
Background:
Use bs4's select under Python3 to get the store name in the coupon information at the top of the ZOZO homepage. (Domestic IP seems to be unable to see the coupon information. You need to scroll through it to see it. It is best to use an island country IP)
Question:
I found that I couldn’t find where his store name was written. I don’t know how to get it. I don’t understand the front-end js. Please give me an answer. Thanks.
My own code is as follows:
import requests, bs4
shopName = 'BEAUTY&YOUTH'
url = 'http://zozo.jp/'
def getZozoCoupon():
res = requests.get(url, headers={"User-Agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_11_4) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/49.0.2623.110 Safari/537.36"})
res.raise_for_status()
soup = bs4.BeautifulSoup(res.text, 'html.parser')
elems = soup.select('.bnrName')
return elems[0].text.strip()The following screenshot shows the text you want to get, 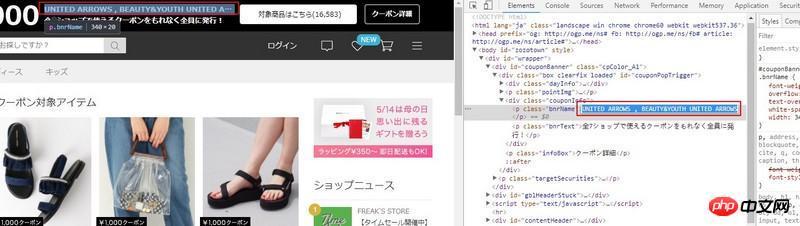
I found that there is no text in the source code.
<p class="couponInfo">
<p class="bnrName">说好的文字呢。。。</p>
<p class="bnrText"></p>
</p>Please tell me where his text is implemented and how to use bs4 select to display it. Thank you.














![[Web front-end] Node.js quick start](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)




It is possible to use ajax to obtain it from the server and then operate the dom to dynamically add it. When js is executed in the browser, the text will also be added. When you crawled with a crawler, you did not execute the relevant js, so you did not add text.
If this is really the case, you can check the network in f12 of the browser, find out the URL of the http request to get the text, and directly request this URL to get the information you need.
I opened http://zozo.jp/ in the browser to view the source code and did not find the bnrName you were looking for

Right-click on the browser and "view web page source code" to see if you can find your text. If you can't find it, the web page should be dynamically loaded using js or ajax. If you want to crawl this kind of dynamic page, you need to There is no other way, either manually simulate the request yourself, or use selenium to catch it
It is indeed generated by js, and has been simulated and captured using a headless browser. Thank you everyone!