
I encountered the following problems when crawling all mobile phone information on JD.com:
1. There are too many return values, as shown in the following picture: 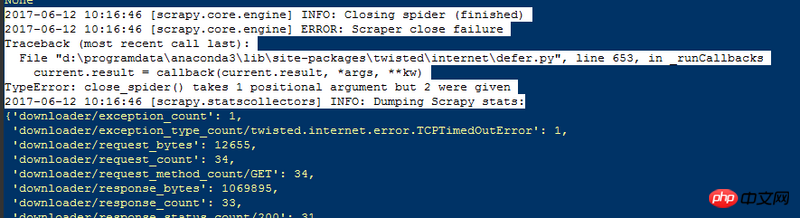
2. The spider code is as follows:
import scrapy
from scrapy.http import Request
from ueinfo.items import UeinfoItem
class MrueSpider(scrapy.Spider):
name = 'mrue'
allowed_domains = ['jd.com']
start_urls = ['http://jd.com/']
def parse(self, response):
key="手机"
for i in range(1,2):
url="https://search.jd.com/Search?keyword="+str(key)+"&enc=utf-8&page="+str((i*2)-1)
#print(url)
yield Request(url=url,callback=self.page)
def page(self,response):
#body=response.body.decode("utf-8","ignore")
allid=response.xpath("//p[@class='p-focus']//a/@data-sku").extract()
for j in range(0,len(allid)):
thisid=allid[j]
url1="https://item.jd.com/"+str(thisid)+".html"
#print(url1)
yield Request(url=url1,callback=self.next)
def next(self,response):
item=UeinfoItem()
item["pinpai"]=response.xpath("//ul[@id='parameter-brand']/li/@title").extract()
#print(item["pinpai"])
item["xinghao"]=response.xpath("//p[@class='Ptable']//p[@class='Ptable-item']//dl//dt[text()='型号']/following::*[1]").extract()
#print(item["xinghao"])
item["nianfen"]=response.xpath("//p[@class='Ptable']//p[@class='Ptable-item']//dl//dt[text()='上市年份']/following::*[1]").extract()
#print(item["nianfen"])
item["yuefen"]=response.xpath("//p[@class='Ptable']//p[@class='Ptable-item']//dl//dt[text()='上市月份']/following::*[1]").extract()
#print(item["yuefen"])
item["caozuoxt"]=response.xpath("//p[@class='Ptable']//p[@class='Ptable-item']//dl//dt[text()='操作系统']/following::*[1]").extract()
#print(item["caozuoxt"])
item["cpupp"]=response.xpath("//p[@class='Ptable']//p[@class='Ptable-item']//dl//dt[text()='CPU品牌']/following::*[1]").extract()
#print(item["cpupp"])
item["cpuhs"]=response.xpath("//p[@class='Ptable']//p[@class='Ptable-item']//dl//dt[text()='CPU核数']/following::*[1]").extract()
#print(item["cpuhs"])
item["cpuxh"]=response.xpath("//p[@class='Ptable']//p[@class='Ptable-item']//dl//dt[text()='CPU型号']/following::*[1]").extract()
#print(item["cpuxh"])
item["shuangkalx"]=response.xpath("//p[@class='Ptable']//p[@class='Ptable-item']//dl//dt[text()='双卡机类型']/following::*[1]").extract()
#print(item["shuangkalx"])
item["mfnetwangl"]=response.xpath("//p[@class='Ptable']//p[@class='Ptable-item']//dl//dt[text()='4G网络']/following::*[1]").extract()
#print(item["mfnetwangl"])
item["fnetwangl"]=response.xpath("//p[@class='Ptable']//p[@class='Ptable-item']//dl//dt[text()='网络频率(4G)']/following::*[1]").extract()
#print(item["fnetwangl"])
item["netwanglplus"]=response.xpath("//p[@class='Ptable']//p[@class='Ptable-item']//dl//dt[text()='指纹识别']/following::*[1]").extract()
#print(item["netwanglplus"])
item["volte"]=response.xpath("//p[@class='Ptable']//p[@class='Ptable-item']//dl//dt[text()='高清语音通话(VOLTE)']/following::*[1]").extract()
#print(item["volte"])
item["screenstyle"]=response.xpath("//p[@class='Ptable']//p[@class='Ptable-item']//dl//dt[text()='主屏幕尺寸(英寸)']/following::*[1]").extract()
#print(item["screenstyle"])
item["fenbiel"]=response.xpath("//p[@class='Ptable']//p[@class='Ptable-item']//dl//dt[text()='分辨率']/following::*[1]").extract()
#print(item["fenbiel"])
item["dianchirl"]=response.xpath("//p[@class='Ptable']//p[@class='Ptable-item']//dl//dt[text()='电池容量(mAh)']/following::*[1]").extract()
#print(item["dianchirl"])
yield itemThe code for pipelines is as follows:
import pymysql
class UeinfoPipeline(object):
def __init__(self):
self.conn=pymysql.connect(host="127.0.0.1",user="root",passwd="root",db="mysql")
def process_item(self, item, spider):
try:
pinpai=item["pinpai"][0]
xinghao=item["xinghao"][0]
nianfen=item["nianfen"][0]
yuefen=item["yuefen"][0]
caozuoxt=item["caozuoxt"][0]
coupp=item["cpupp"][0]
cpuhs=item["cpuhs"][0]
cpuxh=item["cpuxh"][0]
shuangkalx=item["shuangkalx"][0]
mfnetwangl=item["mfnetwangl"][0]
fnetwangl = item["fnetwangl"][0]
netwanglplus=item["netwanglplus"][0]
volte=item["volte"][0]
screenstyle=item["screenstyle"][0]
fenbiel=item["fenbiel"][0]
dianchirl=item["dianchirl"][0]
sql="insert into uems(pinpai,xinghao,nianfen,yuefen,caozuoxt,cpupp,cpuhs,cpuxh,shuangkalx,mwangluo,fwangluo,wangluoplus,volte,screenstyle,fenbian,dianchi)VALUES('"+pinpai+"','"+xinghao+"','"+nianfen+"','"+yuefen+"','"+caozuoxt+"','"+coupp+"','"+cpuhs+"','"+cpuxh+"','"+shuangkalx+"','"+mfnetwangl+"','"+fnetwangl+"','"+netwanglplus+"','"+volte+"','"+screenstyle+"','"+fenbiel+"','"+dianchirl+"')"
self.conn.query(sql)
#print(mfnetwangl)
return item
except Exception as err:
pass
def close_spider(self):
self.conn.close()














![[Web front-end] Node.js quick start](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)




in
pipelinesdef close method is wrongly defined
This is how it should be
def close(self, spider)
As for ignoring some values with empty content
Using for may save code!