

Give you an in-depth understanding of distributed locks in Redis

Do you really understand Redis distributed locks? The following article will give you an in-depth introduction to distributed locks in Redis, and talk about how to implement locks, release locks, defects of distributed locks, etc. I hope it will be helpful to you!

What is a distributed lock
Speaking of Redis, the first function we think of is the ability to cache data. In addition, Redis is single-process , high performance characteristics, it is also often used for distributed locks. [Related recommendations: Redis Video Tutorial]
We all know that locks function as a synchronization tool in programs to ensure that shared resources can only be accessed by one thread at the same time. In Java We are all familiar with locks, such as synchronized and Lock, which we often use. However, Java's locks can only be guaranteed to be effective in a single machine, and there is nothing we can do in a distributed cluster environment. At this time, we need to use distributed locks.
Distributed locks, as the name suggests, are locks used in distributed project development. They can be used to control synchronous access to shared resources between distributed systems. Generally speaking, the characteristics that distributed locks need to meet are as follows A few points:
1. Mutual exclusivity: at any time, for the same piece of data, only one application can obtain the distributed lock;
2. High availability: in a distributed scenario Under this situation, the downtime of a small number of servers does not affect normal use. In this case, the service that provides distributed locks needs to be deployed in a cluster;
3. Prevent lock timeout: If the client does not actively release the lock , the server will automatically release the lock after a period of time to prevent deadlocks when the client is down or the network is unreachable;
4. Exclusivity: locking and unlocking must be performed by the same server, that is, the lock Only the holder can release the lock, and the lock you added cannot be unlocked by others;
There are many tools in the industry that can achieve the effect of distributed locks, but the operations are just the following: locking, unlocking , Prevent lock timeout.
Since this article is talking about Redis distributed locks, of course we will extend it with Redis knowledge points.
Commands to implement locks
First introduce a few commands of Redis,
1. SETNX, the usage is SETNX key value
SETNX is the abbreviation of "SET if Not eXists" (SET if it does not exist). If the setting is successful, it returns 1, otherwise it returns 0.
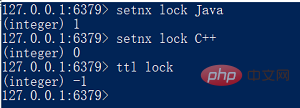
key to lock After the value is set to "Java", it will fail if it is set to another value. It looks very simple, and it seems that the lock is exclusive, but there is a fatal problem, that is, key has no expiration time, so First, unless the key is manually deleted or the expiration time is set after acquiring the lock, other threads will never get the lock.
In this case, we can always add an expiration time to the key, and directly let the thread perform a two-step operation when acquiring the lock:`SETNX Key 1` `EXPIRE Key Seconds`
obtaining the lock is successful but setting the time fails. Wouldn't it be in vain?
But don’t worry, the Redis official has already considered this for us, so the following command was introduced 2, SETEX, usageSETEX key seconds value
value to the key and set the key lifetime to seconds (in seconds unit). If key already exists, the SETEX command will overwrite the old value.
`SET key value` `EXPIRE key seconds # 设置生存时间`
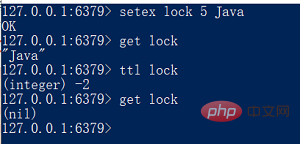 ##setex usage
##setex usage
3. PSETEX, usage
PSETEX key milliseconds value This command is similar to the SETEX command, but it sets the lifetime of
in milliseconds instead of seconds like the SETEX command. However, starting from Redis version 2.6.12, the SET command can use parameters to achieve the same effect as the three commands SETNX, SETEX, and PSETEX.
For example, this command
`SET key value NX EX seconds`
After adding the NX and EX parameters, the effect is equivalent to SETEX, which is also the most common way to write a lock in Redis.
How to release the lock
The command to release the lock is simple, just delete the key directly, but as we said before, because the distributed lock must be released by the lock holder himself, so we You must first ensure that the thread currently releasing the lock is the holder, and then delete it if there is no problem. In this way, it becomes a two-step process, which seems to violate atomicity again. What should I do?
Don’t panic, we can use lua script to assemble the two-step operation, just like this:
`if redis.call("get",KEYS[1]) == ARGV[1]`
`then`
`return redis.call("del",KEYS[1])`
`else`
`return 0`
`end`KEYS[1]是当前key的名称,ARGV[1]可以是当前线程的ID(或者其他不固定的值,能识别所属线程即可),这样就可以防止持有过期锁的线程,或者其他线程误删现有锁的情况出现。
代码实现
知道了原理后,我们就可以手写代码来实现Redis分布式锁的功能了,因为本文的目的主要是为了讲解原理,不是为了教大家怎么写分布式锁,所以我就用伪代码实现了。
首先是redis锁的工具类,包含了加锁和解锁的基础方法:
`public class RedisLockUtil {`
`private String LOCK_KEY = "redis_lock";`
`// key的持有时间,5ms`
`private long EXPIRE_TIME = 5;`
`// 等待超时时间,1s`
`private long TIME_OUT = 1000;`
`// redis命令参数,相当于nx和px的命令合集`
`private SetParams params = SetParams.setParams().nx().px(EXPIRE_TIME);`
`// redis连接池,连的是本地的redis客户端`
`JedisPool jedisPool = new JedisPool("127.0.0.1", 6379);`
`/**`
`* 加锁`
`*`
`* @param id`
`* 线程的id,或者其他可识别当前线程且不重复的字段`
`* @return`
`*/`
`public boolean lock(String id) {`
`Long start = System.currentTimeMillis();`
`Jedis jedis = jedisPool.getResource();`
`try {`
`for (;;) {`
`// SET命令返回OK ,则证明获取锁成功`
`String lock = jedis.set(LOCK_KEY, id, params);`
`if ("OK".equals(lock)) {`
`return true;`
`}`
`// 否则循环等待,在TIME_OUT时间内仍未获取到锁,则获取失败`
`long l = System.currentTimeMillis() - start;`
`if (l >= TIME_OUT) {`
`return false;`
`}`
`try {`
`// 休眠一会,不然反复执行循环会一直失败`
`Thread.sleep(100);`
`} catch (InterruptedException e) {`
`e.printStackTrace();`
`}`
`}`
`} finally {`
`jedis.close();`
`}`
`}`
`/**`
`* 解锁`
`*`
`* @param id`
`* 线程的id,或者其他可识别当前线程且不重复的字段`
`* @return`
`*/`
`public boolean unlock(String id) {`
`Jedis jedis = jedisPool.getResource();`
`// 删除key的lua脚本`
`String script = "if redis.call('get',KEYS[1]) == ARGV[1] then" + " return redis.call('del',KEYS[1]) " + "else"`
`+ " return 0 " + "end";`
`try {`
`String result =`
`jedis.eval(script, Collections.singletonList(LOCK_KEY), Collections.singletonList(id)).toString();`
`return "1".equals(result);`
`} finally {`
`jedis.close();`
`}`
`}`
`}`具体的代码作用注释已经写得很清楚了,然后我们就可以写一个demo类来测试一下效果:
`public class RedisLockTest {`
`private static RedisLockUtil demo = new RedisLockUtil();`
`private static Integer NUM = 101;`
`public static void main(String[] args) {`
`for (int i = 0; i < 100; i++) {`
`new Thread(() -> {`
`String id = Thread.currentThread().getId() + "";`
`boolean isLock = demo.lock(id);`
`try {`
`// 拿到锁的话,就对共享参数减一`
`if (isLock) {`
`NUM--;`
`System.out.println(NUM);`
`}`
`} finally {`
`// 释放锁一定要注意放在finally`
`demo.unlock(id);`
`}`
`}).start();`
`}`
`}`
`}`我们创建100个线程来模拟并发的情况,执行后的结果是这样的:
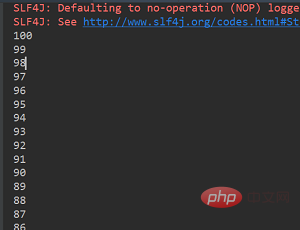
代码执行结果
可以看出,锁的效果达到了,线程安全是可以保证的。
当然,上面的代码只是简单的实现了效果,功能肯定是不完整的,一个健全的分布式锁要考虑的方面还有很多,实际设计起来不是那么容易的。
我们的目的只是为了学习和了解原理,手写一个工业级的分布式锁工具不现实,也没必要,类似的开源工具一大堆(Redisson),原理都差不多,而且早已经过业界同行的检验,直接拿来用就行。
虽然功能是实现了,但其实从设计上来说,这样的分布式锁存在着很大的缺陷,这也是本篇文章想重点探讨的内容。
分布式锁的缺陷
一、客户端长时间阻塞导致锁失效问题
客户端1得到了锁,因为网络问题或者GC等原因导致长时间阻塞,然后业务程序还没执行完锁就过期了,这时候客户端2也能正常拿到锁,可能会导致线程安全的问题。
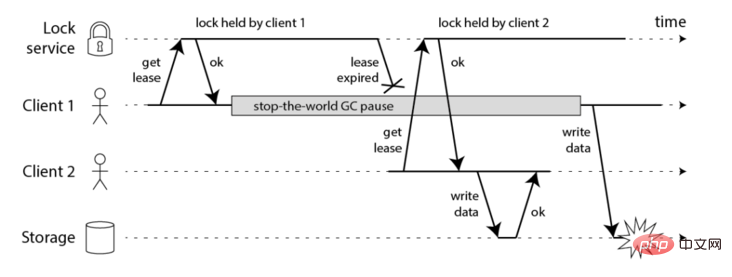
客户端长时间阻塞
那么该如何防止这样的异常呢?我们先不说解决方案,介绍完其他的缺陷后再来讨论。
二、redis服务器时钟漂移问题
如果redis服务器的机器时钟发生了向前跳跃,就会导致这个key过早超时失效,比如说客户端1拿到锁后,key的过期时间是12:02分,但redis服务器本身的时钟比客户端快了2分钟,导致key在12:00的时候就失效了,这时候,如果客户端1还没有释放锁的话,就可能导致多个客户端同时持有同一把锁的问题。
三、单点实例安全问题
如果redis是单master模式的,当这台机宕机的时候,那么所有的客户端都获取不到锁了,为了提高可用性,可能就会给这个master加一个slave,但是因为redis的主从同步是异步进行的,可能会出现客户端1设置完锁后,master挂掉,slave提升为master,因为异步复制的特性,客户端1设置的锁丢失了,这时候客户端2设置锁也能够成功,导致客户端1和客户端2同时拥有锁。
为了解决Redis单点问题,redis的作者提出了RedLock算法。
RedLock算法
该算法的实现前提在于Redis必须是多节点部署的,可以有效防止单点故障,具体的实现思路是这样的:
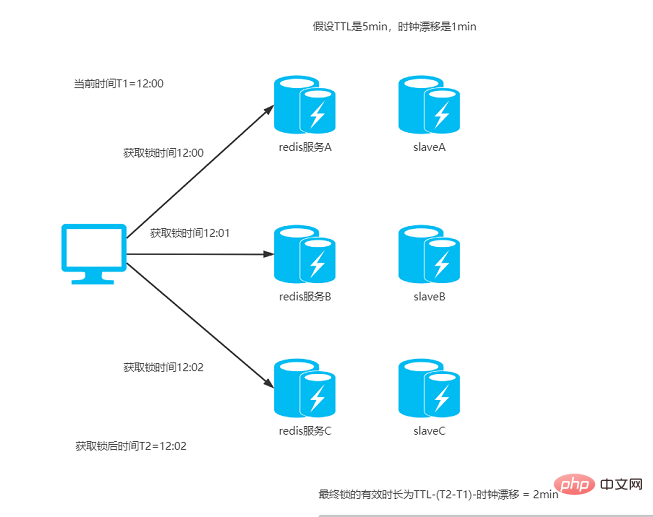
1、获取当前时间戳(ms);
2、先设定key的有效时长(TTL),超出这个时间就会自动释放,然后client(客户端)尝试使用相同的key和value对所有redis实例进行设置,每次链接redis实例时设置一个比TTL短很多的超时时间,这是为了不要过长时间等待已经关闭的redis服务。并且试着获取下一个redis实例。
比如:TTL(也就是过期时间)为5s,那获取锁的超时时间就可以设置成50ms,所以如果50ms内无法获取锁,就放弃获取这个锁,从而尝试获取下个锁;
3、client通过获取所有能获取的锁后的时间减去第一步的时间,还有redis服务器的时钟漂移误差,然后这个时间差要小于TTL时间并且成功设置锁的实例数>= N/2 + 1(N为Redis实例的数量),那么加锁成功
比如TTL是5s,连接redis获取所有锁用了2s,然后再减去时钟漂移(假设误差是1s左右),那么锁的真正有效时长就只有2s了;
4、如果客户端由于某些原因获取锁失败,便会开始解锁所有redis实例。
根据这样的算法,我们假设有5个Redis实例的话,那么client只要获取其中3台以上的锁就算是成功了,用流程图演示大概就像这样:
key valid time
Okay, the algorithm has been introduced. From a design point of view, there is no doubt that the main idea of the RedLock algorithm is In order to effectively prevent the single point of failure of Redis, the error of server clock drift was also taken into consideration when designing TTL, which greatly improved the security of distributed locks.
But is this really the case? Anyway, I personally feel that the effect is average.
First of all, we can see that in the RedLock algorithm, the effective time of the lock will be reduced by the time it takes to connect to the Redis instance. If this process is caused by network problems If it takes too long, the effective time left for the lock will be greatly reduced. The time for the client to access the shared resources is very short, and it is likely that the lock will expire during the program processing. Moreover, the effective time of the lock needs to be subtracted from the clock drift of the server, but how much should be subtracted? If this value is not set well, problems may easily occur.
Then the second point is that although this algorithm takes into account the use of multiple nodes to prevent Redis single point of failure, if a node crashes and restarts, it is still possible for multiple clients to acquire locks at the same time. Case.
Assume there are a total of 5 Redis nodes: A, B, C, D, E, client 1 and 2 are locked respectively
Client 1 is successfully locked A, B, C are obtained, and the lock is acquired successfully (but D and E are not locked).
The master of node C is down, and the lock has not yet been synchronized to the slave. After the slave was upgraded to master, it lost the lock added by client 1.
Client 2 acquired the lock at this time, locked C, D, and E, and acquired the lock successfully.
In this way, client 1 and client 2 get the lock at the same time, and the hidden danger of program security still exists. In addition, if a time drift occurs in one of these nodes, it may also cause lock security issues.
So, although availability and reliability are improved through multi-instance deployment, RedLock does not completely solve the hidden danger of Redis single point of failure, nor does it solve the problems caused by clock drift and long-term client blocking. The problem of lock timeout failure and the security risks of locks still exist.
Conclusion
Some people may want to ask further, what should be done to ensure the absolute safety of the lock?
I can only say that you can’t have your cake and eat it too. The reason why we use Redis as a distributed lock tool is largely because of Redis’s high efficiency and single-process characteristics. Even if Performance can be well guaranteed under high concurrency conditions, but in many cases, performance and security cannot be fully balanced. If you must ensure the security of the lock, you can use other middleware such as db and zookeeper for control. These tools can ensure the safety of the lock very well, but the performance can only be said to be unsatisfactory, otherwise everyone would have used them long ago.
Generally speaking, if you use Redis to control shared resources and require high data security requirements, the final guarantee solution is to control the business data idempotently. In this way, even if multiple clients obtain the lock The situation will not affect the consistency of the data. Of course, not all scenes are suitable for this. The specific choice is up to each judge. After all, there is no perfect technology, only the suitable one is the best.
For more programming-related knowledge, please visit: Introduction to Programming! !
The above is the detailed content of Give you an in-depth understanding of distributed locks in Redis. For more information, please follow other related articles on the PHP Chinese website!

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

AI Hentai Generator
Generate AI Hentai for free.

Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics
 1377
1377
 52
52

 How to build the redis cluster mode
Apr 10, 2025 pm 10:15 PM
How to build the redis cluster mode
Apr 10, 2025 pm 10:15 PM
Redis cluster mode deploys Redis instances to multiple servers through sharding, improving scalability and availability. The construction steps are as follows: Create odd Redis instances with different ports; Create 3 sentinel instances, monitor Redis instances and failover; configure sentinel configuration files, add monitoring Redis instance information and failover settings; configure Redis instance configuration files, enable cluster mode and specify the cluster information file path; create nodes.conf file, containing information of each Redis instance; start the cluster, execute the create command to create a cluster and specify the number of replicas; log in to the cluster to execute the CLUSTER INFO command to verify the cluster status; make
 How to use the redis command
Apr 10, 2025 pm 08:45 PM
How to use the redis command
Apr 10, 2025 pm 08:45 PM
Using the Redis directive requires the following steps: Open the Redis client. Enter the command (verb key value). Provides the required parameters (varies from instruction to instruction). Press Enter to execute the command. Redis returns a response indicating the result of the operation (usually OK or -ERR).
 How to implement the underlying redis
Apr 10, 2025 pm 07:21 PM
How to implement the underlying redis
Apr 10, 2025 pm 07:21 PM
Redis uses hash tables to store data and supports data structures such as strings, lists, hash tables, collections and ordered collections. Redis persists data through snapshots (RDB) and append write-only (AOF) mechanisms. Redis uses master-slave replication to improve data availability. Redis uses a single-threaded event loop to handle connections and commands to ensure data atomicity and consistency. Redis sets the expiration time for the key and uses the lazy delete mechanism to delete the expiration key.
 How to view all keys in redis
Apr 10, 2025 pm 07:15 PM
How to view all keys in redis
Apr 10, 2025 pm 07:15 PM
To view all keys in Redis, there are three ways: use the KEYS command to return all keys that match the specified pattern; use the SCAN command to iterate over the keys and return a set of keys; use the INFO command to get the total number of keys.
 How to start the server with redis
Apr 10, 2025 pm 08:12 PM
How to start the server with redis
Apr 10, 2025 pm 08:12 PM
The steps to start a Redis server include: Install Redis according to the operating system. Start the Redis service via redis-server (Linux/macOS) or redis-server.exe (Windows). Use the redis-cli ping (Linux/macOS) or redis-cli.exe ping (Windows) command to check the service status. Use a Redis client, such as redis-cli, Python, or Node.js, to access the server.
 How to read the source code of redis
Apr 10, 2025 pm 08:27 PM
How to read the source code of redis
Apr 10, 2025 pm 08:27 PM
The best way to understand Redis source code is to go step by step: get familiar with the basics of Redis. Select a specific module or function as the starting point. Start with the entry point of the module or function and view the code line by line. View the code through the function call chain. Be familiar with the underlying data structures used by Redis. Identify the algorithm used by Redis.
 How to use redis lock
Apr 10, 2025 pm 08:39 PM
How to use redis lock
Apr 10, 2025 pm 08:39 PM
Using Redis to lock operations requires obtaining the lock through the SETNX command, and then using the EXPIRE command to set the expiration time. The specific steps are: (1) Use the SETNX command to try to set a key-value pair; (2) Use the EXPIRE command to set the expiration time for the lock; (3) Use the DEL command to delete the lock when the lock is no longer needed.
 How to implement redis counter
Apr 10, 2025 pm 10:21 PM
How to implement redis counter
Apr 10, 2025 pm 10:21 PM
Redis counter is a mechanism that uses Redis key-value pair storage to implement counting operations, including the following steps: creating counter keys, increasing counts, decreasing counts, resetting counts, and obtaining counts. The advantages of Redis counters include fast speed, high concurrency, durability and simplicity and ease of use. It can be used in scenarios such as user access counting, real-time metric tracking, game scores and rankings, and order processing counting.
