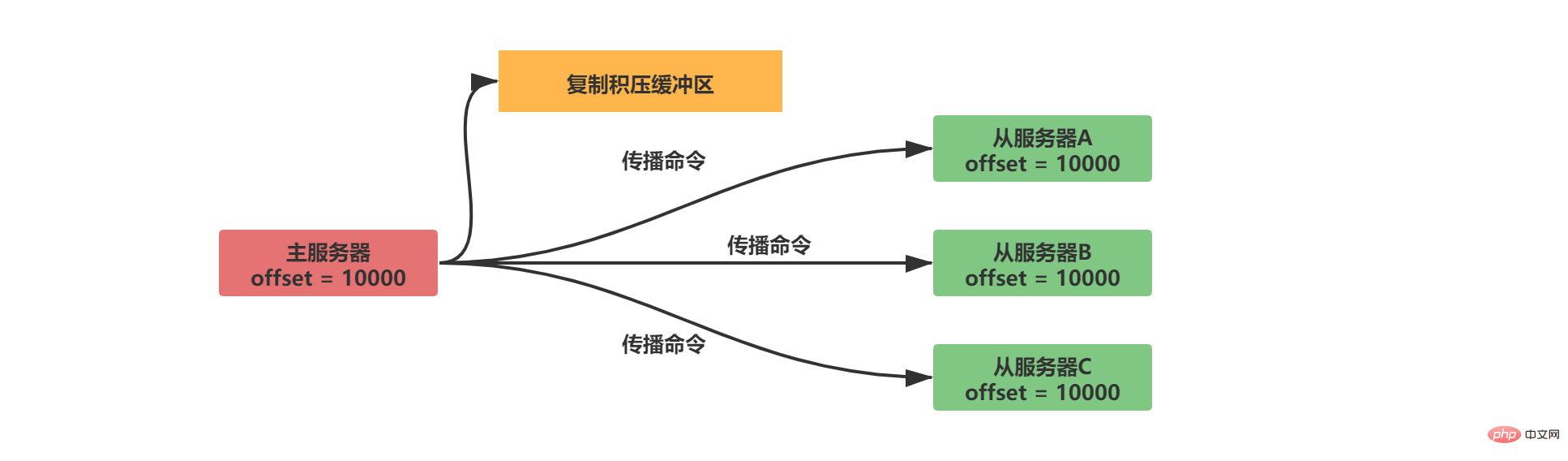
In order to match the offset, the copy backlog buffer not only stores the data content, but also records the offset corresponding to each byte:

When the slave server is disconnected and reconnected, the slave server sends its replication offset (offset) to the master server through the psync command, and the master server can use this offset Use the amount to determine whether to perform incremental propagation or full synchronization.
If the data at offset 1 is still in the copy backlog buffer, then perform incremental synchronization operation
Otherwise, perform full synchronization Operation, consistent with sync
The default copy backlog buffer size of Redis is 1MB. How to set it if you need to customize it? Obviously, we want to use incremental synchronization as much as possible, but we don't want the buffer to occupy too much memory space. Then we can set the size of the replication backlog buffer S by estimating the reconnection time T after the Redis slave service is disconnected and the memory size M of the write commands received by the Redis master server per second.
S = 2 * M * T
Note that the expansion of 2 times here is to leave a certain amount of room to ensure that most of the breaks Incremental synchronization can be used for line reconnection.
2.2.2.3 Server running ID
After seeing this, do you think that the incremental synchronization of disconnection and reconnection can already be achieved, and you also need to run the ID dry Well? In fact, there is another situation that has not been considered, that is, when the master server goes down, a slave server is elected as the new master server. In this case, we can distinguish it by comparing the running ID.
The run ID (run id) is 40 random hexadecimal strings automatically generated when the server starts. Both the master service and the slave server will generate run IDs
When the slave server synchronizes the data of the master server for the first time, the master server will send its running ID to the slave server, and the slave server will save it in the RDB file
When the slave server is disconnected and reconnected, the slave server will send the previously saved master server running ID to the master server. If the server running ID matches, it proves that the master server has not changed, and you can try incremental synchronization
If the server running ID does not match, full synchronization will be performed
2.2.3 Complete psync
The complete psync process is very complicated. It has been very perfect in the master-slave replication version of 2.8-4.0. The parameters sent by the psync command are as follows:
psync
When the slave server has not replicated any master server (it is not the first time that the master-slave replicated , because the master server may change, but the slave server is fully synchronized for the first time), the slave server will send:
psync ? -1
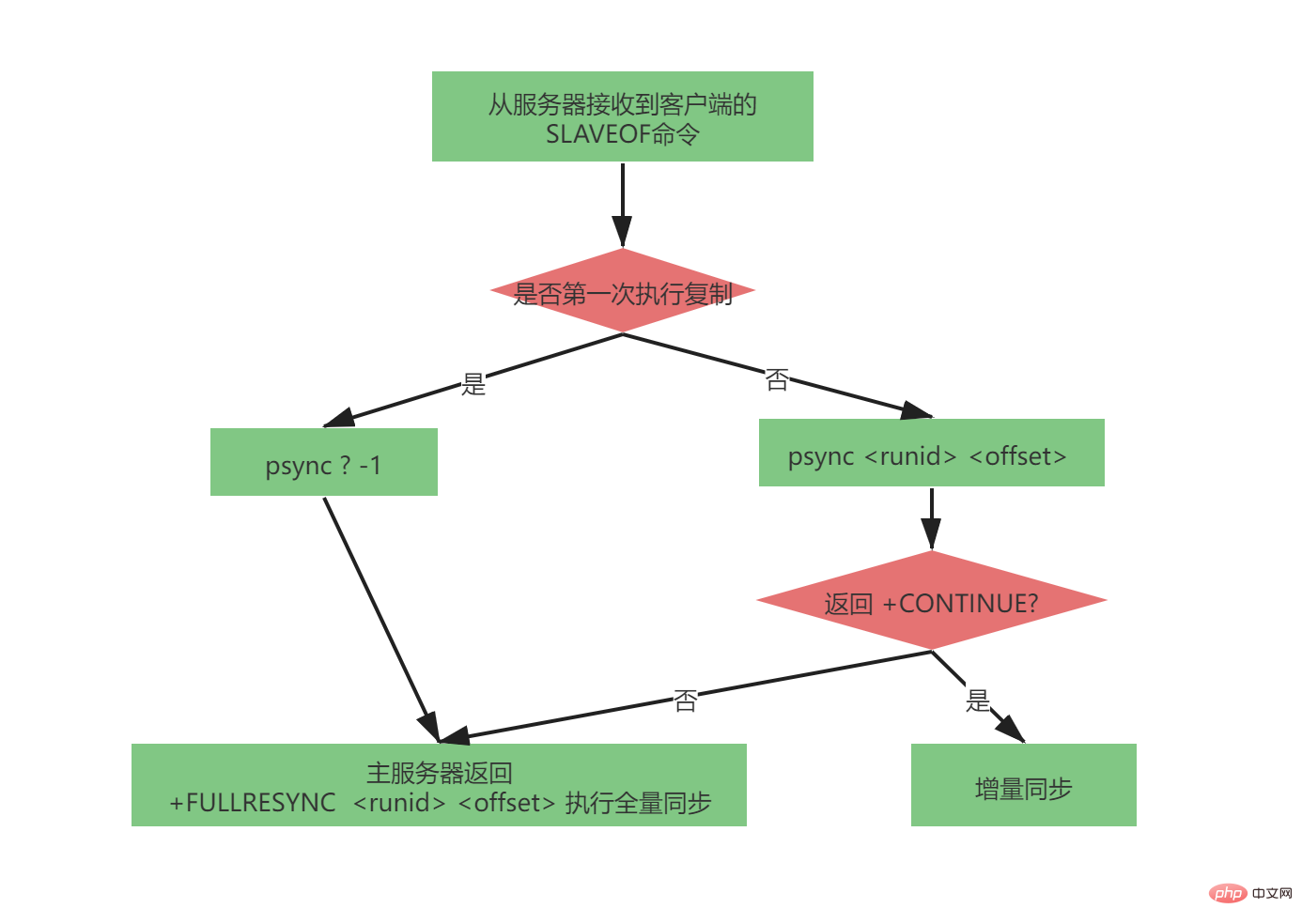
The complete psync process is as follows:
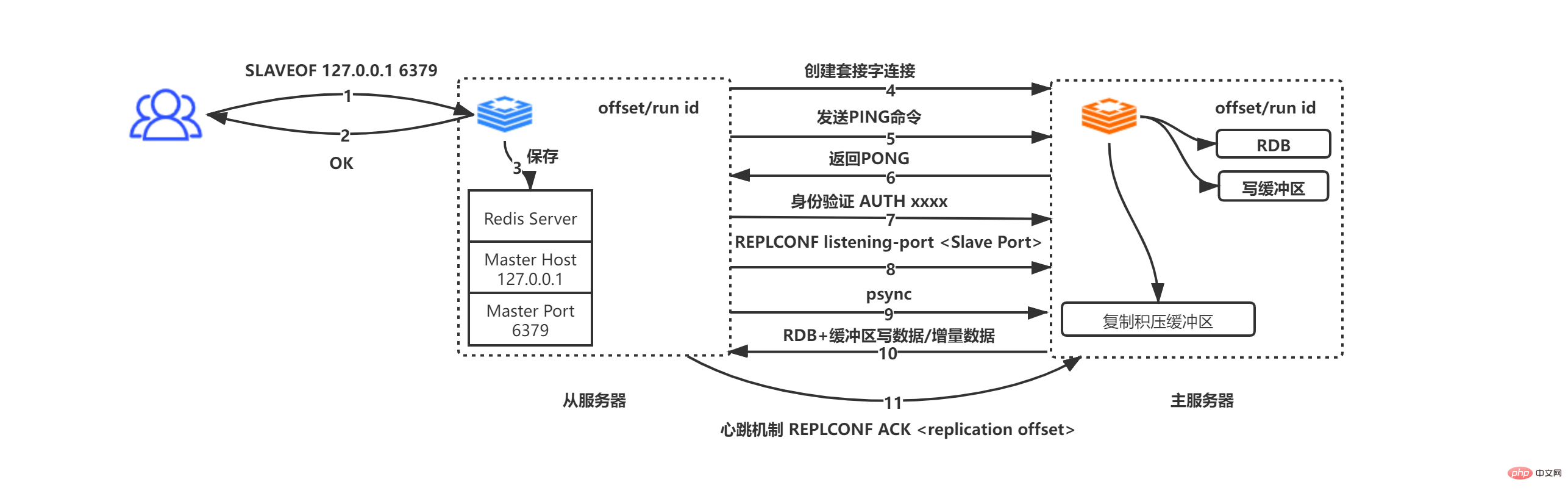
Received from the server Go to SLAVEOF 127.0.0.1 6379 command
Return OK from the server to the command initiator (this is an asynchronous operation, return OK first, and then save the address and port information)
The slave server saves the IP address and port information to the Master Host and Master Port
The slave server actively initiates a socket to the master server based on the Master Host and Master Port connection, and at the same time, the slave service will associate a file event handler specifically used for file copying with this socket connection for subsequent RDB file copying and other work
Master server After receiving the socket connection request from the slave server, create a corresponding socket connection for the request, and look at the slave server as a client (in master-slave replication, the master server and the slave server are actually clients of each other. end and server)
The socket connection is established, and the slave server actively sends a PING command to the main service. If the main server returns PONG within the specified timeout period, the socket is proved The word connection is available, otherwise disconnect and reconnect
If the master server sets a password (masterauth), then the slave server sends the AUTH masterauth command to the master server for authentication. Note that if the slave server sends a password but the master service does not set a password, the master server will send a no password is set error; if the master server requires a password but the slave server does not send a password, the master server will send a NOAUTH error; If the passwords do not match, the master server sends an invalid password error.
The slave server sends REPLCONF listening-port xxxx (xxxx represents the port of the slave server) to the master server. After receiving the command, the master server will save the data. When the client uses INFO replication to query the master-slave information, it can return the data.
The slave server sends the psync command. Please see the above for this step. Figure two situations of psync
The master server and the slave server are clients of each other, performing data requests/responses
Master server The heartbeat packet mechanism is used between the server and the slave server to determine whether the connection is disconnected. The slave server sends a command to the master server every 1 second, REPLCONF ACL offset (replication offset of the slave server). This mechanism can ensure the correct synchronization of data between the master and slave. If the offsets are not equal, the master server will take Incremental/full synchronization measures are used to ensure consistent data status between master and slave (the choice of incremental/full depends on whether the data of offset 1 is still in the replication backlog buffer)
Redis versions 2.8-4.0 still have some room for improvement. Can incremental synchronization be performed when the main server is switched? Therefore, Redis 4.0 version has been optimized to deal with this problem, and psync has been upgraded to psync2.0. pync2.0 abandoned the server running ID and used replid and replid2 instead. Replid stores the running ID of the current main server, and replid2 saves the running ID of the previous main server.
Replication offset
Replication backlog
Main server running id (replid)
Last main server running id (replid2)
We can solve the main server through replid and replid2 When switching, the problem of incremental synchronization:
If replid is equal to the running id of the current main server, then determine the synchronization method incremental/full synchronization
If the replicas are not equal, determine whether replicas 2 are equal (whether they belong to the slave server of the previous master server). If they are equal, you can still choose incremental/full synchronization. If they are not equal, you can only perform full synchronization.
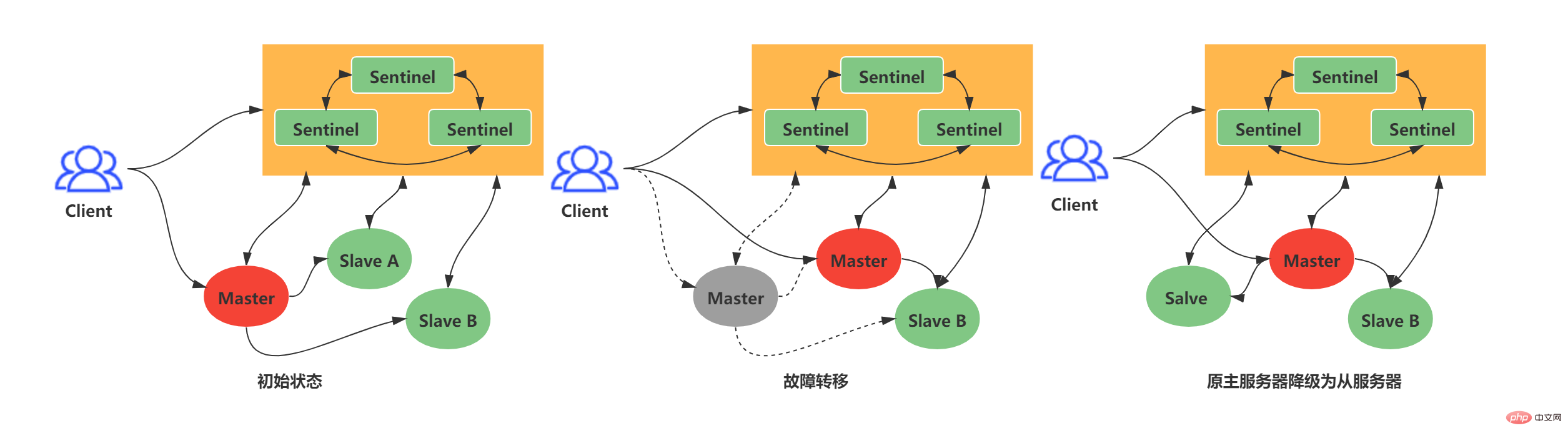
Master-slave replication lays the foundation for Redis distribution The basis, but ordinary master-slave replication cannot achieve high availability. In the ordinary master-slave replication mode, if the master server goes down, the operation and maintenance personnel can only manually switch the master server. Obviously, this solution is not advisable. In response to the above situation, Redis officially launched a high-availability solution that can resist node failures - Redis Sentinel. Redis Sentinel: A Sentinel system composed of one or more Sentinel instances. It can monitor any number of master and slave servers. When the monitored master server goes down, the master server will be automatically offline, and the slave server will be upgraded to New master server.
The following example: When the old Master's offline time exceeds the upper limit of offline time set by the user, the Sentinel system will perform a failover operation on the old Master. The failover operation includes three steps:
Select the latest data in the Slave as the new Master
Send new replication instructions to other Slaves to make other slave servers become the new Master's Slave
Continue to monitor the old Master, and if it comes online, set the old Master as the Slave of the new Master
This article is based on the following resource list:
| IP address | Node role | Port | |||||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| ##192.168.211.104 | Redis Master/ Sentinel | 6379/26379 | |||||||||||||||||||||
| Redis Slave/ Sentinel | ##6379/26379 | #192.168.211.106 | |||||||||||||||||||||
| Redis Slave/ Sentinel | 6379/26379 |
2. Sentinel initialization and network connectionThere is nothing particularly magical about Sentinel. It is a simpler Redis server. When Sentinel starts, it will load different command tables and configuration files. So essentially Sentinel is a Redis service with fewer commands and some special functions. When a Sentinel starts, it needs to go through the following steps:
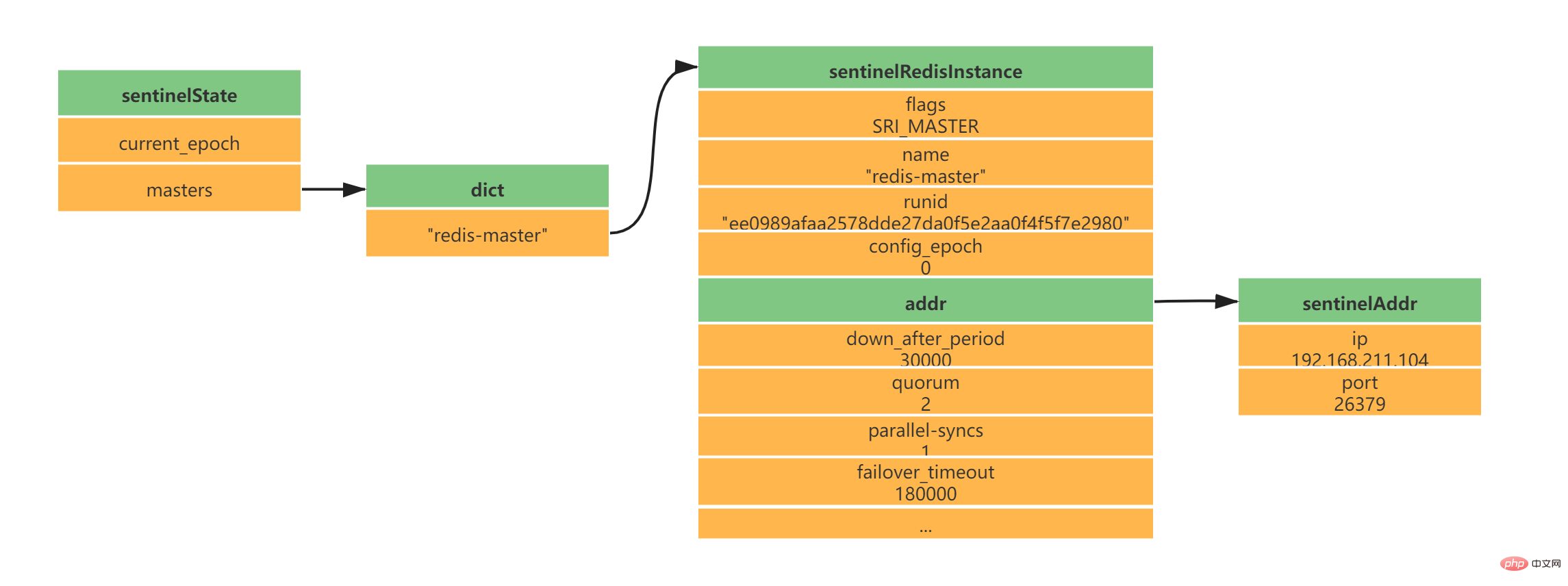
2.1 Initialize Sentinel serverSentinel is essentially a Redis server, so starting Sentinel requires starting a Redis server, but Sentinel does not need to read the RDB/AOF file to restore the data state. 2.2 Replace ordinary Redis code with Sentinel-specific codeSentinel is used for fewer Redis commands. Most commands are not supported by the Sentinel client, and Sentinel has some special functions. These require Sentinel to replace the code used by the Redis server with Sentinel-specific code at startup. During this period, Sentinel will load a different command table than the ordinary Redis server. Sentinel does not support commands such as SET and DBSIZE; it retains support for PING, PSUBSCRIBE, SUBSCRIBE, UNSUBSCRIBE, INFO and other commands; these commands provide guarantees for Sentinel's work. 2.3 Initializing Sentinel stateAfter loading Sentinel's unique code, Sentinel will initialize the sentinelState structure, which is used to store Sentinel-related status information, the most important of which is the masters dictionary. struct sentinelState {
//当前纪元,故障转移使用
uint64_t current_epoch;
// Sentinel监视的主服务器信息
// key -> 主服务器名称
// value -> 指向sentinelRedisInstance指针
dict *masters;
// ...
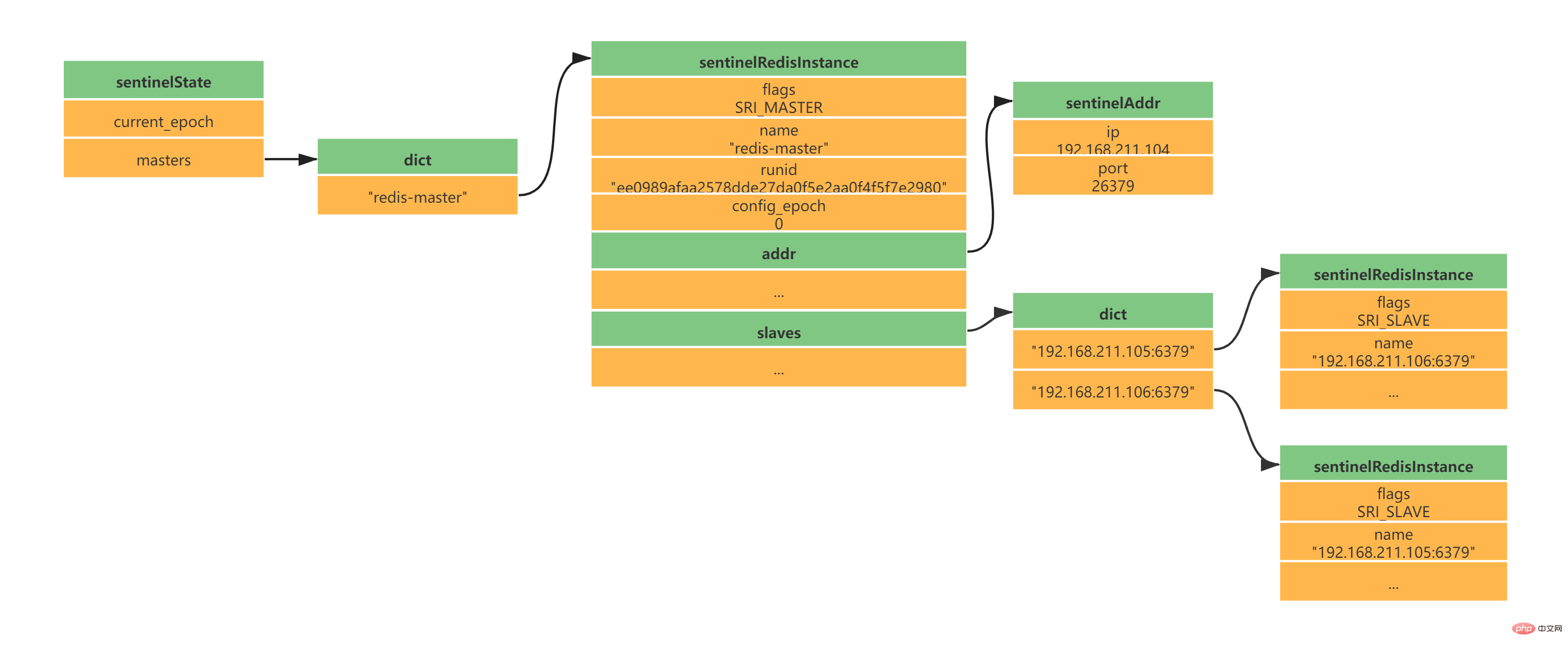
} sentinel;Copy after login 2.4 Initialize the list of master servers monitored by SentinelThe list of master servers monitored by Sentinel is stored in the masters dictionary of sentinelState. When sentinelState is created, the list of master servers monitored by Sentinel begins to be initialized. .
The name of the main server is specified by our sentinel.conf configuration file. The following main server name is redis-master (I have a configuration of one master and two slaves here): daemonize yes port 26379 protected-mode no dir "/usr/local/soft/redis-6.2.4/sentinel-tmp" sentinel monitor redis-master 192.168.211.104 6379 2 sentinel down-after-milliseconds redis-master 30000 sentinel failover-timeout redis-master 180000 sentinel parallel-syncs redis-master 1 Copy after login sentinelRedisInstance instance saves the information of the Redis server (Master server, slave server, and Sentinel information are all stored in this instance). typedef struct sentinelRedisInstance {
// 标识值,标识当前实例的类型和状态。如SRI_MASTER、SRI_SLVAE、SRI_SENTINEL
int flags;
// 实例名称 主服务器为用户配置实例名称、从服务器和Sentinel为ip:port
char *name;
// 服务器运行ID
char *runid;
//配置纪元,故障转移使用
uint64_t config_epoch;
// 实例地址
sentinelAddr *addr;
// 实例判断为主观下线的时长 sentinel down-after-milliseconds redis-master 30000
mstime_t down_after_period;
// 实例判断为客观下线所需支持的投票数 sentinel monitor redis-master 192.168.211.104 6379 2
int quorum;
// 执行故障转移操作时,可以同时对新的主服务器进行同步的从服务器数量 sentinel parallel-syncs redis-master 1
int parallel-syncs;
// 刷新故障迁移状态的最大时限 sentinel failover-timeout redis-master 180000
mstime_t failover_timeout;
// ...
} sentinelRedisInstance;Copy after login According to the above configuration of one master and two slaves, you will get the following instance structure:
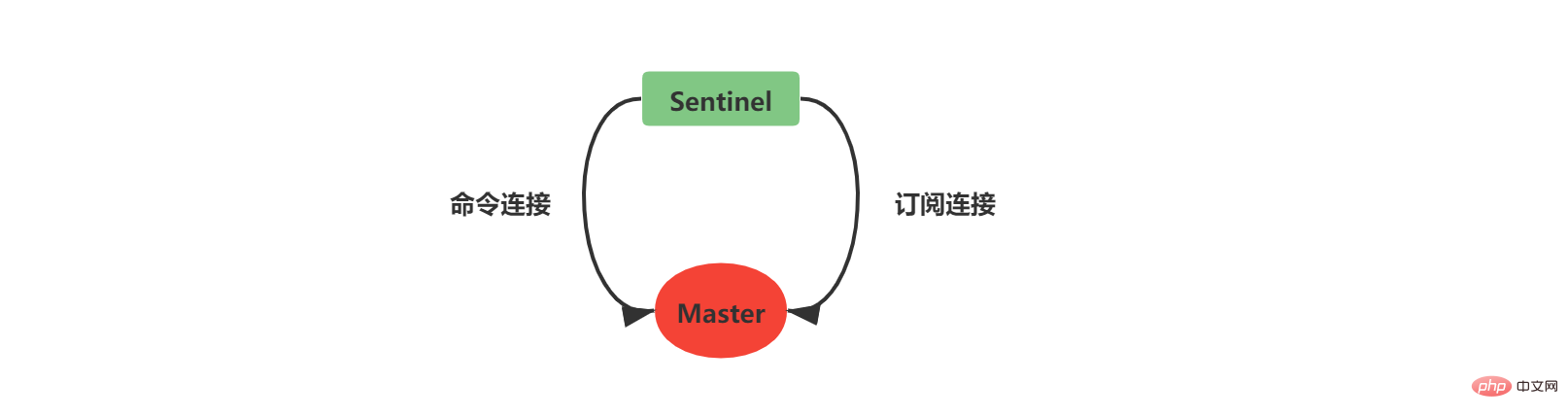
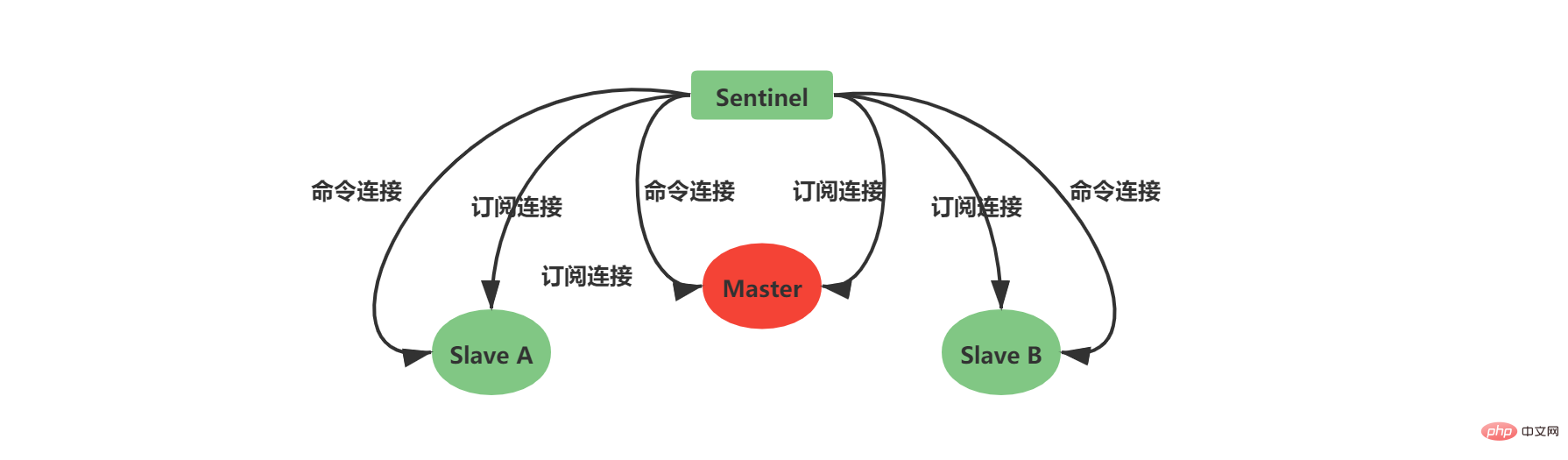
2.5 Create a network connection to the main serverAfter the instance structure is initialized, Sentinel will begin to create a network connection to the Master. In this step, Sentinel will become the client of the Master. A command connection and a subscription connection will be created between Sentinel and Master:
After the command connection is created, Sentinel sends an INFO command to the Master every 10 seconds, and uses the Master’s reply information Two aspects of knowledge can be obtained:
2.6 Create a network connection to the slave serverObtain the slave server information according to the main service. Sentinel can create a network connection to the Slave, and also create a network connection between Sentinel and Slave. Command connection and subscription connection.
当Sentinel和Slave之间创建网络连接之后,Sentinel成为了Slave的客户端,Sentinel也会每隔10秒钟通过INFO指令请求Slave获取服务器信息。 到这一步Sentinel获取到了Master和Slave的相关服务器数据。这其中比较重要的信息如下:
此时实例结构信息如下所示:
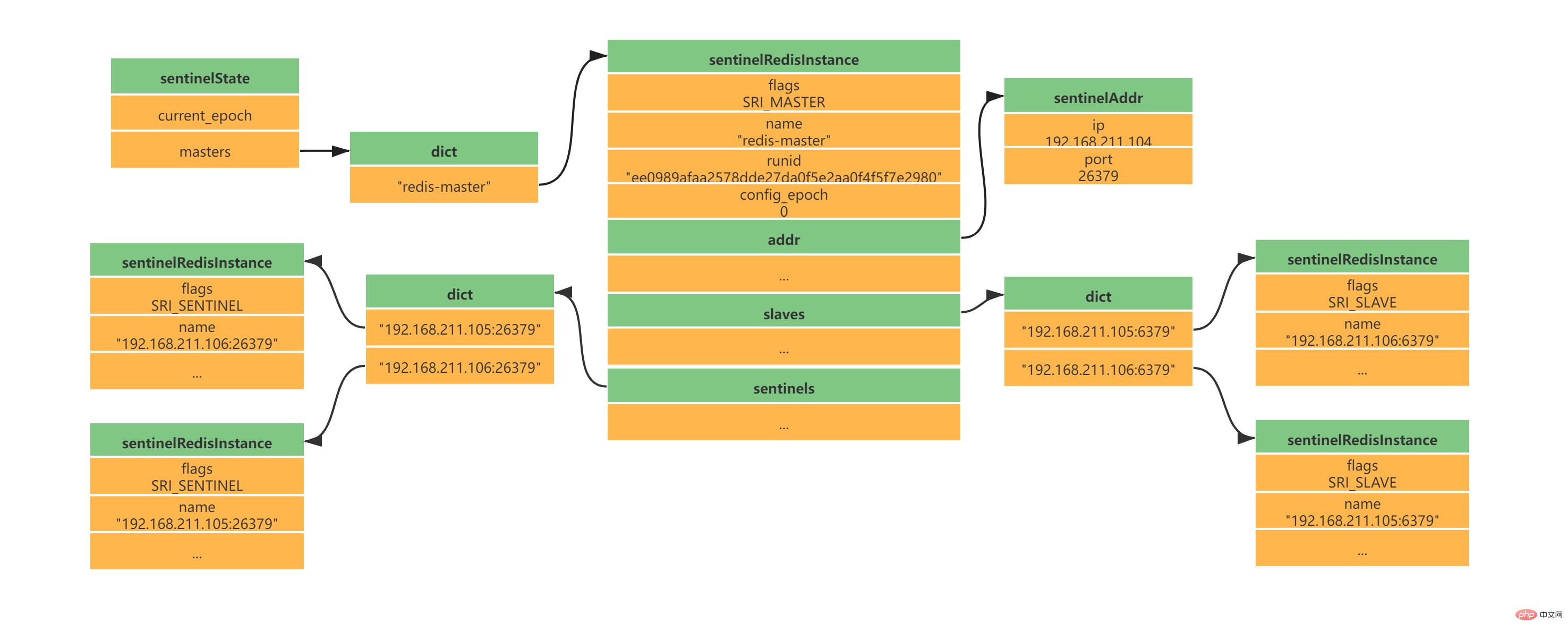
2.7 创建Sentinel之间的网络连接此时是不是还有疑问,Sentinel之间是怎么互相发现对方并且相互通信的,这个就和上面Sentinel与自己监视的主从之间订阅_sentinel_:hello频道有关了。 Sentinel会与自己监视的所有Master和Slave之间订阅_sentinel_:hello频道,并且Sentinel每隔2秒钟向_sentinel_:hello频道发送一条消息,消息内容如下:
其中s代码Sentinel,m代表Master;ip表示IP地址,port表示端口、runid表示运行id、epoch表示配置纪元。 多个Sentinel在配置文件中会配置相同的主服务器ip和端口信息,因此多个Sentinel均会订阅_sentinel_:hello频道,通过频道接收到的信息就可获取到其他Sentinel的ip和port,其中有如下两点需要注意:
Sentinel之间不会创建订阅连接,它们只会创建命令连接:
此时实例结构信息如下所示:
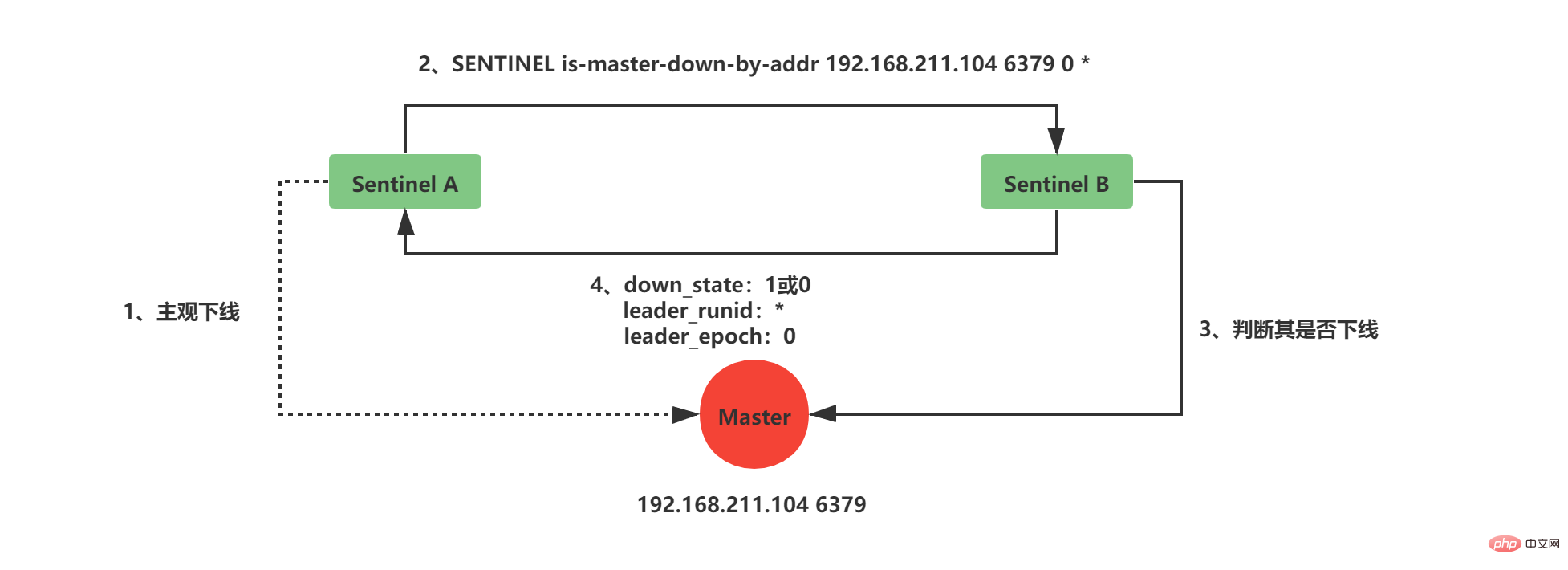
3、Sentinel工作Sentinel最主要的工作就是监视Redis服务器,当Master实例超出预设的时限后切换新的Master实例。这其中有很多细节工作,大致分为检测Master是否主观下线、检测Master是否客观下线、选举领头Sentinel、故障转移四个步骤。 3.1 检测Master是否主观下线Sentinel每隔1秒钟,向sentinelRedisInstance实例中的所有Master、Slave、Sentinel发送PING命令,通过其他服务器的回复来判断其是否仍然在线。 sentinel down-after-milliseconds redis-master 30000 Copy after login 在Sentinel的配置文件中,当Sentinel PING的实例在连续down-after-milliseconds配置的时间内返回无效命令,则当前Sentinel认为其主观下线。Sentinel的配置文件中配置的down-after-milliseconds将会对其sentinelRedisInstance实例中的所有Master、Slave、Sentinel都适应。
如果当前Sentinel检测到Master处于主观下线状态,那么它将会修改其sentinelRedisInstance的flags为SRI_S_DOWN
3.2 检测Master是否客观下线当前Sentinel认为其下线只能处于主观下线状态,要想判断当前Master是否客观下线,还需要询问其他Sentinel,并且所有认为Master主观下线或者客观下线的总和需要达到quorum配置的值,当前Sentinel才会将Master标志为客观下线。
当前Sentinel向sentinelRedisInstance实例中的其他Sentinel发送如下命令: SENTINEL is-master-down-by-addr <ip> <port> <current_epoch> <runid> Copy after login Copy after login
current_epoch和runid均用于Sentinel的选举,Master下线之后,需要选举一个领头Sentinel来选举一个新的Master,current_epoch和runid在其中发挥着重要作用,这个后续讲解。 接收到命令的Sentinel,会根据命令中的参数检查主服务器是否下线,检查完成后会返回如下三个参数:
3.3 选举领头Sentineldown_state返回1,证明接收is-master-down-by-addr命令的Sentinel认为该Master也主观下线了,如果down_state返回1的数量(包括本身)大于等于quorum(配置文件中配置的值),那么Master正式被当前Sentinel标记为客观下线。 此时,Sentinel会再次发送如下指令: SENTINEL is-master-down-by-addr <ip> <port> <current_epoch> <runid> Copy after login Copy after login 此时的runid将不再是0,而是Sentinel自己的运行id(runid)的值,表示当前Sentinel希望接收到is-master-down-by-addr命令的其他Sentinel将其设置为领头Sentinel。这个设置是先到先得的,Sentinel先接收到谁的设置请求,就将谁设置为领头Sentinel。 发送命令的Sentinel会根据其他Sentinel回复的结果来判断自己是否被该Sentinel设置为领头Sentinel,如果Sentinel被其他Sentinel设置为领头Sentinel的数量超过半数Sentinel(这个数量在sentinelRedisInstance的sentinel字典中可以获取),那么Sentinel会认为自己已经成为领头Sentinel,并开始后续故障转移工作(由于需要半数,且每个Sentinel只会设置一个领头Sentinel,那么只会出现一个领头Sentinel,如果没有一个达到领头Sentinel的要求,Sentinel将会重新选举直到领头Sentinel产生为止)。 3.4 故障转移故障转移将会交给领头sentinel全权负责,领头sentinel需要做如下事情:
这其中最难的一步是如果选择最佳的新Master,领头Sentinel会做如下清洗和排序工作:
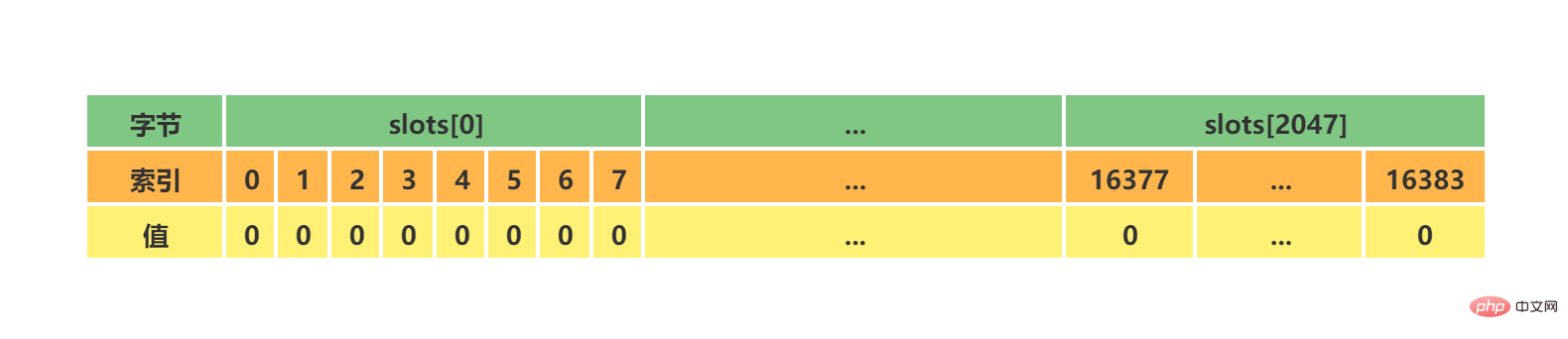
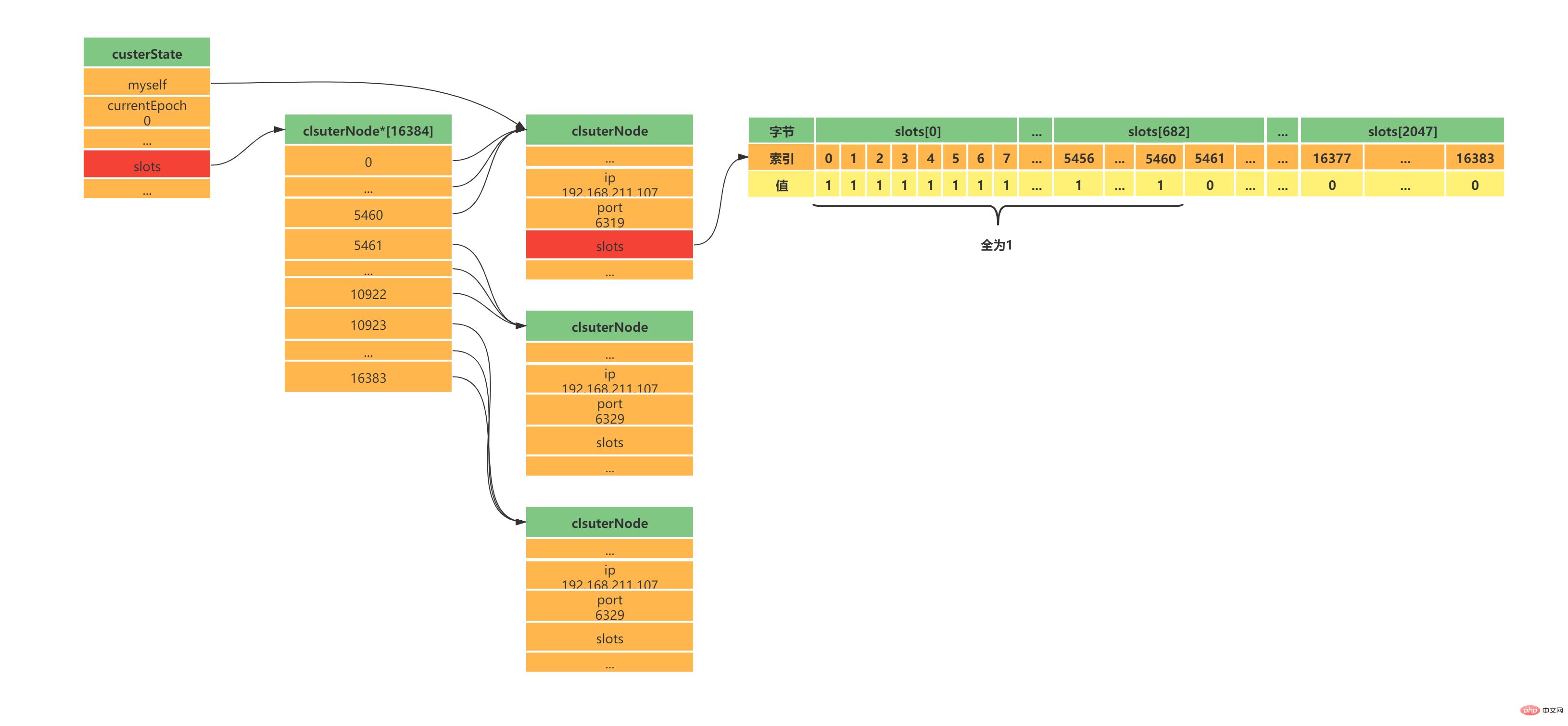
新的Master产生后,领头sentinel会向已下线主服务器的其他从服务器(不包括新Master)发送SLAVEOF ip port命令,使其成为新master的slave。 到这里Sentinel的的工作流程就算是结束了,如果新master下线,则循环流程即可! 三、集群1、简介Redis集群是Redis提供的分布式数据库方案,集群通过分片(sharding)进行数据共享,Redis集群主要实现了以下目标:
Regarding the learning of Redis cluster, if you don’t have any experience, it is recommended to read these three articles (Chinese series) first: Redis Cluster Tutorial
Redis cluster specification
Redis3 master 3 slave pseudo cluster deployment
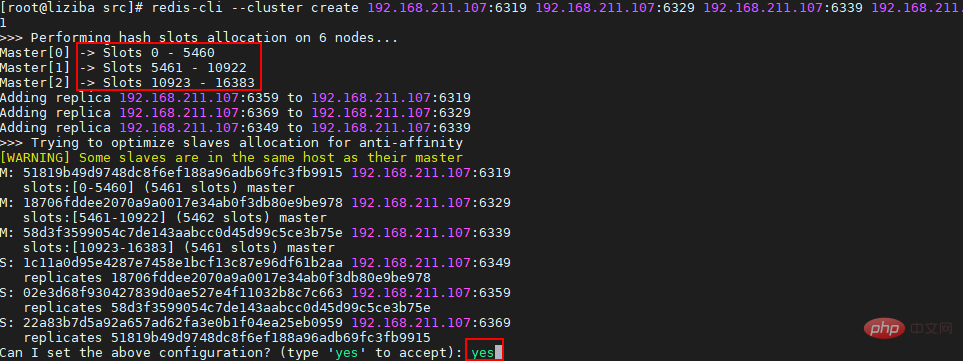
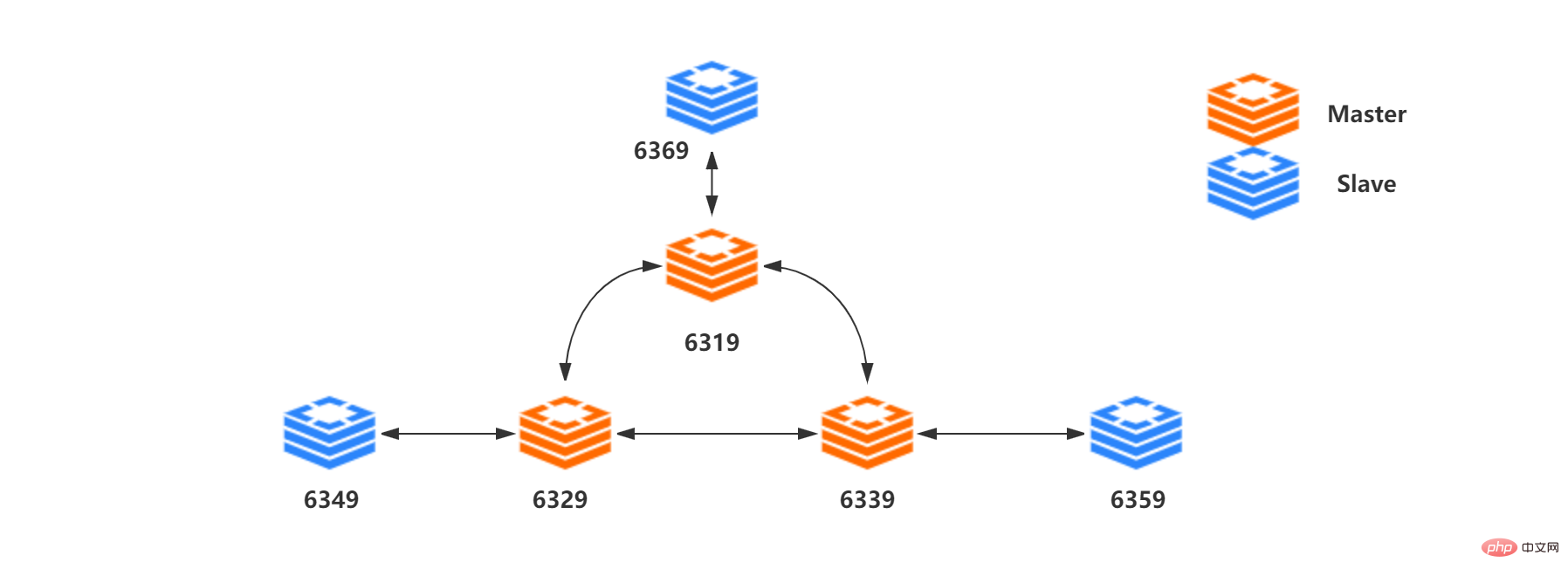
The following content relies on the three master and three slave structure in the figure below:
Resource list:
The above is the detailed content of Take you through master-slave replication, Sentinel, and clustering in Redis. For more information, please follow other related articles on the PHP Chinese website!
Related labels:
Previous article:In-depth analysis of the Info command in Redis
Next article:Sharing of Redis high-frequency interview questions in 2023 (with answer analysis)
Statement of this Website
The content of this article is voluntarily contributed by netizens, and the copyright belongs to the original author. This site does not assume corresponding legal responsibility. If you find any content suspected of plagiarism or infringement, please contact admin@php.cn
Latest Articles by Author
Latest Issues
python2.7 - When using django-redis, the data in redis cannot be accessed after connecting?
From 1970-01-01 08:00:00
0
0
0
Related Topics
More>
|

























![[Web front-end] Node.js quick start](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



