
I want to use urllib to grab the xls download link of the Shanghai Stock Exchange stock list, as shown in the small red box below:
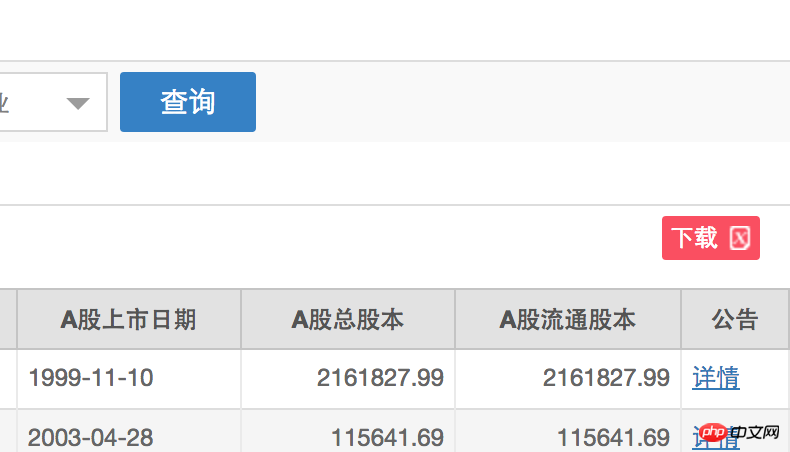
I found that the captured xls only reported error message:
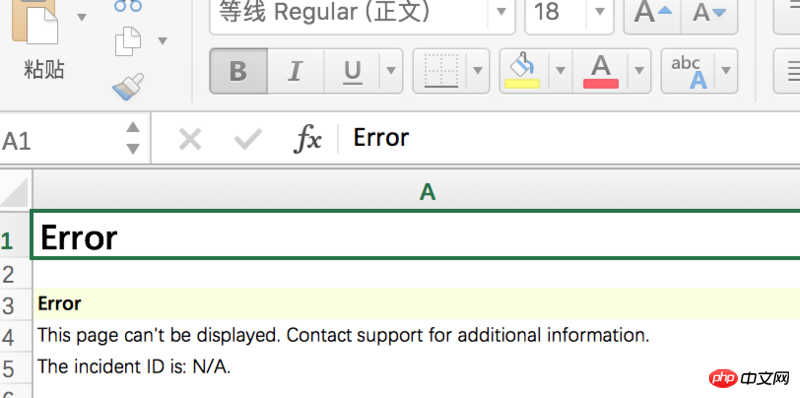
How can I capture the xls with content?
code show as below
from urllib import request
from datetime import datetime
# -*- coding:utf-8 -*-
url = 'http://query.sse.com.cn/security/stock/downloadStockListFile.do?' \
'csrcCode=&stockCode=&areaName=&stockType=1'
myheaders = [('User - Agent', 'Mozilla/5.0 (Windows; U; Windows NT 5.2) AppleWebKit/525.13'
' (KHTML, like Gecko) Version/3.1 Safari/525.13'),]
opener = request.build_opener()
opener.addheaders = myheaders
request.install_opener(opener)
local = "/Users/Mty/Downloads/data/" + str(datetime.now().date()) + " .xls"
request.urlretrieve(url, local)














![[Web front-end] Node.js quick start](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)




You can see the returned company information on the URL marked with a red line. The rest is to simulate the browser requesting this URL. The refer in the request header must not be omitted, otherwise 403 will be reported
Remember to simulate the value of refer.
http://blog.csdn.net/ssshen14...
This is an existing solution
View cookies, referer