I wrote a small piece of code to crawl the pictures in the Blog Park blog. This code is effective for some links, but some links report errors as soon as they are crawled. What is the reason?
#coding=utf-8
import urllib
import re
from lxml import etree
#解析地址
def getHtml(url):
page = urllib.urlopen(url)
html = page.read()
return html
#获取地址并建树
url = "http://www.cnblogs.com/fnng/archive/2013/05/20/3089816.html"
html = getHtml(url)
html = html.decode("utf-8")
tree = etree.HTML(html)
#保存图片至本地
reg = r'src="(.*?)" alt'
imgre = re.compile(reg)
imglist = re.findall(imgre, html)
x = 0
for imgurl in imglist:
urllib.urlretrieve(imgurl, '%s.jpg' % x)
x += 1As shown in the figure, the image can be crawled correctly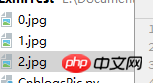
If you change the url to
url = "http://www.cnblogs.com/baronzhang/p/6861258.html"then report an error immediately

Please solve it, thank you!















![[Web front-end] Node.js quick start](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)




The error message is already very obvious. If you look at the source code of the web page, the first image matched is in GIF format, and it is still a relative path, so you cannot download it, so it prompts IOerror, even if you have downloaded it. , because you specified the format as JPG, you cannot open it. So all you need to do is judge and filter
Look at what I added. Of course, this is just the simplest judgment, but it can ensure that your second program will not report an error, and it also gives you an idea!