- Front-end
- HTML| CSS| JavaScript| Vue.js
Latest Recommendations
-

Php8, I'm coming too
84669 person learning
- native foundation
- HTML| CSS| HTML5| CSS3| JavaScript
Latest Recommendations
-

Learn website layout in 30 minutes
152542 person learning
- Introduction to Fundamentals
- MySQL| SQL Server
Latest Recommendations
-

Shangguan Oracle Beginner to Proficient Video Tutorial
20005 person learning
Latest Recommendations
-

Your first line of UNI-APP code
5487 person learning
-

Flutter from scratch to app launch
7821 person learning
- Tool usage
- PhpStudy| Git| Other tools
Latest Recommendations
-

Brother Lian New Linux Video Tutorial
359900 person learning
Latest Recommendations
-

AXURE 9 Video Tutorial (Suitable for Product Manager Interactive Product Design UI)
3350 person learning
-

Zero Basic Proficiency PS Video Tutorial
180660 person learning
-

16 day UI video tutorial to get you started
48569 person learning
-

PS Techniques and Slicing Techniques Video Tutorial
18603 person learning
- Class Library Classification
- HTTP| TCP/IP| basic programming
Latest Recommendations
-

Alibaba Cloud Environment Construction and Project Launch Video Tutorial
40936 person learning
-

Overview of Computer Networks - Basic Knowledge that Programmers Must Master
1549 person learning
-

Essential Tutorial for Programmers - HTTP Protocol Explanation
1183 person learning
-

Websocket Video Tutorial
32909 person learning















![[Web front-end] Node.js quick start](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)




The following code can solve the problem, thank you for your answers. . .
Use xpath to find it. . lxml parsing
It feels like there may be something wrong with the regular expression.
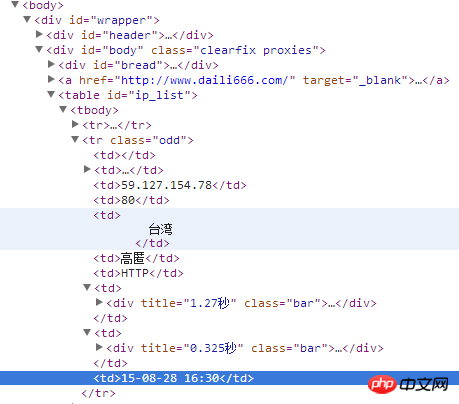
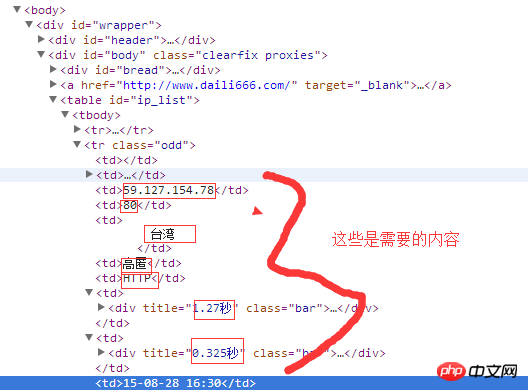
First look at the document structure:
Each
<tr>...</tr>tag contains a complete list of content, while<td>...</td>The tag contains a single item of content.<tr>...</tr>标签里包含了一列完整的内容,而<td>...</td>标签里是一个单项内容。建议用正则表达是从
<tr>标签开始对每一个<td>标签进行解析。大概这样:
r'(<tr class.*?>.*?<td.*?<td.*?<td>(.*?)</td>.......</tr>)'这里面
It is recommended to use regular expressions to parse each(.*?)<td>tag starting from the<tr>tag.
Probably like this:r'(<tr class.*?>.*?<td.*?<td.*?<td>(.*?)</td>.. .....</tr>)'
Here(.*?)is the parsed IP address, which is similar later. 🎜 🎜It’s a little troublesome to write, but it shouldn’t be wrong. 🎜 🎜In fact, it will be much easier to use BeautifulSoup. 🎜Using re to operate html is also boring, let’s use xpath.
Recommended to use BeautifulSoup
BeautifulSoup is a good choice, but writing regular expression code yourself is not elegant enough.
......scrapy
scrapy...