
 Web Front-end
Front-end Q&A
Intermediate and advanced Android interview questions (with answers)
Web Front-end
Front-end Q&A
Intermediate and advanced Android interview questions (with answers)
Intermediate and advanced Android interview questions (with answers)

Recommended: "2020 Android Interview Questions Summary [Collection]"
##1,java中==和equals和hashCodeThe difference
The memory address of class == comparison, that is, Whether it is the same object, without overriding equals, compare the memory address, the original implementation is also ==, such as String, etc., override the equals method.
hashCode is also a method of the Object class. Returns a discrete integer. Used in collection operations to improve query speed. (HashMap, HashSet, etc. are compared to see if they are the same)
2、The difference between int and integer
int basic typeinteger encapsulation class of object int
3、String , StringBuffer, StringBuilderDifference
String: character String constants are not suitable for situations where the value needs to be changed frequently. Each change is equivalent to generating a new objectStringBuffer: String variable (thread safe)
StringBuilder: String variable (thread unsafe) Ensure single-threaded operation Available, slightly more efficient than StringBuffer
4, what is an internal class? The role of inner classes
Inner classes can directly access the properties of external classesInner classes in Java are mainly divided into
member inner classes,Local inner class (nested within methods and scopes), Anonymous inner class (no constructor method), Static inner class (statically modified class, cannot use any Non-static member variables and methods of peripheral classes do not depend on peripheral classes)
5, the difference between processes and threads
The process is the smallest unit of CPU resource allocation, and the thread is the smallest unit of CPU scheduling.Resources cannot be shared between processes, but threads share the address space and other resources of the process in which they are located.
A process can have multiple threads, and a process can start a process or a thread.
A thread can only belong to one process. The thread can directly use the resources of the same process. The thread depends on the process to exist.
6、final、finally、finalizeThe difference
final: Modifies the class, member variables and member methods. The class cannot be inherited, the member variables are immutable, and the member methods cannot be overridden
finally: used together with try...catch... to ensure that it can be called regardless of whether an exception occurs.
finalize: method of the class. This method will be called before garbage collection. Subclasses can override finalize() Methods to realize the recycling of resources
7, Serializable and Parcelable The difference
Serializable Java serialization interface generates a large number of temporary variables during the reading and writing process on the hard disk, and performs a large number of i/o operations internally, which is very inefficient .
Parcelable Android serialization interface is efficient and troublesome to read and write in memory (AS has related plug-ins to generate the required methods with one click), and the object cannot be saved to the disk
8 Can static properties and static methods be inherited? Can it be rewritten? And why?
Inheritable, not overridable, but hidden
If static methods and properties are defined in the subclass, then the static methods or properties of the parent class are called "hidden" at this time. If you want to call the static methods and properties of the parent class, do it directly through the parent class name, method or variable name.
9, understanding of member inner classes, static inner classes, local inner classes and anonymous inner classes, and application in projects
ava Internal classes are mainly divided into member internal classes, local internal classes (nested within methods and scopes), anonymous internal classes (no constructor methods), Static inner class (statically modified class cannot use non-static member variables and methods of any outer class, and does not rely on outer classes)
The most attractive reason for using inner classes is: Every Each inner class can independently inherit an implementation (of the interface), so whether the outer class has inherited an implementation (of the interface), it has no effect on the inner class.
Because Java does not support multiple inheritance, it supports the implementation of multiple interfaces. But sometimes there are some problems that are difficult to solve using interfaces. At this time, we can use the ability provided by internal classes to inherit multiple concrete or abstract classes to solve these programming problems. It can be said that interfaces only solve part of the problem, and inner classes make the solution of multiple inheritance more complete.
10、How to convert string into integer
##String →integer Intrger.parseInt(string);Integer→string Integer.toString();11, Under what circumstances will objects be disposed of by the garbage collection mechanism?
1. All instances have no active thread access. 2. A circular reference instance that is not accessed by any other instance. 3.There are different reference types in Java. Determining whether an instance is eligible for garbage collection depends on its reference type. To determine what kind of objects are useless objects. There are 2 methods here: 1. Use the mark counting method: Mark the object in the memory. When the object is referenced once, the count is increased by 1, and the reference is released. The count is decremented by one. When the count reaches 0, the object can be recycled. Of course, this also raises a problem: objects with circular references cannot be identified and recycled. So there is a second method: 2. Use the root search algorithm: Start from a root and search for all reachable objects, so that the remaining objects need to be recycled12, the difference between static proxy and dynamic proxy, what scenarios are they used in?
Static proxy class: Created by programmers or automatically generated by specific tools, and then compiled. Before the program is run, the .class file of the proxy class already exists. Dynamic proxy class: dynamically created using the reflection mechanism when the program is running.14、What is the mechanism to implement polymorphism in Java?
Answer: Overriding and overloading of methods are different manifestations of Java polymorphismOverriding is a form of polymorphism between parent classes and subclasses A manifestationOverloading is a manifestation of polymorphism in a class.16, tell me what you think JavaUnderstanding of reflection
The JAVA reflection mechanism is in the running state. For any class, you can know all the properties and methods of this class; for any object, you can call any of its methods and properties. Starting from the object, through reflection (Class class), you can obtain the complete information of the class (class name, Class type, package, all methods Method[] types it has, complete information of a method (including modifiers, return value type, Exception, parameter type), all attributes Field[], complete information of a certain attribute, constructors), calling the attributes or methods of the class itself summary: Get all the information of the class, object, and method during the running process.
17, talk about your understanding of Java annotations
Meta-annotations
The role of meta-annotations is to annotate other annotations. In Java 5.0, four standard meta-annotation types were defined, which are used to provide descriptions of other annotation types.
1.@Target
2.@Retention
3.@Documented
4.@Inherited
18 Understanding String in #Java In the source code, string is modified with final, which is a constant that cannot be changed or inherited.
19
、StringWhy should it be designed to be immutable? 1. Requirements for string pool
The string pool is a special storage area in the method area. When a string has been created and the string is in the pool, a reference to the string is immediately returned to the variable, rather than recreating the string and returning the reference to the variable. If strings are not immutable, changing the string in one reference (e.g. string2) will cause dirty data in another reference (e.g. string1).
2. Allow string cache hash codes
The hash code of strings is often used in java, such as: HashMap. The immutability of String ensures that the hash code is always the same, so he does not have to worry about changes. This approach means that the hash code does not have to be recalculated every time it is used - which is much more efficient.
3. Security
String is widely used for parameters in java classes, such as: network connection (Network connection), opening files (opening files), etc. If String is not immutable, network connections and files will be changed - this will lead to a series of security threats. The method of operation was thought to be connected to a machine, but in fact it was not. Since the parameters in reflection are all strings, it will also cause a series of security issues.
20
、Objectequal and hashCodeMethod rewriting, why? First of all, the relationship between equals and hashcode is as follows:
1. If two objects are the same (that is, using equals to compare and return true), then their hashCode values must be the same ;
2. If the hashCode of two objects is the same, they are not necessarily the same (that is, comparing with equals returns false)
Since the hashcode method is implemented in order to improve the efficiency of the program, proceed first If the hashcode comparison is different, then there is no need to compare equals, which greatly reduces the number of equals comparisons. Compared with the large number of comparisons, the efficiency improvement is obvious
21
、The difference between List, Set and Map Set is the simplest one kind of collection. The objects in the collection are not ordered in a particular way, and there are no duplicate objects. The Set interface mainly implements two implementation classes: HashSet: The HashSet class accesses objects in the set according to the hash algorithm, and the access speed is relatively fast.
TreeSet: The TreeSet class implements the SortedSet interface and can access objects in the set. Objects are sorted.
The characteristic of List is that its elements are stored in a linear manner, and repeated objects can be stored in the collection.
ArrayList(): Represents an array whose length can be changed. Elements can be accessed randomly, and inserting and deleting elements into ArrayList() is slow.
LinkedList(): Uses linked list data structure in implementation. Insertion and deletion are fast, access is slow.
Map is a collection that maps key objects and value objects. Each element of it contains a pair of key objects and value objects. Map does not inherit from the Collection interface. When retrieving elements from the Map collection, as long as the key object is given, the corresponding value object will be returned.
HashMap: Map based implementation of hash table. The cost of inserting and querying key-value pairs is fixed. The capacity and load factor can be set through the constructor to adjust the performance of the container.
LinkedHashMap: Similar to HashMap, but when iterating through it, the order in which the "key-value pairs" are obtained is their insertion order, or the least recently used (LRU) order. Only slightly slower than HashMap. Iterative access is faster because it uses a linked list to maintain the internal order.
TreeMap: Implementation based on red-black tree data structure. When viewing "keys" or "key-value pairs", they are sorted (the order is determined by Comparabel or Comparator). The characteristic of TreeMap is that the results you get are sorted. TreeMap is the only Map with a subMap() method, which can return a subtree.
WeakHashMao: Weak key (weak key) Map, the objects used in the Map are also allowed to be released: This is designed to solve special problems. If there is no reference outside the map pointing to a "key", this "key" can be recycled by the garbage collector.
26、Comparison between ArrayMap and HashMap
1. Different storage methods
There is a HashMapEntry
2. When adding data, the processing when expanding is different. The new operation is performed and the object is re-created, which is very expensive. ArrayMap uses copy data, so the efficiency is relatively high.
3. ArrayMap provides the function of array shrinkage. After clear or remove, the array will be shrunk again, whether there is space or not
4. ArrayMap uses binary search;
# The difference between ##29, HashMap and HashTable
1 HashMap is not thread-safe. It is more efficient and the method is not Synchronize. It needs to provide external synchronization. There are containsvalue and containsKey methods. Hashtable is thread-safe and does not allow null keys and values. It is slightly less efficient and the method is Synchronize. There are contains methods. Hashtable inherits from Dictionary class30, HashMap and HashSet Difference
hashMap: HashMap implements the Map interface. HashMap stores key-value pairs. Use the put() method to put elements into the map. HashMap uses key objects to calculate hashcode. Value, HashMap is faster because unique keys are used to obtain objects. HashSet implements the Set interface. HashSet only stores objects. Use the add() method to put elements into the set. HashSet uses member objects to calculate hashcode values. The hashcodes may be the same for two objects, so equals The () method is used to determine the equality of objects. If the two objects are different, then return false. HashSet is slower than HashMap.31, HashSet and HashMapHow to determine if set elements are duplicated?
HashSet cannot add duplicate elements. When the add (Object) method is called, will first call the hashCode method of Object to determine whether the hashCode already exists. If it does not exist, it will be inserted directly. Element; if it already exists, call the equals method of the Object object to determine whether it returns true. If it is true, it means the element already exists. If it is false, the element is inserted.33, the difference between ArrayList and LinkedList, as well as application scenarios
ArrayList is implemented based on arrays, and ArrayList is thread-unsafe. LinkedList is implemented based on a double linked list: Usage scenarios: (1) If the application performs a large number of access or delete operations on elements at each index position, ArrayList objects are far superior to LinkedList objects;(2) If the application mainly loops through lists, and inserts or deletes during the loop, LinkedList objects are far superior to ArrayList objects;34, the difference between arrays and linked lists
Array: It stores elements continuously in memory; its advantage: because the data is stored continuously, The memory address is continuous, so it is more efficient when searching for data; its disadvantage: before storing, we need to apply for a continuous memory space, and the size of its space must be determined during compilation. The size of the space cannot be changed according to your needs during operation. When the data is relatively large, it may be out of bounds. When the data is relatively small, it may be wasted. memory space. When changing the number of data, adding, inserting, and deleting data are less efficient. Linked list: It is a dynamic application for memory space. There is no need to apply for the memory size in advance like an array. A linked list only needs to apply when it is used. It can dynamically apply for or delete memory space as needed. For data increase and deletion and insertion are more flexible than arrays. There is also the fact that the data in the linked list can be at any location in the memory, and the data can be associated through the application (that is, through the pointer of the existing element)35, open the thread Three ways?
ava has three ways to create threads, namely inheriting the Thread class, implementing the Runable interface and using the thread pool36, the difference between threads and processes?
Threads are a subset of processes. A process can have many threads, and each thread performs different tasks in parallel. Different processes use different memory spaces, and all threads share the same memory space. Don't confuse this with stack memory. Each thread has its own stack memory to store local data.
38、The difference between run() and start()
This question is often asked, but it can still distinguish the interviewer's understanding of the Java thread model. The start() method is used to start a newly created thread, and start() internally calls the run() method, which has a different effect than directly calling the run() method. When you call the run() method, it will only be called in the original thread. If no new thread is started, the start() method will start a new thread.
39. How to control the number of concurrent access threads allowed for a certain method?
semaphore.acquire() requests a semaphore. At this time, the number of semaphores is -1 (once there is no usable semaphore, that is, when the number of semaphores becomes negative, request again will block until other threads release the semaphore)
semaphore.release() releases a semaphore. At this time, the number of semaphores is 1
40 , the difference between wait and seelp methods in Java;
Both wait and sleep in Java programs will cause some form of pause, and they can meet different needs. The wait() method is used for inter-thread communication. If the wait condition is true and other threads are awakened, it will release the lock, while the sleep() method only releases CPU resources or stops the current thread for a period of time, but does not release the lock.
41, talk about the understanding of wait/notify keywords
Waiting for the synchronization lock of the object, you need to obtain the synchronization lock of the object before calling this method. Otherwise, the compilation can pass, but an exception will be received at runtime: IllegalMonitorStateException.
Calling the wait() method of any object causes the thread to block, the thread cannot continue to execute, and the lock on the object is released.
Wake up the thread waiting for the synchronization lock of the object (only wake up one, if there are multiple waiting). Note that when calling this method, you cannot exactly wake up a thread in the waiting state. Instead, the JVM determines which thread to wake up, and not by priority.
Calling the notify() method of any object will cause a randomly selected thread blocked by calling the wait() method of the object to be unblocked (but it will not be executed until the lock is obtained).
42. What causes thread blocking? How to close thread?
The blocking method means that the program will wait for the method to complete without doing anything else. The accept() method of ServerSocket is to wait for the client to connect. The blocking here means that before the call result is returned, the current thread will be suspended and will not return until the result is obtained. In addition, there are asynchronous and non-blocking methods that return before the task is completed.
One is to call the stop() method inside it
The other is to set a mark to stop the thread yourself (recommended)
43 , How to ensure thread safety?
1.synchronized;
2.wait,notify in the Object method;
3.ThreadLocal mechanism to achieve.
44, How to achieve thread synchronization?
1. Method of modifying the synchronized keyword. 2. Statement blocks modified with the synchronized keyword 3. Use special domain variables (volatile) to achieve thread synchronization
45, inter-thread operationsList
List list = Collections.synchronizedList(new ArrayList());
46、Let’s talk about Synchronized Understanding of keywords, class locks, method locks, and reentrant locks
java object locks and class locks: java object locks and class locks are in locks The concept is basically the same as the built-in lock, but the two locks are actually very different. Object locks are used for object instance methods, or on an object instance, and class locks are used for static methods of classes. Or on the class object of a class. We know that there can be many object instances of a class, but each class has only one class object, so the object locks of different object instances do not interfere with each other, but there is only one class lock for each class. But one thing that must be noted is that in fact, class lock is only a conceptual thing and does not really exist. It is only used to help us understand the difference between locking instance methods and static methods
49, synchronized and volatile The difference between keywords
1. The essence of volatile is to tell the jvm that the value of the current variable in the register (working memory) is uncertain and needs to be read from the main memory; synchronized locks the current variable and only The current thread can access this variable, other threads are blocked.
2. Volatile can only be used at the variable level; synchronized can be used at the variable, method, and class levels.
3. Volatile can only achieve the visibility of variable modifications and cannot guarantee atomicity. while synchronized can guarantee the visibility and atomicity of variable modifications
4.volatile will not cause thread blocking; synchronized may cause thread blocking.
5. Variables marked volatile will not be optimized by the compiler; variables marked synchronized can be optimized by the compiler
51、ReentrantLock , synchronized and volatileComparison
Ava has been able to achieve mutual exclusion only through the synchronized keyword for a long time in the past, which has some shortcomings. For example, you cannot extend methods or block boundaries outside the lock, you cannot cancel midway when trying to acquire the lock, etc. Java 5 provides more complex control through the Lock interface to solve these problems. The ReentrantLock class implements Lock, which has the same concurrency and memory semantics as synchronized but is also extensible.
53、Four necessary conditions for deadlock?
Causes of deadlock
1. Competition for system resources
Competition for system resources leads to insufficient system resources and improper resource allocation, leading to deadlock.
2. The order of process running and advancement is inappropriate
Mutual exclusion condition: a resource can only be used by one process at a time, that is, a certain resource can only be occupied by one process within a period of time. At this time, if other processes request the resource, the requesting process can only wait.
Request and retention conditions: The process has maintained at least one resource, but has made a new resource request, and the resource has been occupied by other processes. At this time, the requesting process is blocked, but it has not obtained the resource. Resources remain intact.
Nondeprivation condition: The resources obtained by the process cannot be forcibly taken away by other processes before they are completely used, that is, they can only be released by the process that obtained the resources (it can only be released actively).
Loop waiting conditions: A relationship of end-to-end loop waiting for resources is formed between several processes.
These four conditions are necessary conditions for deadlock. As long as a deadlock occurs in the system, these conditions must be true. As long as one of the above conditions is not met, deadlock will not occur.
Deadlock avoidance and prevention:
The basic idea of deadlock avoidance:
The system dynamically checks the resource request issued by the process for each system that can be satisfied, and based on The check result determines whether to allocate resources. If the system may deadlock after allocation, it will not be allocated, otherwise it will be allocated. This is a dynamic strategy to ensure that the system does not enter a deadlock state.
Understanding the causes of deadlocks, especially the four necessary conditions for deadlocks, you can avoid, prevent and eliminate deadlocks to the greatest extent possible. Therefore, in terms of system design and process scheduling, pay attention to how to ensure that these four necessary conditions do not hold true, and how to determine a reasonable resource allocation algorithm to avoid processes permanently occupying system resources. In addition, it is also necessary to prevent processes from occupying resources while in a waiting state. Therefore, the allocation of resources must be properly planned.
The difference between deadlock avoidance and deadlock prevention:
Deadlock prevention is to try to destroy at least one of the four necessary conditions for deadlock, strictly prevent the occurrence of deadlock, and die Lock avoidance does not strictly limit the existence of necessary conditions for deadlock, because even if the necessary conditions for deadlock exist, deadlock may not necessarily occur. Deadlock avoidance is to pay attention to avoid the eventual occurrence of deadlock during the operation of the system.
56、What is a thread pool and how to use it?
Creating threads costs expensive resources and time. If the thread is created only after the task comes, the response time will become longer, and the number of threads that can be created by a process is limited. In order to avoid these problems, several threads are created to respond to processing when the program starts. They are called thread pools, and the threads inside are called worker threads. Starting from JDK1.5, the Java API provides the Executor framework so that you can create different thread pools. For example, a single thread pool processes one task at a time; a fixed number of thread pools or a cache thread pool (an extensible thread pool suitable for programs with many short-lived tasks).
57、What is the difference between heap and stack in Java?
Why is this question classified as a multi-threading and concurrency interview question? Because the stack is a memory area closely related to threads. Each thread has its own stack memory for storing local variables, method parameters and stack calls. Variables stored in one thread are not visible to other threads. The heap is a common memory area shared by all threads. Objects are created in the heap. In order to improve efficiency, the thread will cache it from the heap to its own stack. If multiple threads use this variable, it may cause problems. At this time, volatile variables can come into play. It requires the thread to start from the main stack. Read the value of a variable from memory.
58, there are three threads T1, T2, T3, how to ensure that they are executed in order?
In multi-threading, there are many ways to let threads execute in a specific order. You can use the join() method of the thread class to start another thread in one thread, and the other thread completes the thread and continues. implement. To ensure the order of the three threads you should start the last one first (T3 calls T2, T2 calls T1), so that T1 will finish first and T3 will finish last.
Inter-thread communication
We know that thread is the smallest unit of CPU scheduling. In Android, the main thread cannot perform time-consuming operations, and sub-threads cannot update the UI. There are many ways to communicate between threads, such as broadcast, Eventbus, and interface callback. In Android, handlers are mainly used. The handler sends the message containing the message to the Messagequeue by calling the sendmessage method, and the looper object continuously calls the loop method to take the message out of the messagequeue and hand it over to the handler for processing, thereby completing inter-thread communication.
Thread Pool
There are four common thread pools in Android, FixedThreadPool, CachedThreadPool, ScheduledThreadPool, and SingleThreadExecutor.
The FixedThreadPool thread pool is created through the new FixedThreadPool method of Executors. Its characteristic is that the number of threads in the thread pool is fixed. Even if threads are idle, they will not be recycled unless the thread pool is closed. When all threads are active, new tasks are in the queue waiting for threads to process. Note that FixedThreadPool only has core threads and no non-core threads.
The CachedThreadPool thread pool is created through Executors' newCachedThreadPool. It is a thread pool with a variable number of threads. It has no core threads, only non-core threads. When all threads in the thread pool are active, new threads will be created to handle new tasks. Otherwise, idle threads will be used to handle new tasks. The threads in the thread pool have a timeout mechanism. The timeout mechanism is 60 seconds. After this time, idle threads will be recycled. This type of thread pool is suitable for handling large amounts of less time-consuming tasks. It should be mentioned here that the task queue of CachedThreadPool is basically empty.
The ScheduledThreadPool thread pool is created through the newScheduledThreadPool of Executors. Its core threads are fixed, but the number of non-core threads is not fixed, and when the non-core threads are idle, they are immediately recycled . This kind of thread is suitable for executing scheduled tasks and recurring tasks with a fixed period.
The SingleThreadExecutor thread pool is created through the newSingleThreadExecutor method of Executors. There is only one core thread in this type of thread pool, and there are no non-core threads. This ensures that all tasks can be executed in the same thread and in order. Execution, so there is no need to consider thread synchronization issues.
AsyncTaskWorking Principle
AsyncTask is a lightweight asynchronous task class provided by Android itself. It can execute background tasks in the thread pool, and then pass the execution progress and final results to the main thread to update the UI. In fact, AsyncTask encapsulates Thread and Handler internally. Although AsyncTask is very convenient for performing background tasks and updating the UI on the main thread, AsyncTask is not suitable for particularly time-consuming background operations. For particularly time-consuming tasks, I personally recommend using a thread pool.
AsyncTask provides 4 core methods:
1. onPreExecute(): This method is executed in the main thread and will be called before executing the asynchronous task. It is generally used for some preparation work.
2. doInBackground(String... params): This method is executed in the thread pool. This method is used to perform asynchronous tasks. In this method, the progress of the task can be updated through the publishProgress method. The publishProgress method will call the onProgressUpdate method. In addition, the result of the task is returned to the onPostExecute method.
3. onProgressUpdate(Object... values): This method is executed in the main thread and is mainly used when the task progress is updated. This method will be called.
4. onPostExecute(Long aLong): Executed in the main thread. After the asynchronous task is executed, this method will be called. The parameters of this method are the return results of the background.
In addition to these methods, there are also some less commonly used methods, such as onCancelled(), which will be called when the asynchronous task is canceled.
From the source code, we can know that the executeOnExecutor() method is called from within the above execute method, that is, executeOnExecutor(sDefaultExecutor, params); and sDefaultExecutor is actually a serial thread pool. The onPreExecute() method will be called here. Next look at this thread pool. The execution of AsyncTask is queued because of the keyword synchronized, and the Params parameter of AsyncTask is encapsulated into the FutureTask class. The FutureTask class is a concurrent class, and here it acts as a Runnable. Then the FutureTask will be handed over to the execute method of SerialExecutor for processing, and the executor method of SerialExecutor will first add the FutureTask to the mTasks queue. If there is no task at this time, the scheduleNext() method will be called to execute the next task. If there is a task, scheduleNext(); will be called at the end after execution to execute the next task. until all tasks are completed. There is a call() method in the constructor of AsyncTask, and this method will be executed by the run method of FutureTask. So eventually this call method will be executed in the thread pool. The doInBackground method is called here. Let's take a closer look at this call() method. mTaskInvoked.set(true); indicates that the current task has been executed. Then execute the doInBackground method, and finally pass the result through the postResult(result); method. In the postResult() method, messages are sent through sHandler. In sHandler, a MESSAGE_POST_RESULT is judged by the type of message. In this case, the onPostExecute(result) method or onCancelled(result) is called. Another message type is MESSAGE_POST_PROGRESS, which calls onProgressUpdate to update the progress.
BinderWorking mechanism
Intuitively speaking, Binder is a class in Android. It implements the IBinder interface. From an IPC perspective Generally speaking, Binder is a way of cross-process communication in Android. It can also be understood as a virtual physical device, and its device driver is /dev/binder/. From a Framework perspective, Binder is the bridge of ServiceManager. From the application layer, Binder is the medium for communication between the client and the server.
Let’s first understand the meaning of each method in this class:
DESCRIPTOR: Binder’s unique identifier, generally used to represent the current Binder class name.
asInterface(android.os.IBinder obj): Used to convert the server's Binder object into an object of the AIDL interface type required by the client. This conversion process is process-specific. If the client and service If the client is in the same process, then this method returns the server's stub object itself, otherwise it returns the system-encapsulated Stub.proxy object.
asBinder(): used to return the current Binder object.
onTransact: This method runs in the Binder thread pool on the server side. When the client initiates a cross-process communication request, the remote request is encapsulated by the bottom layer of the system and handed over to this method for processing. Pay attention to this method public boolean onTransact(int code, android.os.Parcel data, android.os.Parcel reply, int flags). The server can determine the target method requested by the client through the code, and then retrieve the target from the data. The parameters required by the method and then execute the target method. When the target method is executed, the return value is written in reply. This is how the method is executed. If this method returns false, the client will fail the request, so we can do some security verification in this method.
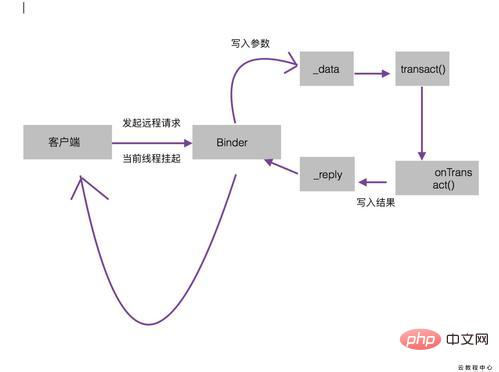
Binder’s working mechanism needs to pay attention to some issues: 1. When the client initiates a request, because the current thread will It is suspended until the server returns data. If this remote method is very time-consuming, then this remote request cannot be initiated in the UI thread, that is, the main thread.
2. Since the Binder method of Service runs in the thread pool, the Binder method should be synchronized whether it is time-consuming or not, because it is already running in a thread.
view event distribution and view working principle
Android custom view, We all know that there are three parts to implementation, onMeasure(), onLayout(), and onDraw(). The drawing process of View starts from the perfromTraversal method of viewRoot. It can draw the view through the measure, layout, and draw methods. Among them, measure measures the width and height, layout determines the position of the view on the parent container, and draw draws the view to the screen.
Measure:
View measurement requires MeasureSpc (measurement specification), which represents a 32-bit int value, the high 2 bits represent SpecMode (measurement mode), and the low (30) bits represent SpecSize (specification size in a certain measurement mode). A set of SpecMode and SpeSize can be packaged into a MeasureSpec, and conversely, MeasureSpec can be unpacked to obtain the values of SpecMode and SpeSize. There are three types of SpecMode:
unSpecified: The parent container does not have any restrictions on the view, as big or small as it wants. This is mostly used in general systems.
Exactly: The parent container has detected the exact size required by the view. At this time, the size of the view is the value specified by SpecSize, which corresponds to math_parent in the layout layout or the specific value
At_most :The parent container specifies a SpecSize of available size. The size of the view cannot be larger than this value. It corresponds to the wrao_content in this layout.
For an ordinary view, its MeasureSpec is composed of the MeasureSpec of the parent container and itself The layoutParam is jointly determined. Once the MeasureSpec is determined, onMeasure can determine the width and height of the view.
View’s measure process:
The onMeasure method has a setMeasureDimenSion method to set the width and height measurement value of the view, and setMeasureDimenSion has a getDefaultSize() method as a parameter. Under normal circumstances, we only need to pay attention to the at_most and exact situations. The return value of getDefaultSize is SpecSize in measureSpec, and this value is basically the measured size of the view. In the case of UnSpecified, it is generally a measurement process within the system, which needs to consider factors such as the background of the view.
What we talked about earlier is the measurement process of view, and the measure process of viewGroup:
For viewGroup, in addition to completing its own measure process, it also needs to traverse to call the measure method of the subclass , each child element performs this process recursively. viewGroup is an abstract class that does not provide an onMeasure method, but provides a measureChildren method. The idea of the measureChild method is to take out the layoutParams of the child element, then get the MeasureSpec of the child element through getChildMeasureSpec, and then measure the child element in the electrophoresis measure method. Since viewGroup subclasses have different layout methods, their measurement details are different, so viewGroup cannot call the onMeasure method for measurement like view.
Note: There is no way to correctly obtain the width and height of the view during the activity life cycle. The reason is that the view has not been measured.
- Obtained in the onWindowFocuschanged method----The meaning of the changed method is that the view has been initialized
- View.post() method, which will deliver the message to the end of the message queue .
- Use viewTreeObserver's callback to complete.
- Manually measure through view.measure.
onLayout
For ordinary views, you can use the setFrame method to get the positions of the four vertices of the view, which also determines the position of the view in the parent container. position, and then call the onLayout method, which determines the position of the child element from the parent container.
onDraw
This method draws the view to the screen. Divide into the following steps:
- draw the background,
- draw yourself,
- draw the child,
- draw the decoration.
AndroidPerformance Optimization
Due to the limitations of mobile phone hardware, neither the memory nor the CPU can have as large a memory as a PC. On Android phones, excessive use of memory can easily lead to OOM, and excessive use of CPU resources can cause the phone to freeze or even cause anr. I mainly optimize from the following parts:
Layout optimization, drawing optimization, memory leak optimization, response speed optimization, listview optimization, bitmap optimization, thread optimization
Layout optimization: tool hierarchyviewer, Solution:
1. Delete useless spaces and levels.
2. Choose a viewgroup with lower performance, such as Relativelayout. If you can choose Relativelayout or LinearLayout, use LinearLayout first, because the function of Relativelayout is relatively complex and will occupy more CPU resources.
3. Use the tags
Drawing optimization
Drawing optimization means that the view avoids a large number of time-consuming operations in the ondraw method, because the ondraw method may be called frequently.
1. Do not create new local variables in the ondraw method. The ondraw method is called frequently, which can easily cause GC.
2. Do not perform time-consuming operations in the ondraw method.
Memory optimization: refer to memory leaks.
Response optimization: The main thread cannot perform time-consuming operations, touch events take 5s, broadcast take 10s, and service take 20s.
Listview optimization:
1. Avoid time-consuming operations in the getview method.
2. View reuse and viewholder use.
3. Sliding is not suitable for enabling asynchronous loading.
4. Process data by paging.
5. Images use level three cache.
Bitmap optimization:
1. Compress images in equal proportions.
2. Recycler unused pictures in time
Thread optimization
The idea of thread optimization is to use the thread pool to manage and reuse threads to avoid a large number of threads in the program. Thread can also control the number of concurrent threads to avoid thread blocking due to mutual preemption of resources.
Other optimizations
1. Use less enumerations, which take up a lot of space.
2. Use Android-specific data structures, such as SparseArray instead of hashMap.
3. Use soft references and weak references appropriately.
Encryption algorithms (base64, MD5, symmetric encryption and asymmetric encryption) and usage scenarios .
What is Rsa encryption?
The RSA algorithm is the most popular public key cryptography algorithm, using keys that can vary in length. RSA is the first algorithm that can be used for both data encryption and digital signatures.
The principle of the RSA algorithm is as follows:
1. Randomly select two large prime numbers p and q, p is not equal to q, and calculate N=pq;
2. Choose a number greater than If 1 is less than N, the natural number e must be relatively prime with (p-1)(q-1).
3. Calculate d using the formula: d×e = 1 (mod (p-1)(q-1)).
4. Destroy p and q.
The final N and e are the "public key", and d is the "private key". The sender uses N to encrypt the data, and the receiver can only use d to decrypt the data content.
The security of RSA relies on large number decomposition. N smaller than 1024 bits has been proven to be unsafe. Moreover, since the RSA algorithm performs large number calculations, RSA is faster than DES at its fastest. Times slower, this is the biggest flaw of RSA, so it can usually only be used to encrypt a small amount of data or encryption keys, but RSA is still a high-strength algorithm.
Usage scenario: In the project, except for login, payment and other interfaces, rsa asymmetric encryption is used, and aes symmetric encryption is used for other interfaces. Today we will learn about aes encryption.
What is MD5 encryption?
The full English name of MD5 is "Message-Digest Algorithm 5", which translates as "Message Digest Algorithm 5". It evolved from MD2, MD3 and MD4. It is a one-way encryption algorithm and is irreversible. encryption method.
What are the characteristics of MD5 encryption?
Compressibility: For data of any length, the length of the calculated MD5 value is fixed.
Easy to calculate: It is easy to calculate the MD5 value from the original data.
Resistance to modification: If any changes are made to the original data, even if only 1 byte is modified, the resulting MD5 value will be very different.
Strong anti-collision: Knowing the original data and its MD5 value, it is very difficult to find data with the same MD5 value (that is, forged data).
MD5 application scenarios:
Consistency verification
Digital signature
Secure access authentication
What is aes encryption?
Advanced Encryption Standard (English: Advanced Encryption Standard, abbreviation: AES), also known as Rijndael encryption method in cryptography, is a block encryption standard adopted by the U.S. federal government. This standard is used to replace the original DES. It has been analyzed by many parties and is widely used around the world.
Implementation principle of HashMap:
HashMap is an asynchronous implementation of the map interface based on the hash table, which allows the use of null values as key and value. There are two most basic structures in the Java programming language, one is an array, and the other is a simulated pointer (reference). All data structures can be constructed using these two basic structures, and HashMap is no exception. HashMap is actually a "linked list hash" data structure. That is a combination of array and linked list.
The bottom layer of HashMap is a data structure, and each item in the array is a linked list.
Conflict:
The Hashcode() method is called in HashMap to calculate the Hashclde value, because two different objects in Java may have the same Hashcode. This led to conflicts.
Solution:
When HashMap is put, it can be seen from the underlying source code that when the program tries to put a key-value object into a HashMap, it first returns the value based on the hashCode() of the key. Determine the storage location of the Entry. If the hashCode() method return value of the two Entry keys is the same, then their storage locations are the same. If the two Entry keys return true through equals comparison, the value of the newly added Entry will be Overwrite the value of the original Entry, but the key will not be overwritten. On the contrary, if false is returned, the newly added Entry will form an Entry chain with the original Entry in the collection, with the newly added one at the head and the old one at the tail
The implementation principle of HashMap:
- Use the hashCode of the key to rehash and calculate the subscript of the element of the current object in the array.
- If keys with the same hash value appear during storage, there are two situations: 1. If the keys are the same, the original value will be overwritten. 2. If the keys are different (conflict occurs), put them in the linked list.
- When obtaining, directly find the subscript corresponding to the hash value, and then further determine whether the key is the same, so as to obtain the corresponding value.
- The core of Hashmap is to use arrays for storage. When a key conflict occurs, it is stored in a linked list.
============================
1. Activity life cycle?
onCreate() -> onStart() -> onResume() -> onPause() -> onStop() -> onDetroy()
2. Service life cycle ?
There are two ways to start service, one is to start through startService(), the other is to start through bindService(). Different startup methods have different life cycles.
The life cycle of a service started through startService() is as follows: call startService() --> onCreate()--> onStartConmon()--> onDestroy(). If you start in this way, you need to pay attention to several issues. First: when we are called through startService, if we call startService() multiple times, the onCreate() method will only be called once, and onStartConmon() will be called multiple times. When we call stopService(), onDestroy() will be called to destroy the service. Second: When we start through startService, pass the value through the intent, and get the value in the onStartConmon() method, we must first determine whether the intent is null.
Bind through bindService(). This way to bind service, life cycle method: bindService-->onCreate()-->onBind()-->unBind()- ->onDestroy() bingservice The advantage of starting the service in this way is that it is more convenient to operate the service in the activity. For example, there are several methods to join the service, a, b. If you want to call it in the activity, you need to obtain the ServiceConnection object in the activity. Use ServiceConnection to obtain the class object of the internal class in the service, and then use this class object to call methods in the class. Of course, this class needs to inherit the Binder object
3. Activity startup process (do not answer the life cycle)
There are two situations in the app startup process. The first is to click the corresponding application icon from the desktop launcher, and the second is to start a new activity by calling startActivity in the activity.
When we create a new project, the default root activity is MainActivity, and all activities are saved in the stack. When we start a new activity, it will be placed on top of the previous activity, and we When clicking the application icon from the desktop, since the launcher itself is also an application, when we click the icon, the system will call startActivitySately(). Under normal circumstances, the relevant information of the activity we start will be saved in the intent, such as action , category and so on. When we install this application, the system will also start a PackaManagerService management service. This management service will parse the AndroidManifest.xml file to obtain relevant information in the application, such as service, activity, Broadcast, etc., and then obtain Information about related components. When we click on the application icon, the startActivitySately() method will be called, and inside this method, startActivty() will be called, and the startActivity() method will eventually call the startActivityForResult() method. And in the startActivityForResult() method. Because the startActivityForResult() method returns a result, the system directly gives a -1, which means that no result is required to be returned. The startActivityForResult() method actually starts the activity through the execStartActivity() method in the Instrumentation class. The main function of the Instrumentation class is to monitor the interaction between the program and the system. In this execStartActivity() method, the proxy object of ActivityManagerService will be obtained, and the activity will be started through this proxy object. A checkStartActivityResult() method will be called during startup. If this component is not configured in the configuration list, an exception will be thrown in this method. Of course, the final call is Application.scheduleLaunchActivity() to start the activity. In this method, an ActivityClientRecord object is obtained, and this ActivityClientRecord uses the handler to send messages. Internally, the system will use the ActivityClientRecord object for each activity component. Description, and the ActivityClientRecord object stores a LoaderApk object, through which handleLaunchActivity is called to start the activity component, and the life cycle method of the page is called in this method.
4. Broadcast registration methods and differences
Extension here: when to use dynamic registration
Broadcast broadcast, there are two main registration methods.
The first is static registration, which can also become a resident broadcast. This kind of broadcast needs to be registered in Androidmanifest.xml. The broadcast registered in this way is not affected by the page life cycle. Even if you exit the page, you can still Receiving a broadcast is generally used when you want to start the computer automatically, etc. Since the broadcast in this registration method is a permanent broadcast, it will occupy CPU resources.
The second type is dynamic registration, and dynamic registration is registered in the code. This registration method is also called non-resident broadcast. It is affected by the life cycle. After exiting the page, it will not After receiving the broadcast, we usually use it to update the UI. This registration method has higher priority. Finally, you need to unbind, whether there will be memory leaks
Broadcast is divided into ordered broadcast and unordered broadcast.
5. The difference between HttpClient and HttpUrlConnection
Extension here: which request method is used in Volley (HttpClient before 2.3, HttpUrlConnection after 2.3)
First of all, HttpClient and HttpUrlConnection both support the Https protocol. Both upload or download data in the form of streams. It can also be said to transmit data in the form of streams, as well as ipv6, connection pooling and other functions. . HttpClient has a lot of APIs, so if you want to extend it without destroying its compatibility, it is difficult to extend it. For this reason, Google directly abandoned this HttpClient in Android 6.0. .
HttpUrlConnection is relatively lightweight, has relatively few APIs, is easy to expand, and can meet most of Android's data transmission. Volley, a relatively classic framework, used HttpClient before version 2.3, and HttpUrlConnection after version 2.3.
6. The difference between java virtual machine and Dalvik virtual machine
Java virtual machine:
1. The java virtual machine is based on the stack. Stack-based machines must use instructions to load and operate data on the stack, and more instructions are required.
2. The java virtual machine runs java bytecode. (The java class will be compiled into one or more bytecode .class files)
Dalvik virtual machine:
1. The dalvik virtual machine is register-based
2 , Dalvik runs a custom .dex bytecode format. (After the java class is compiled into a .class file, a dx tool will be used to convert all the .class files into a .dex file, and then the dalvik virtual machine will read instructions and data from it
3. Constant pool It has been modified to only use 32-bit indexes to simplify the interpreter.
4. One application, one virtual machine instance, and one process (all Android application threads correspond to one Linux thread, all running in In its own sandbox, different applications run in different processes. Each android dalvik application is given an independent linux PID (app_*))
7. Process keep alive (undead process )
Extension here: What is the priority of the process
The current industry's Android process keep-alive methods are mainly divided into three types: black, white, and gray. Their rough implementation The idea is as follows:
Black keep-alive: Different app processes use broadcasts to wake each other up (including using broadcasts provided by the system to wake up)
White keep-alive: Start the foreground Service
Gray keep-alive: Use system vulnerabilities to start the front-end Service
Black keep-alive
The so-called black keep-alive is to use different app processes to use broadcasts to wake up each other. Here are 3 comparisons Common scenarios:
Scenario 1: When turning on the phone, switching networks, taking photos, or taking videos, use the broadcast generated by the system to wake up the app
Scenario 2: Connecting to a third-party SDK will also wake up the corresponding app app process, such as WeChat SDK will wake up WeChat, and Alipay SDK will wake up Alipay. From this, it will directly trigger the following scenario 3
Scenario 3: If you have Alipay and Taobao installed on your phone , Tmall, UC and other Alibaba-based apps, then after you open any Alibaba-based app, you may wake up other Alibaba-based apps by the way. (Just using Alibaba as an example, in fact, the BAT system is similar)
White keep-alive
The white keep-alive method is very simple. It is to call the system API to start a foreground Service process. This will generate a Notification in the system notification bar to let the user know that there is Such an app is running, even if the current app retreats to the background. For example, LBE and QQ Music below:
grey keepalive
Gray keepalive, this kind of keepalive method is the application It has the widest scope. It uses system vulnerabilities to start a foreground Service process. The difference from the ordinary startup method is that it will not appear a Notification in the system notification bar, and it will look like a background Service process is running. The advantage of this is that the user cannot detect that you are running a foreground process (because the Notification cannot be seen), but your process priority is higher than that of ordinary background processes. So how to exploit system vulnerabilities? The general implementation ideas and codes are as follows:
Idea 1: API
Idea 2 : API >= 18, start two front-end services with the same ID at the same time, and then stop the service started later
Anyone who is familiar with the Android system knows that the system is based on experience and performance considerations. , the system will not actually kill the process when the app returns to the background, but will cache it. The more applications you open, the more processes are cached in the background. When the system memory is insufficient, the system begins to determine which processes to kill based on its own set of process recycling mechanisms to free up memory to supply needed apps. This mechanism for killing processes and reclaiming memory is called Low Memory Killer. It is based on the OOM Killer (Out-Of-Memory killer) mechanism of the Linux kernel.
The importance of the process is divided into 5 levels:
Foreground process
Visible process
Service process )
Background process
Empty process
After understanding Low Memory Killer, let’s learn more about oom_adj. What is oom_adj? It is a value assigned by the Linux kernel to each system process, representing the priority of the process. The process recycling mechanism determines whether to recycle based on this priority. Regarding the role of oom_adj, you only need to remember the following points:
The larger the oom_adj of the process, the lower the priority of the process and the easier it is to be killed and recycled; the smaller the oom_adj, the higher the priority of the process. The higher the value, the less likely it is to be killed and recycled
The oom_adj of the ordinary app process>=0, only the oom_adj of the system process may
Some mobile phone manufacturers have put these well-known apps into their own In the white list, it ensures that the process does not die to improve user experience (such as WeChat, QQ, and Momo are all in Xiaomi's white list). If they are removed from the whitelist, they will still be able to escape the fate of being killed like ordinary apps. In order to avoid being killed as much as possible, it is better to do optimization work honestly.
So, the fundamental solution to keeping the process alive ultimately comes back to performance optimization. The immortality of the process is a complete false proposition after all!
8. Explain Context
Context is an abstract base class. When translated as context, it can also be understood as environment, which provides basic information about the running environment of some programs. There are two subclasses under Context. ContextWrapper is the encapsulation class of context functions, and ContextImpl is the implementation class of context functions. ContextWrapper has three direct subclasses, ContextThemeWrapper, Service and Application. Among them, ContextThemeWrapper is an encapsulation class with a theme, and one of its direct subclasses is Activity, so the Context of Activity, Service, and Application are different. Only Activity requires a theme, and Service does not require a theme. There are three types of Context, namely Application, Activity and Service. Although these three classes play different roles, they all belong to a type of Context, and their specific Context functions are implemented by the ContextImpl class. Therefore, in most scenarios, Activity, Service and Application These three types of Context are all universal. However, there are several special scenarios, such as starting an Activity and popping up a Dialog. For security reasons, Android does not allow Activity or Dialog to appear out of thin air. The startup of an Activity must be based on another Activity, which is the return stack formed by this. The Dialog must pop up on an Activity (unless it is a System Alert type Dialog), so in this scenario, we can only use the Activity type Context, otherwise an error will occur.
The objects obtained by the getApplicationContext() and getApplication() methods are the same application object, but the object types are different.
Number of Context = Number of Activity Number of Service 1 (1 is Application)
9. Understand the relationship between Activity, View, and Window
This question is really difficult to answer . So here is a more appropriate metaphor to describe their relationship. Activity is like a craftsman (control unit), Window is like a window (carrying the model), View is like a window grill (displaying the view), LayoutInflater is like scissors, and Xml configuration is like a window grill drawing.
1: When Activity is constructed, a Window will be initialized, PhoneWindow to be precise.
2: This PhoneWindow has a "ViewRoot", and this "ViewRoot" is a View or ViewGroup, which is the initial root view.
3: "ViewRoot" adds Views one by one through the addView method. For example, TextView, Button, etc.
4: The event monitoring of these Views is done by WindowManagerService to receive messages and call back the Activity function. For example, onClickListener, onKeyDown, etc.
10. Four LaunchModes and their usage scenarios
Extension here: the difference between stack (First In Last Out) and queue (First In First Out)
Stack and The difference between queues:
1. The queue is first in, first out, and the stack is first in, last out.
2. "Limitations" on insertion and deletion operations. A stack is a linear list that restricts insertion and deletion operations to only one end of the list. A queue is a linear list that limits insertions to one end of the table and deletions to the other.
3. The data traversal speed is different
standard mode
This is the default mode. Every time the Activity is activated, an Activity instance will be created and placed in the task stack. Usage scenarios: most activities.
singleTop mode
If there happens to be an instance of the Activity at the top of the task stack, the instance will be reused (onNewIntent() of the instance will be called), otherwise a new instance will be created and placed Pushing to the top of the stack, even if an instance of the Activity already exists on the stack, a new instance will be created as long as it is not on the top of the stack. Usage scenarios include content pages of news or reading apps.
singleTask mode
If there is already an instance of the Activity in the stack, the instance will be reused (onNewIntent() of the instance will be called). When reused, the instance will be returned to the top of the stack, so the instances above it will be removed from the stack. If the instance does not exist on the stack, a new instance will be created and placed on the stack. The usage scenario is such as the main interface of the browser. No matter how many applications you start the browser from, the main interface will only be started once. In other cases, onNewIntent will be used, and other pages on the main interface will be cleared.
singleInstance mode
Create an instance of the Activity in a new stack and let multiple applications share the Activity instance in the stack. Once an Activity instance of this mode already exists in a stack, any application that activates the Activity will reuse the instance in the stack (the instance's onNewIntent() will be called). The effect is equivalent to multiple applications sharing one application. No matter who activates the Activity, they will enter the same application. Use scenarios such as alarm reminders to separate alarm reminders from alarm settings. Do not use singleInstance for intermediate pages. If used for intermediate pages, there will be problems with jumps, such as: A -> B (singleInstance) -> C. After completely exiting, start here, and B will be opened first.
11. View drawing process
Custom controls:
1. Combination controls. This kind of custom control does not require us to draw it ourselves, but a new control composed of native controls. Such as title bar.
2. Inherit the original control. This kind of custom control can add some methods by itself in addition to the methods provided by the native control. Such as making rounded corners and circular pictures.
3. Completely customized controls: All the content displayed on this View is drawn by ourselves. For example, make a water ripple progress bar.
View’s drawing process: OnMeasure()——>OnLayout()——>OnDraw()
The first step: OnMeasure(): measure the size of the view. The measure method is called recursively from the top-level parent View to the child View, and the measure method calls back OnMeasure.
Step 2: OnLayout(): Determine the View position and lay out the page. The process of recursively calling the view.layout method from the top-level parent View to the child View means that the parent View places the child View in the appropriate position based on the layout size and layout parameters obtained by measuring the child View in the previous step.
Step 3: OnDraw(): Draw the view. ViewRoot creates a Canvas object and then calls OnDraw(). Six steps: ①, draw the background of the view; ②, save the canvas layer (Layer); ③, draw the content of the View; ④, draw the View subview, if not, do not use it;
⑤, restore Layer; ⑥, draw scroll bars.
12. View and ViewGroup events are divided into
1. There are only two protagonists in Touch event distribution: ViewGroup and View. ViewGroup contains three related events: onInterceptTouchEvent, dispatchTouchEvent, and onTouchEvent. View contains two related events: dispatchTouchEvent and onTouchEvent. Among them, ViewGroup inherits from View.
2. ViewGroup and View form a tree structure, and the root node is a ViwGroup contained within the Activity.
3. The touch event consists of Action_Down, Action_Move, and Aciton_UP. In a complete touch event, there is only one Down and Up, and there are several Moves, which can be 0.
4. When Acitivty receives the Touch event, it will traverse the sub-View to distribute the Down event. ViewGroup traversal can be viewed as recursive. The purpose of distribution is to find the View that actually handles this complete touch event. This View will return true in the onTouchuEvent result.
5. When a sub-View returns true, the distribution of the Down event will be stopped and the sub-View will be recorded in the ViewGroup. The subsequent Move and Up events will be handled directly by the sub-View. Since the sub-View is stored in the ViewGroup, in the multi-layer ViewGroup node structure, the upper-level ViewGroup saves the ViewGroup object where the View that actually handles the event is located: for example, in the structure of ViewGroup0-ViewGroup1-TextView, TextView returns true, which will be saved in ViewGroup1, and ViewGroup1 will also return true and be saved in ViewGroup0. When the Move and UP events come, they will first be passed from ViewGroup0 to ViewGroup1, and then from ViewGroup1 to TextView.
6. When all sub-Views in the ViewGroup do not capture the Down event, the onTouch event of the ViewGroup itself will be triggered. The way to trigger is to call the super.dispatchTouchEvent function, which is the dispatchTouchEvent method of the parent class View. When all sub-Views are not processed, the onTouchEvent method of Activity is triggered.
7.onInterceptTouchEvent has two functions: 1. Intercept the distribution of Down events. 2. Stop the delivery of Up and Move events to the target View, so that the ViewGroup where the target View is located captures the Up and Move events.
13. Save Activity State
onSaveInstanceState(Bundle) will be called before the activity enters the background state, that is, before the onStop() method and after the onPause method;
14. Several animations in Android
Frame animation: refers to the orderly playback of the picture and playback time of each frame to form an animation effect, such as the rhythm bar you want to hear.
Tween animation: refers to the graphical transformation by specifying the initial state, change time, and method of the View through a series of algorithms to form animation effects. There are mainly four effects: Alpha, Scale, Translate, and Rotate. . Note: The animation effect is only implemented in the view layer and does not actually change the properties of the View, such as sliding the list and changing the transparency of the title bar.
Attribute animation: It is only supported in Android 3.0. The animation effect is formed by continuously changing the attributes of the View and constantly redrawing it. Compared with view animation, the properties of View are really changed. For example, view rotation, zooming in, and zooming out.
15. Several methods of cross-process communication in Android
Android cross-process communication, such as intent, contentProvider, broadcast, and service can all communicate across processes.
intent: This cross-process method is not a form of memory access. It requires passing a uri, such as making a call.
contentProvider: This form uses data sharing for data sharing.
service: remote service, aidl
broadcast
16. AIDL understanding
Extension here: Brief description of Binder
AIDL: Each process has its own Dalvik VM instance, has its own independent memory, stores its own data in its own memory, performs its own operations, and completes its own life in its own small space. life. Aidl is like a bridge between two processes, allowing data to be transmitted between the two processes. There are many options for cross-process communication, such as BroadcastReceiver, Messenger, etc., but BroadcastReceiver takes up more system resources. If Frequent cross-process communication is obviously not advisable; when Messenger performs cross-process communication, the request queue is performed synchronously and cannot be executed concurrently.
A simple understanding of the Binde mechanism:
In the Binder mechanism of the Android system, it is composed of Client, Service, ServiceManager, and Binder drivers. Client, service, and Service Manager run in user space. , the Binder driver runs in the kernel space. Binder is the glue that binds these four components together. The core component is the Binder driver. Service Manager provides auxiliary management functions, and Client and Service are based on the Binder driver and Service Manager. Implement communication between C/S on the facility. The Binder driver provides the device file /dev/binder to interact with the user control.
Client, Service, and Service Manager communicate with the Binder driver through corresponding methods of open and ioctl file operations. The inter-process communication between Client and Service is implemented indirectly through the Binder driver. The Binder Manager is a daemon process that manages the Service and provides the Client with the ability to query the Service interface.
17. The principle of Handler
In Android, the main thread cannot perform time-consuming operations, and child threads cannot update the UI. So there is a handler, its role is to implement communication between threads.
handler There are four main objects in the entire process, handler, Message, MessageQueue, and Looper. When the application is created, the handler object will be created in the main thread.
We save the message to be sent to the Message. The handler sends the Message to the MessageQueue by calling the sendMessage method, and the Looper object will continue to Call the loop() method
to continuously take out Messages from the MessageQueue and hand them over to the handler for processing. This enables communication between threads.
18. Principle of Binder mechanism
In the Binder mechanism of the Android system, it is composed of Client, Service, ServiceManager, and Binder drivers. Client, service, and Service Manager run in user space. , the Binder driver runs in the kernel space. Binder is the glue that binds these four components together. The core component is the Binder driver. Service Manager provides auxiliary management functions, and Client and Service are based on the Binder driver and Service Manager. Implement communication between C/S on the facility. The Binder driver provides the device file /dev/binder to interact with user controls. Client, Service, and Service Manager communicate with the Binder driver through corresponding methods of open and ioctl file operations. The inter-process communication between Client and Service is implemented indirectly through the Binder driver. The Binder Manager is a daemon process that manages the Service and provides the Client with the ability to query the Service interface.
19. The principle of hot repair
We know that the Java virtual machine - JVM loads the class file of the class, while the Android virtual machine - Dalvik/ART VM loads the dex file of the class ,
And they all need ClassLoader when loading classes. ClassLoader has a subclass BaseDexClassLoader, and there is an
array under BaseDexClassLoader - DexPathList, which is used to store dex files. When BaseDexClassLoader passes When calling the findClass method, it actually traverses the array,
finds the corresponding dex file, and returns it directly if found. The solution to hot repair is to add the new dex to the collection, and it is in front of the old dex, so
it will be taken out first and returned.
20. Android memory leak and management
(1) The difference between memory overflow (OOM) and memory leak (object cannot be recycled).
(2) Causes of memory leaks
(3) Memory leak detection tool------>LeakCanary
Memory overflow out of memory: refers to When the program applies for memory, there is not enough memory space for it to use, and out of memory appears; for example, if it applies for an integer, but stores a number that can only be stored in a long, it is a memory overflow. In layman's terms, memory overflow means that there is not enough memory.
Memory leak: Memory leak means that after the program applies for memory, it cannot release the allocated memory space. The harm of a memory leak can be ignored, but the consequences of accumulation of memory leaks are serious. No matter how much memory, sooner or later it will be occupied Light
Causes of memory leaks:
1. Memory leaks caused by Handler.
Solution: Declare Handler as a static inner class, so it will not hold a reference to the external class SecondActivity, and its life cycle has nothing to do with the external class.
If context is needed in Handler, you can Reference external classes through weak references
2. Memory leaks caused by singleton mode.
Solution: Context is ApplicationContext. Since the life cycle of ApplicationContext is consistent with the app, it will not cause memory leaks
3. Memory leaks caused by non-static inner classes creating static instances.
Solution: Modify the inner class to be static to avoid memory leaks
4. Memory leaks caused by non-static anonymous inner classes.
Solution: Set the anonymous inner class to static.
5. Memory leaks caused by unpaired use of registration/unregistration.
Register broadcast receiver, EventBus, etc., remember to unbind.
6. Memory leak caused by resource object not being closed.
When these resources are not in use, remember to call the corresponding methods such as close(), destroy(), recycler(), release(), etc. to release them.
7. Memory leaks caused by failure to clean up collection objects in time.
Usually some objects are loaded into a collection. When not in use, you must remember to clean up the collection in time so that related objects are no longer referenced.
21. How Fragment communicates with Fragment and Activity
1. Directly call the method in another Fragment in one Fragment
2. Use interface callback
3. Use broadcast
4.Fragment directly calls the public method in Activity
22. Android UI adaptation
Use sp, use dp, and more for fonts match_parent, wrap_content, weight
picture resources, the resolution of different pictures can be replaced by percentage when placed in the corresponding folder.
23. App optimization
App optimization: (Tool: Hierarchy Viewer analysis layout Tool: TraceView test analysis time-consuming)
App startup optimization
Layout optimization
Response optimization
Memory optimization
Battery usage optimization
Network optimization
App startup optimization (for cold start)
There are three ways to start the App:
Cold start: The App has not been started or the App process has been killed. The App process does not exist in the system. Starting the App at this time is a cold start.
Hot start: Hot start means that your App process is only in the background, and the system just brings it from the background to the foreground and displays it to the user.
Between cold start and warm start, generally occurs in the following two situations:
(1) The user back exits the App and then starts it again. The App process may still be It's running, but the activity needs to be rebuilt.
(2) After the user exits the App, the system may kill the App due to memory reasons, and both the process and activity need to be restarted. However, the saved instance state of the passive kill lock can be restored in onCreate. .
Optimization:
Application’s onCreate (especially third-party SDK initialization) and the rendering of first-screen Activity do not need to perform time-consuming operations. If so, they can be placed in child threads or IntentServices.
Layout optimization
Try not to make nesting too complex. You can use
Response Optimization
The Android system will send out a VSYNC signal every 16ms to redraw our interface (Activity).
Causes of page lag:
(1)Overly complex layout.
(2)Complex operations of UI thread
(3)Frequent There are two reasons for frequent GC: 1. Memory jitter, that is, a large number of objects are created and released immediately in a short period of time. 2. Generating a large number of objects in an instant will seriously occupy the memory area.
Memory optimization: refer to the memory leak and memory overflow section
Battery usage optimization (use tools: Batterystats & bugreport)
(1) Optimize network requests
(2) When using GPS for positioning, please remember to turn off
Network optimization (the impact of network connections on users: traffic, power, user waiting) can be detected by the tool Network Monitor next to logcat under Android studio
API design: The API design between the App and Server should consider the frequency of network requests, the status of resources, etc. so that the App can complete business requirements and interface display with fewer requests.
Gzip compression: Use Gzip to compress request and response, reducing the amount of data transmitted, thereby reducing traffic consumption.
Size of the picture: You can tell the server the width and height of the required picture when obtaining the picture, so that the server can give an appropriate pictures to avoid waste.
Network caching: Proper caching can not only make our application look faster, but also avoid unnecessary traffic consumption.
24. Image optimization
(1) Operate on the picture itself. Try not to use setImageBitmap, setImageResource, BitmapFactory.decodeResource to set a large picture, because after completing decoding, these methods
are ultimately completed through createBitmap of the java layer, which requires more memory.
(2) The scaling ratio of the image. The SDK recommends that the value be an exponential value of 2. The larger the value, the larger the value will cause the image to be unclear.
(3) Remember to call the recycle() method of unused pictures
25. Interaction between HybridApp WebView and JS
Android and JS call each other's methods through WebView. In fact, Yes:
Android calls JS code
1. Using WebView's loadUrl(), this method is simpler and more convenient. However, the efficiency is relatively low and it is difficult to obtain the return value.
2. Through WebView's evaluateJavascript(), this method is highly efficient, but it is only supported by versions above 4.4 and not by versions below 4.4. So it is recommended to use a mixture of both.
JS calls Android code
1. Perform object mapping through WebView's addJavascriptInterface(). This method is simple to use. It only maps Android objects and JS objects, but it has a relatively large problem. loopholes.
The reason for the vulnerability is: when JS gets the Android object, it can call all methods in the Android object, including the system class (java.lang.Runtime class), thereby executing arbitrary code.
Solution:
(1) Google stipulates in Android 4.2 that the called functions be annotated with @JavascriptInterface to avoid vulnerability attacks.
(2) Use intercept prompt() to fix the vulnerability before Android 4.2 version.
2. Intercept the url through the shouldOverrideUrlLoading () method callback of WebViewClient. The advantages of this method: there are no loopholes in method 1; disadvantages: JS obtaining the return value of the Android method is complicated. (ios mainly uses this method)
(1)Android intercepts the url through the callback method shouldOverrideUrlLoading () of WebViewClient
(2)The protocol for parsing the url
( 3) If a pre-agreed protocol is detected, call the corresponding method
3. Intercept the JS dialog box alert(), confirm() through the onJsAlert(), onJsConfirm(), onJsPrompt() method callbacks of WebChromeClient ), prompt() message
The advantages of this method: there are no loopholes in method 1; disadvantages: JS obtaining the return value of the Android method is complicated.
26. JAVA GC Principle
The core idea of the garbage collection algorithm is to identify the available memory space of the virtual machine, that is, the objects in the heap space. If the object is being referenced, then it is called It is a living object
. On the contrary, if the object is no longer referenced, it is a garbage object, and the space it occupies can be reclaimed for reallocation. The choice of garbage collection algorithm and the reasonable adjustment of garbage collection system parameters directly affect system performance.
27, ANR
The full name of ANR is Application Not Responding, which is "Application Not Responding". When the operation cannot be processed by the system within a period of time, the ANR as shown above will pop up at the system level. Dialog box.
Cause:
(1)Unable to respond to user input events (such as keyboard input, touch screen, etc.) within 5s.
(2)BroadcastReceiver in 10s Unable to end within 20s
(3) Service cannot end within 20s (low probability)
Solution:
(1) Do not perform time-consuming operations in the main thread. Instead, it should be implemented in a child thread. For example, do as few creation operations as possible in onCreate() and onResume().
(2) Applications should avoid doing time-consuming operations or calculations in BroadcastReceiver.
(3) Avoid starting an Activity in the Intent Receiver, because it will create a new screen and steal focus from the program currently running by the user.
(4)Service runs in the main thread, so time-consuming operations in service must be placed in child threads.
28. Design pattern
Extension here: Double Check is required to be written.
Single case mode: divided into evil man style and lazy man style
Evil man style:
public class Singleton
{
private static Singleton instance = new Singleton();
public static Singleton getInstance()
{
return instance ;
}
}Lazy man style:
public class Singleton02
{
private static Singleton02 instance;
public static Singleton02 getInstance()
{
if (instance == null)
{
synchronized (Singleton02.class)
{
if (instance == null)
{
instance = new Singleton02();
}
}
}
return instance;
}
}29, RxJava
30, MVP, MVC, MVVM
Extension here: handwritten mvp example, the difference between it and mvc, the advantages of mvp
MVP mode, corresponding to Model--Business Logic and entity model, view - corresponds to the activity, is responsible for drawing the View and interacting with the user, Presenter - is responsible for the interaction between the View and the Model. The MVP mode is based on the MVC mode, completely separating the Model and the View so that The coupling of the project is even lower. In MVC, the activity in the project corresponds to the C--Controllor in MVC, and the logical processing in the project is processed in this C. At the same time, the interaction between View and Model is also Said that all logical interactions and user interactions in mvc are placed in the Controller, that is, in the activity. View and model can communicate directly. The MVP model is more completely separated and has a clearer division of labor. Model - business logic and entity model, view - is responsible for interacting with users, and Presenter is responsible for completing the interaction between View and Model. The biggest difference between MVP and MVC is that in MVC Allows Model and View to interact, and it is obvious in MVP that the interaction between Model and View is completed by Presenter. Another point is that the interaction between Presenter and View is through the interface
31. Handwriting algorithm (must know how to choose bubbling)
32. JNI
(1 )Install and download Cygwin, download Android NDK
(2)Design of JNI interface in ndk project
(3)Use C/C to implement local methods
(4 )JNI generates the dynamic link library .so file
(5) Copy the dynamic link library to the java project, call it in the java project, and run the java project
33. RecyclerView and ListView Difference
RecyclerView can complete the effects of ListView and GridView, and can also complete the effect of waterfall flow. At the same time, you can also set the scrolling direction of the list (vertical or horizontal);
The reuse of views in RecyclerView does not require developers to write code themselves, the system has already packaged it for you.
RecyclerView can perform partial refresh.
RecyclerView provides API to realize the animation effect of item.
In terms of performance:
If you need to refresh data frequently and add animations, RecyclerView has a greater advantage.
If it is only displayed as a list, the difference between the two is not very big.
34. Comparison of Universal-ImageLoader, Picasso, Fresco, and Glide
Fresco is an open source image caching tool launched by Facebook. Its main features include: two memory caches plus Native cache constitute a three-level Cache,
Advantages:
1. The image is stored in the anonymous shared memory of the Android system, rather than in the heap memory of the virtual machine. The intermediate buffer data of the image is also stored in the local heap memory, so , the application uses more memory, does not cause OOM due to image loading, and also reduces the interface lag caused by frequent calls of the garbage collector to recycle Bitmap, resulting in higher performance.
2. Progressive loading of JPEG images, supporting loading of images from blurry to clear.
3. The picture can be displayed in the ImageView at any center point, not just the center of the picture.
4. Changing the size of JPEG images is also done in native, not in the heap memory of the virtual machine, which also reduces OOM.
5. Very good support for the display of GIF images.
Disadvantages:
1. The framework is large, which affects the Apk size
2. It is cumbersome to use
Universal-ImageLoader: (It is estimated that HttpClient is replaced by Google If you give up, the author will give up maintaining this framework)
Advantages:
1. Support download progress monitoring
2. You can pause image loading during View scrolling, through the PauseOnScrollListener interface Pause image loading during View scrolling.
3. Various memory caching algorithms are implemented by default. These image caches can all be configured with caching algorithms. However, ImageLoader implements many caching algorithms by default, such as Largest Size First, Delete Least Used First, and Least Recently Used. , first-in-first-out, longest-in-first-out, etc.
4. Support local cache file name rule definition
Picasso advantages
1. Comes with statistical monitoring function. Supports monitoring of image cache usage, including cache hit rate, used memory size, saved traffic, etc.
2. Support priority processing. Before each task is scheduled, a task with a higher priority will be selected. For example, this is very suitable when the priority of Banner in the App page is higher than that of Icon.
3. Support delay until image size calculation is completed and loading
4. Support flight mode, the number of concurrent threads changes according to the network type. When the phone switches to airplane mode or the network type changes, the maximum concurrency number of the thread pool will be automatically adjusted. For example, the maximum concurrency number of wifi is 4, 4g is 3, and 3g is 2. Here Picasso determines the maximum number of concurrencies based on the network type, not the number of CPU cores.
5. "None" local cache. "No" local cache does not mean that there is no local cache, but Picasso itself has not implemented it and handed it over to another network library of Square, okhttp, to implement it. The advantage of this is that the image can be controlled by requesting Cache-Control and Expired in the Response Header. Expiration time.
Advantages of Glide
1. It can not only cache images but also cache media files. Glide is not only an image cache, it supports Gif, WebP, thumbnails. Even Video , so it should be used as a media cache.
2. Supports priority processing.
3. Consistent with the Activity/Fragment life cycle, supports trimMemory. Glide maintains a RequestManager for each context , through FragmentTransaction, it remains consistent with the Activity/Fragment life cycle, and there is a corresponding trimMemory interface implementation available for calling.
4. Supports okhttp and Volley. Glide obtains data through UrlConnection by default, and can be used with okhttp or Volley .In fact, ImageLoader and Picasso also support okhttp and Volley.
5. Memory friendly. Glide’s memory cache has an active design. When fetching data from the memory cache, it is not like the general implementation that uses get, but Use remove, and then put this cached data into an activeResources map whose value is a soft reference, and count the number of references. After the image is loaded, it will be judged. If the reference count is empty, it will be recycled. Memory cache smaller pictures, Glide Using url, view_width, view_height, screen resolution, etc. as joint keys, cache the processed image in the memory cache instead of the original image to save size. It is consistent with the Activity/Fragment life cycle and supports trimMemory. The default image is used by default. RGB_565 instead of ARGB_888. Although the definition is worse, the picture is smaller and can also be configured to ARGB_888.
6.Glide can support url expiration through signature or without using local cache
42. Comparison of Xutils, OKhttp, Volley, Retrofit
Xutils is a very comprehensive framework that can perform network requests, image loading, data storage, and annotation of views. It is very convenient to use this framework, but it has shortcomings It is also very obvious that using this project will cause the project to be very dependent on this framework. Once there is a problem with this framework, it will have a great impact on the project. ,
OKhttp: In Android development, you can directly use the ready-made api to make network requests. Just use HttpClient and HttpUrlConnection to operate. For Java and Android programs, okhttp encapsulates a high-performance http request library that supports synchronization and asynchronousness. Moreover, okhttp also encapsulates the thread pool, data conversion, parameter usage, error handling, etc. The API is more convenient to use. But when we use it in the project, we still need to make a layer of encapsulation ourselves, so that it can be used more smoothly.
Volley: Volley is a set of small and exquisite asynchronous request libraries officially released by Google. The framework is highly scalable and supports HttpClient, HttpUrlConnection, and even OkHttp, and Volley also encapsulates ImageLoader. So if you want, you don't even need to use an image loading framework. However, this function is not as powerful as some specialized image loading frameworks. It can be used for simple needs, but more complex requirements still require the use of a specialized image loading framework. Volley also has flaws, such as not supporting post big data, so it is not suitable for uploading files. However, the original intention of Volley's design itself is for frequent network requests with small data volumes.
Retrofit: Retrofit is a RESTful network request framework based on OkHttp encapsulation by default produced by Square. RESTful is a currently popular API design style and is not a standard. Retrofit's encapsulation can be said to be very powerful. It involves a bunch of design patterns. Requests can be configured directly through annotations. Different http clients can be used. Although http is used by default, different Json Converters can be used to serialize data. At the same time, To provide support for RxJava, use Retrofit OkHttp RxJava Dagger2. It can be said to be a relatively trendy framework at present, but it requires a relatively high threshold.
Volley VS OkHttp
The advantage of Volley is that it is better encapsulated, but to use OkHttp you need to have enough ability to encapsulate again. The advantage of OkHttp is higher performance. Because OkHttp is based on NIO and Okio, the performance is faster than Volley. IO and NIO are both concepts in Java. If I read data from the hard disk, the first way is that the program waits until the data is read before continuing. This is the simplest and is also called blocking IO. One way is that you read your data, the program continues to execute, and you notify me after the data is processed, and then handle the callback. The second method is NIO, which is non-blocking, so of course NIO has better performance than IO. Okio is a library made by Square based on IO and NIO that is simpler and more efficient in processing data streams. Theoretically, if you compare Volley with OkHttp, you are more inclined to use Volley, because Volley also supports the use of OkHttp internally, so the performance advantage of OkHttp is gone, and Volley itself is packaged easier to use and has better scalability.
OkHttp VS Retrofit
There is no doubt that Retrofit is a package based on OkHttp by default. There is no comparability in this regard, and Retrofit is definitely preferred.
Volley VS Retrofit
Both libraries are well encapsulated, but Retrofit is more thoroughly decoupled, especially when Retrofit 2.0 comes out, Jake fixes the unreasonable parts of the previous 1.0 design. A lot of refactoring, responsibilities are more subdivided, and Retrofit uses OkHttp by default, which has an advantage over Volley in terms of performance. Moreover, if your project uses RxJava, you should use Retrofit. Therefore, compared with these two libraries, Retrofit has more advantages. If you can master both frameworks, you should use Retrofit first. However, the threshold for Retrofit is slightly higher than that of Volley. It takes some effort to fully understand its principles and various uses. If you know only a little about it, it is recommended to use Volley in commercial projects.
Java
1. The difference between sleep and wait in threads
(1) These two methods come from different classes, sleep comes from Thread, and wait comes from Object;
(2) The sleep method does not release the lock, but the wait method releases the lock.
(3)wait, notify, notifyAll can only be used in synchronization control methods or synchronization control blocks, while sleep can be used anywhere.
2. What is the difference between the start() and run() methods in Thread?
The start() method is used to start a newly created thread, and start() internally calls run() ) method, which is different from calling the run() method directly. If the run() method is called directly, it will be no different from the ordinary method.
3. How to use the keywords final and static.
final:
1. The final variable is a constant and can only be assigned a value once.
2. The final method cannot be overridden by subclasses.
3. Final classes cannot be inherited.
static:
1. Static variables: There is only one copy of static variables in memory (saving memory). The JVM only allocates memory once for static variables.
After loading the class The memory allocation of static variables is completed in the process, and can be accessed directly by class name (convenient). Of course, it can also be accessed through objects (but this is not recommended).
2. Static code block
The static code block is automatically executed during initialization when the class is loaded.
3. Static method
The static method can be called directly through the class name, and any instance can also be called. Therefore, the this and super keywords cannot be used in the static method.
You cannot directly access instance variables and instance methods of the class you belong to (that is, member variables and member methods without static), you can only access static member variables and member methods of the class you belong to.
4. Differences between String, StringBuffer and StringBuilder
1. The execution speed of the three: StringBuilder > StringBuffer > String (Since String is a constant and cannot be changed, it will be recreated during splicing. new object).
2. StringBuffer is thread-safe, and StringBuilder is thread-unsafe. (Because StringBuffer has a buffer)
5. The difference between overloading and rewriting in Java:
1. Overloading: There can be multiple methods with the same name in a class, but the parameters The type and number are different. This is overloading.
2. Rewriting: If a subclass inherits the parent class, the subclass can implement the methods in the parent class, so that the new method overwrites the old method of the parent class.
6. Differences between HTTP https cost.
2. http is a hypertext transfer protocol, and information is transmitted in plain text, while https is a secure SSL encrypted transmission protocol.
3. http and https use completely different connection methods and use different ports. The former is 80 and the latter is 443.
4. The http connection is very simple and stateless; the HTTPS protocol is a network protocol built from the SSL HTTP protocol that can perform encrypted transmission and identity authentication, and is more secure than the http protocol.
https implementation principle:
(1) The customer uses the URL of https to access the web server and requires an SSL connection to be established with the web server.
(2) After receiving the client's request, the web server will transmit a copy of the website's certificate information (the certificate contains the public key) to the client.
(3) The client's browser and the Web server begin to negotiate the security level of the SSL connection, which is the level of information encryption.
(4) The client's browser establishes a session key based on the security level agreed by both parties, then uses the website's public key to encrypt the session key and transmits it to the website.
(5) The Web server uses its own private key to decrypt the session key.
(6) The web server uses the session key to encrypt the communication with the client.
7. At which layer in the TCP/IP model is HTTP located? Why is HTTP a reliable data transfer protocol?
Tcp/ip five-layer model:
From bottom to top: physical layer->data link layer->network layer->transport layer->application layer
Among them, tcp/ip is located at the network layer in the model, and ICMP (Network Control Message Protocol) is also at the same layer. http is located in the application layer in the model
Since tcp/ip is a reliable connection-oriented protocol, and http is based on the tcp/ip protocol in the transport layer, so http is a reliable data transmission protocol.
8. Characteristics of HTTP links
The most significant feature of HTTP connections is that each request sent by the client requires the server to send back a response. After the request is completed, the connection will be actively released.
The process from establishing a connection to closing the connection is called "a connection".
9. The difference between TCP and UDP
tcp is connection-oriented. Since tcp connection requires three handshakes, it can minimize the risk and ensure the reliability of the connection.
udp is not connection-oriented. Udp does not need to establish a connection with the object before establishing a connection. No confirmation signal is sent whether it is sending or receiving. So udp is unreliable.
Since UDP does not need to confirm the connection, UDP has less overhead and higher transmission rate, so the real-time operation is better.
10. Steps for Socket to establish a network connection
Establishing a Socket connection requires at least a pair of sockets, one of which runs with the client--ClientSocket, and one runs with the server--ServiceSocket
1. Server monitoring: The server-side socket does not locate the specific client socket, but is in a state of waiting for connection, monitoring the network status in real time, and waiting for the client's connection request.
2. Client request: refers to the client's socket making a connection request, and the target to be connected is the server's socket. Note: The client's socket must describe the socket of the server to which it wants to connect,
indicates the address and port number of the server socket, and then makes a connection request just like the server-side socket.
3. Connection confirmation: When the server-side socket monitors the connection request of the client socket, it responds to the request of the client socket, establishes a new thread, and connects the server-side socket to the client socket. The description of the word
is sent to the client. Once the client confirms this description, the two parties formally establish a connection. The server socket continues to be in the listening state and continues to receive connection requests from other client sockets.
11. Tcp/IP three-way handshake and four-way wave
The above is the detailed content of Intermediate and advanced Android interview questions (with answers). For more information, please follow other related articles on the PHP Chinese website!

Hot AI Tools

Undresser.AI Undress
AI-powered app for creating realistic nude photos

AI Clothes Remover
Online AI tool for removing clothes from photos.

Undress AI Tool
Undress images for free

Clothoff.io
AI clothes remover

Video Face Swap
Swap faces in any video effortlessly with our completely free AI face swap tool!

Hot Article
Hot Tools

Notepad++7.3.1
Easy-to-use and free code editor

SublimeText3 Chinese version
Chinese version, very easy to use

Zend Studio 13.0.1
Powerful PHP integrated development environment

Dreamweaver CS6
Visual web development tools

SublimeText3 Mac version
God-level code editing software (SublimeText3)
Hot Topics
 1666
1666
 14
1425
52
1327
25
1273
29
1253
24
14
1425
52
1327
25
1273
29
1253
24

 New report delivers damning assessment of rumoured Samsung Galaxy S25, Galaxy S25 Plus and Galaxy S25 Ultra camera upgrades
Sep 12, 2024 pm 12:23 PM
New report delivers damning assessment of rumoured Samsung Galaxy S25, Galaxy S25 Plus and Galaxy S25 Ultra camera upgrades
Sep 12, 2024 pm 12:23 PM
In recent days, Ice Universe has been steadily revealing details about the Galaxy S25 Ultra, which is widely believed to be Samsung's next flagship smartphone. Among other things, the leaker claimed that Samsung only plans to bring one camera upgrade
 Samsung Galaxy S25 Ultra leaks in first render images with rumoured design changes revealed
Sep 11, 2024 am 06:37 AM
Samsung Galaxy S25 Ultra leaks in first render images with rumoured design changes revealed
Sep 11, 2024 am 06:37 AM
OnLeaks has now partnered with Android Headlines to provide a first look at the Galaxy S25 Ultra, a few days after a failed attempt to generate upwards of $4,000 from his X (formerly Twitter) followers. For context, the render images embedded below h
 IFA 2024 | TCL\'s NXTPAPER 14 won\'t match the Galaxy Tab S10 Ultra in performance, but it nearly matches it in size
Sep 07, 2024 am 06:35 AM
IFA 2024 | TCL\'s NXTPAPER 14 won\'t match the Galaxy Tab S10 Ultra in performance, but it nearly matches it in size
Sep 07, 2024 am 06:35 AM
Alongside announcing two new smartphones, TCL has also announced a new Android tablet called the NXTPAPER 14, and its massive screen size is one of its selling points. The NXTPAPER 14 features version 3.0 of TCL's signature brand of matte LCD panels
 Vivo Y300 Pro packs 6,500 mAh battery in a slim 7.69 mm body
Sep 07, 2024 am 06:39 AM
Vivo Y300 Pro packs 6,500 mAh battery in a slim 7.69 mm body
Sep 07, 2024 am 06:39 AM
The Vivo Y300 Pro just got fully revealed, and it's one of the slimmest mid-range Android phones with a large battery. To be exact, the smartphone is only 7.69 mm thick but features a 6,500 mAh battery. This is the same capacity as the recently launc
 Samsung Galaxy S24 FE billed to launch for less than expected in four colours and two memory options
Sep 12, 2024 pm 09:21 PM
Samsung Galaxy S24 FE billed to launch for less than expected in four colours and two memory options
Sep 12, 2024 pm 09:21 PM
Samsung has not offered any hints yet about when it will update its Fan Edition (FE) smartphone series. As it stands, the Galaxy S23 FE remains the company's most recent edition, having been presented at the start of October 2023. However, plenty of
 New report delivers damning assessment of rumoured Samsung Galaxy S25, Galaxy S25 Plus and Galaxy S25 Ultra camera upgrades
Sep 12, 2024 pm 12:22 PM
New report delivers damning assessment of rumoured Samsung Galaxy S25, Galaxy S25 Plus and Galaxy S25 Ultra camera upgrades
Sep 12, 2024 pm 12:22 PM
In recent days, Ice Universe has been steadily revealing details about the Galaxy S25 Ultra, which is widely believed to be Samsung's next flagship smartphone. Among other things, the leaker claimed that Samsung only plans to bring one camera upgrade
 Xiaomi Redmi Note 14 Pro Plus arrives as first Qualcomm Snapdragon 7s Gen 3 smartphone with Light Hunter 800 camera
Sep 27, 2024 am 06:23 AM
Xiaomi Redmi Note 14 Pro Plus arrives as first Qualcomm Snapdragon 7s Gen 3 smartphone with Light Hunter 800 camera
Sep 27, 2024 am 06:23 AM
The Redmi Note 14 Pro Plus is now official as a direct successor to last year'sRedmi Note 13 Pro Plus(curr. $375 on Amazon). As expected, the Redmi Note 14 Pro Plus heads up the Redmi Note 14 series alongside theRedmi Note 14and Redmi Note 14 Pro. Li
 Motorola Razr 50s shows itself as possible new budget foldable in early leak
Sep 07, 2024 am 09:35 AM
Motorola Razr 50s shows itself as possible new budget foldable in early leak
Sep 07, 2024 am 09:35 AM
Motorola has released countless devices this year, although only two of them are foldables. For context, while most of the world has received the pair as the Razr 50 and Razr 50 Ultra, Motorola offers them in North America as the Razr 2024 and Razr 2
