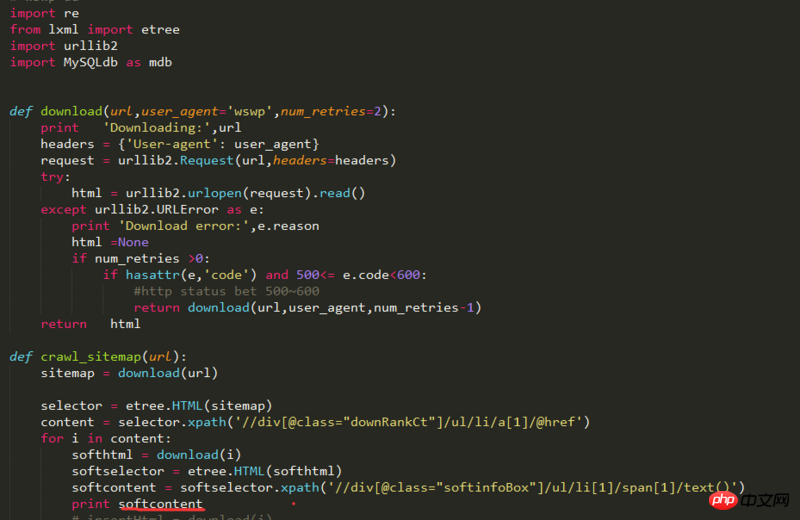
py code:
Page html structure:
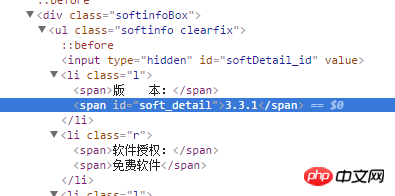
Return result:
[u'xe7x89x88xe3x80x80xe3x80x80xe6x9cxacxefxbcx9a']
What character encoding is this? How to convert it to the version number in html?
学习是最好的投资!
This encoding is the way Chinese characters are stored in lists. You can try printing out the members of the list individually:
print softcontent[0]

















![[Web front-end] Node.js quick start](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)




This encoding is the way Chinese characters are stored in lists. You can try printing out the members of the list individually: