Let’s first take a look at the characteristics of B+ trees
InnoDB engine table is an index organized table (IOT) based on B+ tree
About B+Tree
(Pictures from the Internet)
Features of B+ tree:
a. All keywords appear in the linked list of leaf nodes (dense index), and the keywords in the linked list happen to be ordered;
b. It is impossible to hit on non-leaf nodes;
c. Non-leaf nodes are equivalent to the index of leaf nodes (sparse index), and leaf nodes are equivalent to the data layer that stores (keyword) data.
1. If we define the primary key (PRIMARY KEY)
Then InnoDB will select the primary key as the clustered index. If the primary key is not explicitly defined, InnoDB will select the first unique index that does not contain a NULL value as the primary key index. If there is no such unique index, InnoDB will select The built-in 6-byte long ROWID is used as an implicit clustered index (ROWID is incremented as row records are written and the primary key is incremented. This ROWID is not as referenceable as ORACLE's ROWID and is implicit).
2. The data record itself is stored on the leaf node of the main index (a B+Tree)
This requires that each data record in the same leaf node (the size is one memory page or disk page) is stored in primary key order, so whenever a new record is inserted, MySQL will insert it according to its primary key. Appropriate node and location, if the page reaches the load factor (InnoDB default is 15/16), open a new page (node)
3. If the table uses an auto-incrementing primary key
Then every time a new record is inserted, the record will be added to the subsequent position of the current index node. When a page is full, a new page will be automatically opened
4. If using a non-auto-incrementing primary key (if ID number or student number, etc.)
Since the value of the primary key inserted each time is approximately random, each new record must be inserted somewhere in the middle of the existing index page. At this time, MySQL has to move the data in order to insert the new record into the appropriate location. , even the target page may have been written back to the disk and cleared from the cache. At this time, it needs to be read back from the disk, which adds a lot of overhead. At the same time, frequent moving and paging operations cause a lot of fragmentation, and we get The index structure is not compact enough, and you have to use OPTIMIZE TABLE to rebuild the table and optimize the filling page.
Summary: If the data writing order of the InnoDB table can be consistent with the order of the leaf nodes of the B+ tree index, the access efficiency is the highest at this time, that is, the access efficiency is the highest in the following situations:
a. Use an auto-incrementing column (INT/BIGINT type) as the primary key. At this time, the writing order is auto-incrementing, which is consistent with the splitting order of B+ leaf nodes;
b. The table does not specify an auto-increment column as the primary key, and there is no unique index that can be selected as the primary key (the above condition). At this time, InnoDB will choose the built-in ROWID as the primary key, and the writing order and ROWID growth order Consistent;
c. If an InnoDB table does not display a primary key, and there is a unique index that can be selected as the primary key, but the unique index may not be in an incremental relationship (such as string, UUID, multi-field joint unique index), The access efficiency of this table will be relatively poor.
The following are the original words from "High Performance MySQL"
Original address: http://imysql.com/2014/09/14/mysql-faq-why-innodb-table-using-autoinc-int-as-pk.shtml
Let’s first understand some key features of InnoDB engine tables:
InnoDB engine table is an index-organized table (IOT) based on B+ tree; Each table needs to have a clustered index; All row records are stored in the leaf nodes of B+ tree (leaf pages of the tree); The efficiency of addition, deletion, modification and query based on clustered index is relatively the highest; If we define the primary key (PRIMARY KEY), then InnoDB will choose it as the clustered index ; If the primary key is not explicitly defined, InnoDB will select the first unique index that does not contain a NULL value as the primary key index; If there is no such unique index, InnoDB will select the built-in 6-byte long index The ROWID is used as an implicit clustered index (the ROWID is incremented as the row record is written and the primary key is incremented. This ROWID is not as referenceable as ORACLE's ROWID and is implicit). To sum up, if the data writing order of the InnoDB table can be consistent with the order of the leaf nodes of the B+ tree index, the access efficiency will be the highest at this time, that is, the access efficiency will be the highest in the following situations:
Use an auto-incrementing column (INT/BIGINT type) as the primary key. At this time, the writing order is auto-incrementing, which is consistent with the splitting order of B+ leaf nodes; This table does not specify an auto-incrementing column as the primary key, and it also There is no unique index that can be selected as the primary key (the above condition). At this time, InnoDB will choose the built-in ROWID as the primary key, and the writing order is consistent with the ROWID growth order; In addition, if an InnoDB table does not display the primary key , and there is a unique index that can be selected as the primary key, but when the unique index may not have an increasing relationship (such as string, UUID, multi-field joint unique index), the access efficiency of the table will be relatively poor. What is the actual situation? After a simple TPCC benchmark test, the TPCC test was modified to use auto-increment columns as the primary key and the original table structure. The TpmC result of the former was 9% higher than the latter, which shows the obvious benefits of using auto-increment columns as the primary key of the InnoDB table. Other more You can compare and test the performance improvement of using auto-increment columns in many different scenarios.
Innodb is a clustered index. If you don’t add a primary key, it will also add an implicit primary key. The data itself of the innodb data table is an index file distributed by primary key. You can read this article http://segmentfault.com/a/1190000003046591
















![[Web front-end] Node.js quick start](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)




Let’s first take a look at the characteristics of B+ trees
InnoDB engine table is an index organized table (IOT) based on B+ tree
About B+Tree
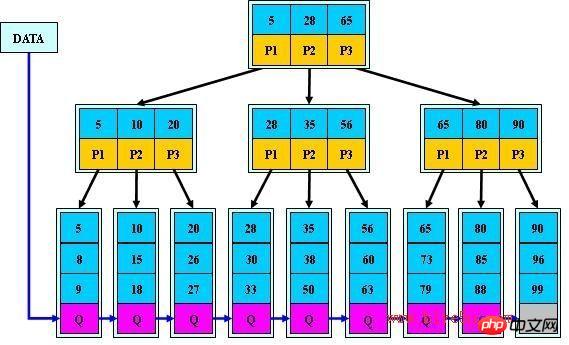
(Pictures from the Internet)
Features of B+ tree:
a. All keywords appear in the linked list of leaf nodes (dense index), and the keywords in the linked list happen to be ordered;
b. It is impossible to hit on non-leaf nodes;
c. Non-leaf nodes are equivalent to the index of leaf nodes (sparse index), and leaf nodes are equivalent to the data layer that stores (keyword) data.
1. If we define the primary key (PRIMARY KEY)
Then InnoDB will select the primary key as the clustered index. If the primary key is not explicitly defined, InnoDB will select the first unique index that does not contain a NULL value as the primary key index. If there is no such unique index, InnoDB will select The built-in 6-byte long ROWID is used as an implicit clustered index (ROWID is incremented as row records are written and the primary key is incremented. This ROWID is not as referenceable as ORACLE's ROWID and is implicit).
2. The data record itself is stored on the leaf node of the main index (a B+Tree)
This requires that each data record in the same leaf node (the size is one memory page or disk page) is stored in primary key order, so whenever a new record is inserted, MySQL will insert it according to its primary key. Appropriate node and location, if the page reaches the load factor (InnoDB default is 15/16), open a new page (node)
3. If the table uses an auto-incrementing primary key
Then every time a new record is inserted, the record will be added to the subsequent position of the current index node. When a page is full, a new page will be automatically opened
4. If using a non-auto-incrementing primary key (if ID number or student number, etc.)
Since the value of the primary key inserted each time is approximately random, each new record must be inserted somewhere in the middle of the existing index page. At this time, MySQL has to move the data in order to insert the new record into the appropriate location. , even the target page may have been written back to the disk and cleared from the cache. At this time, it needs to be read back from the disk, which adds a lot of overhead. At the same time, frequent moving and paging operations cause a lot of fragmentation, and we get The index structure is not compact enough, and you have to use OPTIMIZE TABLE to rebuild the table and optimize the filling page.
Summary: If the data writing order of the InnoDB table can be consistent with the order of the leaf nodes of the B+ tree index, the access efficiency is the highest at this time, that is, the access efficiency is the highest in the following situations:
a. Use an auto-incrementing column (INT/BIGINT type) as the primary key. At this time, the writing order is auto-incrementing, which is consistent with the splitting order of B+ leaf nodes;
b. The table does not specify an auto-increment column as the primary key, and there is no unique index that can be selected as the primary key (the above condition). At this time, InnoDB will choose the built-in ROWID as the primary key, and the writing order and ROWID growth order Consistent;
c. If an InnoDB table does not display a primary key, and there is a unique index that can be selected as the primary key, but the unique index may not be in an incremental relationship (such as string, UUID, multi-field joint unique index), The access efficiency of this table will be relatively poor.
The following are the original words from "High Performance MySQL"
Original address: http://imysql.com/2014/09/14/mysql-faq-why-innodb-table-using-autoinc-int-as-pk.shtml
Let’s first understand some key features of InnoDB engine tables:
InnoDB engine table is an index-organized table (IOT) based on B+ tree;
Each table needs to have a clustered index;
All row records are stored in the leaf nodes of B+ tree (leaf pages of the tree);
The efficiency of addition, deletion, modification and query based on clustered index is relatively the highest;
If we define the primary key (PRIMARY KEY), then InnoDB will choose it as the clustered index ;
If the primary key is not explicitly defined, InnoDB will select the first unique index that does not contain a NULL value as the primary key index;
If there is no such unique index, InnoDB will select the built-in 6-byte long index The ROWID is used as an implicit clustered index (the ROWID is incremented as the row record is written and the primary key is incremented. This ROWID is not as referenceable as ORACLE's ROWID and is implicit).
To sum up, if the data writing order of the InnoDB table can be consistent with the order of the leaf nodes of the B+ tree index, the access efficiency will be the highest at this time, that is, the access efficiency will be the highest in the following situations:
Use an auto-incrementing column (INT/BIGINT type) as the primary key. At this time, the writing order is auto-incrementing, which is consistent with the splitting order of B+ leaf nodes;
This table does not specify an auto-incrementing column as the primary key, and it also There is no unique index that can be selected as the primary key (the above condition). At this time, InnoDB will choose the built-in ROWID as the primary key, and the writing order is consistent with the ROWID growth order;
In addition, if an InnoDB table does not display the primary key , and there is a unique index that can be selected as the primary key, but when the unique index may not have an increasing relationship (such as string, UUID, multi-field joint unique index), the access efficiency of the table will be relatively poor.
What is the actual situation? After a simple TPCC benchmark test, the TPCC test was modified to use auto-increment columns as the primary key and the original table structure. The TpmC result of the former was 9% higher than the latter, which shows the obvious benefits of using auto-increment columns as the primary key of the InnoDB table. Other more You can compare and test the performance improvement of using auto-increment columns in many different scenarios.
Innodb is a clustered index. If you don’t add a primary key, it will also add an implicit primary key. The data itself of the innodb data table is an index file distributed by primary key.
You can read this article http://segmentfault.com/a/1190000003046591