count(*) does not count the value of each column (regardless of whether it is null), but directly counts the number of rows, which is more efficient;
You can also use the elimination method. For example, if the platform is qq and there is a lot of data, you can use the total data to subtract the data of platform=other;
From a business perspective, the cost of obtaining accurate values is very high, but the cost of approximate values is lower. If the requirements are not strict, approximate values can be used instead;
In addition, you can also consider using "memory database" such as redis to maintain this time-consuming data acquisition;
1. If I encounter such a problem, my solution is to create a new table, such as playfrom_count for statistics. It would be better to use methods like after_insert and after_delete in the framework. If not, write one yourself. 2. If the volume of such query business is not very large, or if it is not very accurate, you can do a task to run it. Update it every once in a while. 3. Whether you are innodb or myisam, because you added where, it will Scan the entire table. So you can increase the retrieval speed by adding a primary key.
Option 1. Create a partition table for the platform Option 2. Split the table by platform Option 3. Create a separate index for the platform, but considering that the value set of your platform should not be very large, it is not appropriate to do this index
This problem will be encountered in classic relational databases. The general solution is to access the system table, which contains the number of data rows in each table, which is countless times faster than your COUNT(*).
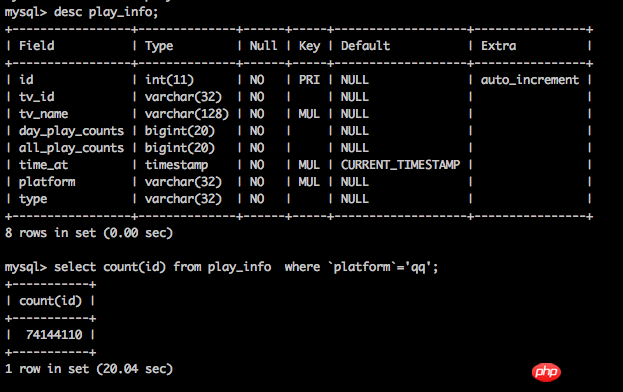
Upgrade your machine. Even a simple count takes 20 seconds. Although there are many methods such as partition tables, I feel that the investment is not worth the investment.
It is recommended to consider the needs of the business scenario first. The cost of a purely technical solution is too high, and in many cases it is basically impossible to implement it. Possible solutions are: 1. Split tables: Divide into multiple tables according to the platform. The storage engine is MyISAM. The query statement is changed to count(*). MyISAM will save the total number of rows in the table, so the query efficiency is very high. improvement. It is necessary to consider the workload of system transformation caused by sub-tables and whether MyISAM can meet the system requirements because MyISAM does not support transactions.
2. Create redundant tables or fields and recalculate the data that needs to be summarized when it changes. You need to consider whether a large number of update operations will increase the load on the system.
3. If the query results are not required to be completely accurate, the results can be calculated regularly and saved. When querying, the original table is not directly queried.
In this case, it can be divided into multiple statistical tables according to months or quarters. For example, if you have 8 million data, create a new table, and each row represents the total records of a month. This way the statistics will be much faster.














![[Web front-end] Node.js quick start](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)




count(*) does not count the value of each column (regardless of whether it is null), but directly counts the number of rows, which is more efficient;
You can also use the elimination method. For example, if the platform is qq and there is a lot of data, you can use the total data to subtract the data of platform=other;
From a business perspective, the cost of obtaining accurate values is very high, but the cost of approximate values is lower. If the requirements are not strict, approximate values can be used instead;
In addition, you can also consider using "memory database" such as redis to maintain this time-consuming data acquisition;
1. If I encounter such a problem, my solution is to create a new table, such as playfrom_count for statistics.
It would be better to use methods like after_insert and after_delete in the framework. If not, write one yourself.
2. If the volume of such query business is not very large, or if it is not very accurate, you can do a task to run it. Update it every once in a while.
3. Whether you are innodb or myisam, because you added where, it will Scan the entire table. So you can increase the retrieval speed by adding a primary key.
Option 1. Create a partition table for the platform
Option 2. Split the table by platform
Option 3. Create a separate index for the platform, but considering that the value set of your platform should not be very large, it is not appropriate to do this index
This problem will be encountered in classic relational databases. The general solution is to access the system table, which contains the number of data rows in each table, which is countless times faster than your COUNT(*).
Upgrade your machine. Even a simple count takes 20 seconds. Although there are many methods such as partition tables, I feel that the investment is not worth the investment.
It is recommended to consider the needs of the business scenario first. The cost of a purely technical solution is too high, and in many cases it is basically impossible to implement it.
Possible solutions are:
1. Split tables: Divide into multiple tables according to the platform. The storage engine is MyISAM. The query statement is changed to count(*). MyISAM will save the total number of rows in the table, so the query efficiency is very high. improvement. It is necessary to consider the workload of system transformation caused by sub-tables and whether MyISAM can meet the system requirements because MyISAM does not support transactions.
2. Create redundant tables or fields and recalculate the data that needs to be summarized when it changes. You need to consider whether a large number of update operations will increase the load on the system.
3. If the query results are not required to be completely accurate, the results can be calculated regularly and saved. When querying, the original table is not directly queried.
In this case, it can be divided into multiple statistical tables according to months or quarters. For example, if you have 8 million data, create a new table, and each row represents the total records of a month. This way the statistics will be much faster.